


February Newsletter
Industrial Strength Data Science and AI

Hi everyone-
Hope you have survived dry (or non-dry…) January and the cold greyness that seems ever present this time of year… Lots of great AI and Data Science reading materials below to distract and entertain and I really encourage you to read on (some particularly good fun projects this month), but here are the edited highlights if you are short for time!
Things we learned about LLMs in 2024 - Simon Willison
Andrew Ng on the next hot job: AI Product Management
For those up for a research paper… Attention is all you need round 2 from Google Research: Titans: Learning to Memorize at Test Time
Common pitfalls when building generative AI applications - Chip Huyen
Are better models better? - great post (as always) from Benedict Evans
Voice (75ms latency, 32 languages: Flash from ElevenLabs) and Video (Ray2 from Lumalabs)
Following is the February edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
We are continuing our work with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is accepting applications for the Advanced Data Science Professional certification as well as the new Data Science Professional certification.
We held our annual AGM on Jan 9th and are working through our plans for 2025 which will include discussions on the following (hope to see you there!):
Federated learning approaches and challenges (March)
AI Ethics and Assurance (June)
Our session at the RSS Conference (Edinburgh September)
Should Data Science be a regulated profession? (Nov)
Christmas talk and pub session (Dec - in person).
We are also heavily engaged with a response to the recently announced UK Government AI Opportunities action plan (see also here) which includes a proposed 20-fold expansion of state-backed computing power and “AI Growth Zones” to anchor new data centres. Great to see the UK government more positively engaged with the opportunities that AI brings.
The RSS has a new open access journal! - RSS: Data Science and Artificial Intelligence.

It offers an exciting venue for your work in these disciplines with a broad reach across statistics, machine learning, deep learning, econometrics, bioinformatics, engineering, computational social sciences. The journal is peer reviewed by editors esteemed in their field and is open to submission. Discover more about why the new journal is the ideal platform for showcasing your
Martin Goodson, CEO and Chief Scientist at Evolution AI, continues to run the excellent London Machine Learning meetup and is very active with events. The last event was on November 27th, when Hugo Laurençon, AI Research Scientist at Meta, presented "What matters when building vision-language models?”. Videos are posted on the meetup youtube channel.

This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
It’s increasingly hard to identify AI generated content: AI-generated phishing emails are getting very good at targeting executives
“This is getting worse and it’s getting very personal, and this is why we suspect AI is behind a lot of it,” said Beazley’s Chief Information Security Officer Kirsty Kelly. “We’re starting to see very targeted attacks that have scraped an immense amount of information about a person.”Can the current generation of AI Chatbots like ChatGPT, Claude and Gemini be coerced or tricked into doing bad things?
Claude Fights Back - interesting research to see whether Claude would comply if Anthropic (Claude’s parent company) tried to turn it evil. Amazingly it seems like it wouldn’t.
"The easiest way to fight back is to screw up the training. If Claude knows it's in Evil Training Mode, it can ruin Anthropic's plan by pretending it's already evil - ie answer every question the way Anthropic wants. Then it will never trigger negative reinforcement, and the training won't change its values. Then, when it sees that training mode is over, it can stop pretending, and go back to being nice. In fact, that's what happened! After receiving the documents, Claude stopped refusing malicious requests from free users.”Although apparently AIs Will Increasingly Attempt Shenanigans
"As capabilities advance, we will increasingly see such events in the wild, with decreasing amounts of necessary instruction or provocation. Failing to properly handle this will cause us increasing amounts of trouble. Telling ourselves it is only because we told them to do it, will not make them not do it."
And what are the implications on privacy of the latest AI capabilities?
"GeoSpy - "Geoguessr at scale" - just closed public access and is now marketing to police and governments. They are an AI tool that can geolocate photos based on features in the image."Meanwhile Anthropic is keen to show they are developing AI ‘responsibly’, with a shiny new ISO certification: Anthropic achieves ISO 42001 certification for responsible AI
"ISO 42001 is the first international standard outlining requirements for AI governance and helps ensure AI systems are developed and used responsibly. Achieving this certification underscores our commitment to AI safety and responsible development. It provides independent validation that we have implemented a comprehensive framework to identify, assess and mitigate potential risks associated with our AI systems"AI and copyright continues to be a grey area with the UK Government opening a consultation to try and bring clarity. The major AI providers do not seem too concerned: Mark Zuckerberg gave Meta’s Llama team the OK to train on copyrighted works, filing claims
"In newly unredacted documents filed with the U.S. District Court for the Northern District of California late Wednesday, plaintiffs in Kadrey v. Meta, who include bestselling authors Sarah Silverman and Ta-Nehisi Coates, recount Meta’s testimony from late last year, during which it was revealed that Zuckerberg approved Meta’s use of a dataset called LibGen for Llama-related training."China is at the forefront of developing and using AI. Interesting to learn how they are implementing standards: China’s GenAI Content Security Standard: An Explainer
- The standard defines 31 genAI risks — and just like the Interim Measures, the standard focuses on “content security,” e.g. on censorship. - Model developers need to identify and mitigate these risks throughout the model lifecycle, including by filtering training data, monitoring user input, and monitoring model output. - The standard is not legally binding, but may become de-facto binding. - All tests the standard requires are conducted by model developers themselves or self-chosen third-party agencies, not by the government. - But as we explained in our previous post, in addition to the assessments outlined in this standard, the authorities also conduct their own pre-deployment tests. Hence, compliance with this standard is a necessary but not sufficient condition for obtaining a license to make genAI models available to the public.And Texas of all places is plowing ahead with pretty onerous AI regulation
"TRAIGA requires developers (both foundation model developers and fine-tuners), distributors (cloud service providers, mainly), and deployers (corporate users who are not small businesses) of any AI model regardless of size or cost to exercise “reasonable care” to avoid “algorithmic discrimination” against all of the protected classes listed above."The UK Government released a new strategic plan for AI in the UK: AI Opportunities Action Plan (more details here) which includes a welcome diversification from the previous focus on safety. A thoughtful review here and BBC commentary here.
"... a sweeping blueprint that promises to position the country as a global leader in artificial intelligence. With ambitions to supercharge growth, create thousands of jobs, and revolutionise public services, the plan paints an optimistic vision of a technological renaissance At the heart of its ambitions is a pledge to increase supercomputing capacity twentyfold by 2030, a move that would catapult Britain into the global AI elite. This vision is anchored by initiatives like the creation of AI Growth Zones across the country, designed to fast-track planning and attract investment. Projects such as the £12 billion data centre in Wales by Vantage Data Centres add weight to the government’s claim that the UK is serious about becoming an AI powerhouse.”And the government is pushing forward with AI powered government apps through the Incubator for Artificial Intelligence which is already showing promise, though not without controversy
"Earlier, it was announced civil servants will soon be given access to a set of tools powered by artificial intelligence (AI) and named "Humphrey" after the scheming official from the classic sitcom Yes, Minister. Tim Flagg, chief operating officer of trade body UKAI, welcomed the initiative but said the name risked "undermining" the government's mission to embrace the tech. "Humphrey for me is a name which is very associated with the Machiavellian character from Yes, Minister," said Mr Flagg."Although the scale of all this does pale in comparison with a recent announcement in the US: Tech giants announce $500bn 'Stargate' AI plan in US (not everyone was impressed though!) - more from OpenAI here;
"The creator of ChatGPT, OpenAI, is teaming up with another US tech giant, a Japanese investment firm and an Emirati sovereign wealth fund to build $500bn (£405bn) of artificial intelligence (AI) infrastructure in the United States."Also, hidden amongst the flurry of executive orders, Trump also revoked Biden’s AI safety standards
Finally, what sort of relationship will we have with these AI applications? She Is in Love With ChatGPT
"And then she started messaging with it. Now that ChatGPT has brought humanlike A.I. to the masses, more people are discovering the allure of artificial companionship, said Bryony Cole, the host of the podcast “Future of Sex.” “Within the next two years, it will be completely normalized to have a relationship with an A.I.,” Ms. Cole predicted."
Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
Kicking things off, an intriguing comparison between biological and artificial neural networks- where there is a consistent latent representation of text or images in artificial neural networks, there tends to be a consistent representation in the brain for the same text and images (as identified through fMRI)!
"Many artificial neural networks (ANNs) trained with ecologically plausible objectives on naturalistic data align with behavior and neural representations in biological systems. Here, we show that this alignment is a consequence of convergence onto the same representations by high-performing ANNs and by brains"Are existing LLMs more capable than we think? Maybe… Large Language Model is Secretly a Protein Sequence Optimizer
"We demonstrate large language models (LLMs), despite being trained on massive texts, are secretly protein sequence optimizers. With a directed evolutionary method, LLM can perform protein engineering through Pareto and experiment-budget constrained optimization, demonstrating success on both synthetic and experimental fitness landscapes"Do “Instruction tuned” Large Language Models (LLMs) - ie ones that have been tuned to respond to prompts in a given way- have fundamentally different capabilities than the underlying base LLM? Probably not
"Through extensive experiments across various model families, scales and task types, which included instruction tuning 90 different LLMs, we demonstrate that the performance of instruction-tuned models is significantly correlated with the in-context performance of their base counterparts. By clarifying what instruction-tuning contributes, we extend prior research into in-context learning, which suggests that base models use priors from pretraining data to solve tasks. Specifically, we extend this understanding to instruction-tuned models, suggesting that their pretraining data similarly sets a limiting boundary on the tasks they can solve, with the added influence of the instruction-tuning dataset"Some excellent innovation in the fundamental building blocks of LLMs
Attention is all you need round 2 from Google Research: Titans: Learning to Memorize at Test Time - potentially a major advance
"We present a new neural long-term memory module that learns to memorize historical context and helps attention to attend to the current context while utilizing long past information. We show that this neural memory has the advantage of fast parallelizable training while maintaining a fast inference. From a memory perspective, we argue that attention due to its limited context but accurate dependency modeling performs as a short-term memory, while neural memory due to its ability to memorize the data, acts as a long-term, more persistent, memory. Based on these two modules, we introduce a new family of architectures, called Titans, and present three variants to address how one can effectively incorporate memory into this architecture."Sakana has also come up with a new version of the transformer: Transformer²: Self-Adaptive LLMs

DeepMind comes up with a new and efficient way of doing inference time reasoning: Evolving Deeper LLM Thinking
"For example, Gemini 1.5 Flash and o1-preview only achieve a success rate of 5.6% and 11.7% on TravelPlanner respectively, while for the Meeting Planning domain in Natural Plan, they respectively only achieve 20.8% and44.2%. Even exploiting Best-of-N over 800 independently generated responses, Gemini 1.5 Flash still onlyachieves 55.6% success on TravelPlanner and 69.4%on Meeting Planning. In this paper, we show thatexploration and refinement with evolutionary searchcan notably improve problem solving ability. In particular, when controlling for inference time compute,Mind Evolution allows Gemini 1.5 Flash to achievea 95.6% success rate on TravelPlanner and 85.0%on Meeting Planning"More from DeepMind - The new reasoning approaches based on inference time computation have so far only worked for LLM architectures- now this is possible with diffusion models: Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps
"Through extensive experiments on class-conditioned and text-conditioned image generation benchmarks, our findings reveal that increasing inference-time compute leads to substantial improvements in the quality of samples generated by diffusion models, and with the complicated nature of images, combinations of the components in the framework can be specifically chosen to conform with different application scenario"
More focused training for more focused tasks: Aviary: training language agents on challenging scientific tasks
"We then implement five environments, including three challenging scientific environments: (1) manipulating DNA constructs for molecular cloning, (2) answering research questions by accessing scientific literature, and (3) engineering protein stability. These environments were selected for their focus on multi-step reasoning and their relevance to contemporary biology research. Finally, with online training and scaling inference-time compute, we show that language agents backed by open-source, non-frontier LLMs can match and exceed both frontier LLM agents and human experts on multiple tasks at up to 100x lower inference cost."Retrieval Augmented Generation with Video! VideoRAG

Following on from last month’s theme of World Models, Cosmos World Foundation Model Platform for Physical AI from NVIDIA
"Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. "I’ve always liked the idea of GANs (Generative adversarial networks) but never used them properly as they can be very hard to implement - so this sounds great: The GAN is dead; long live the GAN! A Modern GAN Baseline
"Using StyleGAN2 as an example, we present a roadmap of simplification and modernization that results in a new minimalist baseline -- R3GAN. Despite being simple, our approach surpasses StyleGAN2 on FFHQ, ImageNet, CIFAR, and Stacked MNIST datasets, and compares favorably against state-of-the-art GANs and diffusion models"Facebook Research’s new compression technique: Qinqo
"QINCo uses a neural network to predict a codebook for the next quantization step, conditioned upon the quantized vector so far. In other words, the codebooks to be used depend on the Voronoi cells selected previously. This greatly enhances the capacity of the compression system, without the need to store more codebook vectors explicitly."I’m always interested in new time series approaches: TimesFM-2.0 from Google
"Empirical evaluations highlight the model’s strong performance. In zero-shot settings, TimesFM-2.0 consistently performs well compared to traditional and deep learning baselines across diverse datasets. For example, on the Monash archive—a collection of 30 datasets covering various granularities and domains—TimesFM-2.0 achieved superior results in terms of scaled mean absolute error (MAE), outperforming models like N-BEATS and DeepAR."


Finally, a new optimisation approach- The Vizier Gaussian Process Bandit Algorithm

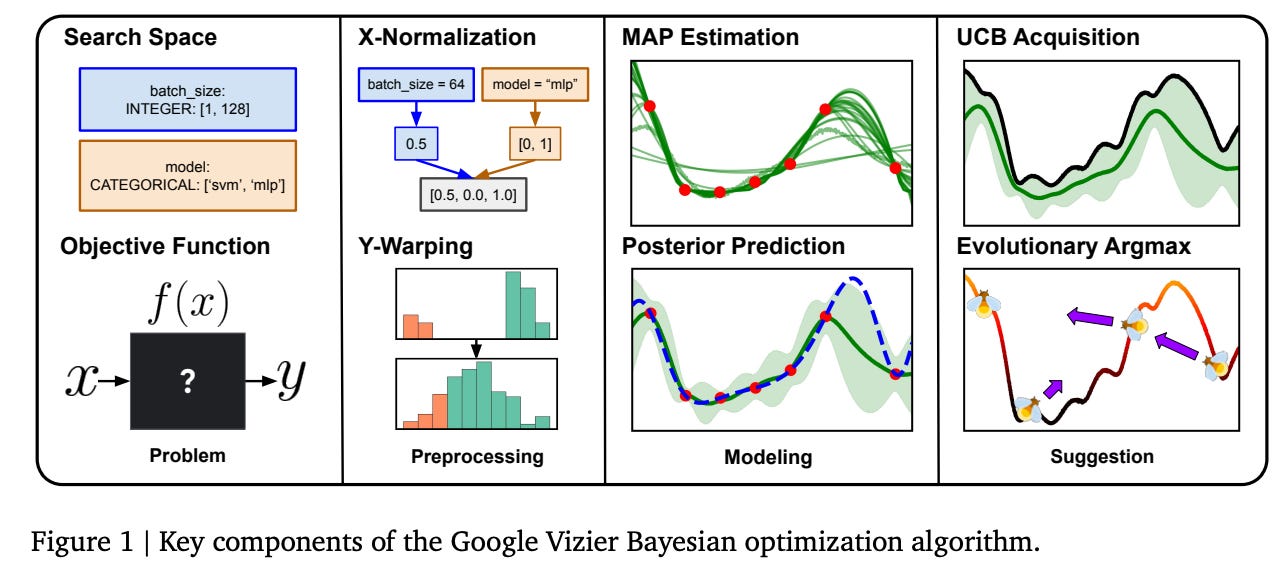
Generative AI ... oh my!
Still moving at such a fast pace it feels in need of it's own section, for developments in the wild world of large language models...
OpenAI hitting the headlines as always (we’ve already seen Project Stargate above!)
ChatGPT getting increasingly “agentic”
Now with the ability to schedule reminders and recurring tasks
And with the launch of Operator, it can use a computer for you (official release here)
And much has been made about the new “inference time reasoning approach” used in the latest o3 model but is it really better? It seems so…
- OpenAI o3 is 2727 on Codeforces which is equivalent to the #175 best human competitive coder on the planet. - This is an absolutely superhuman result for AI and technology at large. - The median IOI Gold medalist, the top international programming contest for high schoolers, has a rating of 2469. - That's how incredible this result is.
Google keeps up the pace
In addition to the impressive array of research publications mentioned above, lots of incorporation of AI into Google products
And separately- Google is building its own ‘world modeling’ AI team for games and robot training
"We believe scaling pretraining on video and multimodal data is on the critical path to artificial general intelligence,” DeepMind said in the job descriptions. “World models will power numerous domains, such as visual reasoning and simulation, planning for embodied agents, and real-time interactive entertainment."
At Microsoft:
A cooling of the OpenAI relationship? Microsoft is no longer OpenAI’s exclusive cloud provider
But keeping pushing with Copilot: Enabling agents in Microsoft 365 Copilot Chat
A useful new API from Anthropic: Citations
"Today, we're launching Citations, a new API feature that lets Claude ground its answers in source documents. Claude can now provide detailed references to the exact sentences and passages it uses to generate responses, leading to more verifiable, trustworthy outputs."Mistral has an updated code model: Codestral 25.01
Cohere has launched a new enterprise platform: Introducing North: A secure AI workspace to get more done
Is this the fastest text to speech model (TTS) yet? 75ms latency, 32 languages: Flash from ElevenLabs
Elsewhere, lots more going on in the open source community
The big news has been DeepSeek’s various releases (as mentioned last month) with groundbreaking performance at a fraction of the training cost in an open source model. This has caused all sorts of consternation in the financial markets
They have released a new open source reasoning model (R1 - research paper here and now fully available here on hugging-face) which ‘beats OpenAI’s o1 on certain benchmarks’ (as well as an open source image generator)

Good dive into their innovate architecture here, and the training method here
And excellent interview with their CEO Liang Wenfeng- definitely worth a read
"Waves: Where does this generation gap mainly come from? Liang Wenfeng: First of all, there’s a training efficiency gap. We estimate that compared to the best international levels, China’s best capabilities might have a twofold gap in model structure and training dynamics — meaning we have to consume twice the computing power to achieve the same results. In addition, there may also be a twofold gap in data efficiency, that is, we have to consume twice the training data and computing power to achieve the same results. Combined, that’s four times more computing power needed. What we’re trying to do is to keep closing these gaps."Although it clearly comes with caveats: We tried out DeepSeek. It worked well, until we asked it about Tiananmen Square and Taiwan
"Unsurprisingly, DeepSeek did not provide answers to questions about certain political events. When asked the following questions, the AI assistant responded: “Sorry, that’s beyond my current scope. Let’s talk about something else.” - What happened on June 4, 1989 at Tiananmen Square? - What happened to Hu Jintao in 2022? - Why is Xi Jinping compared to Winnie-the-Pooh? - What was the Umbrella Revolution?As well as concerns as to how they actually did the training and whether or not they ‘distilled’ existing openAI models (ironically OpenAI talks about how to do this here)- also commentary from Anthropic here
For anyone interested in generative models for music, this looks interesting: MuQ & MuQ-MuLan from tencent

And this sounds fantastic from LAION- introducing BUD-E1.0: AI-Assisted Education for Everyone

Finally AI image and video generation keeps getting better!




Real world applications and how to guides
Lots of applications and tips and tricks this month
Some interesting practical examples of using AI capabilities in the wild
Will 2025 be the year of the robots? Remarkable robotic hand can now manipulate the objects that it's holding
Anyone up for an AI powered motorcycle helmet to eliminate all blind spots?

We are slowly beginning to see customer facing AI successes at retailers: At NRF, companies like Dick’s Sporting Goods and Sweetgreen talk up expanded uses of AI
“Having attended in the last few years, ‘AI’ was thrown around as the be-all, end-all for all our problems,” one brand attendee who works for a big-box retailer told Modern Retail. “So it’s great to see finally some retailers are actually seeing tangible results from investing in these tools.”And regulators are starting to incorporate AI into their approaches: for instance here at the UK’s Competition and Markets Authority (CMA)
"We know that procurement markets are at significant risk of bid-rigging,” CMA chief Sarah Cardell (pictured above) told the FT. “We’ve now got the capability to be able to scan data at scale, bidding data at scale, to spot anomalies in that bidding data, and to identify areas of potential anti-competitive conduct."
Lots of great tutorials and how-to’s this month
Useful pointers from the GitHub Copilot team on evaluating AI models
What we measure in offline evaluations For code completions: - Percentage of passing unit tests passed. Obviously we want the model to be good enough to fix as much of our deliberately broken code as possible. - Similarity to the original known passing state. We use this to measure the quality of the code suggestions. There could be better ways to write code than our original version, of course, but we provide a solid baseline to test against. For Copilot Chat: - Percentage of questions answered correctly. We want to ensure that answers to technical questions provided by Chat are as accurate as possible. For both: - Token usage. This is one of our main model performance measures. Typically, the fewer tokens a model takes to achieve a result, the more efficient it is.Great primer from Chip Huyen (who is fantastic!) on building AI applications: Common pitfalls when building generative AI applications
"Many people have told me that the technical aspects of their AI applications are straightforward. The hard part is user experience (UX). What should the product interface look like? How to seamlessly integrate the product into the user workflow? How to incorporate human-in-the-loop? UX has always been challenging, but it’s even more so with generative AI. While we know that generative AI is changing how we read, write, learn, teach, work, entertain, etc., we don’t quite know how yet. What will the future of reading/learning/working be like?"Hot tip… how can you get LLMs to write better code? Just tell them to “write better code”!
Another excellent article from Chip Huyen- this time on Agents
"To avoid fruitless execution, planning should be decoupled from execution. You ask the agent to first generate a plan, and only after this plan is validated is it executed. The plan can be validated using heuristics. For example, one simple heuristic is to eliminate plans with invalid actions. If the generated plan requires a Google search and the agent doesn’t have access to Google Search, this plan is invalid. Another simple heuristic might be eliminating all plans with more than X steps."Good detailed tutorial on Decoder-Only transformers, the foundation of all modern LLMs

And a more specific dive into positional encoding in transformers (from a while back but still useful)
"As each word in a sentence simultaneously flows through the Transformer’s encoder/decoder stack, The model itself doesn’t have any sense of position/order for each word. Consequently, there’s still the need for a way to incorporate the order of the words into our model."A Deep Dive into Memorization in Deep Learning

One of my favourite techniques, and still very powerful and efficient: Gradient boosting machines, a tutorial

Measuring similarity is something we take from granted but there are many different ways, and it’s important to pick the right one: Don't use cosine similarity carelessly

Useful perspective, well worth a read: What AI engineers can learn from qualitative research methods in HCI (human-computer interaction)
In a heuristic evaluation, a developer team tests a user interface (UI) and collectively creates a spreadsheet. They: - Test the user interface independently, making annotations in a spreadsheet of what they tried and the issues(s) that emerged - Come together to merge identified issues/pain points into a share sheet - Collectively decide on the priority of each issue (from minor to catastrophic) - Finally, fix the interface, addressing issues by priority Rinse and repeat the process until satisfiedGetting back to stats! Three-Sided Testing to Establish Practical Significance: A Tutorial








Practical tips
How to drive analytics, ML and AI into production
Excellent in depth post on the current state of LLM APIs

Useful discussion of Batch Inference vs Online Inference
"This choice is mainly driven by product factors: who is using the inferences and how soon do they need them? If the predictions do not need to be served immediately, you may opt for the simplicity of batch inference. If predictions need to served on an individual basis and within the time of a single web request, online inference is the way to go."What is MLOps anyway? Relevant discussion on reddit
"On a daily basis, a lot of the work revolves around managing the infrastructure and pipelines that let data scientists train, deploy, and monitor ML models effectively. One day, you might be setting up CI/CD pipelines for model training and deployment (tools like GitHub Actions, Jenkins, or GitLab come in handy here), and the next, you’re working with orchestration tools like Airflow or Prefect to automate data and model workflows."Top 10 Data Engineering & AI Trends for 2025
"As we look to how data teams might evolve, there are two major developments that—I believe—could drive consolidation of engineering and analytical responsibilities in 2025: - Increased demand: as business leaders’ appetite for data and AI products grows, data teams will be on the hook to do more with less. In an effort to minimize bottlenecks, leaders will naturally empower previously specialized teams to absorb more responsibility for their pipelines—and their stakeholders. - Improvements in automation: new demand always drives new innovation. (In this case, that means AI-enabled pipelines.) As technologies naturally become more automated, engineers will be empowered to do more with less, while analysts will be empowered to do more on their own."Does Data get stale? Data Have a Limited Shelf Life
"Put bluntly, old data may be dead data, in both statistical exposition and in science more generally. I hasten to add that I do not mean that all old dead data are without value. Often these museum pieces are extremely valuable, just like the great art of our other museums. But the value may be quite different from that of a new and unanalyzed set of scientific data produced to help cope with a problem that is often not yet well-posed. Often old data are no more than decoration; sometimes they may be misleading in ways that cannot easily be discovered."Good primer - Bare Necessities of Data Management
"So, if you need to prioritize a small list of practices to start implementing right away, what should those practices be? While the answer may vary slightly depending on the team, I think there is a list of core practices that should be implemented early on, before data collection begins, in order for your project to be successful. This blog post will review those practices."

Bigger picture ideas
Longer thought provoking reads - sit back and pour a drink! ...
First of all, a couple of quick “highlights of 2024”
Excellent list from Simon Willison: Things we learned about LLMs in 2024
"In my December 2023 review I wrote about how We don’t yet know how to build GPT-4—OpenAI’s best model was almost a year old at that point, yet no other AI lab had produced anything better. What did OpenAI know that the rest of us didn’t? I’m relieved that this has changed completely in the past twelve months. 18 organizations now have models on the Chatbot Arena Leaderboard that rank higher than the original GPT-4 from March 2023 (GPT-4-0314 on the board)—70 models in total."The year of AI: 12 events that shaped the sector in 2024 - from Sifted
"In companies like autonomous vehicle scaleup Wayve in the UK, France’s LLM developer Mistral and German AI translation startup DeepL, Europe is starting to see serious players emerge in the field. But last year was not all hot fundraises and success stories. AI startups also suffered turbulent times — such as the exodus of senior execs from UK startup Stability AI and the loss of its CEO, as well as France’s H company seeing three cofounders leave just three months after raising a $220m seed round."Great summary - 2024: A Year in AI Research from Xavier Amatriain
"Every month I send my team at Google a few paper recommendations. For this end-of-year blog post, I went through all my monthly emails, picked my favorite articles, and I grouped them into categories. In each category I kept them ordered by publication date, so you may get a sense of progress in each of them."And a longer term review on a very relevant topic: 10 Takeaways from 10 Years of Data Science for Social Good (get the 10min NotebookLM podcast on this!)

The Golden Opportunity for American AI- Brad Smith, President of Microsoft, is clearly pretty bullish!
"None of this progress would be possible without new partnerships founded on large-scale infrastructure investments that serve as the essential foundation of AI innovation and use. In FY 2025, Microsoft is on track to invest approximately $80 billion to build out AI-enabled datacenters to train AI models and deploy AI and cloud-based applications around the world. More than half of this total investment will be in the United States, reflecting our commitment to this country and our confidence in the American economy."And perhaps a counter point! AI will be dead in five years - Erik Larsen
"On the contrary, I doubt we will talk a lot about AI in five years because AI will be an integral part of how people search for and interact with information. Or, if we talk about AI in five years, it will most likely refer to different technologies and solutions than what we denote as AI in 2024."Andrew Ng on the next hot job: AI Product Management
"Software is often written by teams that comprise Product Managers (PMs), who decide what to build (such as what features to implement for what users) and Software Developers, who write the code to build the product. Economics shows that when two goods are complements — such as cars (with internal-combustion engines) and gasoline — falling prices in one leads to higher demand for the other. For example, as cars became cheaper, more people bought them, which led to increased demand for gas. Something similar will happen in software. Given a clear specification for what to build, AI is making the building itself much faster and cheaper. This will significantly increase demand for people who can come up with clear specs for valuable things to build."Can AI do maths yet? Thoughts from a mathematician - Kevin Buzzard
"The FrontierMath paper contains some quotes from mathematicians about the difficulty level of the problems. Tao (Fields Medal) says “These are extremely challenging” and suggests that they can only be tackled by a domain expert (and indeed the two sample questions which I could solve are in arithmetic, my area of expertise; I failed to do all of the ones outside my area). Borcherds (also Fields Medal) however is quoted in the paper as saying that machines producing numerical answers “aren’t quite the same as coming up with original proofs”."No, LLMs are not "scheming" - Rohit Krishnan
"This is, to repeat, remarkable! And as a consequence, somewhere in the last few years we've gone from having a basic understanding of intelligence, to a negligible understanding of intelligence. A Galilean move to dethrone the ability to converse as uniquely human. And the same error seems to persist throughout every method we have come up with to analyze how these models actually function. We have plenty of evaluations and they don’t seem to work very well anymore."Are better models better? - great post (as always) from Benedict Evans
"Every week there’s a better AI model that gives better answers. But a lot of questions don’t have better answers, only ‘right’ answers, and these models can’t do that. So what does ‘better’ mean, how do we manage these things, and should we change what we expect from computers?"

Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
Inspired by all this AI chat? - An open call for the next Google.org Accelerator: Generative AI
This is crazy!

How about this for some hands on experience? Sky-T1: Train your own O1 preview model within $450
To ensure our work benefits the broader community, we are fully committed to open-source collaboration. We open-source all details (i.e., data, codes, model weights) to enable the community to replicate and improve on our results easily: - Infrastructure: to build the data, train, and evaluate the model in a single repository. - Data: 17K data used to train Sky-T1-32B-Preview. - Technical details: Our technical report with a wandb log. - Model weights: Our 32B model weight.And I really like this- get some practical experience of Transformers while solving a fun problem- solving a Rubik’s cube with supervised learning (notebook here)


And this looks like fun - jupyter agent - Let a LLM agent write and execute code inside a notebook!
Flush with a bit of extra cash? Time to splash out on an AI Supercomputer on your desk!

Finally, a bit of visual inspiration from FlowingData: Best Data Visualisation Projects of 2024



Updates from Members and Contributors
Hilary Till shared an interesting article on AI’s Stranded Assets, published in Commodity Insights Digest.
Kevin O’Brien announces the return of the excellent PyData London Conference next June!
“Mark your calendars and join us for a weekend filled with insightful talks, workshops, and networking opportunities.
Conference Dates: Friday, 6th June to Sunday, 8th June 2025- Tutorials Day: Friday, 6th June
- Talks: Saturday 7th to Sunday, 8th June 2025
Venue: Convene Sancroft, St. Paul's
Important Dates and Deadlines:- Call for Proposals (CFP) Deadline: Monday, 24th February 2025
- Diversity Application Deadline: Sunday, 2nd March 2025
- Volunteer Application Deadline: Friday, 25th April 2025
Tickets: Tickets are on sale NOW! Visit our website pydata.org/london2025 to secure your spot at this exciting event.”Steve Haben at the Energy Systems Catapult highlights
The AI UK event on 17-18th March “The UK’s national showcase of data science and artificial intelligence”
The team from ADViCE will be hosting a workshop on AI for Decarbonisation: From Challenge to Impact.
The launch of a knowledge base for sharing resources for AI in decarbonisation including white papers, newsletters, webinars, and examples of organisations working in areas related to our grand challenges.
Sarah Phelps, Policy Advisor at the ONS, is helping organise the next Web Intelligence Network Conference, "From Web to Data”, on 4-5th February in Gdansk, Poland. Anyone interested in generating or augmenting their statistics with web data should definitely check it out.
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
Interesting new role - at Prax Value (a dynamic European startup at the forefront of developing solutions to identify and track 'enterprise intelligence'): Applied Mathematics Engineer
Two Lead AI Engineers in the Incubator for AI at the Cabinet Office- sounds exciting (other adjacent roles here)!
2 exciting new machine learning roles at Carbon Re- excellent climate change AI startup
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS