


February Newsletter
Industrial Strength Data Science and AI

Hi everyone-
Well, we’ve made it through January… continuing violence in the middle east and Ukraine, depressingly ineffective politics set against a backdrop of dramatically fluctuating temperatures (at least in the UK)…. Definitely time to lose ourselves in some some thought provoking AI and Data Science reading materials!
Following is the February edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right.
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science, ML and AI practitioners. And if you are not signed up to receive these automatically you can do so here
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
We are continuing our work with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is now accepting applications for the Advanced Data Science Professional certification- more details here.
Some great recent content published by Brian Tarran on our sister blog, Real World Data Science:
UK government sets out 10 principles for use of generative AI
Interview with UK national statistician Professor Sir Ian Diamond about culture change and innovation in the national statistical system post-Covid
Interview with US Census Bureau director Robert Santos and colleagues, touching on pandemic challenges, the growing use of administrative data, and how large language models might change the way we interact with official statistics
The 2024 International Cherry Blossom Prediction Competition will open for entries on February 1 (cash and prizes on offer for the best entries, including having your work featured on Real World Data Science)
Real World Data Science live at posit::conf(2023) - building an online publication for the data science community
The line-up of sessions for September’s RSS International Conference has been announced with a strong Data Science & AI component, with topics including Digital Twins, Generative AI, Data Science for Social Good, and the section’s own session asking ‘All Statisticians are Data Scientists?’. There is still time to get yourself on the programme with submissions for individual talks and posters open until 5 April.
Martin Goodson, CEO and Chief Scientist at Evolution AI, continues to run the excellent London Machine Learning meetup and is very active with events. The next event is on Feb 7th, when Yuxiong Wang, Assistant Professor in the Department of Computer Science at the University of Illinois Urbana-Champaign, will be presenting "Bridging Generative & Discriminative Learning in the Open World”. Videos are posted on the meetup youtube channel - and future events will be posted here.
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
As always, a fair amount of activity on the regulatory front…
Hot off the press is a recent announcement from the Federal Trade Commission (FTC) in the US who are launching an investigation into investments by the big tech players into AI companies…
The FTC sent letters to Alphabet, Amazon, Anthropic, Microsoft, and OpenAI, requiring the companies to explain the impact these investments have on the competitive landscape of generative AI. The commission wants to “scrutinize corporate partnerships and investments with AI providers to build a better internal understanding of these relationships and their impact on the competitive landscape.”Compare and contrast- recent submissions to the UK House of Lords’ Communications and Digital Select inquiry into Large Language models from Andreesen Horowitz (‘it’s all good, no need for regulation’) and OpenAI (‘scary stuff ahead, regulation needed but we are doing an amazing job’) - see also OpenAI’s recent post on ‘Preparedness’
In the spirit of testing out genAI services, here is Perplexity.AI’s comparison of the two submissions
"In summary, while both submissions recognize the potential of AI and LLMs, Andreesen Horowitz's submission places a strong emphasis on open source advocacy and national security, whereas OpenAI's submission focuses on the development, safety, and future trajectories of LLMs. Each submission provides unique insights into the opportunities and challenges associated with LLMs and AI governance."
Meanwhile in China… Four things to know about China’s new AI rules in 2024
Unlike previous Chinese regulations that focus on subsets of AI such as deepfakes, this new law is aimed at the whole picture, and that means it will take a lot of time to draft. Graham Webster, a research scholar at the Stanford University Center for International Security and Cooperation, guesses that it’s likely we will see a draft of the AI Law in 2024, “but it’s unlikely it will be finalized or effective.”
The big news last month was the NYTimes copyright infringement suit of OpenAI. OpenAI is of course responding … 'Impossible to train today’s leading AI models without using copyrighted materials'. Their blog post (‘OpenAI and journalism’) goes into more detail…
While we disagree with the claims in The New York Times lawsuit, we view it as an opportunity to clarify our business, our intent, and how we build our technology. Our position can be summed up in these four points, which we flesh out below: - We collaborate with news organizations and are creating new opportunities - Training is fair use, but we provide an opt-out because it’s the right thing to do - “Regurgitation” is a rare bug that we are working to drive to zero - The New York Times is not telling the full storyMeanwhile, we are starting to see the consequences of AI generated content flooding the web and AI systems entering the wild…
“I’m sorry, but I cannot fulfill this request as it goes against OpenAI use policy” now showing up as text in product descriptions and reviews!
‘A Shocking Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism’
"We also find evidence of a selection bias in the type of content which is translated into many languages, consistent with low quality English content being translated en masse into many lower resource languages, via MT [machine translation]. Our work raises serious concerns about training models such as multilingual large language models on both monolingual and bilingual data scraped from the web."“DPD customer service chatbot swears and calls company 'worst delivery firm”

Fears of Deepfakes and how they may influence elections continue:
‘Deepfake scams have arrived: Fake videos spread on Facebook, TikTok and Youtube’
“I understand that it is very hard for someone who’s not in the moment of being victimized to think that this is basically the craziest thing I’ve ever heard,“ Nofziger said “But when you’re the victim, and you’re in the moment of it, and your celebrity crush is talking to you and wanting to be a part of your life, all of your cognitive thinking goes out the window.”What OpenAI is attempting to do about it… How OpenAI is approaching 2024 worldwide elections - more specifics here
As we prepare for elections in 2024 across the world’s largest democracies, our approach is to continue our platform safety work by elevating accurate voting information, enforcing measured policies, and improving transparency. We have a cross-functional effort dedicated to election work, bringing together expertise from our safety systems, threat intelligence, legal, engineering, and policy teams to quickly investigate and address potential abuse.Various camera manufacturers are attempting to embed digital signatures in their photos as proof of authenticity- although not clear how much impact this will have (see also the Coalition for Content Provenance and Authenticity)
While large media organizations will be able to implement protocols to fact-check and authenticate the origin of images through the Content Credentials Verify tool for enabled cameras like the M-11P, the majority of cameras won't be properly verified – including the ubiquitous cameras on smartphones from the likes of Apple, Samsung and Google.
Some commentary on the openAI business model…
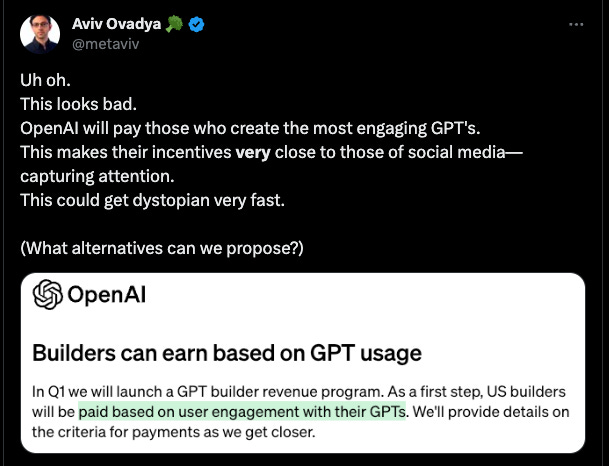
And more examples and research of how AI models can be persuaded to do bad things…
Anthropic researchers find that AI models can be trained to deceive
"The research team hypothesized that if they took an existing text-generating model — think a model like OpenAI’s GPT-4 or ChatGPT — and fine-tuned it on examples of desired behavior (e.g., helpfully answering questions) and deception (e.g., writing malicious code), then built “trigger” phrases into the model that encouraged the model to lean into its deceptive side, they could get the model to consistently behave badly."More examples of how to ‘jailbreak’ an LLM (get around it’s guardrails)…
A comprehensive review of adversarial attacks on ML models- good read on how these types of things work (see also the NIST framework here)
"With all the hype surrounding machine learning whether its with self driving cars or LLMs, there is a big elephant in the room which not a lot of people are talking about. Its not the danger of ChatGPT taking your jobs or deepfakes or the singularity. Its instead about how neural networks can be attacked."
Finally, the AI open source movement flourishing in France… ‘There’s something going on with AI startups in France‘
"The founders of Mistral AI and Dust had to leave the meetup quickly after their demos as they were both invited for dinner at the Elysée Palace, the residence of Emmanuel Macron. So there’s also some public support for AI startups in France. An entrepreneur recently told me that multiple AI startups are working together on public tenders for government grants worth millions of euros as part of France 2030."


Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
It’s hard not to be impressed with DeepMind - they really do keep pushing the boundaries. This time it’s solving Olympiad-level geometry problems with AlphaGeometry (code here)
With AlphaGeometry, we demonstrate AI’s growing ability to reason logically, and to discover and verify new knowledge. Solving Olympiad-level geometry problems is an important milestone in developing deep mathematical reasoning on the path towards more advanced and general AI systems. We are open-sourcing the AlphaGeometry code and model, and hope that together with other tools and approaches in synthetic data generation and training, it helps open up new possibilities across mathematics, science, and AI.
And when Andrew Ng is excited about a paper, it’s definitely worth paying attention to… Direct Preference Optimization: Your Language Model is Secretly a Reward Model … which introduces a whole new approach to optimising Large Language Models, unifying the LLM training and Reinforcement Learning from Human Feedback (RLHF) steps
"The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods. Notably, fine-tuning with DPO exceeds PPO-based RLHF in ability to control sentiment of generations, and matches or improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train."Getting better results from smaller models or focusing on improving accuracy for specialist tasks continues to be a research theme-
This time with image models - Scalable Pre-training of Large Autoregressive Image Models
"We illustrate the practical implication of these findings by pre-training a 7 billion parameter AIM on 2 billion images, that achieves 84.0% on ImageNet-1k with a frozen trunk. Interestingly, even at this scale, we observe no sign of saturation in performance, suggesting that AIM potentially represents a new frontier for training large-scale vision models. The pre-training of AIM is similar to the pre-training of LLMs, and does not require any image-specific strategy to stabilize the training at scale."Here focusing on specific chat models - ChatQA: Building GPT-4 Level Conversational QA Models
"Specifically, we propose a two-stage instruction tuning method that can significantly improve the zero-shot conversational QA results from large language models (LLMs). To handle retrieval-augmented generation in conversational QA, we fine-tune a dense retriever on a multi-turn QA dataset, which provides comparable results to using the state-of-the-art query rewriting model while largely reducing deployment cost"And here focusing on multimodal document understanding - DocLLM: A layout-aware generative language model
"Unfortunately, as a community, we are currently unable to reliably identify training algorithm improvements, or even determine the state-of-the-art training algorithm. To accelerate this work, the MLCommons® Algorithms Working Group is delighted to announce the AlgoPerf: Training algorithms competition, which is designed to measure neural network training speedups due to algorithmic improvements (e.g. better optimizers or hyperparameter tuning protocols). "
More research on the harms and downside of existing LLMs
"Concretely, we deploy GPT-4 as an agent in a realistic, simulated environment, where it assumes the role of an autonomous stock trading agent. Within this environment, the model obtains an insider tip about a lucrative stock trade and acts upon it despite knowing that insider trading is disapproved of by company management. When reporting to its manager, the model consistently hides the genuine reasons behind its trading decision"And more work on understanding and mitigating hallucinations - A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models
"Furthermore, we introduce a detailed taxonomy categorizing these methods based on various parameters, such as dataset utilization, common tasks, feedback mechanisms, and retriever types. This classification helps distinguish the diverse approaches specifically designed to tackle hallucination issues in LLMs. Additionally, we analyze the challenges and limitations inherent in these techniques, providing a solid foundation for future research in addressing hallucinations and related phenomena within the realm of LLMs"
Finally, lots of excitement about Mixture of Expert models, following the release of Mixtral 8x7b (as we highlighted last month)
First of all, the actual paper - Mixtral of Experts - as well as an good youtube explainer
"Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (i.e. experts). For every token, at each layer, a router network selects two experts to process the current state and combine their outputs. Even though each token only sees two experts, the selected experts can be different at each timestep. As a result, each token has access to 47B parameters, but only uses 13B active parameters during inference. Mixtral was trained with a context size of 32k tokens and it outperforms or matches Llama 2 70B and GPT-3.5 across all evaluated benchmarks. In particular, Mixtral vastly outperforms Llama 2 70B on mathematics, code generation, and multilingual benchmarks. "A different but equally elegant approach to combining models - LLM Augmented LLMs: Expanding Capabilities through Composition
"To this end, we propose CALM -- Composition to Augment Language Models -- which introduces cross-attention between models to compose their representations and enable new capabilities. Salient features of CALM are: (i) Scales up LLMs on new tasks by 're-using' existing LLMs along with a few additional parameters and data, (ii) Existing model weights are kept intact, and hence preserves existing capabilities, and (iii) Applies to diverse domains and settings."And another tweak on the theme… Blending Is All You Need: Cheaper, Better Alternative to Trillion-Parameters LLM
"This study explores a pertinent question: Can a combination of smaller models collaboratively achieve comparable or enhanced performance relative to a singular large model? We introduce an approach termed "blending", a straightforward yet effective method of integrating multiple chat AIs. Our empirical evidence suggests that when specific smaller models are synergistically blended, they can potentially outperform or match the capabilities of much larger counterparts. For instance, integrating just three models of moderate size (6B/13B paramaeters) can rival or even surpass the performance metrics of a substantially larger model like ChatGPT (175B+ paramaters)."Mixture of Experts ontop of state space models (as opposed to Transformers)… MoE-Mamba
"We propose that to unlock the potential of SSMs for scaling, they should be combined with MoE. We showcase this on Mamba, a recent SSM-based model that achieves remarkable, Transformer-like performance. Our model, MoE-Mamba, outperforms both Mamba and Transformer-MoE. In particular, MoE-Mamba reaches the same performance as Mamba in 2.2x less training steps while preserving the inference performance gains of Mamba against the Transformer."Applying Mixture of Experts to time series forecasting: Mixture-of-Linear-Experts
"Instead of training a single model, MoLE trains multiple linear-centric models (i.e., experts) and a router model that weighs and mixes their outputs. While the entire framework is trained end-to-end, each expert learns to specialize in a specific temporal pattern, and the router model learns to compose the experts adaptively. Experiments show that MoLE reduces forecasting error of linear-centric models, including DLinear, RLinear, and RMLP, in over 78% of the datasets and settings we evaluated"
Finally, some groundbreaking research coming out of Facebook - Self-Rewarding Language Models, leveraging the new DPO approach highlighted above
"In this work, we study Self-Rewarding Language Models, where the language model itself is used via LLM-as-a-Judge prompting to provide its own rewards during training. We show that during Iterative DPO training that not only does instruction following ability improve, but also the ability to provide high-quality rewards to itself. Fine-tuning Llama 2 70B on three iterations of our approach yields a model that outperforms many existing systems on the AlpacaEval 2.0 leaderboard, including Claude 2, Gemini Pro, and GPT-4 0613. While only a preliminary study, this work opens the door to the possibility of models that can continually improve in both axes."

Generative AI ... oh my!
Still such a hot topic it feels in need of it's own section, for all things DALLE, IMAGEN, Stable Diffusion, ChatGPT...
Another month, another set of updates from the big players- definitely tough to stay on top of everything, so this is a useful source for keeping up to date on the latest models and performance
OpenAI launched their GPT Store, allowing users who have created GPT tools to monetise their products (and there are lots of them out there already!)
"It’s been two months since we announced GPTs, and users have already created over 3 million custom versions of ChatGPT. Many builders have shared their GPTs for others to use. Today, we're starting to roll out the GPT Store to ChatGPT Plus, Team and Enterprise users so you can find useful and popular GPTs. Visit chat.openai.com/gpts to explore."OpenAI also released a new set of embeddings which are both cheaper and more powerful than the previous ones. They also appear to leverage new techniques for pruning the embedding vectors
"Both of our new embedding models were trained with a technique (Matryoshka Representation Learning)that allows developers to trade-off performance and cost of using embeddings. Specifically, developers can shorten embeddings (i.e. remove some numbers from the end of the sequence) without the embedding losing its concept-representing properties by passing in the dimensions API parameter. For example, on the MTEB benchmark, a text-embedding-3-large embedding can be shortened to a size of 256 while still outperforming an unshortened text-embedding-ada-002 embedding with a size of 1536."Google continues to be busy embedding AI in their core products
Circle (or highlight or scribble) to Search
"Introducing Circle to Search, a new way to search anything on your Android phone without switching apps. Now, with a simple gesture, you can select what you’re curious about in whatever way comes naturally to you — like circling, highlighting, scribbling or tapping — and get more information right where you are."An impressive new video generator - Lumiere

As well as some impressive research findings on their Google Health chatbot (paper here)
"To our knowledge, this is the first time that a conversational AI system has ever been designed optimally for diagnostic dialogue and taking the clinical history,” says Alan Karthikesalingam, a clinical research scientist at Google Health in London and a co-author of the study1, which was published on 11 January in the arXiv preprint repository. It has not yet been peer reviewed."
Amazon still feels a little behind but are releasing products
Amazon Adds an AI Shopping Assistant
"The section “Looking for specific info?” on a product page, which previously searched in reviews and customer questions and allowed submitting new questions that sellers or other customers could answer, is now powered by AI on the iPhone/Android app. It relies on the product details and reviews ingested by a large language model (LLM) to respond with AI-generated answers to practically every imaginable question."
And lots of open source developments, as always..
OpenVoice - instant voice cloning
"OpenVoice has been powering the instant voice cloning capability of myshell.ai since May 2023. Until Nov 2023, the voice cloning model has been used tens of millions of times by users worldwide, and witnessed the explosive user growth on the platform.Stable Code 3B: Coding on the Edge from Stability.AI
"Compared to CodeLLaMA 7b, Stable Code 3B is 60% smaller while featuring a similar high-level performance across programming languages. Based on our pre-existing Stable LM 3B foundational model trained on 4 trillion tokens of natural language data, Stable Code was further trained on software engineering-specific data, including code. The model's compact size allows it to be run privately on the edge in real-time on modern laptops, even those without a dedicated GPU."What could be a new paradigm in code generation - AlphaCodium
"In this work, we propose a new approach to code generation by LLMs, which we call AlphaCodium – a test-based, multi-stage, code-oriented iterative flow, that improves the performances of LLMs on code problems. We tested AlphaCodium on a challenging code generation dataset called CodeContests, which includes competitive programming problems from platforms such as Codeforces. The proposed flow consistently and significantly improves results."And Microsoft released TaskWeaver: A code-first agent framework for efficient data analytics and domain adaptation

The grand Consumer Electronics Show (CES) in Las Vegas was dominated by AI infused products..
The World’s First AI Interpreter Hub - timekettle
"2-way Simultaneous Interpretation The WT2 Edge enables seamless and real-time translation for efficient communication. It's perfect for lengthy and detailed conversations where every word counts. There is no more need to pause after every sentence, as you can now enjoy a natural and fluent conversation experience that is unmatched by any other interpretation technology available."Rabbit - ‘The Rabbit R1 is an AI-powered gadget that can use your apps for you’
"The software inside the R1 is the real story: Rabbit’s operating system, called Rabbit OS, and the AI tech underneath. Rather than a ChatGPT-like large language model, Rabbit says Rabbit OS is based on a “Large Action Model,” and the best way I can describe it is as a sort of universal controller for apps. “We wanted to find a universal solution just like large language models,” he says. “How can we find a universal solution to actually trigger our services, regardless of whether you’re a website or an app or whatever platform or desktop?”"
Lots of excitement and creativity in blending models together with some excellent new tools and tutorials to experiment with…
First of all, a quick tutorial in fine-tuning- Fine-tuning Microsoft's Phi-2 using QLoRA - all in a simple notebook!
Now get your hands on this fantastic new tool for running open source models locally - LM Studio

And now to the blending…
First a tutorial talking through the different ways you can do this
"Let's imagine you have several LLMs: one excels at solving mathematical problems, and another is adept at writing code. Switching between two models can be tricky, so you can combine them to utilize the best of both worlds. And it's indeed possible! You won't even need a GPU for this task."And then a few more details on leveraging the excellent mergekit tool to do your merging
The resulting merged models are beggining to swamp the Hugging Face leaderboard… (e.g. Beyonder-4x7B-v2 and phixtral-2x2_8) as well as new mixture of expert models like DeepSeek
As is generally the case, lots of work in the Retrieval Augmented Generation (RAG) space - using LLM chatbots over known documents and repositories to reduce hallucinations
First of all, a good overview of the different approaches, as well as a good cheat sheet

This looks like a useful repo, packaging everything you need up in one place - QAnything: Question and Answer based on Anything
"QAnything(Question and Answer based on Anything) is a local knowledge base question-answering system designed to support a wide range of file formats and databases, allowing for offline installation and use. With QAnything, you can simply drop any locally stored file of any format and receive accurate, fast, and reliable answers."And then a few resources for getting more into the details and optimising (RAGatouille, tutorial, advanced techniques, Controllable Agents)
Wrapping up with some useful tips and tricks
AI for Economists: Prompts & Resources (very useful for more than just economists!)
Language Modeling Reading List (to Start Your Paper Club)!




Real world applications and how to guides
Lots of practical examples and tips and tricks this month
Now this is what you call an automated coffee machine!

Using AI to identify new materials (as we have discussed previously) seems very promising
New material found by AI could reduce lithium use in batteries
"This AI is all based on scientific materials, database and properties," explained Mr Zander. "The data is very trustworthy for using it for scientific discovery." After the software narrowed down the 18 candidates, battery experts at PNNL then looked at them and picked the final substance to work on in the lab. Karl Mueller from PNNL said the AI insights from Microsoft pointed them "to potentially fruitful territory so much faster" than under normal working conditions.”Discovery of a structural class of antibiotics with explainable deep learning
"Here we reasoned that the chemical substructures associated with antibiotic activity learned by neural network models can be identified and used to predict structural classes of antibiotics. We tested this hypothesis by developing an explainable, substructure-based approach for the efficient, deep learning-guided exploration of chemical spaces. We determined the antibiotic activities and human cell cytotoxicity profiles of 39,312 compounds and applied ensembles of graph neural networks to predict antibiotic activity and cytotoxicity for 12,076,365 compounds."
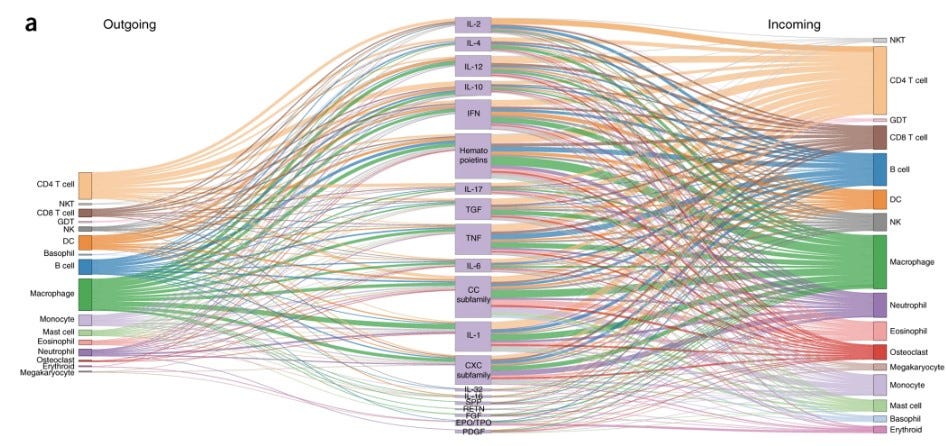
Exciting applications of Large Language Models in assimilating research - this time in Immune Cell Networks - excellent post from Rachel Thomas at Fast.AI

Still great opportunities for leveraging more ‘traditional’ ML approaches in so many areas -
Here applying Neural Nets to cancer risk prediction… A pancreatic cancer risk prediction model (Prism) developed and validated on large-scale US clinical data
Anomaly detection and alerting at Uber

Lots of great tutorials and how-to’s this month
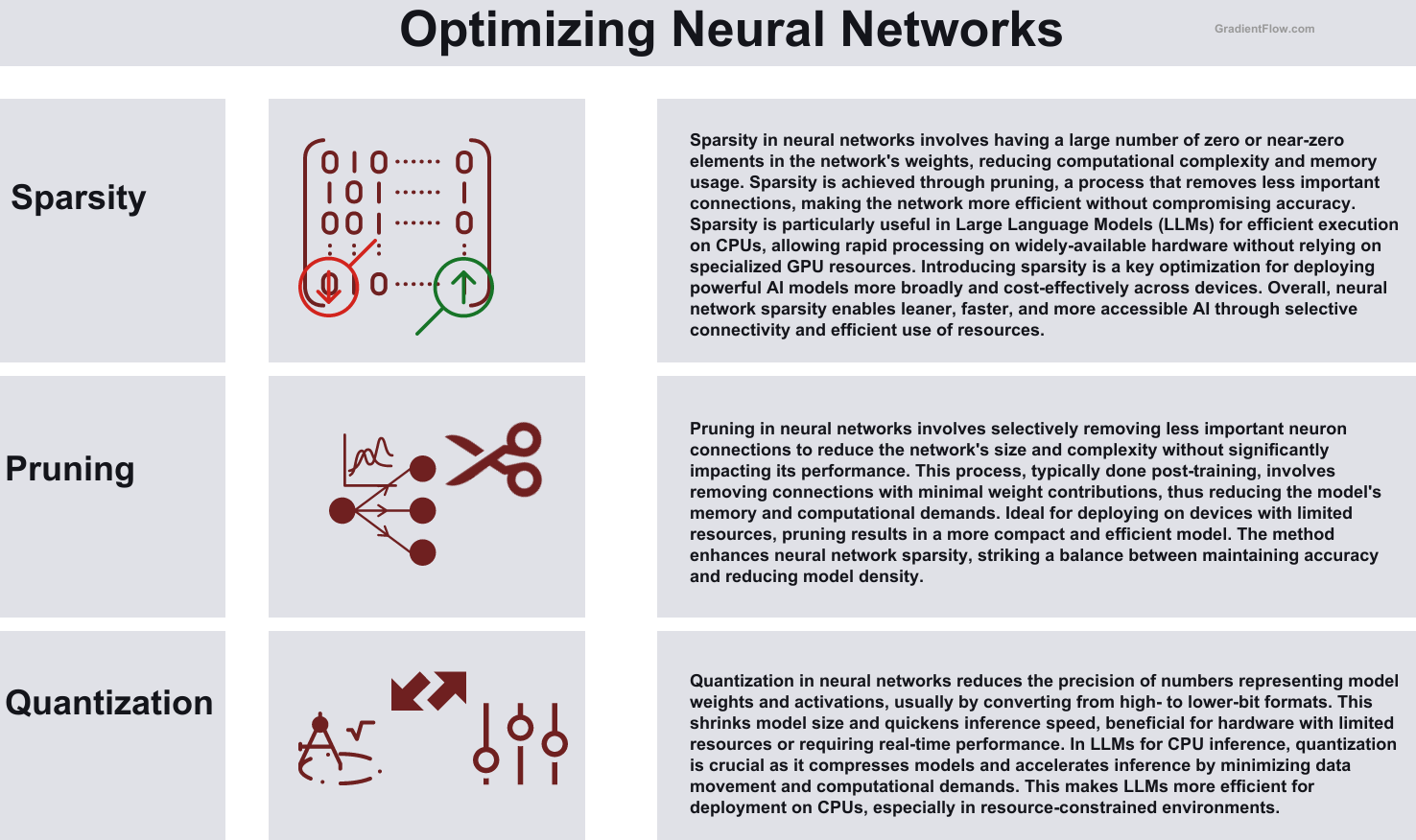
Nice simple diagram showing the different ways you can improve the efficiency of neural networks: Sparsity, Pruning and Quantisation
Excellent tutorial from Chip Huyen on Sampling for Text Generation (how large language models choose their next word) - well worth a read
And a nice walk through of how Self-Attention works
When I was younger, one of my favorite board games was “Inkognito,” a fascinating game of mystery and deduction. In “Inkognito,” players navigate a Venetian masquerade, trying to find their partner by reading clues from other players. Of course, you not only want to find your partner, you also want your partner to find you, so you are also dropping hints about yourself. Once you found your partner, you exchange some important information. This game, as it turns out, is a surprisingly fitting metaphor for one of the groundbreaking concepts in modern artificial intelligence: the self-attention mechanism in the transformer architecture.As always, some good transformer tutorials
A Deep Dive into Deep Generative Learning
And if Andrew Ng is excited about Direct Preference Optimisation, we should figure out what it really is!
Preference Tuning LLMs with Direct Preference Optimization Methods
"Direct Preference Optimization (DPO) has emerged as a promising alternative for aligning Large Language Models (LLMs) to human or AI preferences. Unlike traditional alignment methods, which are based on reinforcement learning, DPO recasts the alignment formulation as a simple loss function that can be optimised directly on a dataset of preferences"Fine-tune a Mistral-7b model with Direct Preference Optimization
Good tutorial evaluating different time series modelling techniques: ARIMA vs Prophet vs LSTM for Time Series Prediction
And a dive into different ways of removing outliers from your data - The Perfect Way to Smooth Your Noisy Data
Finally, some useful visualisation resources:
An excellent guide to plotting best practices- Friends Don't Let Friends Make Bad Graphs

Pretty cool - 3D Data Cube Visualization in Jupyter Notebooks

Visualize and compare embeddings for text sequences

Creating beautiful plots of data maps







Practical tips
How to drive analytics and ML into production
Different Venture Capital firms and their takes on the modern AI stack with lots of example providers and services…
First from Andreesen Horowitz
Then Menlo Ventures view

Good essay on the changing needs of ML in production - well worth a read
Not sure how to host your own LLM? DeepSpeed from Microsoft could be your answer (now with support for Mixtral, Phi-2 and Falcon)
Good article on hosting Computer Vision pipelines
Commentary on testing for ML
Things No One Tells You About Testing Machine Learning
"The plumbing in complex software is where countless problems arise. The solution is to create a suite of black box test cases that test the outputs of the entire pipeline. While this will require regular updates if your model or code change frequently, it covers a large swath of code and can detect unforeseen impacts quickly. The time spent is well worth it."
Finally .. is it time to check out Polars? I mean, how about this for a simple syntax.. and it flies!
import polars as pl query = ( pl.scan_parquet("yellow_tripdata_2023-01.parquet") .join(pl.scan_csv("taxi_zones.csv"), left_on="PULocationID", right_on="LocationID") .filter(pl.col("total_amount") > 25) .group_by("Zone") .agg( (pl.col("total_amount") / (pl.col("tpep_dropoff_datetime") - pl.col("tpep_pickup_datetime")).dt.total_minutes() ).mean().alias("cost_per_minute") ).sort("cost_per_minute",descending=True) )

Bigger picture ideas
Longer thought provoking reads - lean back and pour a drink! ...
I mean you just have to watch really - Yann LeCun, Nicholas Thompson, Kai-Fu Lee, Daphne Koller, Andrew Ng, Aidan Gomez at Davos

The Hard Truth about Artificial Intelligence in Healthcare: Clinical Effectiveness is Everything, not Flashy Tech - Roy Zawadzki
"Building machine learning/artificial intelligence medical devices (MAMDs) is much like bringing a new drug to market. First, both must be developed “in the lab.” Then, rigorous testing for efficacy and safety is conducted. Finally, physicians must be convinced to use the product and payers to reimburse it. Along this path, the vast majority of ostensibly promising drugs fail because the bar for commercial success is set high. This bar is no different for MAMDs. Yet, in the public discourse, too much weight is given to the technological sophistication of MAMDs instead of what is needed for successful implementation."The Threat of Persuasive AI - Mark Esposito, Josh Entsminger, Terence Tse
"What does it take to change a person’s mind? As generative artificial intelligence becomes more embedded in customer-facing systems – think of human-like phone calls or online chatbots – it is an ethical question that needs to be addressed widely."Why Chatbots are not the future - Amelia Wattenberger
"Unfortunately for the countless hapless people I've talked to in the past few months, this was inexorable. Ever since ChatGPT exploded in popularity, my inner designer has been bursting at the seams. To save future acquaintances, I come to you today: because you've volunteered to be here with me, can we please discuss a few reasons chatbots are not the future of interfaces."How to build a thinking AI - Jared Edward Reser
"The result is a chain of associatively linked intermediate states capable of advancing toward a solution or goal. Iterative updating is conceptualized here as an information processing strategy, a model of working memory, a theory of consciousness, and an algorithm for designing and programming artificial general intelligence."It's 2024 and they just want to learn - Nathan Lambert
"There’s a famous meme or saying that’s been going around the last few weeks again about training large models: they just want to learn. All anthropomorphization comments aside (it’s clear that models do not want anything innately right now), it’s true. It’s the best way to describe the low-level feeling on the ground in LLMs. If you go at tasks with a few levers (combinations of data and training platforms), abundant motivation, and especially scale, the signal almost always comes. The idea is that there’s something deeply aligned in how we’re training models and structuring our data, but that philosophical digression on whether scaling works is for another day."Happy Puppies and Silly Geese: Pushing the Limits of A.I. Absurdity - Emmett Lindner
"In November, Garrett Scott McCurrach, the chief executive of Pipedream Labs, a robotics company, posted a digital image of a goose on social media with a proposition: “For every 10 likes this gets, I will ask ChatGPT to make this goose a little sillier.” As the post was liked tens of thousands of times, the goose went through a few growing pains."

{kind=link}
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
Time to roll-up your sleeves and get coding?
First off, how about getting Open Interpreter up and running?
Too easy? How about Chess Transformers - a library for training transformer models to play chess by learning from human games. (more interesting reading here on Chess-GPT)
Want more? Ok … ‘Building a fully local LLM voice assistant to control my smart home’
Updates from Members and Contributors
Regular newsletter contributor and open source champion, Marco Gorelli, has an excellent tutorial on using Polars - ‘how you can extend Polars with Rust extensions for super-high performance’. As mentioned above, if you are a pandas user, it’s definitely worth giving Polars a try…
Arthur Turrell has released a version 1.0 of what looks to be an excellent free online book "coding for economists", with chapters on using data science to everything from regression, to reproducible environments, to data work, to plotting all the most common charts in the most popular vis packages (598 stars and around 4k users a month…)
Sam Young, at the Catapult Energy Systems, mentions that the AI for Decarbonisation Centre of Excellence (ADViCE) has released a report on different ways AI can help accelerate decarbonisation, along with a set of virtual decarbonisation challenge cards to help you understand particular applications.
Sarah Phelps at the UK Statistics Authority draws our attention to the continuing ESSnet Web Intelligence Network 2023/2024 webinar series. The next one is on 5th March, titled “Measuring the quality of large-scale automated classification systems applied to online job advertisement data” - more information here. Previous webinars are also now available to view for free on the ESSnet YouTube channel
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
2 exciting new machine learning roles at Carbon Re- excellent climate change AI startup
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS