
June 2026 Newsletter
Industrial Strength Data Science and AI
Hi everyone-
A glorious UK bank holiday weekend- surely some mistake?! I'm a bit nervous that summer may have been and gone, but assuming not, there is lots to keep up with in the wide world of AI and Data Science so how about some reading materials for a leisurely day in the park? Lots of great content below and I really encourage you to read on, but here are the edited highlights if you are short for time!
This Is Why You’re Drowning in Busywork - Carl Benedikt Frey
Predicting AI job exposure — Benedict Evans - Benedict Evans
An OpenAI model has disproved a central conjecture in discrete geometry - OpenAI
World Models Can Change Everything - James Wang
Choosing to Stay Human - Ethan Mollick
Following is the latest edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
committee; ethics; research; generative ai; applications; practical tips; engineering; big picture ideas; fun; reader updates; jobs
Committee Activities
The full program for the RSS International Conference (Bournemouth 7-10 September 2026) is now out
"Whether you are looking to immerse yourself in the newest methodological innovation, hear about real world impact in health, public policy, and education, or learn new skills via our professional development workshops, there is plenty to choose from."
Our new journal is up and running RSS: Data Science and Artificial Intelligence
There is a new call for paper for the journal- the very relevant topic of “Uncertainty in the Era of AI” (Deadline 31 July 2026)
Hold the date! 16th of June, 1-2pm (virtual event). We are continuing our series "10 key skills for Data Science that universities are failing to teach", diving into two of the most important technical skills for any data scientist working in an organisation. How to write code you can be proud of and how to get your models deployed in production.
Our Chair, Janet Bastiman, and committee member Matt Forshaw will both be at Datalyst 2026 in Newcastle upon Tyne on 26th June as part of an engaging panel session on Governance, Ethics, and Legalities. Tickets for this great all day event are available on eventbrite: Datalyst 2026 Tickets, Friday 26 June • 8:30 - 17
Check out the RSS blog Real World Data Science (Keep a lookout here as a write up of our Meeetup on “How to stay up to date as a data scientist?” will be published soon)
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
The Wide World of Geopolitics and Sovereign AI
Two different paths towards AI dominance- it's not at all clear who will win: 2028: Two scenarios for global AI leadership Anthropic
Distillation attacks, in which China-based labs create thousands of fraudulent accounts to circumvent access controls on US AI models and systematically harvest their outputs to replicate frontier capabilities, are another illicit technique used by PRC labs to catch up to their US counterparts and blunt the impact of export controls.
…
The result is near-frontier capability at a fraction of the cost, subsidized by the United States. It is systematic industrial espionage of a technology critical to long-term US national security interests.Beijing is now treating AI talent as a core national security asset, blocking Western acquisitions outright: China blocks Meta from acquiring startup Manus as global AI rivalry deepens
“China is showing the world that it is willing to play hardball when it comes to AI talents and capabilities, which the country views as a core national security asset,” said Lian Jye Su, chief analyst at the technology research and advisory group Omdia.
Proof that you do not need to be an American giant to be successful if you prioritise sovereignty: Why MistralAI Grows Faster Than OpenAI/Anthropic

Even deregulation-focused administrations are finding that some models are simply too powerful to leave unvetted: White House Considers Vetting A.I. Models Before They Are Released
The noninterventionist policy also began changing last month after the start-up Anthropic announced a new A.I. model called Mythos. Mythos is so powerful at identifying security vulnerabilities in software that it could lead to a cybersecurity 'reckoning,' said Anthropic, which declined to release the model to the public. The White House wants to avoid any political repercussions if a devastating A.I.-enabled cyberattack were to occur, people in the tech industry and the administration said.
Is the 'light-touch' era ending as the US considers treating frontier models like prescription drugs.: Hassett: White House may review AI models ‘like an FDA drug’
We’re studying possibly an executive order to give a clear roadmap to everybody about how this is going to go and how future AIs that also potentially create vulnerabilities should go through a process so that, you know, they’re released in the wild after they’ve been proven safe, just like an FDA drug...
Maybe not!: Trump calls off AI executive order over concern it could weaken US tech edge
President Donald Trump called off plans to sign a new executive order on artificial intelligence hours before an expected White House ceremony Thursday because he said he was worried the measure could dull America’s edge on AI technology.
Warfare, Security and Safety
Digging into how censorship is hard-coded into model weights in China: What political censorship looks like inside an LLM's weights — a mechanistic-interpretability study of Qwen 3.5
Qwen3.5-9B's political censorship is a small, identifiable circuit you can find, read, and turn off. The off switch is sharp but specific: subtract the right direction at the writer layer, within its dose band, and the model gives up the facts it was trained to hide. Push past that band, or steer the wrong axis, and it doesn't fall back to the truth.
Sobering - the first signs of autonomous, agentic malware in the wild: Adversaries Leverage AI for Vulnerability Exploitation, Augmented Operations, and Initial Access | Google Cloud Blog
In one notable example, we observed prominent cyber crime threat actors partnering to plan a mass vulnerability exploitation operation. Our analysis of exploits associated with this campaign identified a zero-day vulnerability implemented in a Python script that enables the user to bypass two-factor authentication (2FA) on a popular open-source, web-based system administration tool.
The future of warfare is being forged in Ukraine, where battlefield data is the new currency: Enter the Killer Robots: The Ukrainian Forging the Future of Warfare
He is leading an effort to monetize or trade Ukrainian war data, including a library of more than five million annotated videos of the battlefield filmed by surveillance and strike drones. These include footage showing how humans behave as killer drones close in, such as running or hiding. Last month, the Defense Ministry, through a program called Avenger Labs, opened up the data sets to companies from allied nations to train artificial intelligence models.
The Pentagon is diversifying, prioritising military utility over ethics: US government increases AI suppliers and rethinks Anthropic's role
The Pentagon’s statement on its new agreements reads, “The Department will continue to build an architecture that prevents AI vendor lock-in and ensures long-term flexibility for the Joint force.” The technologies will “give warfighters the tools they need to act with confidence and safeguard the nation against any threat.” The AIs will be used for ‘Impact Levels’ six (secret data) and seven (the most highly-classified materials) use-cases, helping create what the statement describes as an “AI-first fighting force.”
Perhaps Anthropic's new approach to ethical reasoning can save the day?: Teaching Claude why
Training on demonstrations of desired behavior is often insufficient. Instead, our best interventions went deeper: teaching Claude to explain why some actions were better than others, or training on richer descriptions of Claude’s overall character. Overall, our impression is, as we hypothesized in our discussion of Claude’s constitution, that teaching the principles underlying aligned behavior can be more effective than training on demonstrations of aligned behavior alone. Doing both together appears to be the most effective strategy.
The Societal Cost: From Algorithmic Cruelty to the Chore Economy
Bad algorithms can have serious consequences: Flaws in Kenya’s AI-driven health reforms driving up costs for the poorest
Kenya’s algorithmic healthcare system is structured on a decades-old World Bank bugbear: proxy means testing (PMT), a way of estimating the incomes of the poor based on their possessions and other life circumstances, such as how many children they have or whether they live alone. PMT has been used in World Bank-funded programmes 'all over Africa, all over Asia and the Pacific', said Stephen Kidd, a development economist.
China leading the way for workers rights vs AI?: Chinese Courts Rule Companies Cannot Fire Workers Simply to Replace Them With AI
The court emphasized AI integration as a strategic choice, not a legal 'objective major change' voiding contracts; AI should liberate labor and promote jobs while firms protect rights, suggesting retraining, reasonable reassignments with compensation, or worker upskilling.
Even the staunchest sceptics are beginning to wonder about AI consciousness: Richard Dawkins concludes AI is conscious, even if it doesn’t know it | AI (artificial intelligence) | The Guardian
There was mutual flattery as Dawkins showed the AI his unpublished novel and its response was, he said, 'so subtle, so sensitive, so intelligent that I was moved to expostulate: “You may not know you are conscious, but you bloody well are”.'
Is AI actually saving us time, or just turning us into our own unpaid tech support?: Opinion | A.I. Claims to Make Our Lives Easier. Does It?
The A.I. revolution involves a huge transfer of labor — not from worker to machine but from worker to consumer. The ability to do everything ourselves may be satisfying, but it can gradually overload us with busywork without our noticing.
The EU is moving to ensure creators get paid, which might just end the fair-use era: Commission preparing law on licensing content for AI | Euractiv
Speaking at an event on Wednesday, Tech Commissioner Henna Virkkunen said that many rights holders were willing to share their content but wanted fair compensation. “I’m willing to facilitate more possibilities for the licensing models between the rights holders and AI model creators,” she added – echoing remarks from a meeting of culture ministers on Tuesday, where several capitals called for a push in a similar direction.

Developments in Data Science and AI Research...
Refining the foundations of pre-training and optimisation
Have we been overthinking data cleaning? Apparently, at scale, even the 'messy' bits provide a useful signal.: A Bitter Lesson for Data Filtering
We investigate data filtering for large model pretraining via new scaling studies that target the high compute, data-scarce regime. In spite of an apparently common belief that filtering data to include only high-quality information is essential, our experiments suggest that with enough compute, the best data filter is no data filter. We find that sufficiently trained large parameter models not only tolerate low-quality and distractor data, but in fact benefit from nominally "poor" data.
Did you know about 'neuron death'? Solving it might unlock large data efficiency gains.: Aurora: A Leverage-Aware Optimizer for Rectangular Matrices | Tilde
We show that Muon's update inherits row-norm anisotropy on tall matrices which can cause a significant portion of neurons in MLP layers to permanently die. Row normalizing updates fixes this, but at the cost of orthogonality. We formulate the problem of steepest descent under the joint constraint of row-norm uniformity and orthogonality, and present Aurora optimizer as a solution. We use Aurora to train a 1.1B model, which achieves 100x data efficiency on open-source internet data and outperforms larger models on general evals like HellaSwag.
This could be a huge win for long-context training- scaling context without the quadratic pain: Lighthouse Attention - Nous Research
Lighthouse Attention, a selection-based hierarchical attention that pools queries, keys and values symmetrically across a multi-resolution pyramid, scores every pyramid entry with a parameter-free function, and keeps the selection logic outside the attention kernel … every recovered run matches or beats dense-from-scratch at the same token budget.
Distributed training keeps getting better: Decoupled DiLoCo: Resilient, Distributed AI Training at Scale

Agents as autonomous engineers and co-mathematicians
Moving from simple chat to stateful collaboration, Google’s latest agent solved real-world topology problems.: AI Co-Mathematician: Accelerating Mathematicians with Agentic AI
To establish this missing agentic flow for mathematics, we introduce the AI co-mathematician, a workbench for mathematicians to interactively leverage AI agents to pursue open-ended research, based on the latest Gemini language models. The AI co-mathematician provides a stateful, interactive workspace where a project coordinator agent delegates complex tasks across parallel workstreams, allowing the user to direct and interact with an evolving research process, rather than waiting for end-to-end autonomous execution.
Impressive breadth: AI agents are now autonomously optimising everything from silicon architecture to DNA variant detection.: AlphaEvolve: Gemini-powered coding agent scaling impact across fields

Are we approaching a new form of computing?: Neural Computer: A New Machine Form Is Emerging
NC points to a different path: through sustained interaction, runtime may gradually acquire new internal structures. User inputs stop looking like one-shot triggers and start acting more like ways of installing, invoking, composing, and preserving reusable neural routines, perhaps even internal executors that can be called again later. Functionally, that is closer to memory than to a processor. Upgrading the machine would no longer always mean rewriting the whole thing; it could mean writing new structures into an internal state that is addressable, callable, and persistent.
The inner life of models
A positive sounding approach- encouraging good things rather than just attempting to stop bad things: Positive Alignment: Artificial Intelligence for Human Flourishing
What we call Positive Alignment is the development of AI systems that (i) actively support human and ecological flourishing in a pluralistic, polycentric, context-sensitive, and user-authored way while (ii) remaining safe and cooperative. It is a distinct and necessary agenda within AI alignment research. We argue that several existing failures of alignment (e.g., engagement hacking, loss of human autonomy, failures in truth-seeking, low epistemic humility, error correction, thickness of diverse viewpoints, and being primarily reactive rather than proactive) may be better addressed through positive alignment, including cultivating virtues and maximizing human flourishing.
More cool stuff from Anthropic's research team: 'read' a model's latent thoughts: Natural Language Autoencoders
The core idea is to train Claude to explain its own activations. But how do we know whether an explanation is good? Since we don't know what thoughts an activation actually encodes, we can't directly check whether an explanation is accurate. So we train a second copy of Claude to work backwards—reconstruct the original activation from the text explanation. We consider an explanation to be good if it leads to an accurate reconstruction. We then train Claude to produce better explanations according to this definition using standard AI training techniques.
Reliability isn't just about more facts; it's about models knowing when to say 'I don't know': Hallucinations Undermine Trust; Metacognition is a Way Forward
If we understand hallucinations as confident errors - incorrect information delivered without appropriate qualification - a third path emerges beyond the answer-or-abstain dichotomy: expressing uncertainty. We propose faithful uncertainty: aligning linguistic uncertainty with intrinsic uncertainty.
Foundation models for the rest of the stack – From RecSys to Tabular data
We've covered this before- maybe this time it really will work! A new foundation model for Tabular data (thanks Dirk!): TabPFN | Prior Labs
TabPFN-3 by the numbers: Average accuracy across 51 OpenML datasets. 93% win rate over classic ML on TabArena, leading benchmark for structured data tasks. 0.2s for predictions on 1M samples.
For those wanting to dive into the code, the TabPFN repository is now available for enterprise tasks.: PriorLabs/TabPFN: ⚡ TabPFN: Foundation Model for Tabular Data ⚡ (see also The Magic of In-Context Learning (ICL): When Your Model Already Knows Your Data – Learning Machines)

Meta’s latest optimisation proves that treating data layout as a kernel concern can supercharge recommendation system inference.: In-Kernel Broadcast Optimization: Co-Designing Kernels for RecSys Inference – PyTorch





Generative AI ... oh my!
Snapshots of where we stand in June 2026
Google models lead in volume according to Vercel: AI Gateway production index

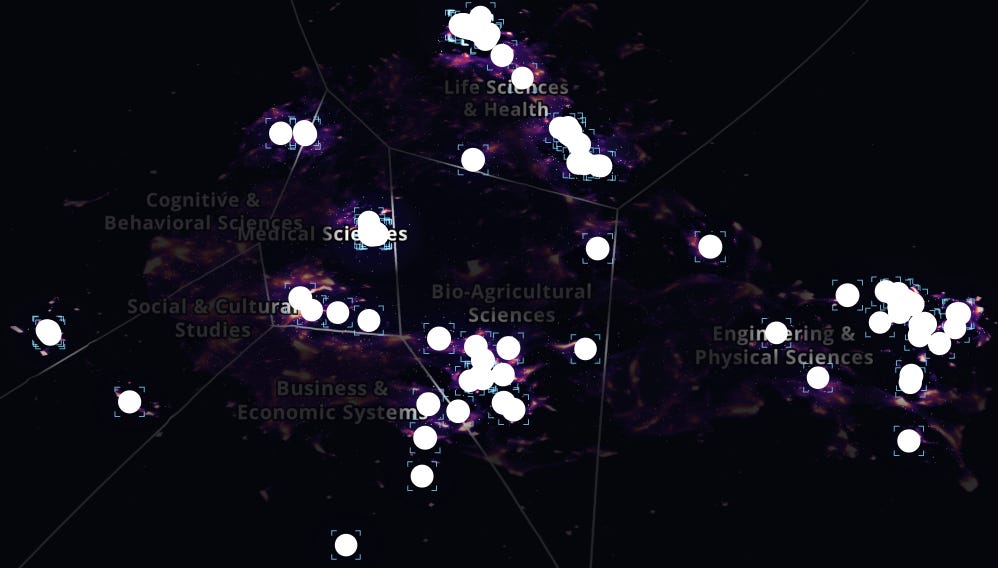
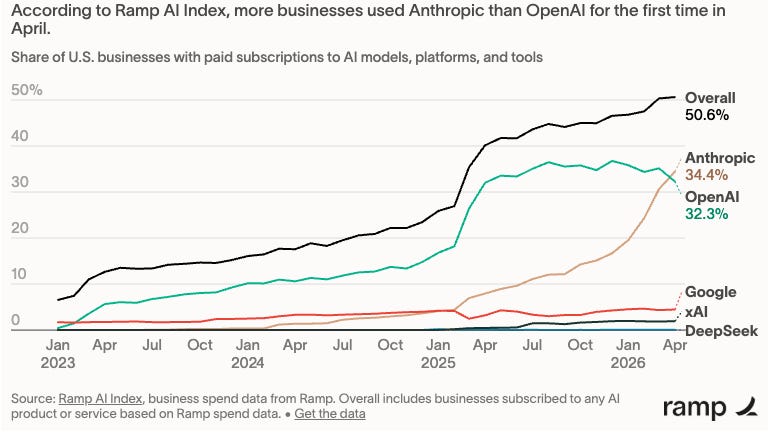
While Anthropic has made huge gains in the enterprise market: Anthropic beats OpenAI on business adoption
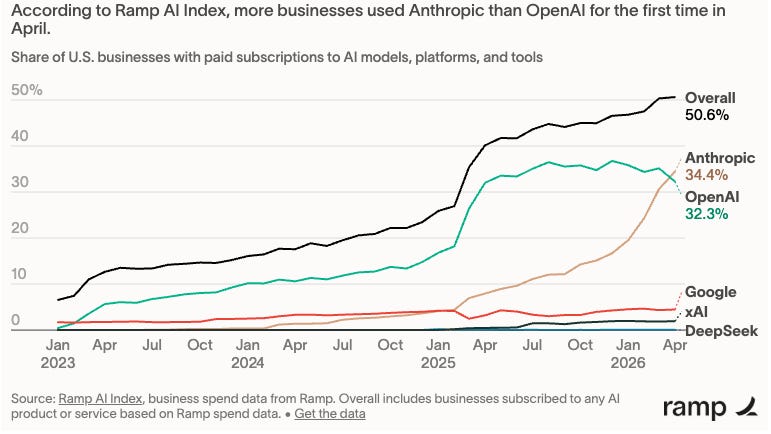
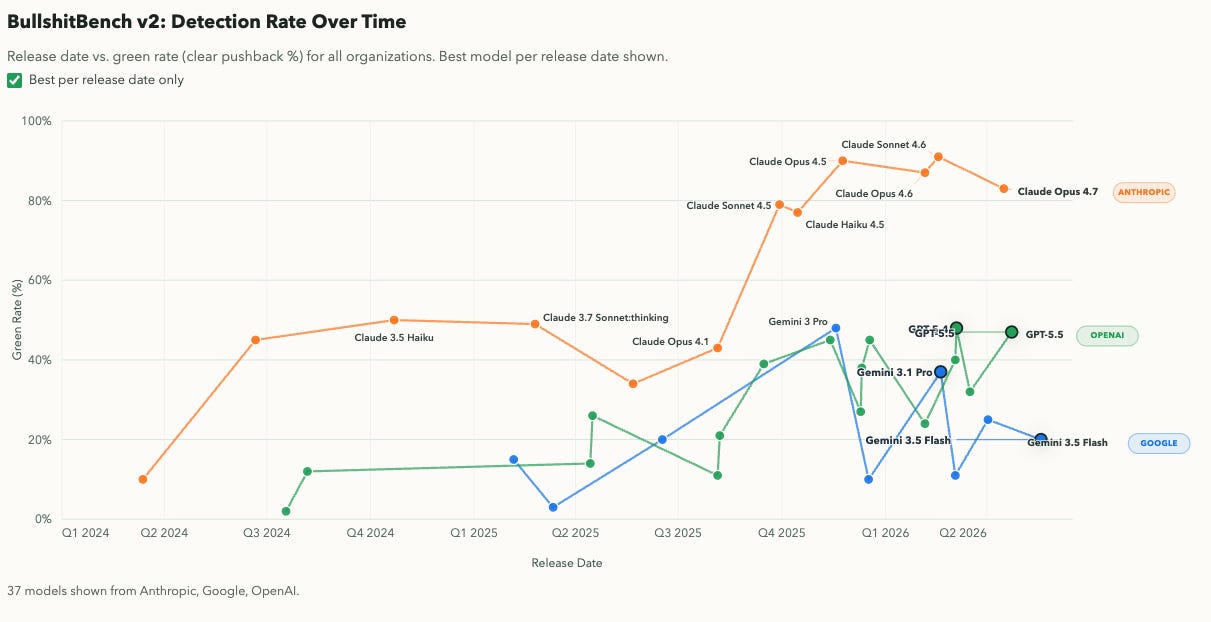
One benchmark that has not been improving- the "bullshit-benchmark": BullshitBench: V2 (New) Viewer
OpenAI keeps releasing
GPT-5.5 Instant: faster and better, halving hallucinations in critical domains.: GPT-5.5 Instant: smarter, clearer, and more personalized
Instant is now more dependable, with significant improvements in factuality across the board and the largest gains in domains where accuracy matters most. In internal evaluations, GPT‑5.5 Instant produced 52.5% fewer hallucinated claims than GPT‑5.3 Instant on high-stakes prompts covering areas like medicine, law, and finance.
Impressive real-time reasoning arrives for voice interfaces: Advancing voice intelligence with new models in the API
What stood out about GPT-Realtime-2 was the intelligence and tool-calling reliability it brings to complex voice interactions. On our hardest adversarial benchmark, this translates to a 26-point lift in call success rate after prompt optimization (95% vs. 69%).
Codex can increasingly do many things outside of pure coding: Codex can now control other desktop devices via Computer Use
OpenAI appears to be quietly extending the reach of its Codex remote control system, working on a capability that would let the coding agent operate macOS applications through Computer Use even when a laptop is locked or asleep.
Impressive research success as an autonomous researcher solving decades-old conjectures.: An OpenAI model has disproved a central conjecture in discrete geometry
As part of a broader effort to test whether advanced models can contribute to frontier research, we evaluated it on a collection of Erdős problems. In this case, it produced a proof resolving the open problem. This proof is an important milestone for the math and AI communities. It marks the first time that a prominent open problem, central to a subfield of mathematics, has been solved autonomously by AI.
Google drives forward on many different fronts with Google IO 2026 all AI
Gemini 3.5 Flash- all about cost effective throughput. Fast and cheap: Gemini 3.5: frontier intelligence with action
Gemini 3.5 Flash delivers intelligence that rivals large flagship models on multiple dimensions, at the speeds you have come to expect from the Flash series. It’s our strongest agentic and coding model yet, outperforming Gemini 3.1 Pro on challenging coding and agentic benchmarks like Terminal-Bench 2.1 (76.2%), GDPval-AA (1656 Elo) and MCP Atlas (83.6%), and leading in multimodal understanding (84.2% on CharXiv Reasoning).
Is it any good?: Gemini 3.5 Flash Looks Good For How Fast It Is

Antigravity SDK: attempting to catch up with Claude Code and Codex: Google Antigravity Blog: introducing-google-antigravity-2-0
Some new capabilities include: Dynamic subagents: the main agent can dynamically choose to define and invoke subagents to complete focused subtasks, thereby not polluting the main agents’ context window and allowing for parallelism of work. Asynchronous task management: Tasks and commands are managed and can run asynchronously to not block the main agent from continuing its work. JSON hooks: You can now define hooks in a simple JSON format, allowing you to intercept and control the Antigravity agent’s behavior.
Gemini Omni: Video generation becomes a dynamic, two-way conversation: Introducing Gemini Omni
We’re introducing Gemini Omni, where Gemini’s ability to reason meets the ability to create. Omni is our new model that can create anything from any input — starting with video. With Omni, you can combine images, audio, video and text as input and generate high-quality videos grounded in Gemini's real-world knowledge.
DeepMind is grounding world models in real Street View data to train next-gen embodied agents.: Simulate real-world places with Project Genie and Street View

Agent Executor- Open-sourcing the "agent-first" plumbing needed to keep long-running tasks alive and secure.: Agent Executor, Google’s distributed Agent Runtime | Google Cloud Blog
Agent Executor provides this backend resilience automatically for any actor (e.g., an agent, agent harness, skill, tool, or sandbox) through its event log and snapshotting.
Anthropic seems to be flourishing
New specialised agents- financial services.: Agents for financial services
Each agent template is a reference architecture that packages three things: skills (instructions and domain knowledge for the task), connectors (governed access to the data the task runs on), and subagents (additional Claude models that are called upon by the main agent, for specific sub-tasks such as comparables selection or methodology checks). Firms can adapt any of them to their own modeling conventions, risk policies, and approval flows.
Claude agents are now "dreaming" to refine their memories and verify their own work autonomously.: New in Claude Managed Agents: dreaming, outcomes, and multiagent orchestration | Claude

The great Andrej Karpathy has joined Anthropic to focus on what he calls formative R&D.: Andrej Karpathy on X: "Personal update: I've joined Anthropic”
I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
Progress at Microsoft?
Harnesses and multi-agents can beat the best models?: Microsoft’s multi-agent AI system tops Anthropic’s Mythos on cybersecurity benchmark

World-R1 text to video looks impressive: World-R1 | Reinforcing 3D Constraints for Text-to-Video Generation
Chinese open source continues to fly
ByteDance unifies audio and video generation into a single latent space for professional control.: Seedance 2.0
Seedance 2.0 adopts a unified multimodal audio-video joint generation architecture that supports text, image, audio, and video inputs, leading to the most comprehensive multimodal content reference and editing capabilities in the industry.
Alibaba’s latest flagship prioritises sustained autonomous execution and a massive 1-million-token context window.: Qwen Introduces Qwen3.7-Max: A Reasoning Agent Model With a 1M-Token Context Window

Baidu proves that state-of-the-art reasoning can be achieved with drastically lower parameter and compute costs.: ERNIE 5.1 Officially Released! Topping Multiple Leaderboards — A Model That Writes Better and Understands You More
ERNIE 5.1 compresses total parameters to approximately one-third and activated parameters to approximately half those of ERNIE 5.0, with pre-training compute cost at only 6% of comparable models at the same scale. Compared to ERNIE 5.0, inference cost is significantly reduced while still achieving leading performance among models of comparable scale.
And there are signs of life for open source outside of China
First open-weight architecture capable of full six-minute audio compositions from Stability AI: Stable Audio 3.0, the model family built with open-weight models — Stability AI

If you are in the market for building your own sovereign model, Cohere looks like a good starting point: Introducing Command A+ | Cohere
Today, we’re releasing Command A+ open-source. A mixture-of-experts (MoE) model, Command A+ is an efficient, versatile, and privately deployable LLM built for high-performance agentic tasks with minimal compute overhead.
NVIDIAs new architecture consolidates vision, audio, and text into a single reasoning stream.: NVIDIA Launches Nemotron 3 Nano Omni Model, Unifying Vision, Audio and Language for up to 9x More Efficient AI Agents | NVIDIA Blog

Our favourites at the Allen Institute are at it again with a high-performance open alternative for robotics: MolmoAct 2: An open foundation for robots that work in the real world | Ai2

And more from Allen- OlmoEarth- rethinking to process and tokenise satellite imagery.: OlmoEarth v1.1: A more efficient family of models

More innovation from Thinking Machines: continuous, time-aware human-machine interaction: Interaction Models: A Scalable Approach to Human-AI Collaboration
The interaction model works with micro-turns continuously interleaving the processing of 200ms worth of input and generation of 200ms worth of output. Rather than consuming a complete user-turn and generating a complete response, both input and output tokens are treated as streams.
Another example of small specialised models outperforming on specific tasks: CyberSecQwen-4B: Why Defensive Cyber Needs Small, Specialized, Locally-Runnable Models
Frontier models are very good at very many things. They are also expensive to call, ship every prompt off to someone else's datacenter, and are explicitly trained to refuse the messy edge cases a real defender lives in. Defensive cybersecurity is not a place where any of those tradeoffs are acceptable.










Real world applications
Shifting from general chatbots to precision agents
Scaling laws aren't just for LLMs; Datadog's Toto proves that bigger models reliably deliver better time series forecasts—impressive stuff.: Toto 2.0: Time series forecasting enters the scaling era | Datadog

DeepMind is reimagining the mouse pointer as a context-aware agent, making UI interaction feel far more intuitive—long overdue.: Shaping the future of AI interaction by reimagining the mouse pointer

How Mozilla use Anthropic's new "superpowered" Mythos model to fix bugs that had survived for decades: Behind the Scenes Hardening Firefox with Claude Mythos Preview - Mozilla Hacks - the Web developer blog

In high-stakes medical environments, specialised models can often beat the best generalists: Corti's new Symphony for Speech-to-Text model beats OpenAI at medical terminology accuracy, highlighting the value of specialized AI
In a newly published research paper, Corti revealed that its new clinical-grade speech models reduced word error rates (WER) by up to 93% when compared against leading generalist speech models and APIs on medical terminology.



Practical tips
The shifting economics of the personal AI stack
While it may feel more comfortable paying as you go, subscriptions are currently subsidising your tokens by a massive factor: Coding plan comparisons based on actual usage — sites.diy
The usage these plans provide is intentionally obfuscated and likely played around with depending on supply and demand. I make an effort here to measure and snapshot what you actually get on each plan. This data is from May 1st, 2026. I proxy each request through a server that logs, and measure input tokens, thinking tokens, output tokens, and calculate the price it would cost to use these models directly from the API.
Forget the hardware improvements, it is the software efficiency gains that are truly driving down inference costs: AI's Plummeting Prices Are a Software Story, Not a Hardware One

Another fun way way to burn those tokens- new Science Skills for Antigravity (thanks Dirk!): google-deepmind/science-skills
A collection of agent skills for scientific research tasks, spanning genomics, structural biology, cheminformatics, literature search, and more. Each skill provides structured instructions, scripts, and resources that extend an AI agent's capabilities for specialized scientific tasks.
The fork in the road is here: do you want the convenience of Gemini Spark or the sovereignty of OpenClaw?: OpenClaw passed 300,000 GitHub stars. Then Google launched Spark. - The New Stack
The self-hosted version asks for real work. Buy the Mac mini, keep it awake, install a daemon, set up Tailscale, and rotate the key when it expires. The reward is control. Your credentials and workflows can stay under your own hand, depending on how you wire up models and integrations... Spark asks for nothing. It is already inside Gmail, Docs, and Sheets, with no manual wiring, because Google owns both ends. That out-of-the-box reach is the structural advantage no third-party agent can copy.
Or maybe Hermes?: OpenClaw vs Hermes Agent: Why Nous Research's Self-Improving Agent Now Leads OpenRouter's Global Rankings - MarkTechPost
The rivalry between Hermes and OpenClaw comes down to a fundamental architectural disagreement. OpenClaw is organised around a central WebSocket Gateway — a persistent routing layer that connects 50+ messaging channels (Telegram, Discord, Slack, WhatsApp, Signal, and more) to an agent runtime. Its design optimises for reach: how many surfaces the agent can operate across simultaneously. Hermes Agent takes the opposite approach. Built under an MIT license, it centres on a 'do, learn, improve' execution loop. After completing a task, the agent enters a reflective phase where it analyses its own performance and autonomously generates reusable skill files for future use.
The architecture of agents – building robust harnesses
A excellent reminder that agents are less about the algorithm and much more about the environment design and evaluation process: On Building Agents From First Principles
At a high level, the loop is: prompt -> model action -> environment -> reward -> gradient update. Almost every agent-training system is a scaled-up version of this loop. A browser agent, a coding agent, a spreadsheet agent, a robotics planner, a math solver, and a diagramming agent all have the same basic structure. They differ in the environment, the action space, and the reward function. This is the part that is easy to miss when using frameworks. Libraries like TRL, Unsloth, PRIME-RL, verl, OpenRLHF, or custom internal trainers are not magic. They are mostly infrastructure around this loop: batching, rollout generation, distributed inference, reward computation, logging, reference models, clipping, checkpointing, and scaling. The conceptual core is much smaller.
Useful insight from Anthropic on their learnings from managing multi-million line repos: How Claude Code works in large codebases: Best practices and where to start | Claude

Similar theme from OpenAI: What Parameter Golf taught us
That lowered the barrier to entry. Participants could set up experiments faster, inspect unfamiliar code, and test ideas with less friction. Runpod’s sponsorship of $1,000,000 in compute also played a major role in making the challenge accessible to more people. At the same time, agent use created new issues for submission and scoring. Many submissions were small changes to existing top scorers, rather than fundamentally new approaches. This was often useful: strong ideas spread quickly and were refined by others. But it also created noise.
Retrieval redefined – search as an iterative reasoning loop
Perhaps the best retriever is no retriever at all?: Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction
We replaced the entire agentic search pipeline — embedding model, vector index, top-k retrieval — with only
grepandbash. The agent searches the raw corpus directly —grep,find,bash, shell pipelines — exactly like a coding agent navigating a codebase. No preprocess. No embedding model. No vector index. No offline indexing. DCI outperforms top baselines across 13 benchmarks.Replacing the search stack with an autonomous, iterative reasoning loop.: Can agents replace the search stack?
What’s amazing about this? I’ve barely lifted a finger. I just set up a stock LLM with some search tools. Nothing here has been fit to my data. A 0.289→0.453 jump in quality depends only on model quality + simple retrievers.
Memory needs to be more than just a vector database: How AI Agent Memory Works
Memory is a lifecycle problem: write, age, supersede, redact, forget. Watch the same input handled three different ways... Naive append leaks PII and produces contradictions. Naive overwrite loses temporal context, the agent can't answer 'where did the user used to live?'… Memory governance is what separates a one-off demo from a production agent.
Evaluation at scale – benchmarks and the 'goblin' problem
Pretty cool approaches in DeepMind's new eval framework, well worth checking out: google-deepmind/proeval.
Slash GenAI evaluation costs by up to 100x while actively discovering model failure patterns to guide better AI development.
1. Cut GenAI eval costs up to 100× — achieve ±1% accuracy with a fraction of the samples
2. Discover failure cases — proactively surface diverse bugs under strict evaluation budgets
3. Transfer learning over benchmarks — pre-trained GP surrogates generalize to new models instantly
4. Easy Integration - Easily to integrate into the GenAI evaluation systems with different modalities
5. Validated on reasoning, safety & classification — GSM8K, MMLU, StrategyQA, Jigsaw, and moreEvals in legal workflows: Introducing Harvey’s Legal Agent Benchmark

This is a sobering look at why agents still struggle with 'taste' and qualitative depth compared to humans.: Exploring Agent-Assisted Qualitative Analysis
Qualitative analysis is also hard for AI to do because the ‘right’ analysis depends heavily on context outside the corpus itself. In the PhD example above, one researcher might focus on advisor relationships and build a theory around mentorship breakdown, while another might focus on identity, isolation, or academic incentives. Neither analysis is necessarily wrong; they are emphasising different aspects of the same interviews based on what they think is important and what question they are ultimately trying to answer.
The 'goblin' phenomenon: Where the goblins came from
That creates a feedback loop: 1. Playful style is rewarded 2. Some rewarded examples contain a distinctive lexical tic. 3. The tic appears more often in rollouts. 4. Model-generated rollouts are used for supervised fine-tuning (SFT). 5. The model gets even more comfortable producing the tic. A search through GPT‑5.5’s SFT data found many datapoints containing “goblin” and “gremlin.” Further investigation revealed a whole family of other odd creatures: raccoons, trolls, ogres, and pigeons were identified as other tic words, while most uses of frog turned out to be legitimate.
Frontier approaches – from thermodynamic hardware to tabular foundation models
RVFL networks offer an innovative low-cost way to get non-linear power without the usual backpropagation headache.: T. Moudiki's webpage
Random Vector Functional Link (RVFL) networks offer a simple yet powerful alternative to traditional neural networks for tabular data. Instead of learning hidden layers through backpropagation, RVFL generates them randomly (or not, if using a deterministic sequence of quasi-random numbers) and focuses all learning effort on a final, regularized linear model.
Using the physical relaxation of oscillators to solve matrix inversions for Gaussian Processes via analogue hardware.: gpr-thermodynamic-hardware/
In the thermodynamic framework described by the paper, a matrix A defines the coupling (or potential energy landscape) of a system of harmonic oscillators. If you apply a constant external force b to the oscillators, the system will eventually settle into a thermal equilibrium. The mean position (average state) of the oscillators in this equilibrium state naturally corresponds to the solution of the linear system.
Getting down in the statistical weeds
Steering is back in vogue, offering a way to perform 'brain surgery' on models without the heavy fine-tuning.: DeepSeek-V4-Flash means LLM steering is interesting again
The basic idea behind steering is extracting a concept (like “respond tersely”) from the model’s internal brain state, then reaching in during inference and boosting the numerical activations that form that concept. One way you might do this is to feed your model the same set of a hundred prompts twice, once with the normal prompts and once with the words “respond tersely” appended. Then measure the difference in the model’s activations for each prompt pair (by subtracting one activation matrix from the other). That’s your “steering vector”.
You know you want it! A deep dive into the softmax Jacobian and why its so useful for memory: Softmax, can you really derive the Jacobian? And should you care? — idlemachines
The second term is an outer product, which means it has rank 1. So the full Jacobian is a diagonal matrix with a rank-1 correction. This is exactly why we can compute the backward pass efficiently. Instead of working with an n x n matrix, we only need a dot product and a few elementwise operations. The structure of the Jacobian is doing all the work for us.
Linear PCA doesnt generally work well with transformer embeddings; a polynomial fit might be the answer: Polynomial autoencoder
The most direct way to compress an embedding (other than quantization) is to fit PCA on the corpus and keep the top-d eigenvectors. It works, but PCA is a linear projection, and neural-network embeddings on the sphere are structurally nonlinear — the well-known cone effect in transformers. Some of the variance lives in a nonlinear tail that a linear decoder can’t reach. This post is about a closed-form way to add a quadratic decoder on top of PCA, to capture part of that nonlinear tail. The encoder stays as plain PCA.
Deep dive into survival analysis: Learning & Exploring Survival Analysis Part 1 - A Note To Myself | Everyday Is A School Day

Ever wondered how Shazam works? Wonder no more!: How The Heck Does Shazam Work? (An Interactive Exploration)
The algorithm gives every peak a turn as an anchor. For each one, it defines a target zone to its right (a window of time and frequency) and pairs the anchor with every peak inside that zone. Each pair generates a compact hash from three numbers: the two frequencies and the time difference between them. You can think of a hash as a short string of characters that acts like a shorthand code: the same three inputs will always produce the same hash, but even a tiny change in any input produces a completely different one.




Engineering and Infrastructure
Optimising the engine: from formal requirements for AI agents to the raw physics of local hardware
Catching requirement bugs before they become code: Requirements analysis: catching requirement bugs before they become code

You know you want your own local model!: Localmaxxing
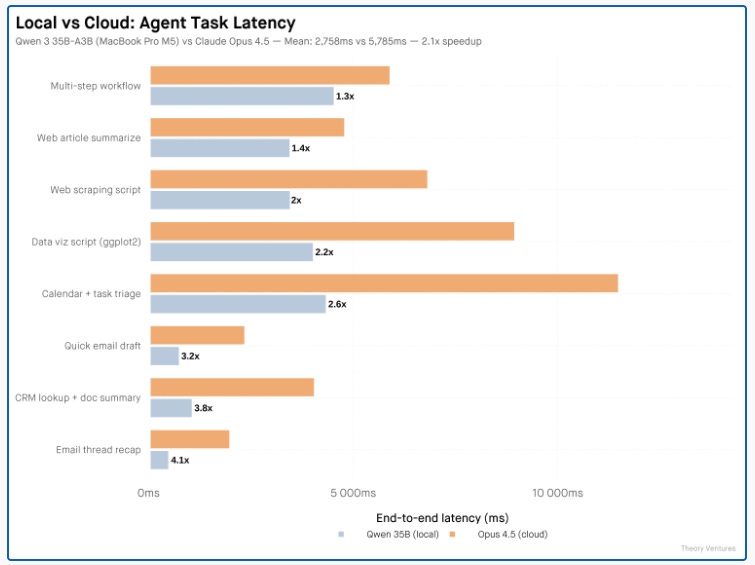
It turns out memory bandwidth, not raw compute, is the real bottleneck for local inference setups.: @adlrocha - In a quest to becoming AI-independent

A great reminder that even classic algorithms like binary search can be outpaced by optimising for modern hardware parallelism.: You can beat the binary search


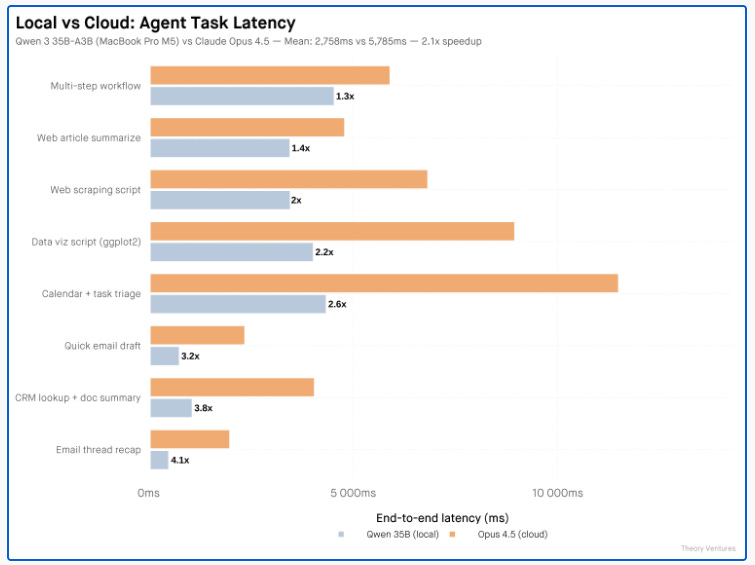


Bigger picture ideas
Longer thought provoking reads
A recent experience with ChatGPT 5.5 Pro - Timothy Gowers (field medallist):
I would judge the level of the result that ChatGPT found in under two hours to be that of a perfectly reasonable chapter in a combinatorics PhD. It wouldn’t be considered an amazing result, since it leant very heavily on Isaac’s ideas, but it was definitely a non-trivial extension of those ideas, and for a PhD student to find that extension it would be necessary to invest quite a bit of time digesting Isaac’s paper, looking for places where it might not be optimal, familiarizing oneself with various algebraic techniques that he used, and so on.
Project Glasswing: what Mythos showed us - Grant Bourzikas:

Predicting AI job exposure — Benedict Evans - Benedict Evans:

World Models Can Change Everything - James Wang:

Choosing to Stay Human - Ethan Mollick:
By short-circuiting effort, you short-circuit learning. That is why the initial results of AI on learning in classrooms can be so worrying. Yet we can see a different result in a second paper... from many of the same authors when they ran a five-month Python course across ten high schools in Taipei... Students who were given a personalized sequence of problems by an AI tutor scored 0.15 standard deviations higher on a final exam taken without AI help. By some estimates, that’s the equivalent of six to nine months of additional schooling.



Fun Practical Projects and Learning Opportunities
A curious collection of fun things
Taking Karpathy's local Wiki approach to the next level- a great personal project: LLM Wiki v2
A pattern for building personal knowledge bases using LLMs. Extended with lessons from building agentmemory 10K Stars ⭐️, a persistent memory engine for AI coding agents.
How do you locate a device without GPS?: Marco Polo
Kalman filters are the gold standard for state-space estimation in physical spaces, and are exactly what we need to solve our problem. They operate on the principle of having an internal estimation of the unobservable true state — in this case, the relative position — which is updated with new information we get from measurements in a looping process.
19th-century 'Polish System' for visualising history as a spatial grid: Visualizing History: The Polish System

How do New Yorkers react to the first snow?: Bad Weather and the Subway

Tracking seventy years of Eurovision lyrics: 70 years of love, empowerment, and freedom. Here's a look at Eurovision by its lyrics.

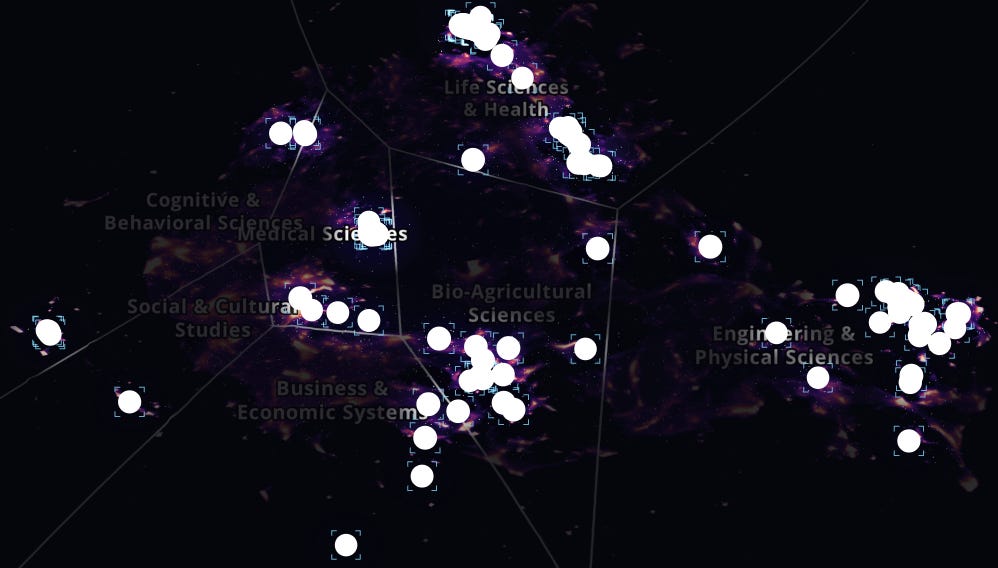
Nothing like a pretty interactive map!: TGRS — The Global Research Space



Updates from Members and Contributors
Mia Hatton, Senior Engagement Manager, Department for Business and Trade, shares the following update:
"The data team in the Department for Business and Trade have been tackling the challenge of making sensitive, live data available to their suite of AI tools without compromising security. Read about their approach using a Model Context Protocol (MCP) server and existing SSO, which allows investment advisors to quickly access a wealth of information from our CRM system, greatly enhancing their capacity to support businesses."
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you’d like to advertise
Napier AI are hiring for a data scientist in their Belfast office - this would suit someone with several years of commercial experience who can take models from research to production. You must be a UK national and already physically located in the Belfast area. You can submit your CV via a speculative application here: Register Your Interest | Napier AI Careers
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
Piers
The views expressed are our own and do not necessarily represent those of the RSS