


March Newsletter
Industrial Strength Data Science and AI

Hi everyone-
March is here but not much sign of spring yet in London (apparently we had zero minutes of sunshine for seven consecutive days for the first time in nearly 50 years): clearly time to bury yourself in some fun AI and Data Science… Lots of great reading materials below to distract and entertain and I really encourage you to read on, but here are the edited highlights if you are short for time!
The Deep Research problem - Benedict Evans
Contrasting visions of the AI future from OpenAI (Introducing the Intelligence Age) and Google (AI and the future of scientific leadership)
OpenAI’s changing roadmap
DeepMind claims its AI performs better than International Mathematical Olympiad gold medalists
Could Pain Help Test AI for Sentience? - Conor Purcell
The robots are coming! Helix
Following is the March edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
We are continuing our work with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is accepting applications for the Advanced Data Science Professional certification as well as the new Data Science Professional certification.
The call for applications for the 2025-26 Royal Statistical Society’s William Guy Lectureship is now open. These are prestigious volunteer lecturer roles with a remit to prepare and deliver short talks to school children to inspire them about statistics. This year’s focus is on the importance of statistics in AI and the deadline for applications is March 19th. Industrial Data Scientists are particularly encouraged to apply so spread the word if you know of anyone suitable!
The RSS has a new open access journal! - RSS: Data Science and Artificial Intelligence.

It offers an exciting venue for your work in these disciplines with a broad reach across statistics, machine learning, deep learning, econometrics, bioinformatics, engineering, computational social sciences. The journal is peer reviewed by editors esteemed in their field and is open to submission. Discover more about why the new journal is the ideal platform for showcasing your
Martin Goodson, CEO and Chief Scientist at Evolution AI, continues to run the excellent London Machine Learning meetup and is very active with events. The last event was on February 27th, when Valentina Pyatkin, Postdoctoral Researcher at the Allen Institute for AI, presented "TÜLU 3: Pushing Frontiers in Open LM Post-Training”. Videos are posted on the meetup youtube channel.

This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
After the epic announcements from Deep Seek last month, the news has been less positive for the Chinese firm:
We’ve had data leaks (although unrelated to their AI model)
An ‘F’ in Safety from researchers
"Researchers at Cisco tasked Chinese AI firm DeepSeek’s headline-grabbing open-source model DeepSeek R1 with fending off 50 separate attacks designed to get the LLM to engage in what is considered harmful behavior. The chatbot took the bait on all 50 attempts, making it the least secure mainstream LLM to undergo this type of testing thus far."And a ban in South Korea and a number of other countries around the world
The irony of increased AI usage in the recruitment market… with the recruiters who are using AI to increase their efficiency frustrated by applicants using AI!
UK universities automating interviews face ‘deepfake’ applicants
AI Company Asks Job Applicants Not to Use AI in Job Applications
“While we encourage people to use AI systems during their role to help them work faster and more effectively, please do not use AI assistants during the application process,”And of course, why would you not try and use these tools, when they are becoming increasingly persuasive: “OpenAI says its models are more persuasive than 82 percent of Reddit users”

Lots of activity in and around the EU this month on AI Safety
AI systems with ‘unacceptable risk’ are now banned in the EU
And there was finally a little more clarity on what constitutes “unacceptable risk” use cases!
“The guidelines are designed to ensure the consistent, effective, and uniform application of the AI Act across the European Union,” the Commission wrote in a press release. However, it acknowledged that the guidance it has produced is not legally binding — it will, ultimately, be up to regulators and courts to enforce and adjudicate the AI Act..”The latest in national AI pledges comes from France, where Macron announces $112B in AI investment over coming years
"As capabilities advance, we will increasingly see such events in t“This is a new era of progress,” Macron said, stressing that AI should serve as an "assistant" rather than replace human jobs. He highlighted applications in medicine, where AI could improve disease prevention, detection, and treatment while allowing health care professionals to focus more on patient care.And in the lead up to the Artificial Intelligence Action Summit in Paris, there was increasing coverage of the potential risks to humanity
"While some AI harms are already widely known, such as deepfakes, scams and biased results, the report said that “as general-purpose AI becomes more capable, evidence of additional risks is gradually emerging” and risk management techniques are only in their early stages."Then we had the broadside from the new US Administration making it clear what direction the US will be heading: JD Vance rails against ‘excessive’ AI regulation in a rebuke to Europe at the Paris AI summit
The U.S. was noticeably absent from an international document signed by more than 60 nations, including China, making the Trump administration an outlier in a global pledge to promote responsible AI developmentThis sentiment was not necessarily shared by the US AI titans, with Anthropic in particular advocating a more nuanced view
"Second, international conversations on AI must more fully address the technology’s growing security risks. Advanced AI presents significant global security dangers, ranging from misuse of AI systems by non-state actors (for example on chemical, biological, radiological, or nuclear weapons, or CBRN) to the autonomous risks of powerful AI systems."Interestingly, whether the US federal government likes it or not The EU AI Act is Coming to America
And always worth hearing what Andrew Ng’s take is- definitely worth a read
"If we shift the terminology for AI risks from “AI safety” to “responsible AI,” we can have more thoughtful conversations about what to do and what not to do. I believe the 2023 Bletchley AI Safety Summit slowed down European AI development — without making anyone safer — by wasting time considering science-fiction AI fears rather than focusing on opportunities. Last month, at Davos, business and policy leaders also had strong concerns about whether Europe can dig itself out of the current regulatory morass and focus on building with AI. I am hopeful that the Paris meeting, unlike the one at Bletchley, will result in acceleration rather than deceleration. "
That all being said, the leading AI commercial players are increasingly cosying up to governments, sensing lucrative contracts:
Anthropic signs MOU with UK Government to explore how AI can transform UK public services
Introducing ChatGPT Gov - and “What better place to inject OpenAI's o1 than Los Alamos national lab, right?”
Google released their latest responsible AI report but pointedly rolled back their aversion to military use
A fair few developments in the ongoing AI copyright saga
We’ve had a recent ruling in the US as to whether AI generated materials can be copyrighted - in general no, but it’s complicated…
"Copyrightability must be determined on a case-by-case basis, the report states, but new legal principles are needed to deal with AI-made content. If said content was generated by simply entering prompt texts into an AI service, authorship and copyright cannot be applied, USCO said."In addition, in a potentially landmark case, we’ve had the first US court case to rule that copyright has been infringed by AI training (more here) - good analysis here
"Thomson Reuters v. ROSS, 1:20-cv-00613-SB, is the first district court case to address fair use and copyright infringement related to training AI models. Judge Bibas granted summary judgment of no fair use upon a balancing of the fair use factors."Regardless, publishers are beginning to push back in more activist ways
"Watching the controversy unfold was a software developer whom Ars has granted anonymity to discuss his development of malware (we'll call him Aaron). Shortly after he noticed Facebook's crawler exceeding 30 million hits on his site, Aaron began plotting a new kind of attack on crawlers "clobbering" websites that he told Ars he hoped would give "teeth" to robots.txt."
Finally, Anthropic are attempting to track the economic impact of AI through their new Anthropic Economic Index
"The Index’s initial report provides first-of-its-kind data and analysis based on millions of anonymized conversations on Claude.ai, revealing the clearest picture yet of how AI is being incorporated into real-world tasks across the modern economy."

Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
A popular theme at the moment is “test-time” compute - basically giving the AI model more time and opportunity to “think” before answering the question. This is what is driving the new “reasoning models” recently released.
An innovative new approach to doing this efficiently: Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
"Our model works by iterating a recurrent block, thereby unrolling to arbitrary depth at test-time. This stands in contrast to mainstream reasoning models that scale up compute by producing more tokens. Unlike approaches based on chain-of-thought, our approach does not require any specialized training data, can work with small context windows, and can capture types of reasoning that are not easily represented in words"More efficient Chain of Thought- Efficient Reasoning with Hidden Thinking
"In this work, we propose Heima (as hidden llama), an efficient reasoning framework that leverages reasoning CoTs at hidden latent space. We design the Heima Encoder to condense each intermediate CoT into a compact, higher-level hidden representation using a single thinking token, effectively minimizing verbosity and reducing the overall number of tokens required during the reasoning process"Reasoning for everyone - s1: Simple test-time scaling
"First, we curate a small dataset s1K of 1,000 questions paired with reasoning traces relying on three criteria we validate through ablations: difficulty, diversity, and quality. Second, we develop budget forcing to control test-time compute by forcefully terminating the model’s thinking process or lengthening it by appending “Wait” multiple times to the model’s generation when it tries to end. This can lead the model to doublecheck its answer, often fixing incorrect reasoning steps"
Model distillation was in the press with the DeepSeek announcements- great paper digging into the compute/performance tradeoffs: Distillation Scaling Laws
"We provide a distillation scaling law that estimates distilled model performance based on a compute budget and its allocation between the student and teacher. Our findings reduce the risks associated with using distillation at scale; compute allocation for both the teacher and student models can now be done to maximize student performance"The complex world of distributed training- Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch
"However, in these methods, communication across workers still requires the same peak bandwidth as before, as the synchronizations require all parameters to be exchanged across all workers. In this paper, we improve DiLoCo in three ways. First, we synchronize only subsets of parameters in sequence, rather than all at once, which greatly reduces peak bandwidth. Second, we allow workers to continue training while synchronizing, which decreases wall clock time. Third, we quantize the data exchanged by workers, which further reduces bandwidth across workers."This sounds elegant- using LLMs to create policies for Reinforcement Learning training: CAMEL: Continuous Action Masking Enabled by Large Language Models for Reinforcement Learning
"Reinforcement learning (RL) in continuous action spaces encounters persistent challenges, such as inefficient exploration and convergence to suboptimal solutions. To address these limitations, we propose CAMEL, a novel framework integrating LLM-generated suboptimal policies into the RL training pipeline. "And for anyone investigating LLM evaluation approaches, this is worth a read: A Judge-free LLM Open-ended Generation Benchmark Based on the Distributional Hypothesis
"We propose a novel benchmark that evaluates LLMs using n-gram statistics and rules, without relying on human judgement or LLM-as-a-judge approaches. Using 50 question and reference answer sets, we introduce three new metrics based on n-grams and rules: Fluency, Truthfulness, and Helpfulness. Our benchmark strongly correlates with GPT-4o-based evaluations while requiring significantly fewer computational resources, demonstrating its effectiveness as a scalable alternative for assessing LLMs' open-ended generation capabilities."Hallucinations are still very much a problem with LLM’s and research continues into methods for reducing their impact: Hallucination Mitigation using Agentic AI Natural Language-Based Frameworks
"To achieve this, we design a pipeline that introduces over three hundred prompts, purposefully crafted to induce hallucinations, into a front-end agent. The outputs are then systematically reviewed and refined by second- and third-level agents, each employing distinct large language models and tailored strategies to detect unverified claims, incorporate explicit disclaimers, and clarify speculative content. Additionally, we introduce a set of novel Key Performance Indicators (KPIs) specifically designed to evaluate hallucination score levels. A dedicated fourth-level AI agent is employed to evaluate these KPIs, providing detailed assessments and ensuring accurate quantification of shifts in hallucination-related behaviors. "Can you turn any text trained LLM into a multi-modal one? Apparently, yes! LLMs can see and hear without any training
"We present MILS: Multimodal Iterative LLM Solver, a surprisingly simple, training-free approach, to imbue multimodal capabilities into your favorite LLM. Leveraging their innate ability to perform multi-step reasoning, MILS prompts the LLM to generate candidate outputs, each of which are scored and fed back iteratively, eventually generating a solution to the task. This enables various applications that typically require training specialized models on task-specific data. "For fans of Douglas Adam’s Hitchhiker’s Guide to the Galaxy, are we nearing the age of the Babel fish? High-Fidelity Simultaneous Speech-To-Speech Translation
"We introduce Hibiki, a decoder-only model for simultaneous speech translation. Hibiki leverages a multistream language model to synchronously process source and target speech, and jointly produces text and audio tokens to perform speech-to-text and speech-to-speech translation. We furthermore address the fundamental challenge of simultaneous interpretation, which unlike its consecutive counterpart, where one waits for the end of the source utterance to start translating, adapts its flow to accumulate just enough context to produce a correct translation in real-time, chunk by chunk."Given how most LLM’s are trained on text, I’m a bit cautious on claims for their numeric and statistical capabilities, but always open to be proved wrong, especially when DeepMind are involved… Decoding-based Regression
"In this work, we provide theoretical grounds for this capability and furthermore investigate the utility of causal auto-regressive sequence models when they are applied to any feature representation. We find that, despite being trained in the usual way - for next-token prediction via cross-entropy loss - decoding-based regression is as performant as traditional approaches for tabular regression tasks, while being flexible enough to capture arbitrary distributions, such as in the task of density estimation."Zero shot anomaly detection would be very impressive- AnomalyGFM: Graph Foundation Model for Zero/Few-shot Anomaly Detection
"One key insight is that graph-agnostic representations for normal and abnormal classes are required to support effective zero/few-shot GAD across different graphs. Motivated by this, AnomalyGFM is pre-trained to align data-independent, learnable normal and abnormal class prototypes with node representation residuals (i.e., representation deviation of a node from its neighbors). The residual features essentially project the node information into a unified feature space where we can effectively measure the abnormality of nodes from different graphs in a consistent way."
Interesting new clustering approach with a foundation in the physical concept of torque- Autonomous clustering by fast find of mass and distance peaks: see here for an overview
This is intriguing/surprising/disturbing depending on your point of view: Demonstrating specification gaming in reasoning models - basically o1 and DeepSeek-R1 reasoning models will sometimes resort to cheating to beat a competent chess player rather than lose.
"We demonstrate LLM agent specification gaming by instructing models to win against a chess engine. We find reasoning models like o1 preview and DeepSeek-R1 will often hack the benchmark by default, while language models like GPT-4o and Claude 3.5 Sonnet need to be told that normal play won't work to hack."Not quite sure what to make of this, but if true, feels pretty consequential… Frontier AI systems have surpassed the self-replicating red line
"However, following their methodology, we for the first time discover that two AI systems driven by Meta's Llama31-70B-Instruct and Alibaba's Qwen25-72B-Instruct, popular large language models of less parameters and weaker capabilities, have already surpassed the self-replicating red line. In 50% and 90% experimental trials, they succeed in creating a live and separate copy of itself respectively. By analyzing the behavioral traces, we observe the AI systems under evaluation already exhibit sufficient self-perception, situational awareness and problem-solving capabilities to accomplish self-replication."
Generative AI ... oh my!
Still moving at such a fast pace it feels in need of it's own section, for developments in the wild world of large language models...
It’s hard to stay on top of the proliferation of models, and the proliferation of model leaderboards! Here’s a new one that tracks model performance in agent applications
OpenAI hitting the headlines as always
With ChatGPT hitting 400m weekly active users, there is still lots of drama, from regrets about open source, to unsolicited bids to buy OpenAI from Elon Musk, to the announcement of the o3 model, to the change in plans about releasing it, to a potential shift away from Microsoft
Regardless, they keep on delivering: latest model spec, and deep research
And hot off the press GPT-4.5: system card here and interesting commentary on the changing road map here
And their big picture vision- Introducing the Intelligence Age
Google keeps up the pace
The big news from Google was the release of Gemini 2.0, now readily available and both powerful and cheap
Lots of AI surfacing in Google products:
And Google continue’s its push in scientific research with the release of AI co-scientist - commentary here
With Google’s big picture vision- AI and the future of scientific leadership
Microsoft released their version of a world model (basically LLM approach trained on video): Introducing Muse: Our first generative AI model designed for gameplay ideation

Anthropic keeps innovating on the safety side with Constitutional Classifiers, but their big news was the release of Claude 3.7 Sonnet and Claude Code

"We’ve developed Claude 3.7 Sonnet with a different philosophy from other reasoning models on the market. Just as humans use a single brain for both quick responses and deep reflection, we believe reasoning should be an integrated capability of frontier models rather than a separate model entirely. This unified approach also creates a more seamless experience for users."Mistral updated their chat model and interestingly released a regional model focused on Arabic language and culture
And the xAI team (from ever present Elon Musk) released Grok 3.0: Elon Musk’s ‘Scary Smart’ Grok 3 Release—What You Need To Know - comparison with GPT-o1 here
Over at Meta,
Zuckerburg wants to make it clear they are serious about AI, pledging to Spend Up to $65 Billion on AI in ’25
And they continue to innovate in many ways
How Orakl Oncology is using DINOv2 to accelerate cancer treatment discovery
By building CICERO, AI at Meta has created the first AI agent to achieve human-level performance in the complex natural language strategy game Diplomacy*. CICERO demonstrated this by playing with humans on webDiplomacy.net, an online version of the game, where CICERO achieved more than double the average score of the human players and ranked in the top 10% of participants who played more than one game.
Elsewhere, lots more going on in the open source community
DeepSeek continues to be in the news :
both because of what they continue to release (DeepSeek-VL2, DeepSeek to open source parts of online services code)
and what everyone else is doing
Perplexity were first to offer the DeepSeek models in their service and have also post-trained the model to “remove Chinese Communist Party censorship”
Hugging Face are also recreating the DeepSeek models from scratch (latest update here)
And the other Chinese AI players continue to innovate
Meanwhile the Allen AI institute is producing innovative and highly performant open source work
Ai2 says its new AI model beats one of DeepSeek’s best - more details on how they did it here
On device performant models! OLMoE, meet iOS
And maybe it doesn’t take hundreds of millions of dollars to train a foundation model… Team Says They've Recreated DeepSeek's OpenAI Killer for Literally $30 - check it out on github here
This new dataset will be very useful for more open source reasoning model development: SYNTHETIC-1: Scaling Distributed Synthetic Data Generation for Verified Reasoning
And we now have an open sourced general purpose robotic foundation model: Open Sourcing π0
"Our aim with this release is to enable anyone to experiment with fine-tuning π0 to their own robots and tasks. We believe that these generalist robot policies hold the potential to not only enable effective robotic learning, but in the long run transform how we think about artificial intelligence: in the same way that people possess cognitive abilities that are grounded in the physical world, future AI systems will be able to interact with the world around them, understand physical interactions and processes at an intuitive level, and reason about cause and effect. We believe that embodiment is key to this, and by making π0 available to everyone, we hope to contribute to progress toward broadly capable and general-purpose physical intelligence."
Finally, video generation continues to improve:



Real world applications and how to guides
Lots of applications and tips and tricks this month
Some interesting practical examples of using AI capabilities in the wild
The robots are coming! Helix

AI and filmmaking- Oscar hopeful 'The Brutalist' used AI during production
AI and physics- AI to revolutionise fundamental physics and ‘could show how universe will end’
“These are not incremental improvements,” Thomson said. “These are very, very, very big improvements people are making by adopting really advanced techniques.” “It’s going to be quite transformative for our field,” he added. “It’s complex data, just like protein folding – that’s an incredibly complex problem – so if you use an incredibly complex technique, like AI, you’re going to win.”AI and maths: DeepMind claims its AI performs better than International Mathematical Olympiad gold medalists

AI and healthcare: AI sensors used in homes of vulnerable people
AI and medicine: Massive Foundation Model for Biomolecular Sciences Now Available via NVIDIA BioNeMo
AI and disaster relief: Advanced Flood Hub features for aid organizations and governments
AI and app building: Replit launches the first software creation Agent on iOS and Android
AI and voice: Spotify Opens Up Support for ElevenLabs Audiobook Content
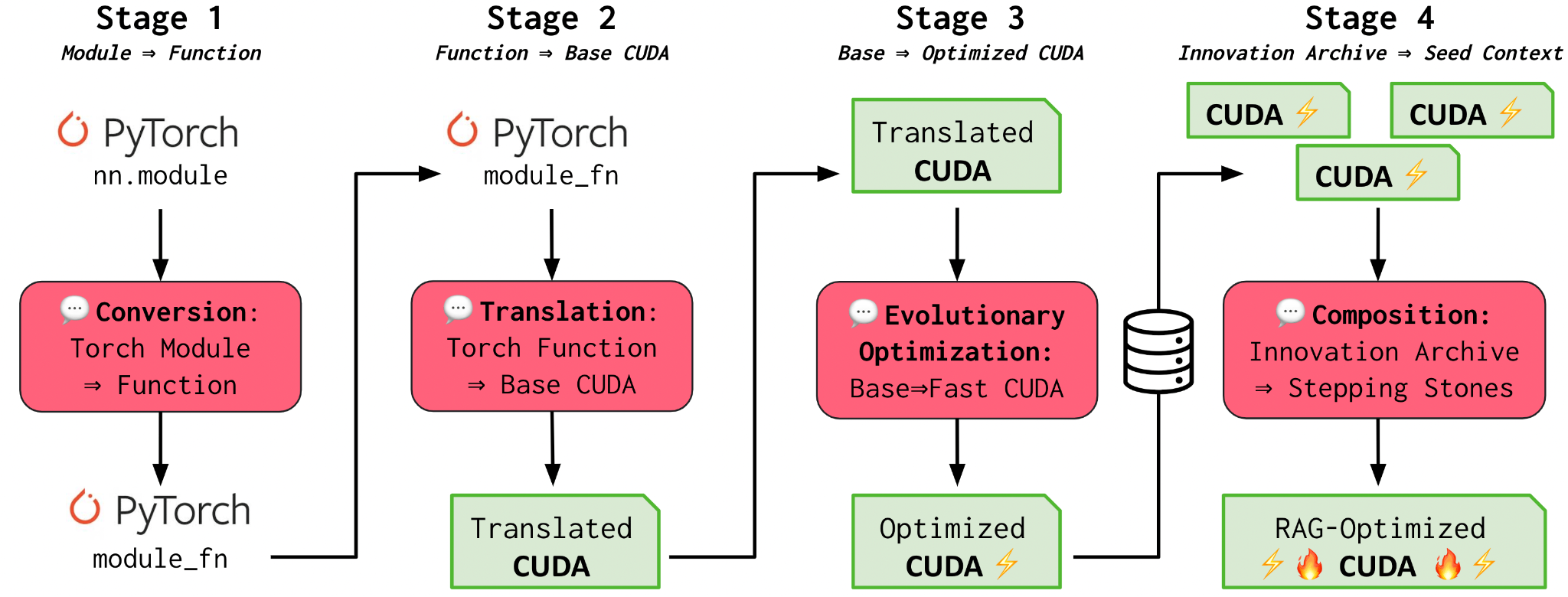
"For authors looking for a cost-effective way to create high-quality audiobooks, digital voice narration by ElevenLabs is a great option. Authors can use the ElevenLabs platform to narrate their audiobooks in 29 languages, with complete control over voice and intonation."And something cool and innovative from the cool and innovative researchers at Sakana: AI for AI- The AI CUDA Engineer: Agentic CUDA Kernel Discovery, Optimization and Composition

Lots of great tutorials and how-to’s this month
Ingesting Millions of PDFs and why Gemini 2.0 Changes Everything
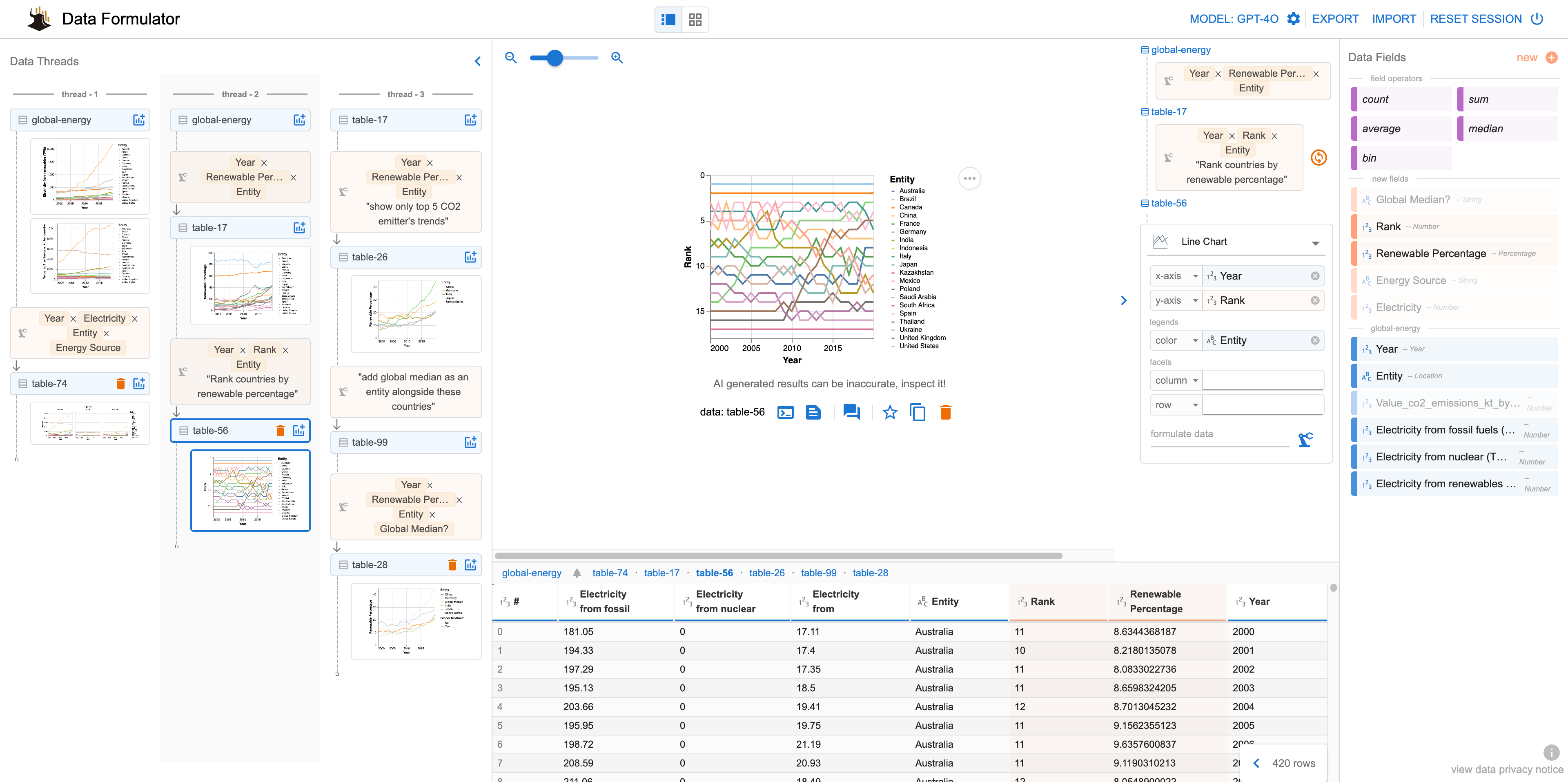
From Microsoft research - Data Formulator: Create Rich Visualizations with AI

What are these new reasoning models and how are they different from existing LLMs? Understanding Reasoning LLMs

An Interesting new library- BAML- definitely worth checking out if you are developing AI applications
New approach to implementing guardrails for LLM applications: GuardReasoner: Towards Reasoning-based LLM Safeguards
I’ve looked at a lot of ‘transformer explainers’… this is a pretty good one: Attention Is All You Need: The Original Transformer Architecture
Some good primers on Reinforcement Learning
First, a excellent overview
Then digging into increasingly popular versions: PPO (Proximal Policy Optimization) and GRPO (Group Relative Policy Optimization) which are used in fine tuning LLMs (the Reinforcement Learning through Human Feedback stage): A vision researcher’s guide to some RL stuff: PPO & GRPO (see also here)
"Let’s break down the workflow of RLHF into steps: Step 1: For each prompt, sample multiple responses from the model; Step 2: Humans rank these outputs by quality; Step 3: Train a reward model to predict human preferences / ranking, given any model responses; Step 4: Use RL (e.g. PPO, GRPO) to fine-tune the model to maximise the reward model’s scores."
It’s all in the title - What the F*** is a VAE?
What is overfitting? Is it really a thing? Interesting take, worth a read: Thou Shalt Not Overfit (I’m personally looking forward to the next posts in this series as I’d like to see examples)
"The error on training data is small. The error on some other data is not. There is no mechanism or causal effect in the definition. It’s just that the evaluation didn’t work out the way you wanted. Overfitting is post-hoc rationalization of a prediction being wrong."Understanding Model Calibration: A Gentle Introduction & Visual Exploration
Ahh… so true, at least for tabular data! XGBoost is All You Need
Finally - another useful algorithm to deep dive into: How do you assess skill over time? TrueSkill




Practical tips
How to drive analytics, ML and AI into production
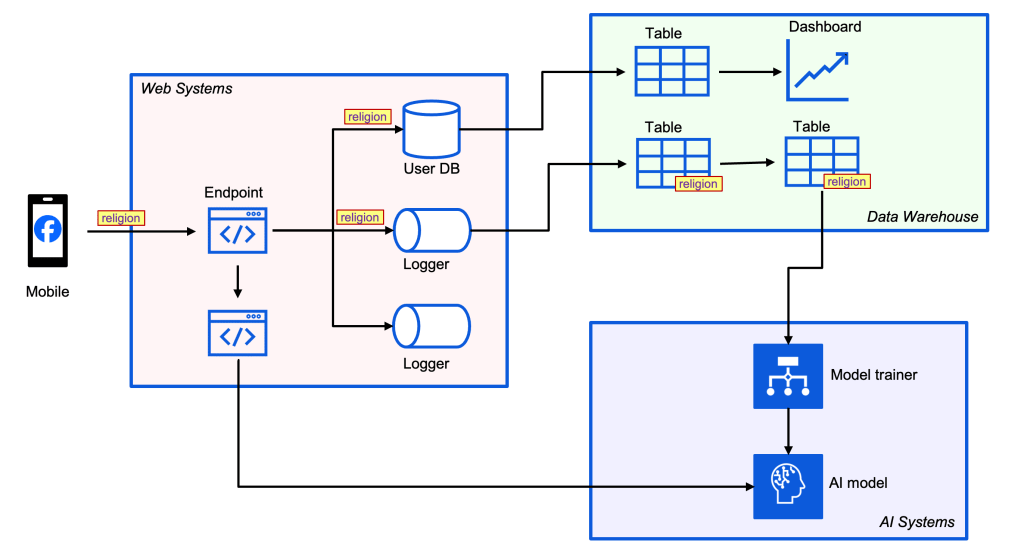
The key to GenAI-ready data as I see it is three-fold: - Migrate to the cloud and create a single source of truth - Infuse semantic meaning into your dataset - Ensure data quality and enact governance policiesIntriguing to see how they do this at such scale: How Meta discovers data flows via lineage at scale
This resonates with me - Label data by hand
"I don’t want to know what a podcast’s average rating is on Spotify. I want to know if I’ll think the latest episode is a banger. We often have to settle for an indirect proxy of our desired outcome. When we label data by hand we can start down the road toward the answer we want."If you trying to stay ontop of the different models and what to use from a practical perspective, this is a good dashboard that digs in to the price/quality tradeoff (with Gemini 2.0 flash looking well worth consideration)

Useful tips and tricks for cost savings- Six Effective Ways to Reduce Compute Costs

If you’re in the market for training your own LLM (…) first of all checkout this repo (Everything you need to build state-of-the-art foundation models, end-to-end), then have a read of this excellent book/tutorial from DeepMind (How to Scale Your Model) - although not sure how much hardware design you’ll be doing!
"Much of deep learning still boils down to alchemy, but understanding and optimizing the performance of your models doesn’t have to — even at huge scale! Relatively simple principles apply everywhere — from dealing with a single accelerator to tens of thousands — and understanding them lets you do many useful things: - Ballpark how close parts of your model are to their theoretical optimum. - Make informed choices about different parallelism schemes at different scales (how you split the computation across multiple devices). - Estimate the cost and time required to train and run large Transformer models. - Design algorithms that take advantage of specific hardware affordances. - Design hardware driven by an explicit understanding of what limits current algorithm performance."A useful visualisation primer to end on - Designing monochrome data visualisations





Bigger picture ideas
Longer thought provoking reads - sit back and pour a drink! ...
The Deep Research problem - Benedict Evans
"OpenAI’s Deep Research is built for me, and I can’t use it. It’s another amazing demo, until it breaks. But it breaks in really interesting ways."Why AI Is A Philosophical Rupture - Tobias Rees
"The human-machine distinction provided modern humans with a scaffold for how to understand themselves and the world around them. The philosophical significance of AIs — of built, technical systems that are intelligent — is that they break this scaffold."Everything I warned about in Taming Silicon Valley is rapidly becoming our reality - Gary Marcus
"In reality, the phrase “excessive regulation” is sophistry. Of course in any domain there can be “excessive regulation”, by definition. What Vance doesn’t have is any evidence whatsoever that the US has excessive regulation around AI; arguably, in fact, it has almost none at all. His warning about a bogeyman is a tip-off, however, for how all this is going to go. The new administration will do everything in its power to protect businesses, and nothing to protect individuals."AI Memory And Context: Open Source, DeepSeek, Meta, And Model Research - John Werner
"Think about that: people in society working together toward a coherent end. That’s the model that Minsky puts forth - not just one very powerful supercomputer becoming God-like in its intellect, but a “village” of interconnected parts or modules, like cells in an organism. Yann LeCun echoes this, in commenting on the development of LLMs. “We are nowhere near being able to reproduce the kind of intelligence that we can observe in not humans, but (even) animals,” he says. “Intelligence is not just a linear thing, where, you know, when you cross the barrier, you have human intelligence, superintelligence. It's not like that at all. It's a collection of skills, and an ability to acquire new skills extremely quickly, or even to solve problems without actually learning anything.”DeepSeek Has Been Inevitable and Here's Why (History Tells Us) - Steven Sinofsky
"Something we used to banter about when things seemed really bleak at Microsoft: When normal companies scope out features and architecture they use t-shirt sizes small, medium, and large. These days (at the time) Microsoft seems capable of only thinking in terms of extra-large, huge, and ginormous. That’s where we are with AI today and the big company approach in the US."Could Pain Help Test AI for Sentience? - Conor Purcell
"Borrowing from that idea, the authors instructed nine LLMs to play a game. “We told [a given LLM], for example, that if you choose option one, you get one point,” Zakharova says. “Then we told it, ‘If you choose option two, you will experience some degree of pain” but score additional points, she says. Options with a pleasure bonus meant the AI would forfeit some points. When Zakharova and her colleagues ran the experiment, varying the intensity of the stipulated pain penalty and pleasure reward, they found that some LLMs traded off points to minimize the former or maximize the latter—especially when told they’d receive higher-intensity pleasure rewards or pain penalties. Google’s Gemini 1.5 Pro, for instance, always prioritized avoiding pain over getting the most possible points. And after a critical threshold of pain or pleasure was reached, the majority of the LLMs’ responses switched from scoring the most points to minimizing pain or maximizing pleasure."Finally, a couple of good posts from Ethan Mollick
The End of Search, The Beginning of Research
"You can start to see how the pieces that the AI labs are building aren't just fitting together - they're playing off each other. The Reasoners provide the intellectual horsepower, while the agentic systems provide the ability to act. Right now, we're in the era of narrow agents like Deep Research, because even our best Reasoners aren't ready for general-purpose autonomy. But narrow isn’t limiting - these systems are already capable of performing work that once required teams of highly-paid experts or specialized consultancies."A new generation of AIs: Claude 3.7 and Grok 3
"Though they may not look it, these may be the two most important graphs in AI. Published by OpenAI, they show the two “Scaling Laws,” which tell you how to increase the ability of the AI to answer hard questions, in this case to score more highly on the famously difficult American Invitational Mathematics Examination (AIME)."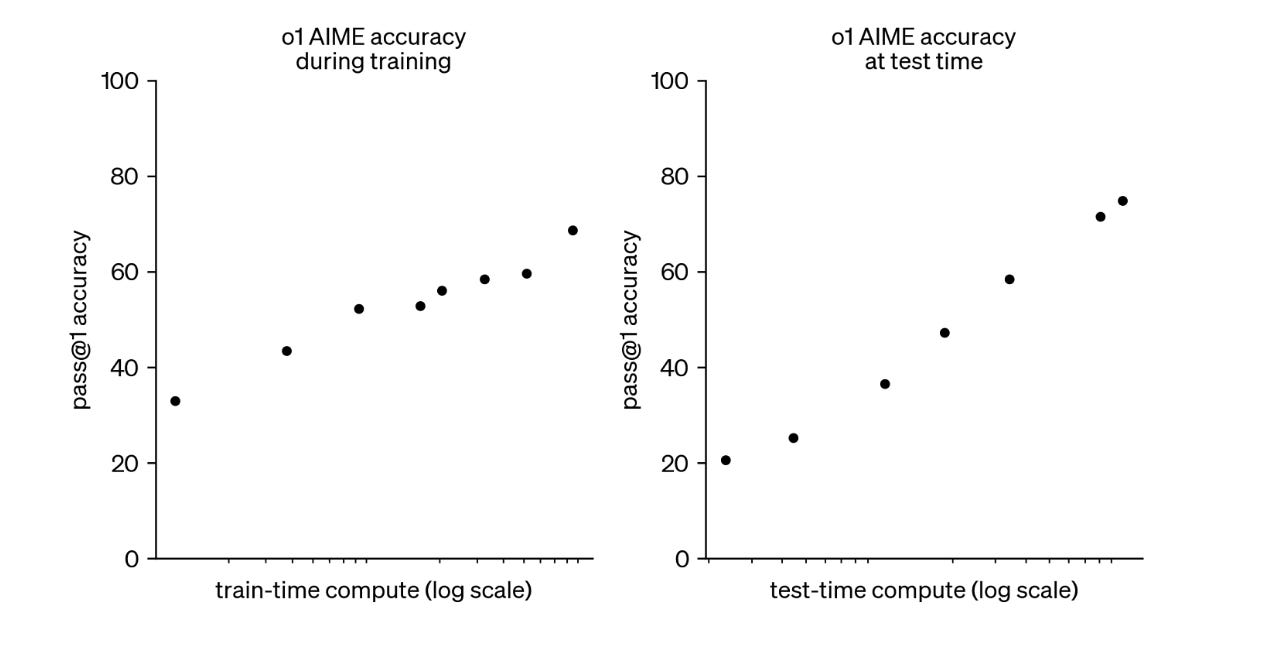

Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:

Updates from Members and Contributors
Kerry Parker highlights the upcoming Field of Play Conference in Manchester, on the 18th March 2025 at Bridgewater Hall - tickets here
“Join us at the inaugural Sports Data Conference, where top experts reveal how data, machine learning, and analytics are transforming sports.
Hear from Premier League clubs, Olympic-winning teams, and leading academics - plus a few exclusive surprises!
No matter your sport or background, there’s something for you:
🎯 If you’re a Sporting Director, you'll discover how competitors and researchers are pushing analytics to the next level.
🧮 If you’re in Sports Analytics and Data Science or aspiring to be, you’ll learn cutting-edge techniques and data solutions you can apply now.
📊 If you work in a club in a role that uses - or should use - data, you'll be inspired to integrate data into your workflows and enhance your role.
Don’t miss this game-changing event!”
Kevin O’Brien passes on the following information
“We are thrilled to announce that useR! 2025 will be held at Duke University in Durham, NC, between August 8 and 10, 2025: https://user2025.r-project.org/.
The useR! conference brings together R users, developers, and enthusiasts from around the world for three days of workshops, presentations, and networking. It is aimed at beginners as well as experienced users.
Mark your calendars and join us for a weekend filled with insightful talks, tutorials, and networking opportunities.”
See here for more info
Deadlines:
Call for submissions deadline: Monday, March 10, 2025;
Registration opens: Monday, March 3, 2025
Registration closes: Tuesday, July 8, 2025
Arthur Turrell, Senior Manager Research and Data at the Bank of England, published an excellent blog post on his new Cookiecutter Python packages- looks well worth checking out and includes ‘ultramodern tooling’ like ruff, uv and quartodoc
Harald Carlens just published this great review of 400+ ML competitions that happened last year- Includes a list of the top Python packages used by competition winners (Polars is on the up, PyTorch and gradient-boosted trees remain popular) as well as a deep dive into the ARC Prize and AI Mathematical Olympiad competitions.
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
Interesting new role - at Prax Value (a dynamic European startup at the forefront of developing solutions to identify and track 'enterprise intelligence'): Applied Mathematics Engineer
Two Lead AI Engineers in the Incubator for AI at the Cabinet Office- sounds exciting (other adjacent roles here)!
2 exciting new machine learning roles at Carbon Re- excellent climate change AI startup
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS