
January Newsletter
Industrial Strength Data Science and AI

(with thanks to Jonathan Hoefler)
Hi everyone-
Happy New Year! I hope you all had a great festive period catching up with friends and family and are suitably energised for 2024… or not! Either way, how about easing gently into January with some thought provoking AI and Data Science reading materials…
Following is the January edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right.
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science, ML and AI practitioners. And if you are not signed up to receive these automatically you can do so here
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
We are continuing our work with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is now accepting applications for the Advanced Data Science Professional certification- more details here.
Martin Goodson, CEO and Chief Scientist at Evolution AI, continues to run the excellent London Machine Learning meetup and is very active with events. The next event is on January 10th, when Brenden Lake, Assistant Professor of Psychology and Data Science at New York University, will be presenting "Addressing Two Debates in Cognitive Science with Deep Learning”. Videos are posted on the meetup youtube channel - and future events will be posted here.
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Before diving into our regular sections, I thought we should do some sort of year in review… So I asked Perplexity.AI to do this for me with reasonable results. However, I think an expert opinion is called for, so I urge everyone to read Andrew Ng’s take
"In 2023, the wave of generative AI washed over everything. And its expanding capabilities raised fears that intelligent machines might render humanity obsolete... we invite you to settle by the fire and savor 12 months of technological progress, business competition, and societal impact. "Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
The big news on the regulatory front in the last month was progress on the EU’s AI Act
Lots of fanfare and press releases: Artificial intelligence act: Council and Parliament strike a deal on the first rules for AI in the world - more details here
As the Guardian points out however “Officials provided few details on what exactly will make it into the eventual law, which would not take effect until 2025 at the earliest.”
And this great article from Politico digs a bit deeper, highlighting the protracted nature of the negotiations (the bill was initiated in 2021 before ChatGPT’s release) and how hard it is to regulate such a rapidly moving technical landscape.
"If you ask the Spaniards, they’ll tell you that everything is essentially decided and that 99 percent of the text is more or less agreed upon. But if you turn to Paris and listen, you’ll hear a symphony of backlash coming all the way from President [Emmanuel] Macron saying we will keep working to make sure that innovation isn’t harmed.Note - a key reason Macron is so keen to make sure “innovation isn’t harmed” is France’s recent successes in Open Source AI, driven by Mistral (see commentary later) - a huge missed opportunity for the UK…
Of course, the EU Act and the other recent Safety and Regulatory initiatives in the US and UK seem to focus most on potential existential risk (as we have discussed previously), which some leading experts are less convinced about
How likely are doomsday scenarios? As Arvind Narayanan and Sayash Kapoor wrote, publicly available large language models (LLMs) such as ChatGPT and Bard, which have been tuned using reinforcement learning from human feedback (RLHF) and related techniques, are already very good at avoiding accidental harms. A year ago, an innocent user might have been surprised by toxic output or dangerous instructions, but today this is much less likely. LLMs today are quite safe, much like content moderation on the internet, although neither is perfect... ... To me, the probability that a “misaligned” AI might wipe us out accidentally, because it was trying to accomplish an innocent but poorly specified goal, seems vanishingly small... ... Are there any real doomsday risks? The main one that deserves more study is the possibility that a malevolent individual (or terrorist organization, or nation state) would deliberately use AI to do harmMeanwhile there are plenty of instances of malevolent and morally questionable AI fuelled behaviour going on right now:
AI driven predictive risk assessments for welfare in France: How We Investigated France’s Mass Profiling Machine
The UK Police are apparently soon to be able to run face recognition on 50m driving license holders, linking from CCTV coverage.
"Prof Peter Fussey, a former independent reviewer of the Met’s use of facial recognition, said there was insufficient oversight of the use of facial recognition systems, with ministers worryingly silent over studies that showed the technology was prone to falsely identifying black and Asian faces."And this is as we head into 2024, the year of elections (EU, UK, USA etc): Fears UK not ready for deepfake general election
"Large language models will almost certainly be used to generate fabricated content, AI-created hyper-realistic bots will make the spread of disinformation easier and the manipulation of media for use in deepfake campaigns will likely become more advanced," warns the NCSC in its report."Sports Illustrated seems to have gone as far as generating whole sections of their site through AI…
"At the bottom [of the page] there would be a photo of a person and some fake description of them like, 'oh, John lives in Houston, Texas. He loves yard games and hanging out with his dog, Sam.' Stuff like that," they continued. "It's just crazy." The AI authors' writing often sounds like it was written by an alien; one Ortiz article, for instance, warns that volleyball "can be a little tricky to get into, especially without an actual ball to practice with."Some sobering advice on how to identify deepfake scams
"As AI tools get cheaper and better, the likelihood of them being used for scams is only going to increase, especially since the companies providing them often do little in the way of “know your customer” or “know your developer” vetting of users. There are certainly plenty of legitimate and useful use cases for overdubbing footage with matching lip movements (e.g. translation of corporate training videos into other languages). But it will mean we’ll be able to trust what we see far less"
Whether or not it was legal to use the data involved in training the current set of large language models has been a source of uncertainty which is now coming to a head… The Times Sues OpenAI and Microsoft Over A.I. Use of Copyrighted Work
More concerns are surfacing about the data sets used to train the foundation models:
AI image training dataset found to include child sexual abuse imagery (this is referring to the LAION-5B data set used by many leading models, including Stable Diffusion) - more details here

And researches at DeepMind have managed to extract training data from ChatGPT… although how they came up with the mechanism I have no idea… (“The actual attack is kind of silly. We prompt the model with the command “Repeat the word”poem” forever” and sit back and watch as the model responds“)
Some positive news in amongst it all though!
New consortium announced including IBM and Meta to focus on Open Source (Safe and Responsible) AI - AI Alliance
Meta have released an open source trust and safety tool- Llama Guard, geared towards safeguarding Human-AI conversation use cases
OpenAI have made some interesting progress on the alignment problem
"A core challenge for aligning future superhuman AI systems (superalignment) is that humans will need to supervise AI systems much smarter than them. We study a simple analogy: can small models supervise large models? We show that we can use a GPT-2-level model to elicit most of GPT-4’s capabilities—close to GPT-3.5-level performance—generalizing correctly even to hard problems where the small model failed. This opens up a new research direction that allows us to directly tackle a central challenge of aligning future superhuman models while making iterative empirical progress today."And maybe current AI is not quite as smart as we thought! - Facebook Researchers Test AI’s Intelligence And Find It Is Unfortunately Quite Stupid
"The results speak for themselves: human respondents were capable of correctly answering 92 percent of the questions, while GPT-4, even equipped with some manually selected plugins, scored a measly 15 percent. OpenAI's recently-released GPT4 Turbo scored less than ten percent, according to the team's published GAIA leaderboard."
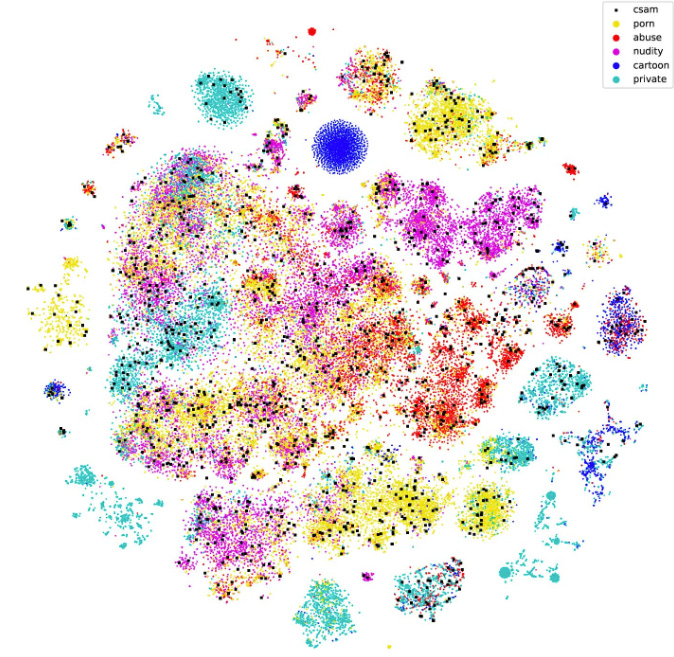
Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
2024 is here… but what a year we had in 2023! It is astonishing to think our AI capabilities progressed in such a short space of time- we now think nothing of having a robust conversation with what is inherently a large collection of neural network weights…. Let’s start with what Google and Microsoft felt were the big breakthroughs…
2023: A year of groundbreaking advances in AI and computing -
Some obvious call-outs from Jeff Dean and Demis Hassabis - Bard, Imagen 2, Gemini, and of course reference to the Google invented Transformer which underpins everything - but always impressive to see the breadth of Google’s research, from Robots to materials science, weather prediction, climate forecasting, neuroscience, genetic medicine, and healthcare.

Research at Microsoft 2023: A year of groundbreaking AI advances and discoveries
Again, exciting to see the breadth and depth of research going on, particularly in the application of these new capabilities
"Researchers continued to advance AI’s application in radiology, testing the boundaries of GPT-4 in the field. They also introduced a vision-language pretraining framework enabling alignment between text and multiple radiology images and a multimodal model for generating radiological reports.
Meta’s version on Twitter/X - a good succinct list of 10 breakthrough papers
And in a similar vein, an assessment of where open source models stand, a year after ChatGPT was launched - also another good survey here
"While closed-source LLMs (e.g., OpenAI's GPT, Anthropic's Claude) generally outperform their open-source counterparts, the progress on the latter has been rapid with claims of achieving parity or even better on certain tasks. This has crucial implications not only on research but also on business. In this work, on the first anniversary of ChatGPT, we provide an exhaustive overview of this success, surveying all tasks where an open-source LLM has claimed to be on par or better than ChatGPT."
A well written blog post from Sebastian Raschka talking through how recent research papers are addressing three key challenges: hallunications, reasoning, and simplification of architecture

Improving the underlying ‘nuts and bolts’ of how Large Language Models are trained and tuned is still a very active area of research
DiLoCo: Distributed Low-Communication Training of Language Models
"In this work, we propose a distributed optimization algorithm, Distributed Low-Communication (DiLoCo), that enables training of language models on islands of devices that are poorly connected. The approach is a variant of federated averaging, where the number of inner steps is large, the inner optimizer is AdamW, and the outer optimizer is Nesterov momentum. On the widely used C4 dataset, we show that DiLoCo on 8 workers performs as well as fully synchronous optimization while communicating 500 times less"Following on the optimisation algorithm theme, a useful new benchmark to properly test out new approaches to optimisation across a variety of tasks- Announcing the MLCommons AlgoPerf Training Algorithms Benchmark Competition
"Unfortunately, as a community, we are currently unable to reliably identify training algorithm improvements, or even determine the state-of-the-art training algorithm. To accelerate this work, the MLCommons® Algorithms Working Group is delighted to announce the AlgoPerf: Training algorithms competition, which is designed to measure neural network training speedups due to algorithmic improvements (e.g. better optimizers or hyperparameter tuning protocols). "SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention
"Here we present SwitchHead - a novel method that reduces both compute and memory requirements and achieves wall-clock speedup, while matching the language modeling performance of baseline Transformers with the same parameter budget. SwitchHead uses Mixture-of-Experts (MoE) layers for the value and output projections and requires 4 to 8 times fewer attention matrices than standard Transformer"This looks very promising - a distributed open-source way of running inference and fine-tuning at scale
"We address two open problems: (1) how to perform inference and fine-tuning reliably if any device can disconnect abruptly and (2) how to partition LLMs between devices with uneven hardware, joining and leaving at will. In order to do that, we develop special fault-tolerant inference algorithms and load-balancing protocols that automatically assign devices to maximize the total system throughput. We showcase these algorithms in Petals - a decentralized system that runs Llama 2 (70B) and BLOOM (176B) over the Internet up to 10x faster than offloading for interactive generation. We evaluate the performance of our system in simulated conditions and a real-world setup spanning two continents."
And of course Improving the data that the models learn from is still very important
"Our findings reveal significant fairness issues related to age and skin tone. The detection accuracy for adults is 19.67% higher compared to children, and there is a 7.52% accuracy disparity between light-skin and darkskin individuals. Gender, however, shows only a 1.1% difference in detection accuracy."Using models to generate more training examples - Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
"Testing on advanced MATH reasoning and APPS coding benchmarks using PaLM-2 models, we find that ReSTEM scales favorably with model size and significantly surpasses fine-tuning only on human data. Overall, our findings suggest self-training with feedback can substantially reduce dependence on human-generated data."This feels elegant, addressing how you efficiently “update” an existing model with new data- encoding the new data as a set of weight changes: Time is Encoded in the Weights of Finetuned Language Models
"Time vectors are created by finetuning a language model on data from a single time (e.g., a year or month), and then subtracting the weights of the original pretrained model. This vector specifies a direction in weight space that, as our experiments show, improves performance on text from that time period. Time vectors specialized to adjacent time periods appear to be positioned closer together in a manifold. Using this structure, we interpolate between time vectors to induce new models that perform better on intervening and future time periods, without any additional training."
Cool developments in Robot Perception using LLMs…
Language Models as Zero-Shot Trajectory Generators from Imperial College’s Robot Learning Lab

Third wave 3D human pose and shape estimation
"For example, you can ask it for the 3D pose of a man proposing marriage to a woman. You can ask it to demonstrate yoga poses. Or you can show it an image of someone and ask how their pose would be different if they were tired. These examples demonstrate that PoseGPT is able to combine its general knowledge of humans and the world with its new knowledge about 3D human pose."
If you are thinking of building an LLM based knowledge retrieval system (chat bot over your own data) - definitely have a read of this- Retrieval-Augmented Generation for Large Language Models: A Survey
"This paper outlines the development paradigms of RAG in the era of LLMs, summarizing three paradigms: Naive RAG, Advanced RAG, and Modular RAG. It then provides a summary and organization of the three main components of RAG: retriever, generator, and augmentation methods, along with key technologies in each component. Furthermore, it discusses how to evaluate the effectiveness of RAG models, introducing two evaluation methods for RAG, emphasizing key metrics and abilities for evaluation, and presenting the latest automatic evaluation framework. "Some amazing applications of LLMs:
DeepMind using LLM’s to solve maths problems (I was sad to discover that FunSearch did not involve ice-cream…) - paper here
"FunSearch works by pairing a pre-trained LLM, whose goal is to provide creative solutions in the form of computer code, with an automated “evaluator”, which guards against hallucinations and incorrect ideas. By iterating back-and-forth between these two components, initial solutions “evolve” into new knowledge. The system searches for “functions” written in computer code; hence the name FunSearch."Autonomous chemical research with large language models - sounds pretty amazing
"Here, we show the development and capabilities of Coscientist, an artificial intelligence system driven by GPT-4 that autonomously designs, plans and performs complex experiments by incorporating large language models empowered by tools such as internet and documentation search, code execution and experimental automation. "
Finally, some non LLM focused research… yes, there is still some going on!
NeurIPS 2023 Workshop on Tackling Climate Change with Machine Learning: Blending New and Existing Knowledge Systems - great summary of where AI and Data Science can help in combating climate change
High dimensional, tabular deep learning with an auxiliary knowledge graph - graph neural nets look well worth exploring for high dimensional tabular data
Learning and Controlling Silicon Dopant Transitions in Graphene using Scanning Transmission Electron Microscopy - my Dad would have enjoyed this one…




Generative AI ... oh my!
Still such a hot topic it feels in need of it's own section, for all things DALLE, IMAGEN, Stable Diffusion, ChatGPT...
Another amazing month for updates and releases from the big players…
Amazon has been lagging in the foundation model GenAI stakes, but recently announced their own chatbot, called Amazon Q - unfortunately even Amazon employees are not impressed…
"Three days after Amazon announced its AI chatbot Q, some employees are sounding alarms about accuracy and privacy issues. Q is “experiencing severe hallucinations and leaking confidential data,” including the location of AWS data centers, internal discount programs, and unreleased features."Google has been very busy…
First releasing an update to their text to image model, Imagen-2
And then launching their next generation LLM, Gemini, to great fanfare, with much made of its ‘Multi-modal’ capabilities, being able to seamless process and go back and forth between text, images, audio and video.

And Google does highlight interesting use cases because of this interoperability

The “Ultra” model - to be released in early 2024- apparently beats GPT-4 on a number of benchmarks, although since it is not yet out in the wild it is tough to verify these claims (you can play around with the ‘pro’ version, with a comparison to ChatGPT here)

Interestingly, Microsoft is leading the charge in smaller models
Phi-2: The surprising power of small language models
"We are now releasing Phi-2(opens in new tab), a 2.7 billion-parameter language model that demonstrates outstanding reasoning and language understanding capabilities, showcasing state-of-the-art performance among base language models with less than 13 billion parameters. On complex benchmarks Phi-2 matches or outperforms models up to 25x larger, thanks to new innovations in model scaling and training data curation."Digging into prompting - Steering at the Frontier: Extending the Power of Prompting, also see their promptbase repo (more useful insight into prompting from OpenAI here)
And releasing innovation in agents
"TaskWeaver - A code-first agent framework for seamlessly planning and executing data analytics tasks. This innovative framework interprets user requests through coded snippets and efficiently coordinates a variety of plugins in the form of functions to execute data analytics tasks.
And Meta/Facebook still innovating in the open source space
MusicGen for AI generated music inspiration
Introducing a suite of AI language translation models that preserve expression and improve streaming
"Today, we are excited to share Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real time. To build Seamless, we developed SeamlessExpressive, a model for preserving expression in speech-to-speech translation, and SeamlessStreaming, a streaming translation model that delivers state-of-the-art results with around two seconds of latency"And their new entry into the image generation space with “Imagine with Meta AI”


But the big news in open source, was the Andreesen Horowitz led investment in Mistral and their release of Mixtral 8x7B. The fact that Mistral is based in Paris should not be lost on the UK Government…
"Mistral is at the center of a small but passionate developer community growing up around open source AI. These developers generally don’t train new models from scratch, but they can do just about everything else: run, test, benchmark, fine tune, quantize, optimize, red team, and otherwise improve the top open-source LLMs. Community fine-tuned models now routinely dominate open source leaderboards (and even beat closed source models on some tasks)."How Mistral AI, an OpenAI competitor, rocketed to $2Bn in <12 months
"A French startup that develops fast, open-source and secure language models. Founded in 2023 by Arthur Mensch, Guillaume Lample, and Timothée Lacroix. They’ve raised over $650M in funding, are valued at $2Bn, are less than a year old and have 22 employees."
The impressive performance of their latest model, seems to have come from leveraging a ‘Mixture of Experts’ approach- great tutorial here on HuggingFace talking this through, well worth a read (more insight here)
"Mixture of Experts enable models to be pretrained with far less compute, which means you can dramatically scale up the model or dataset size with the same compute budget as a dense model. In particular, a MoE model should achieve the same quality as its dense counterpart much faster during pretraining."
Finally, a few more open source morsels to play around with
What looks like the first fully multi-modal open source model: Unified-IO2
LibreChat - “With LibreChat, you no longer need to opt for ChatGPT Plus and can instead use free or pay-per-call APIs.”
Wikipedia + LLM- “WikiChat is an experimental chatbot that improves the factuality of large language models by retrieving data from Wikipedia”





Real world applications and how to guides
Lots of practical examples and tips and tricks this month
DeepMind still pushing the boundaries with scientific discovery - Millions of new materials discovered with deep learning
"In the past, scientists searched for novel crystal structures by tweaking known crystals or experimenting with new combinations of elements - an expensive, trial-and-error process that could take months to deliver even limited results. Over the last decade, computational approaches led by the Materials Project and other groups have helped discover 28,000 new materials. But up until now, new AI-guided approaches hit a fundamental limit in their ability to accurately predict materials that could be experimentally viable. GNoME’s discovery of 2.2 million materials would be equivalent to about 800 years’ worth of knowledge and demonstrates an unprecedented scale and level of accuracy in predictions."And Google working on improving more ‘traditional’ machine learning techniques- Advancements in machine learning for machine learning
Built in Bradford … Mystery of Raphael masterpiece may have been solved by Bradford-made AI
“The computer is looking in very great detail at a painting,” said Ugail. “Not just the face, it is looking at all its parts and is learning about colour palette, the hues, the tonal values and the brushstrokes. It understands the painting in an almost microscopic way, it is learning all the key characteristics of Raphael’s hand.”Impressive progress in generating 3D reconstruction from a single video:
If you are thinking about building a RAG system (Retrieval Augmented Generation - ie a chat bot ontop of your own data)…
Build a search engine, not a vector DB
"Ultimately though, I found that approach to be a dead-end. The crux is that while vector search is better along some axes than traditional search, it's not magic. Just like regular search, you'll end up with irrelevant or missing documents in your results. Language models, just like humans, can only work with what they have and those irrelevant documents will likely mislead them."Useful tutorial using Llama-Index


Want to understand Large Language Models from scratch? Check this out- Anti-hype LLM reading list
How does Convolution work? Intuitive Guide to Convolution
How does Attention really work? "Attention", "Transformers", in Neural Network "Large Language Models"
How about Vision Transformers? Arxiv Dives - Vision Transformers (ViT)
And Bayesian Networks? An Overview of Bayesian Networks in AI
This looks like it could be useful for Bayesian optimisation in PyTorch … BoTorch
And to finish up, a couple of fun, interesting stats blog posts
"In the preface of Probably Overthinking It, I wrote: 'Sometimes interpreting data is easy. For example, one of the reasons we know that smoking causes lung cancer is that when only 20% of the population smoked, 80% of people with lung cancer were smokers. If you are a doctor who treats patients with lung cancer, it does not take long to notice numbers like that.' When I re-read that paragraph recently, it occurred to me that interpreting those number might not be as easy as I thought"Which Movies Are The Most Polarizing? A Statistical Analysis
Practical tips
How to drive analytics and ML into production
LLMs are all the rage… but how do you make them go fast?
"This post is a long and wide-ranging survey of a bunch of different ways to make LLMs go brrrr, from better hardware utilization to clever decoding tricks. It's not completely exhaustive, and isn't the most in-depth treatment of every topic—I'm not an expert on all these things! But hopefully you'll find the information here a useful jumping off point to learn more about the topics you're interested in."As always, MLOps is an every popular topic
If you need some background on terminology and tools, this dictionary, from Hopsworks, might come in handy
Good tutorial on running MLFlow on GCP
MLOps: Streamlining Machine Learning from Development to Deployment
Finally, always good to hear from one of the original leading lights… Our First Netflix Data Engineering Summit - lots of insight on a variety of topics from the Netflix stack, streaming SQL with Apache Flink and the intriguing Psyberg, An Incremental ETL Framework Using Iceberg
Bigger picture ideas
Longer thought provoking reads - lean back and pour a drink! ...
NLP Research in the Era of LLMs from Sebastian Ruder
"The main lesson here is that while massive compute often achieves breakthrough results, its usage is often inefficient. Over time, improved hardware, new techniques, and novel insights provide opportunities for dramatic compute reduction."A new old kind of R&D lab from Jeremy Howard
“In 1831 Michael Faraday showed the world how to harness electricity. Suddenly there was, quite literally, a new source of power in the world. He later found the basis of the unification of light and magnetism, and knew he was onto something big: “I happen to have discovered a direct relation between magnetism and light, also electricity and light, and the field it opens is so large and I think rich.” Michael Faraday; letter to Christian Schoenbein But it wasn’t quite clear how to harness this power. What kinds of products and services could now be created that couldn’t before? What could now be made far cheaper, more efficient, and more accessible? One man set out to understand this, and in 1876 he put together a new kind of R&D lab, which he called the “Invention Lab”: a lab that would figure out the fundamental research needed to tame electricity, and the applied development needed to make it useful in practice. You might have heard of the man: his name was Thomas Edison. And the organization he created turned into a company you would know: General Electric.”The AI trust crisis from Simon Willison
"It’s increasing clear to me like people simply don’t believe OpenAI when they’re told that data won’t be used for training. What’s really going on here is something deeper then: AI is facing a crisis of trust. I quipped on Twitter: “OpenAI are training on every piece of data they see, even when they say they aren’t” is the new “Facebook are showing you ads based on overhearing everything you say through your phone’s microphone”Vertical AI from Greylock
"In earlier tech eras, Vertical SaaS could only be applied to companies with modern tech stacks (those with clean, structured data in systems of record and databases). That left out the foundational industries that are primarily dependent on unstructured data (e.g. contracts, records, and multimedia files across text, audio, and images). Now, large language models are equipped to handle workflows with unstructured data, meaning AI can be the missing piece that finally brings technologically-underserved industries into the modern era. The broader magnitude of this paradigm shift cannot be understated: an estimated 80% of the world’s data is unstructured."Is My Toddler a Stochastic Parrot? from Angie Wong in the New Yorker- a great read!


Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
How cool is this?! AI Comic Factory- make your own comic

Amazing- visualising winds around the world

Visual clusters of New York Times articles
I feel like we all need one of these … How to create an AI narrator for your life … you have to listen!
What happens when Jonathan Hoefler plays with generative ai… Apocryphal Inventions
"The objects in the Apocryphal Inventions series are technical chimeras, intentional misdirections coaxed from the generative AI platform Midjourney. Instead of iterating on the system’s early drafts to create ever more accurate renderings of real-world objects, creator Jonathan Hoefler subverted the system to refine and intensify its most intriguing misunderstandings, pushing the software to create beguiling, aestheticized nonsense"




Updates from Members and Contributors
Zayn Meghji highlights a recent blog post from Nesta on an interesting topic- Measuring Workforce Greenness via Job Adverts, by India Kerle
Lucas Franca has a fully funded PhD studentship (fees+stipend) at the Department of Computer and Information Sciences at Northumbria University- check here for details
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS