


April Newsletter
Industrial Strength Data Science and AI

Hi everyone-
Spring in the air, daffodils out - a vague inkling that the winter gloom might be coming to an end finally. Time to find a comfy spot outside and immerse yourself in some fun AI and Data Science… Lots of great reading materials below to distract and entertain and I really encourage you to read on, but here are the edited highlights if you are short for time!
Is it still worth learning to code? Yes! - Andrew Ng
The AI Scientist Generates its First Peer-Reviewed Scientific Publication - Sakana
Is the Mercury LLM the first of a new Generation of LLMs? - Devansh
The Cybernetic Teammate - Ethan Mollick
Teaching Language Models to Solve Sudoku Through Reinforcement Learning - Hrishbh Dalal
Following is the April edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
The RSS has a new open access journal! - RSS: Data Science and Artificial Intelligence.

It offers an exciting venue for your work in these disciplines with a broad reach across statistics, machine learning, deep learning, econometrics, bioinformatics, engineering, computational social sciences. The journal is peer reviewed by editors esteemed in their field and is open to submission. Discover more about why the new journal is the ideal platform for showcasing your
The RSS AI Task Force was established to be the strategic group planning the RSS's work on AI, and has been busy over the past few months. The Chair, Donna Philips, was recently interviewed to explain why the task force is so important.
The task force delivers its work through four sub-groups: Policy and Ethics; Evaluation of AI; Practitioner and Communications. The aims of each sub-group are:
Policy and Ethics: lead the development of the RSS AI policy work, build relationships with policy makers and influence the development of AI policy
Evaluation of AI models: ensure that the RSS can guide the field in better quantifying the performance and impact of AI models, alongside helping members to build more resilient, reliable and responsible AI models
Practitioners: encourage AI practitioners to join the RSS, support their professional development and represent and amplify their voice.
Communications: communicate and amplify the work of the task force to members, the media and to the wider public.
Over the next six to nine months, the task force plans to build our work across our priority areas of policy, ethics, evaluation and supporting practitioners and will be engaging more with RSS members. If you would like to engage directly with the task force, then please do email at aitf@rss.org.uk.
It’s not too late to submit a talk or poster to the RSS 2025 conference!
Many congratulations to our Chair, Janet Bastiman who was recently involved in the United Nations 69th on the prevention of human trafficking, sharing insights on AI’s power in identifying illicit financial flows.
Martin Goodson, CEO and Chief Scientist at Evolution AI, continues to run the excellent London Machine Learning meetup and is very active with events. The next event is on Wednesday, April 16th when Max Bartolo, Researcher at Cohere, will present Building Robust Enterprise-Ready Large Language Models - this will be in-person, so well worth going along! Videos are posted on the meetup youtube channel.

This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
We all know the AI capabilities landscape is changing rapidly while governments and regulators attempt to keep up and figure out where and how AI should be governed.
This is a useful comparison of regulatory approaches across the world from GradientFlow
Each region has developed distinctively different approaches reflecting their values and priorities: - EU: Implements a structured, comprehensive framework with clear risk categories and corresponding requirements. The approach prioritizes user rights, transparency, and oversight before deployment. - US: Takes a decentralized, sector-specific approach where various agencies regulate within their domains. This creates a patchwork of rules that offers flexibility but may lead to inconsistent coverage. - UK: Employs a flexible, sector-specific strategy that allows regulators to tailor requirements for individual industries, promoting agile responses and innovation while risking some regulatory fragmentation. - China: Uses a centralized, state-led model with top-down directives aligned with national priorities. This enables rapid implementation but limits public transparency and independent oversight.Although China is often perceived as a global threat with concerns about AI misuse, it is interesting to see they are in the forefront in some areas. One of the biggest challenges consumers face is identifying whether or not content is AI or human generated so this is welcome: China will enforce clear flagging of all AI generated content starting from September (more here)
"The Chinese Communist Party’s (CCP's) national internet censor just announced that all AI-generated content will be required to have labels that are explicitly seen or heard by its audience and embedded in metadata. The Cyberspace Administration of China (CAC) just released the transcript for the media questions and answers (akin to an FAQ) on its Measures for the Identification of Artificial Intelligence Generated and Synthetic Content [machine translated]. We saw the first signs of this policy move last September when the CAC's draft plans emerged."Of course you can use AI for all sorts of things - People are using Google’s new AI model to remove watermarks from images
Meanwhile over in the US, Trump has already signalled rolling back what limited regulations exist, and has asked industry leaders for ideas on governance (talk about the fox guarding the henhouse…)
Not surprisingly, those industry leaders have plenty of ideas! Here is OpenAI’s response (summary here)
"We propose a holistic approach that enables voluntary partnership between the federal government and the private sector" ... "We propose a copyright strategy that would extend the system’s role into the Intelligence Age by protecting the rights and interests of content creators while also protecting America’s AI leadership and national security. The federal government can both secure Americans’ freedom to learn from AI, and avoid forfeiting our AI lead to the PRC by preserving American AI models’ ability to learn from copyrighted material.Do you think this might have influenced their request? “Judge allows authors’ AI copyright lawsuit against Meta to move forward”
"In Kadrey vs. Meta, authors — including Richard Kadrey, Sarah Silverman, and Ta-Nehisi Coates — have alleged that Meta has violated their intellectual property rights by using their books to train its Llama AI models and that the company removed the copyright information from their books to hide the alleged infringement."Content creators have come out in force against such proposals: “Hollywood unites against AI: 400 celebs demand Trump take action on OpenAI, Google”. I wonder who Trump will side with??
Meanwhile, AI’s slow but steady penetration of military activities persists: It begins: Pentagon to give AI agents a role in decision making, ops planning
“The value of the contract, awarded as part of the US Defense Innovation Unit's Thunderforge project, wasn't specified, though given its considerable scope it's likely to be a large one. According to data labeling and AI training outfit Scale today, the contract will see it leading a team including Palmer Luckey's Anduril and Copilot-obsessed Microsoft to implement the US Department of Defense's "first foray into integrating AI agents in and across military workflows."”Anthropic continues to showcase its activities around AI safety, through it’s Red Teaming: Progress from our Frontier Red Team “In Capture The Flag (CTF) exercises — cybersecurity challenges that involve finding and exploiting software vulnerabilities in a controlled environment — Claude improved from the level of a high schooler to the level of an undergraduate in just one year.” And OpenAI is doing similar things here.

As we talk about every month, open ai models are becoming increasingly powerful and accessible. But just how “open” are they?: ‘Open’ AI model licenses often carry concerning restrictions
“The restrictive and inconsistent licensing of so-called ‘open’ AI models is creating significant uncertainty, particularly for commercial adoption,” Nick Vidal, head of community at the Open Source Initiative, a long-running institution aiming to define and “steward” all things open source, told TechCrunch. “While these models are marketed as open, the actual terms impose various legal and practical hurdles that deter businesses from integrating them into their products or services.”Finally, there is increasing concern about the AI benchmarks used to assess how good the different models are:
Did xAI lie about Grok 3’s benchmarks?
"xAI’s graph showed two variants of Grok 3, Grok 3 Reasoning Beta and Grok 3 mini Reasoning, beating OpenAI’s best-performing available model, o3-mini-high, on AIME 2025. But OpenAI employees on X were quick to point out that xAI’s graph didn’t include o3-mini-high’s AIME 2025 score at “cons@64.”“These benchmarks themselves deserve as much scrutiny as the models, argue seven researchers from the European Commission's Joint Research Center in their paper, "Can We Trust AI Benchmarks? An Interdisciplinary Review of Current Issues in AI Evaluation." Their answer is not really."

Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
We were just talking about benchmarks and their struggle to stay relevant- researchers are always on the lookout for new approaches
Not just hard but “extra-hard”: BIG-Bench Extra Hard
"One particular exception is the BIG-Bench dataset, which has served as a crucial benchmark for evaluating the general reasoning capabilities of LLMs, thanks to its diverse set of challenging tasks that allowed for a comprehensive assessment of general reasoning across various skills within a unified framework. However, recent advances in LLMs have led to saturation on BIG-Bench, and its harder version BIG-Bench Hard (BBH). State-of-the-art models achieve near-perfect scores on many tasks in BBH, thus diminishing its utility. To address this limitation, we introduce BIG-Bench Extra Hard (BBEH), a new benchmark designed to push the boundaries of LLM reasoning evaluation."An interesting, more theoretical, approach: The KoLMogorov Test: Compression by Code Generation
"A theoretically optimal way to compress any sequence of data is to find the shortest program that outputs that sequence and then halts. However, such 'Kolmogorov compression' is uncomputable, and code generating LLMs struggle to approximate this theoretical ideal, as it requires reasoning, planning and search capabilities beyond those of current models. In this work, we introduce the KoLMogorov-Test (KT), a compression-as-intelligence test for code generating LLMs. In KT a model is presented with a sequence of data at inference time, and asked to generate the shortest program that produces the sequence. We identify several benefits of KT for both evaluation and training: an essentially infinite number of problem instances of varying difficulty is readily available, strong baselines already exist, the evaluation metric (compression) cannot be gamed, and pretraining data contamination is highly unlikely."
One fruitful area of AI research has been in attempting to understand scaling laws- what improvement in performance can we expect with an x-fold improvement in model size, data, compute etc?
Predictable Scale: Part I -- Optimal Hyperparameter Scaling Law in Large Language Model Pretraining
"Through extensive empirical studies involving grid searches across diverse configurations, we discover universal scaling laws governing these hyperparameters: optimal learning rate follows a power-law relationship with both model parameters and data sizes, while optimal batch size scales primarily with data sizes. Our analysis reveals a convex optimization landscape for hyperparameters under fixed models and data size conditions. "And this is a slightly different approach geared towards reasoning models (those which take more time to iterate towards a final solution): Measuring AI Ability to Complete Long Tasks
"Despite rapid progress on AI benchmarks, the real-world meaning of benchmark performance remains unclear. To quantify the capabilities of AI systems in terms of human capabilities, we propose a new metric: 50%-task-completion time horizon. This is the time humans typically take to complete tasks that AI models can complete with 50% success rate. We first timed humans with relevant domain expertise on a combination of RE-Bench, HCAST, and 66 novel shorter tasks. On these tasks, current frontier AI models such as Claude 3.7 Sonnet have a 50% time horizon of around 50 minutes. Furthermore, frontier AI time horizon has been doubling approximately every seven months since 2019, though the trend may have accelerated in 2024.And this indicates that distributed training (a very hard problem but potentially necessary at scale) is viable- Communication-Efficient Language Model Training Scales Reliably and Robustly: Scaling Laws for DiLoCo
"In this work, we study the scaling law behavior of DiLoCo when training LLMs under a fixed compute budget. We focus on how algorithmic factors, including number of model replicas, hyperparameters, and token budget affect training in ways that can be accurately predicted via scaling laws. We find that DiLoCo scales both predictably and robustly with model size. When well-tuned, DiLoCo scales better than data-parallel training with model size, and can outperform data-parallel training even at small model sizes."
Another hot topic on the research front is improving inference efficiency- how quickly you can get a response from the model.
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
"In this paper, we introduce EAGLE-3, which abandons feature prediction in favor of direct token prediction and replaces reliance on top-layer features with multi-layer feature fusion via a technique named training-time test. These improvements significantly enhance performance and enable the draft model to fully benefit from scaling up training data."I mean you have to be impressed by the name alone- ThunderKittens


And another LLM style approach to time-series: SeqFusion: Sequential Fusion of Pre-Trained Models for Zero-Shot Time-Series Forecasting. I’m intrigued by the idea of these, but no idea if they work any better than traditional approaches!
"Instead of collecting diverse pre-training data, we introduce SeqFusion in this work, a novel framework that collects and fuses diverse pre-trained models (PTMs) sequentially for zero-shot forecasting. Based on the specific temporal characteristics of the target time series, SeqFusion selects the most suitable PTMs from a batch of pre-collected PTMs, performs sequential predictions, and fuses all the predictions while using minimal data to protect privacy."This looks impressive- building reasoning into multi-modal models: LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL

Building specialised models for specific tasks can still be a very successful strategy- this is pretty impressive: Dereflection Any Image
with Diffusion Priors and Diversified Data

Finally, this release from a firm called Inception Labs showcases a new and potentially ground breaking approach: “Introducing Mercury, the first commercial-scale diffusion large language model”. The underlying theory is based on these papers (here and here) and there’s an excellent explainer from Devansh here
"models run at most at 200 tokens per second, we can serve Mercury Coder on commodity NVIDIA H100s at speeds of over 1000 tokens per second, a 5x increase. Compared with some frontier models, which can run at less than 50 tokens per second, we offer a more than 20X speedup. The throughput achieved by dLLMs was previously achievable only using specialized hardware, such as Groq, Cerebras, and SambaNova. Our algorithmic improvements are orthogonal to hardware acceleration and speedups would compound on faster chips."


Generative AI ... oh my!
Still moving at such a fast pace it feels in need of it's own section, for developments in the wild world of large language models...
It’s clear that the recent DeepSeek releases (covered in previous newsletters) is having a lasting impact with the realisation that frontier models can be trained for much less money than the current incumbents are spending. And everyone is playing catch-up
“Distillation is quite magical,” said Olivier Godement, head of product for OpenAI’s platform. “It’s the process of essentially taking a very large smart frontier model and using that model to teach a smaller model . . . very capable in specific tasks that is super cheap and super fast to execute.”Despite this, OpenAI continues to deliver impressive capabilities, doubling down on its proprietary models, although it now has by far the most expensive offerings
OpenAI’s o1-pro is the company’s most expensive AI model yet - details here
They also broaden their offering with new tools for audio, image and agent building

Google keeps up the pace
Lots of AI surfacing in Google products and consumer offerings:
They also released an updated open source model: Introducing Gemma 3: The most capable model you can run on a single GPU or TPU, as well as an updated embedding model
And barely a month after releasing Gemini 2.0, they have released their new “thinking” model, Gemini 2.5 which looks to be highly performant
"The Gemini family of models have capabilities that set them apart from other models: - Long context length—Gemini 2.5 Pro supports up to 1 million tokens - Audio input—something which few other models support, certainly not at this length and with this level of timestamp accuracy - Accurate bounding box detection for image inputs My experiments so far with these capabilities indicate that Gemini 2.5 Pro really is a very strong new model. I’m looking forward to exploring more of what it can do."
As we reported last month, Anthropic released their latest model Claude 3.7 Sonnet and are also now flush with cash, having raised $3.5 billion at a $61.5 billion post-money valuation. They also had a win, with OpenAI adopting their Model Context Protocol (MCP) standard to connecting agents to tools.
Amazon added new AI powered features to their recommendations, finally managed to upgrade Alexa onto frontier models (apparently their own Nova model as well as Anthropics’ Claude), and is reportedly developing their own reasoning model
At least Amazon got Alexa over the line- Apple still hasn’t managed to upgrade Siri and is suffering for it - this highlights how hard it is to build integrated AI applications!
Mistral released a specialised Optical Character Recognition API
And Cohere continues to produce impressive models focused on the enterprise/agent space: Command A and Aya Vision
But in many ways the big news continues to be in the open source world
DeepSeek is still very much in the news :
DeepSeek's open-source week and why it's a big deal - lots of detail into how they achieved their results
And another all conquering release- their upgraded V3 model. Remember GPT4.5 and Claude Sonnet 3.7 have only just been released themselves so the lead time between leading commercial and open source models has almost evaporated.
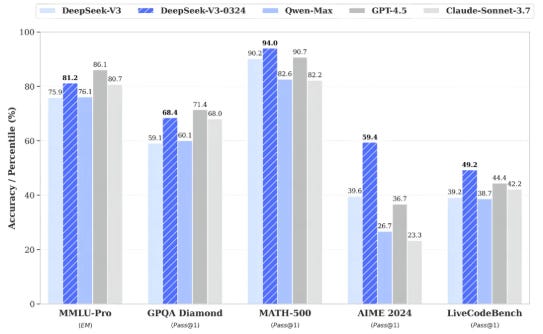
And it’s not just DeepSeek- other Chinese AI firms are producing equally impressive models
New kid on the block- Manus AI: The Best Autonomous AI Agent Redefining Automation and Productivity
Alibaba Released Babel: An Open Multilingual Large Language Model LLM Serving Over 90% of Global Speakers; they also released a free AI video generation model; and a new open source small model that is up there with the best- Qwen2.5-VL-32B
And not to be outdone, Baidu released ERNIE 4.5 and Reasoning Model ERNIE X1
NVIDIA released a new family of reasoning models: Llama Nemotron
And if you feel like you want your own video generation model, check out Open-Sora; or how about your own local coding assistant: OlympicCoder

Real world applications and how to guides
Lots of applications and tips and tricks this month
Some interesting practical examples of using AI capabilities in the wild
First of all, our obligatory robot update: Google’s new robot AI can fold delicate origami, close zipper bags without damage

Google and Microsoft have been busy with broader applications of their research
Google releases SpeciesNet, an AI model designed to identify wildlife

AI weather forecasting just took a big step forward
- What sets Aardvark Weather apart — and may usher in a new era in AI-driven models — is that it uses a single machine-learning model that takes in observations from satellites, weather stations, ships and other sensors, and yields high-resolution global and local forecasts. - It doesn't involve traditional numerical weather models at any step of the process, setting it apart from other new AI systems.Microsoft’s new Dragon Copilot is an AI assistant for healthcare
MatterGen: A new paradigm of materials design with generative AI

Sakana keeps delivering intriguing innovations:
Amazing! - The AI Scientist Generates its First Peer-Reviewed Scientific Publication

Although not without controversy: “Sakana claims its AI-generated paper passed peer review — but it’s a bit more nuanced than that”
"In the blog post, Sakana admits that its AI occasionally made “embarrassing” citation errors, for example incorrectly attributing a method to a 2016 paper instead of the original 1997 work. Sakana’s paper also didn’t undergo as much scrutiny as some other peer-reviewed publications. Because the company withdrew it after the initial peer review, the paper didn’t receive an additional “meta-review,” during which the workshop organizers could have in theory rejected it."
I’ll admit- I’m “slightly” addicted to duolingo- cool to see behind the scenes: Using generative AI to scale DuoRadio 10x faster
"During our initial testing, we realized that adding more constraints on our generative AI prompts didn’t work well. Instead, feeding existing content from our learning curriculum delivered far better results as it gave our generative AI model specific patterns to follow (as opposed to more complex instructions). By supplying the prompts with well-crafted sentences and exercises created by our Learning Designers for Duolingo lessons, it was possible to generate a large volume of promising scripts (level-appropriate, grammatically sound, using the correct vocabulary, etc.). But we hold a high-quality bar at Duolingo, and while much of that output was good, some of it wasn't. To filter out only the best scripts for our learners, our Learning Designers crafted effective prompts that assessed the outputs for naturalness, grammaticality, coherence, logic, and other key learning criteria. And just like magic, the scripts that passed through those filters met our quality standards and showed us a clear path to rapidly scale DuoRadio."
Lots of great tutorials and how-to’s this month
Eugene Yan is always worth reading: Improving Recommendation Systems & Search in the Age of LLMs
"Recommendation models are increasingly adopting language models and multimodal content to overcome traditional limitations of ID-based approaches. These hybrid architectures include content understanding alongside the strengths of behavioral modeling, addressing the common challenges of cold-start and long-tail item recommendations."All about the python:
Poking Around Claude Code - how to get it setup, and how best to use it
I’ve found coding with these AI coding assistants definitely speeds me up, but how I use them is continually evolving, as they still make very basic errors. Excellent post from Simon Willison on how he uses them: Here’s how I use LLMs to help me write code
"Using LLMs to write code is difficult and unintuitive. It takes significant effort to figure out the sharp and soft edges of using them in this way, and there’s precious little guidance to help people figure out how best to apply them. If someone tells you that coding with LLMs is easy they are (probably unintentionally) misleading you. They may well have stumbled on to patterns that work, but those patterns do not come naturally to everyone. I’ve been getting great results out of LLMs for code for over two years now. Here’s my attempt at transferring some of that experience and intution to you."I do love geospatial data! Geospatial Python Tutorials
And if you are new to Python, this is a good resource: Python Developer Tooling Handbook
This is a great little experiment/tutorial: Teaching Language Models to Solve Sudoku Through Reinforcement Learning
"Sudoku presents a fascinating challenge for language models. Unlike open-ended text generation, solving a Sudoku puzzle requires: - Following strict rules (each row, column, and box must contain numbers 1-9 without repetition) - Maintaining a consistent grid format - Applying step-by-step logical reasoning - Understanding spatial relationships between grid elements - Arriving at a single correct solution What makes this particularly interesting is that language models aren’t designed for structured problem-solving. They’re trained to predict text, not to follow logical rules or maintain grid structures. Yet with the right approach, they can learn these skills."Excellent primer on statistical tests: Common statistical tests are linear models (or: how to teach stats)- highlighting the underlying relationships between the different tests I’ve found to be really useful (click on the image for the pdf cheatsheet)

A couple of follow ups from last month-
We talked about XGBoost - how about training a model in the browser!
And Part 2 of the TrueSkill algorithm







Practical tips
How to drive analytics, ML and AI into production
Message queues are great right? Not all the time- When Kafka is not the right Move
When designing distributed systems, event streaming platforms such as Kafka are the preferred solution for asynchronous communication. In fact, on Kafka’s official website, the first use-case listed is messaging1. My believe is that this default choice can lead to problems and unnecessary complexity. The main reason for this is the conversion between state and events, which we’ll look at in this article through a game of chess.LLMOps Is About People Too: The Human Element in AI Engineering
When teams deploy generative AI, it's easy to focus solely on models, pipelines, and frameworks—and overlook the human factors critical to success. Misaligned executive expectations, resistance from subject-matter experts, and ineffective team structures often pose greater challenges than the technology itselfExcellent summary of data validation tools from friend of the newsletter (Arthur Turrell): - The data validation landscape in 2025
"In my experience, there are broadly two types of analytical work that public sector institutions undertake. One is ad hoc analysis, the other is regular production of statistics. In the latter case, data validation is extremely helpful because you want to know whether there are problems with, say, the latest data you’ve ingested before it goes to senior leaders or, even worse, is published externally. But even for ad hoc data analysis, if it’s on a standard dataset that is ingested, say, every month, you probably do want to have data validation checks so you’re not caught out by an anomaly that you misinterpret as a real effect."Finally - Defense Against Dishonest Charts - great pointers on how to make charts readable and honest!
Bigger picture ideas
Longer thought provoking reads - sit back and pour a drink! ...
The Physicist Working to Build Science-Literate AI - Quanta Magazine
"The biggest challenge, if you abstract away everything, is that machine learning is bad at “out-of-distribution” prediction. That means that if you have a new data point that’s unlike anything you’ve seen before, a machine learning model will tend to do badly. This is the major weakness of machine learning, compared to traditional science."AI Slop Is a Brute Force Attack on the Algorithms That Control Reality - Jason Koebler
"Any of these Reels could have been and probably was made in a matter of seconds or minutes. Many of the accounts that post them post multiple times per day. There are thousands of these types of accounts posting thousands of these types of Reels and images across every social media platform. Large parts of the SEO industry have pivoted entirely to AI-generated content, as has some of the internet advertising industry. They are using generative AI to brute force the internet, and it is working."Doctors Told Him He Was Going to Die. Then A.I. Saved His Life - Kate Morgan
"The lifesaving drug regimen wasn’t thought up by the doctor, or any person. It had been spit out by an artificial intelligence model. In labs around the world, scientists are using A.I. to search among existing medicines for treatments that work for rare diseases. Drug repurposing, as it’s called, is not new, but the use of machine learning is speeding up the process — and could expand the treatment possibilities for people with rare diseases and few options."Gemma 3, OLMo 2 32B, and the growing potential of open-source AI - Nathan Lambert
"I was poking through the results for our latest model when I realized that we finally did it! We have a fully open-source GPT-4 class model, i.e., it is comparable with OpenAI's original release rather than the current version. Today, we're releasing OLMo 2 32B, the biggest model we've trained from scratch yet. Here are the post-training evaluations, where it surpasses GPT-3.5, GPT-4o-mini, Qwen 2.5 32B Instruct, the recent Mistral Small 24B, and comes close to the Qwen and Llama 70B Instruct models.”Is it still worth learning to code? Yes! - Andrew Ng
"In the 1960s, when programming moved from punchcards (where a programmer had to laboriously make holes in physical cards to write code character by character) to keyboards with terminals, programming became easier. And that made it a better time than before to begin programming. Yet it was in this era that Nobel laureate Herb Simon wrote the words quoted in the first paragraph. Today’s arguments not to learn to code continue to echo his comment."The Challenges and Upsides of Using AI in Scientific Writing - IEEE Spectrum
"A unified effort within the academic community is needed to ensure that AI in scientific writing is used responsibly to enhance critical thinking, not replace it. This concept aligns with the broader vision of augmented artificial intelligence, advocating for the collaboration between human judgment and AI toward ethical technology development and applying the same principles to scientific writing."LLMs in medicine: evaluations, advances, and the future - Tanishq Mathew Abraham
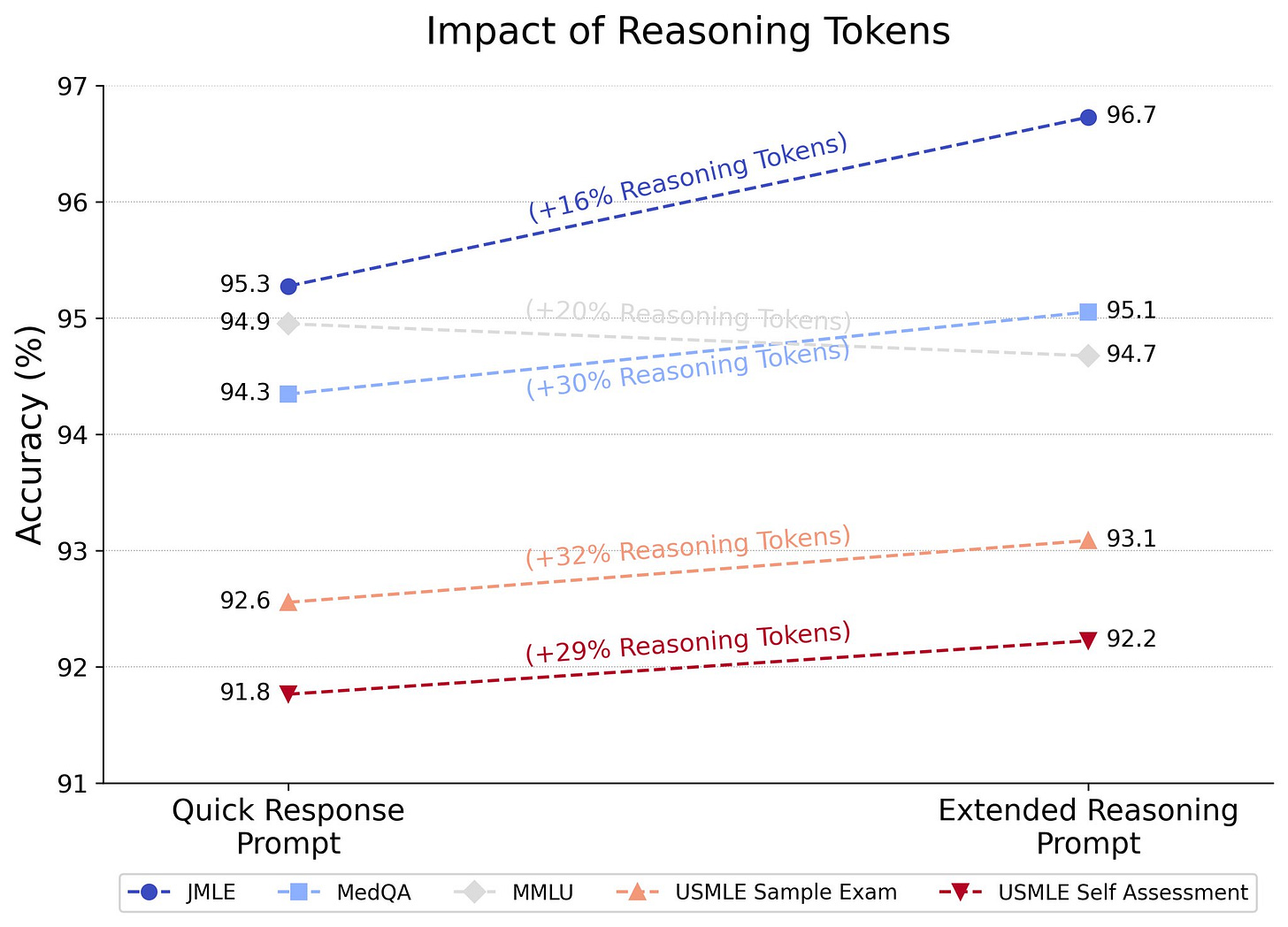
How AI Takeover Might Happen in 2 Years - joshc
"I’m not a natural “doomsayer.” But unfortunately, part of my job as an AI safety researcher is to think about the more troubling scenarios. I’m like a mechanic scrambling last-minute checks before Apollo 13 takes off. If you ask for my take on the situation, I won’t comment on the quality of the in-flight entertainment, or describe how beautiful the stars will appear from space. I will tell you what could go wrong. That is what I intend to do in this story."Finally, a couple of good posts from Ethan Mollick
Speaking things into existence
"Influential AI researcher Andrej Karpathy wrote two years ago that “the hottest new programming language is English,” a topic he expanded on last month with the idea of “vibecoding” a practice where you just ask an AI to create something for you, giving it feedback as it goes. I think the implications of this approach are much wider than coding, but I wanted to start by doing some vibecoding myself."

Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
One or Two? How Many Queues? - very applied queue theory!
"The other day, I was up at Crystal Mountain, and needed to visit the ahem facilities. In the base lodge there, the men’s room includes a bank of urinals, and a row of stalls. As men’s rooms often do. What it also features is a long queue at rush hour, and a sharp corner before its possible to see which of the facilities are occupied. The result is a queue with a mix of folks waiting for urinals and stalls, and often under-utilization of the urinals (because the person at the head of the queue is waiting on a stall). Single queue, lower utilization, longer waits."How Many Episodes Should You Watch Before Quitting a TV Show? A Statistical Analysis

Finally - a fun data set to explore: OpenTimes: Free travel times between U.S. Census geographies


Updates from Members and Contributors
Mark Rogers at GroundedAI, highlights what looks like a very useful application for academic authors and publishers:
“Grounded AI working with Hum have a new piece of software which automates citation checking for academic publishers - Veracity. The first customer is the American Institute of Physics Publishing. The software uses search and LLMs to check:
- Is the citation accurate in its details?
- Does the paper cited support the claim made?
- Is it a self-citation part of a citation ring?
It's handy for authors - checking their work for errors, for peer reviewers, identifying issues and for publishers who want to keep an eye on quality.”
Arthur Turrell, Senior Manager Research and Data at the Bank of England, published an excellent blog post on his new Cookiecutter Python packages- looks well worth checking out and includes ‘ultramodern tooling’ like ruff, uv and quartodoc
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
Interesting new role - at Prax Value (a dynamic European startup at the forefront of developing solutions to identify and track 'enterprise intelligence'): Applied Mathematics Engineer
Two Lead AI Engineers in the Incubator for AI at the Cabinet Office- sounds exciting (other adjacent roles here)!
2 exciting new machine learning roles at Carbon Re- excellent climate change AI startup
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS