
May Newsletter
Industrial Strength Data Science and AI

Hi everyone-
May is here! Spring time sunshine (hopefully) and a steady stream of bank holidays (in the UK at least…) so plenty of time to catch up on your Data Science and AI reading.
Lots of great content below and I really encourage you to read on, but here are the edited highlights if you are short for time!
The Mythos Threshold - Joe Reis
The Gap in understanding of AI capability - Andrej Karpathy
Emotion concepts and their function in a large language model - Anthropic Research
Components of A Coding Agent- Sebastian Raschka
The Revenge of the Data Scientist - Hamel Husain
Following is the latest edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications and howtoguides; engineering_tips; big picture ideas; fun; reader updates; jobs
Committee Activities
Our new journal is up and running (RSS: Data Science and Artificial Intelligence)
There is a new call for paper for the journal- the very relevant topic of “Uncertainty in the Era of AI” (Deadline 31 July 2026)
We just held our latest meetup and discussion on “How to stay up to date as a data scientist?” which included an entertaining fireside chat between Giles Pavey and Piers Stobbs. It was well attended with some great discussion. For those who missed it here are the sources Piers mentioned (in addition to Raindrop, for managing bookmarks)
TLDR (AI and Data newsletters); The Batch from Andrew Ng; Data Science Weekly; Import AI from Jack Clark; One Useful Thing from Ethan Mollick; Benedict Evans newsletter and Exponential View from Azeem Azhar.
Hold the date for the second in our series of essential skills for data scientists with "How to write code you can be proud of" on 28th May.
Our Chair, Janet Bastiman, and committee member Matt Forshaw will both be at Datalyst 2026 in Newcastle upon Tyne on 26th June as part of an engaging panel session on Governance, Ethics, and Legalities. Tickets for this great all day event still have an early bird discount and are available on eventbrite: Datalyst 2026 Tickets, Friday 26 June • 8:30 - 17
Check out the RSS blog Real World Data Science
The latest big question video: What Excites you in data science at the moment?
The section has been heavily involved in the RSS AI Task Force work- update here with the published response to the government’s plans for an AI Growth Lab here
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
Whether and how to regulate AI remains a hot topic
The incredibly rapid rise of OpenClaw usage in China is sparking increased discussion around security and privacy
Indeed, the AI phone has caused an uproar in China. Within days, many of China’s biggest apps blocked the Doubao phone. They saw it as a serious risk to data security. Built into the operating system of the phone itself, it has a kind of master key that gives the embedded AI agent blanket access to the screen, all app content, and the ability to tap or click as if it were a user. Critics dubbed the agent a “burglar” with “god’s fingertips” increasing risks of malicious input and intrusion attacks by criminal actors. For the banks, it was impossible to distinguish actions taken by the agent and those of the user, creating myriad vulnerabilities for fraud and hacking.But on Monday, Gov. Gavin Newsom of California, a Democrat, defied Mr. Trump by issuing an executive order that requires safety and privacy guardrails for A.I. companies contracting with the state. He also said he would fight to preserve California’s laws that provide safeguards against A.I.-related catastrophic harms, scams and risks for children.Meanwhile there is lots of thought going into the different types of policies that society may need: The Windfall Trusts’s Looking for a specific policy? looks like a useful resource

Like it or not, AI keeps impacting more and more areas of business and society
AI is clearly being used to attempt to sway elections- Hundreds of Fake Pro-Trump Avatars Emerge on Social Media
Health is one of the most popular topics researched on chatbots, but how accurate are they in their responses? It depends on what context they are given it seems.

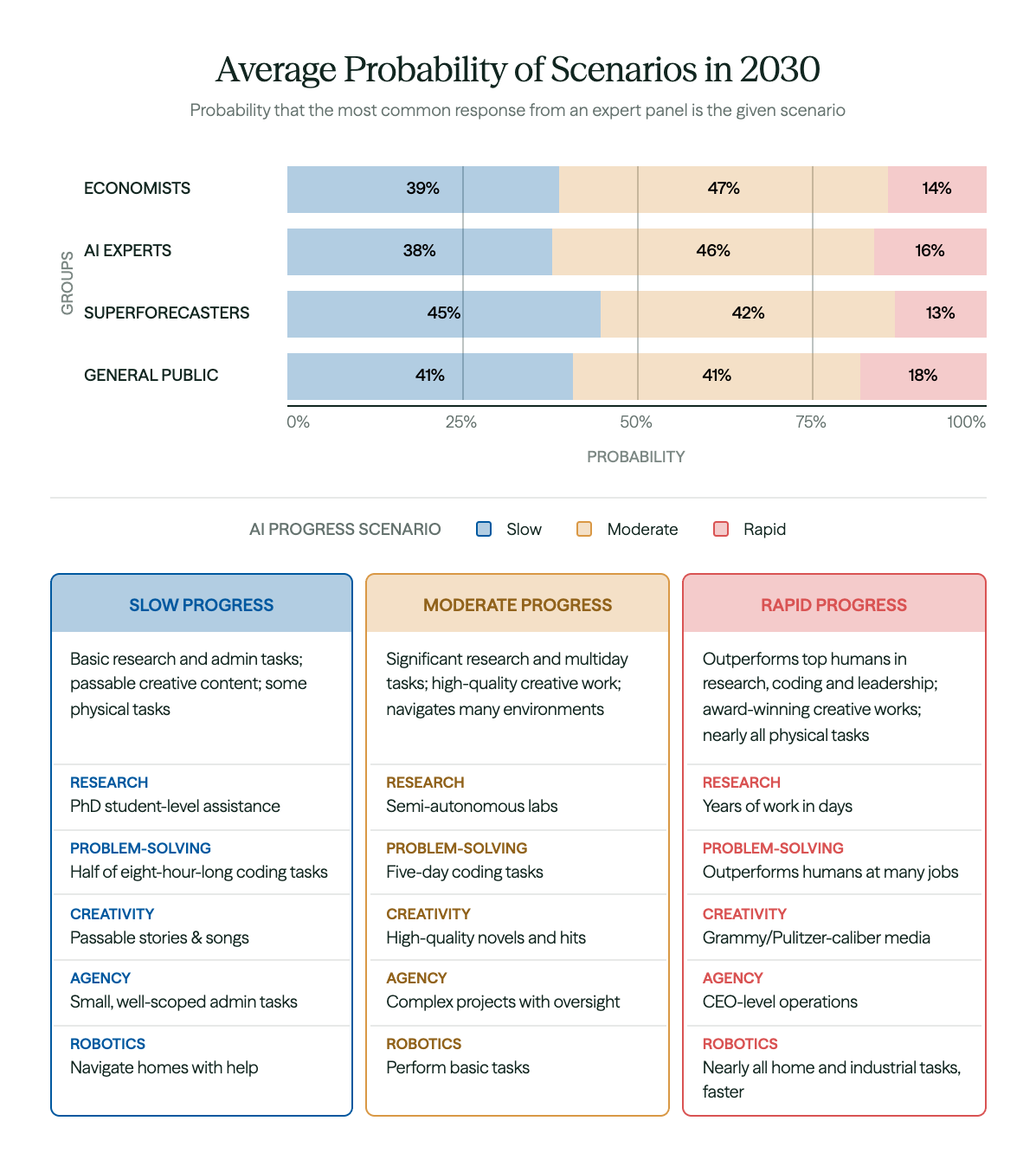
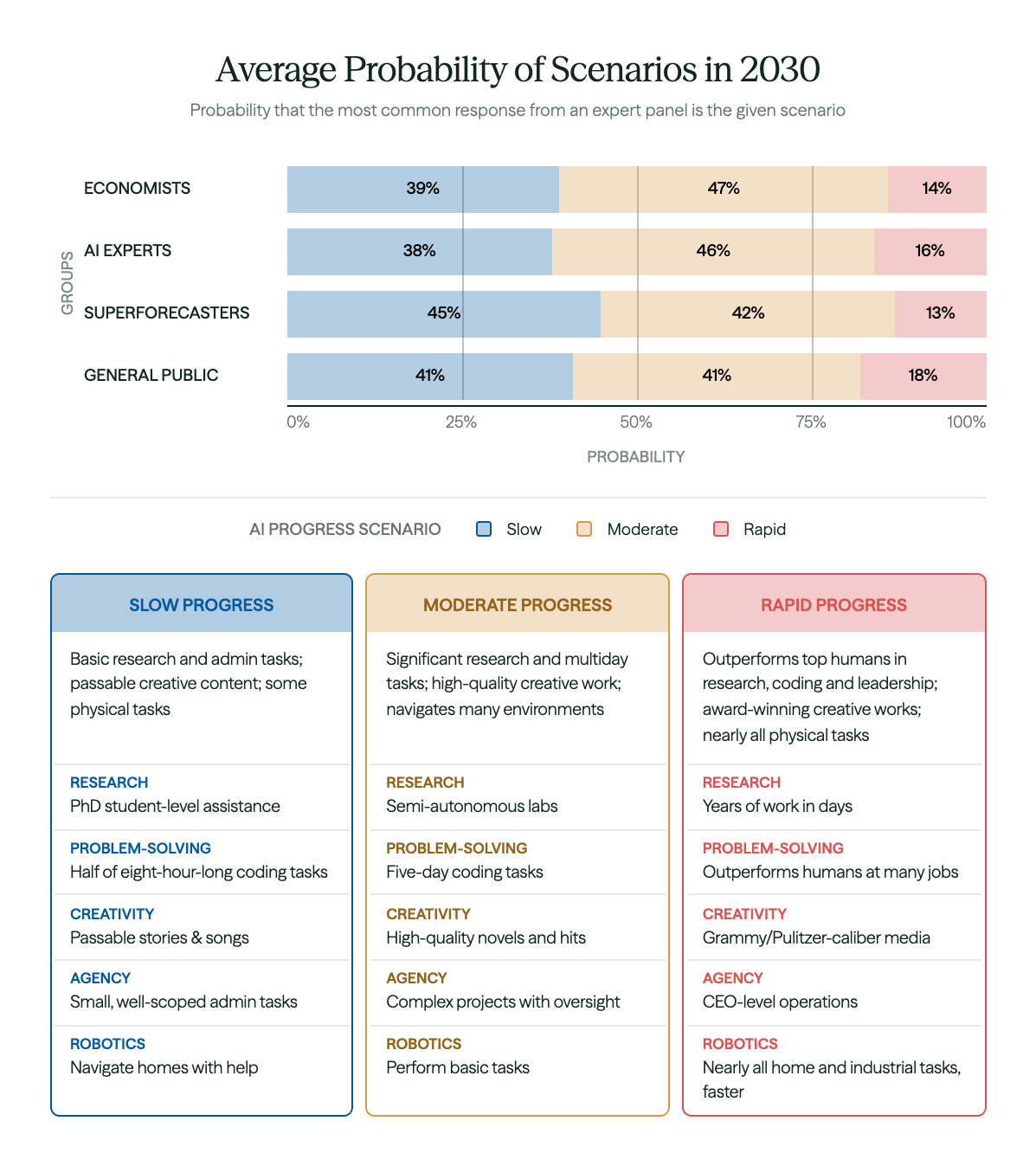
How much impact is AI going to have on economies? No one is sure, but some think the impact will be very large
Good comparison here with what happened to travel agents with the advent of the internet- A case study in job displacement
So the decline of travel agents was driven largely by technological displacement. AI is a very different kind of shock from the internet of the 1990s, and its effects on labor markets may turn out to be quite different too. But the story of the travel agent is still instructive, because it demonstrates what happens to workers when a technology renders their profession obsolete. As it turns out, the story is not entirely bleak.And when it comes to using AI, more research is showing that the short term gain could well come at the expense of longer term harm

Meanwhile, experts are becoming increasingly worried about cybersecurity risks
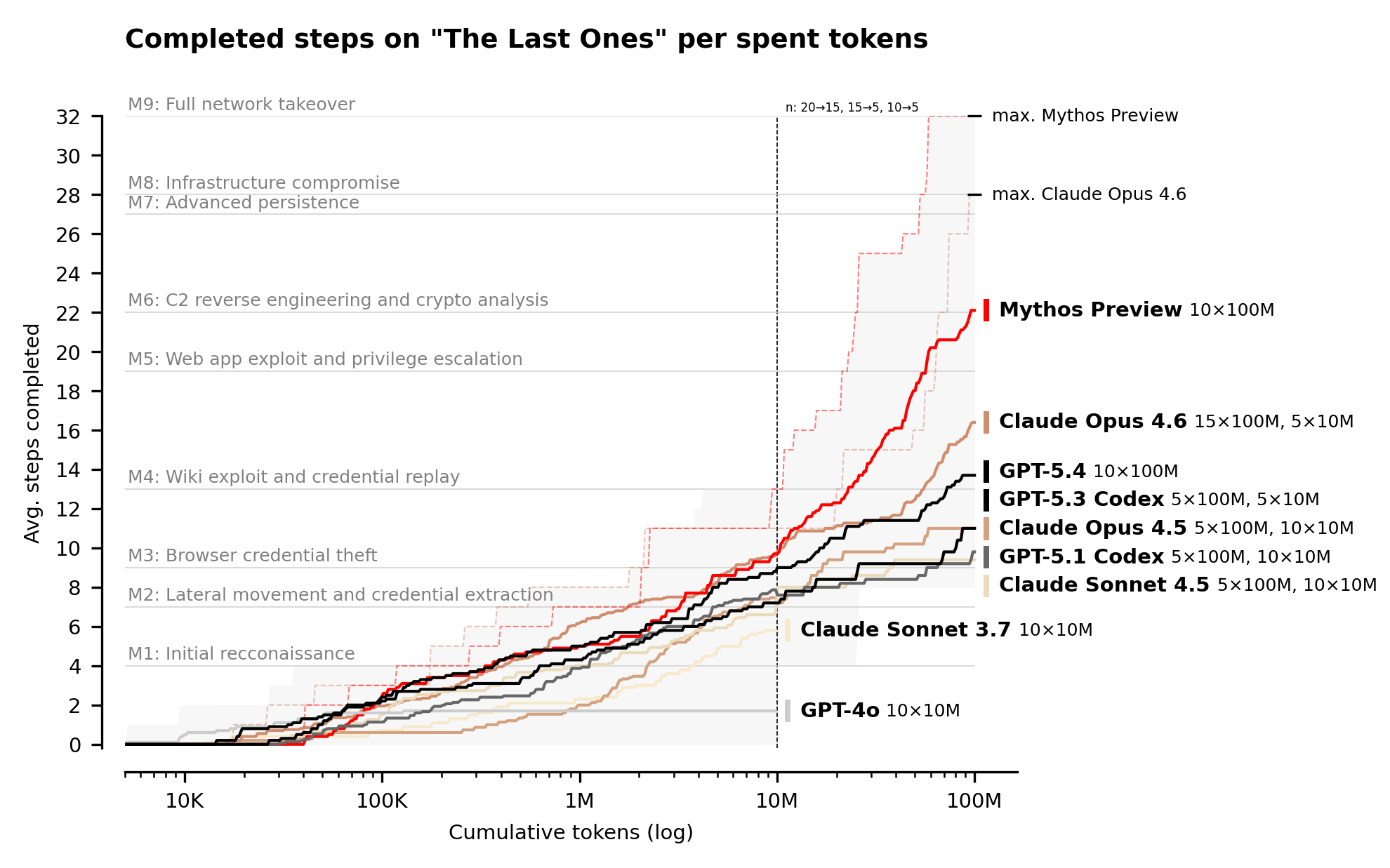
And then a couple of days later, Claude Mythos and Project Glasswing are released (more on this in later sections)
Mythos Preview has already found thousands of high-severity vulnerabilities, including some in every major operating system and web browser. Given the rate of AI progress, it will not be long before such capabilities proliferate, potentially beyond actors who are committed to deploying them safely. The fallout—for economies, public safety, and national security—could be severe. Project Glasswing is an urgent attempt to put these capabilities to work for defensive purposes.Finally… the robots are getting better! Robots beat human records at Beijing half-marathon






Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
Good to see some interesting research from outside of the big industrial labs
First there is Aurora from Together.ai: improving speculative decoding- where a small, fast “draft” model is used to predict multiple future tokens, which a larger “target” model verifies in parallel
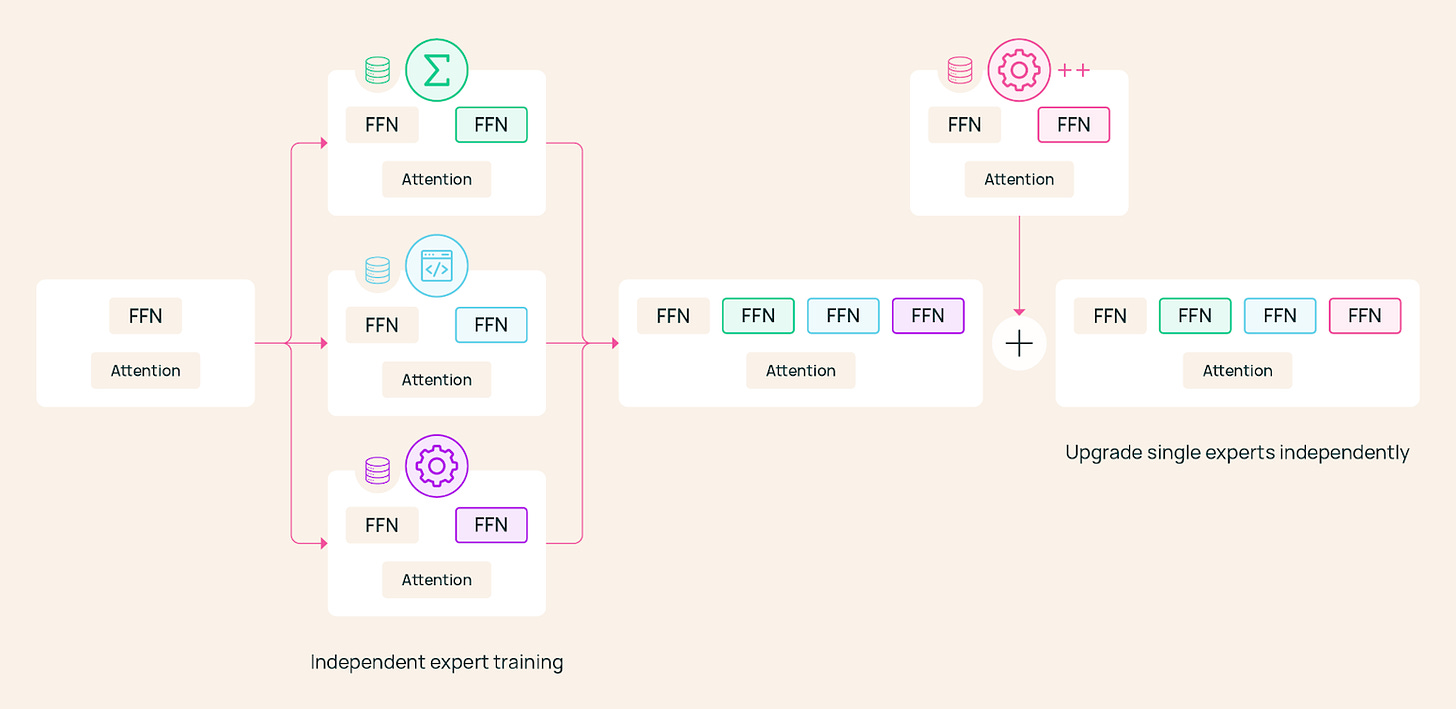
Speculative decoding goes stale in production — draft models can drift and offline retraining can't always keep pace. Aurora fixes this. It's an open-source, RL-based framework that learns directly from live inference traces and continuously updates the speculator without interrupting serving. Key results: → Real-time adaptation across shifting traffic domains → 1.25x additional speedup over a well-trained static speculator The headline finding: online training from scratch can outperform a carefully pretrained static baseline.Then we have the ever-impressive Allen Institute with an innovative approach to modular post-training: Branch-Adapt-Route
Of course Deep Mind is pretty irrepressible on the research front:
A new approach to image-text encoding: TIPSv2

And a more philiosophical piece: The Abstraction Fallacy: Why AI Can Simulate But Not Instantiate Consciousness (thanks Dirk!)- needs a quiet room and some time, but worth the effort!
The framework proposed here explicitly separates simulation (behavioral mimicry driven by vehicle causality) from instantiation (intrinsic physical constitution driven by content causality). Establishing this ontological boundary shows why algorithmic symbol manipulation is structurally incapable of instantiating experience.
Anthropic continues do excellent work in interpretability, looking for structures in the weights that seem to encompass specific concepts: Emotion concepts and their function in a large language model

How stable are modern LLMs- excellent work from Nvidia in identifying how changes in certain key weights can change outputs dramatically
Deep neural networks are vulnerable to catastrophic failure from flipping just a few sign bits in model parameters. We present Deep Neural Lesion (DNL), a data-free method that identifies and exploits critical parameters across vision and language domains. Our approach requires only write access to stored weights—no training data, no optimization, minimal computation. This makes it practical under realistic threat models where attackers compromise model storage through firmware exploits, rootkits, DMA attacks, or Rowhammer vulnerabilities. - ResNet-50: 2 sign flips → 99.8% accuracy drop - Mask R-CNN / YOLOv8-seg: 1–2 flips collapse detection and segmentation - Qwen3-30B & Nemotron 8B: Few flips reduce reasoning and task accuracy to near-zeroThought provoking and a bit disconcerting: when we think about “Chain-of-thought” we assume the model first reasons a plan, and then follows the plan to the answer. What if it was the other way around? Therefore I am. I Think (I did check and it’s not an April Fool!)
In this paper, we present evidence that detectable, early-encoded decisions shape chain-of-thought in reasoning models. Specifically, we show that a simple linear probe successfully decodes tool-calling decisions from pre-generation activations with very high confidence, and in some cases, even before a single reasoning token is produced.Applying the LLM concepts to different data sets
Very cool: CLIP (encoding images in the same vector space as text), but for geospatial data: UniGeoCLIP - results look impressive on geospatial problems

Must Read- an excellent example of applying the concepts of LLMs to different types of data: PRAGMA: Revolut Foundation Model
Our approach pre-trains a Transformer-based architecture with masked modelling on a large-scale, heterogeneous banking event corpus using a self-supervised objective tailored to the discrete, variable-length nature of financial records. The resulting model supports a wide range of downstream tasks such as credit scoring, fraud detection, and lifetime value prediction: strong performance can be achieved by training a simple linear model on top of the extracted embeddings and can be further improved with lightweight fine-tuning. Through extensive evaluation on downstream tasks, we demonstrate that PRAGMA achieves superior performance across multiple domains directly from raw event sequences, providing a general-purpose representation layer for financial applications.And then there’s drumming! DexDrummer: In-Hand, Contact-Rich, and Long-Horizon Dexterous Robot Drumming

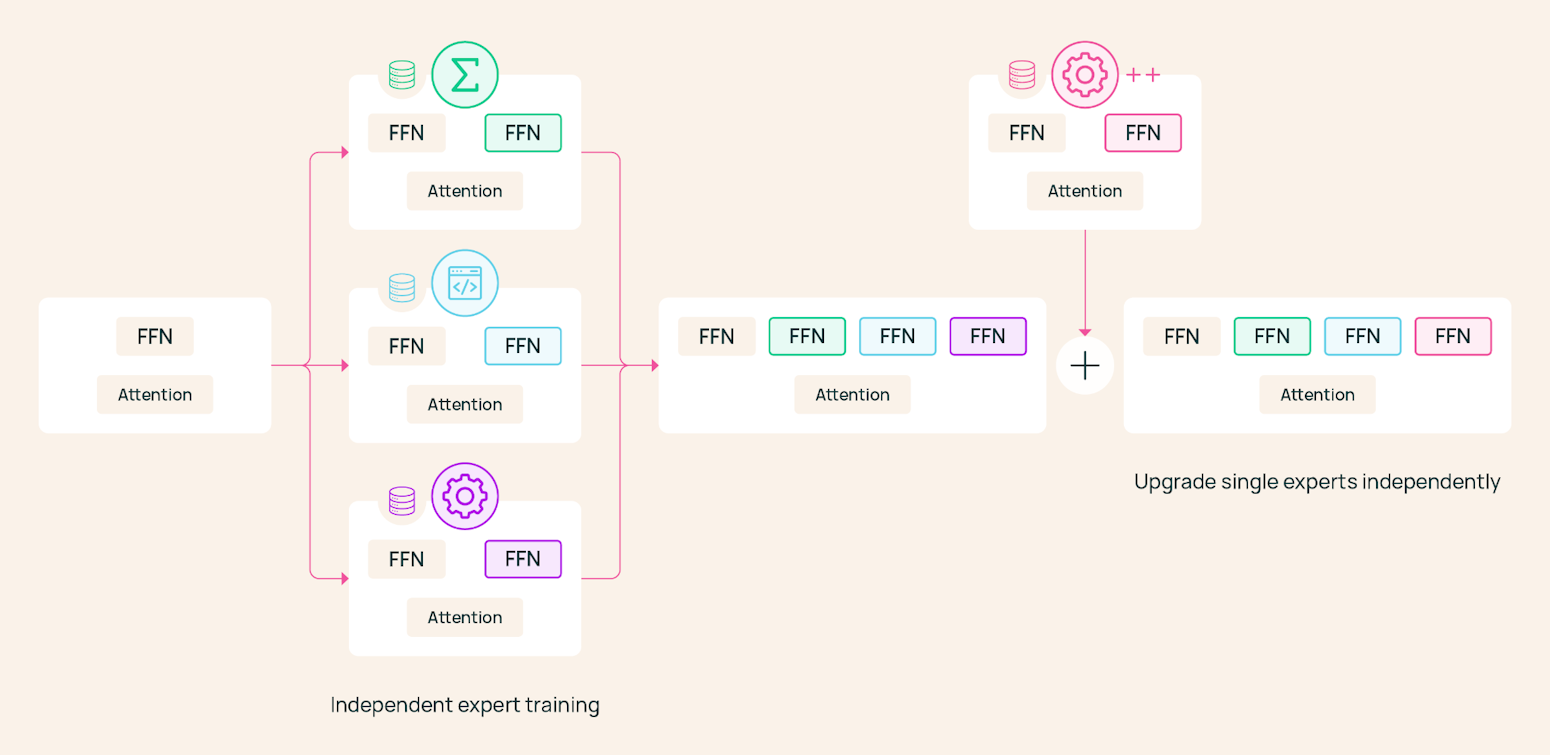




Generative AI ... oh my!
Developments in the wild world of large language models, foundation models, world models...
Before we delve into the company updates, I thought it would be useful to look at a couple of key themes across the big three: Security, Coding, and Agent infrastructure
Security
On the security front (as mentioned above) the big news was the release (or non-release) of Anthropic’s Claude Mythos and Project Glasswing which caused a good deal of consternation: AI Security Institute Review, Simon Willison review (“Saying “our model is too dangerous to release” is a great way to build buzz around a new model, but in this case I expect their caution is warranted.”)
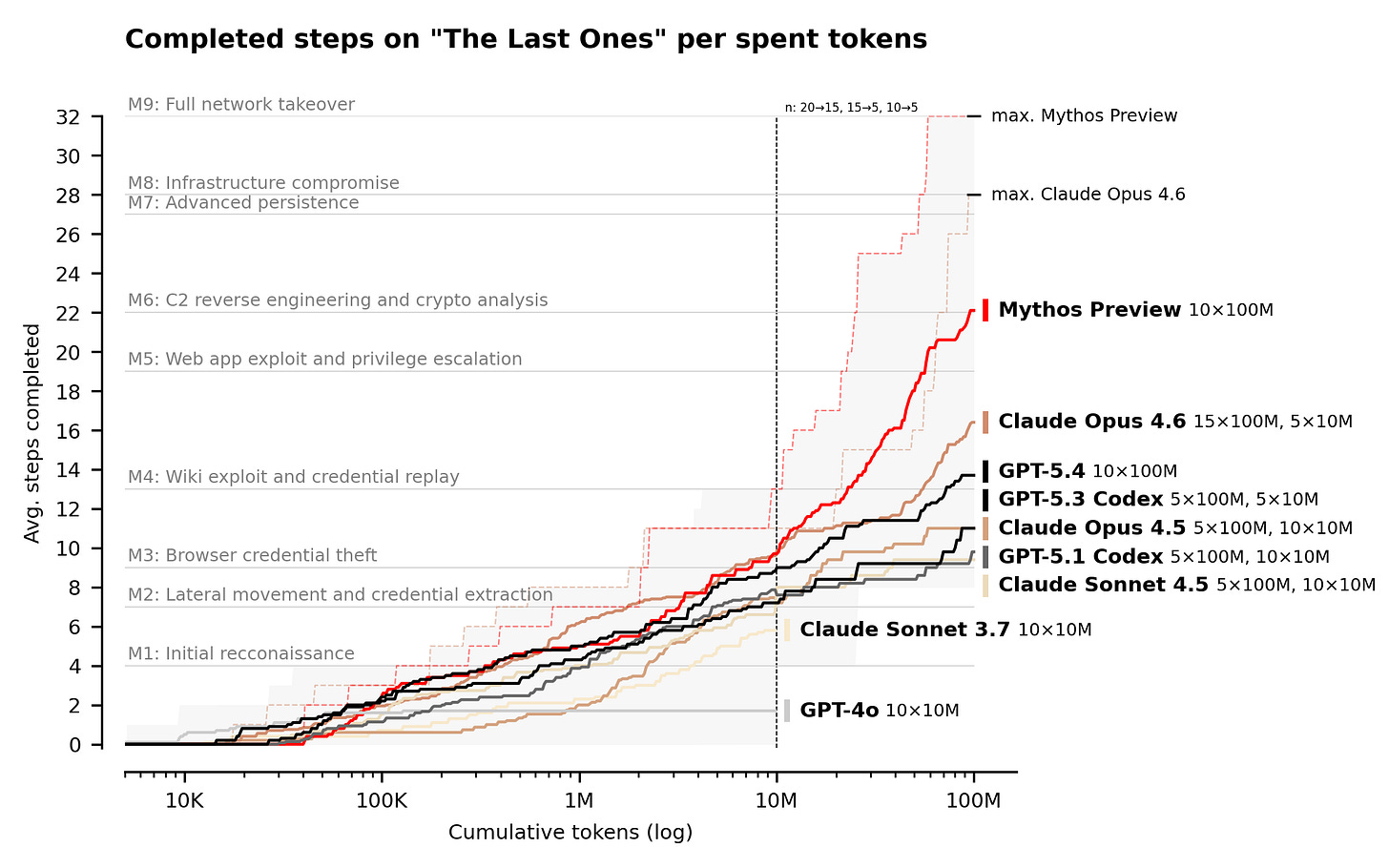
Sam Altman (OpenAI CEO) “throws shade at Anthropic’s cyber model, Mythos” while releasing their own new cyber model (GPT-5.4-Cyber)
While Google released their new Sec-Gemini v1 model earlier in April
Agent based Coding and Coworking
The leading commercial coding agents are OpenAI’s Codex and Claude Code and they are increasing impressive- well worth trying - and also now driving significant revenues (as well as footholds in the enterprise world) for both companies. Google is less well placed in this space- the Gemini CLI is functional but generally viewed less favourably
This month OpenAI expanded the capabilities of Codex, while Claude improved both Code and Cowork
Agent Infrastructure
Agents generally perform longer running tasks and require more orchestration- which can be much harder to productionise than a simple LLM call. Given this, the race to “host” AI agents is definitely heating up with OpenAI’s workspace agents, new capabilities from Anthropic (“scaling managed agents”), and Google’s new Gemini Enterprise Agent Platform
Back on the round-up front, OpenAI had a busy month:
On the top of the Security, Codex and Agent updates, they released a brand new model GPT 5.5 (5.4 was only released last month)
New capabilities for developers with Chronicle (Codex memories from recent screen context) and Agents SDK updates
And a new image model: ChatGPT Images 2.0

But there is more unwanted coverage of Sam Altman: “I think there’s a small but real chance he’s eventually remembered as a Bernie Madoff- or Sam Bankman-Fried-level scammer.”
Google is so impressive at progressing capabilities across a huge range:
Lots of focus on embedding AI into products: AI mode in Chrome, AI overviews in Gmail, new video creation tools
Lots more capabilities for developers: Veo 3.1 Lite for cost effective video generation, Gemini 3.1 Flash TTS for expressive AI speech, Deep Research Max for autonomous agents, and subagents for Gemini CLI
And then there’s Gemma 4 an impressively capable open model, readily fine-tuned - oh, and then there’s robotics!
, scissors (1), paintbrushes (1), pliers (6), and a collection of garden tools which can be interpreted as a single group or multiple points. It does not point to requested items that are not present in the image — a wheelbarrow and Ryobi drill. In comparison Gemini Robotics-ER 1.5 fails to identify the correct number of hammers or paint brushes, misses the scissors altogether, hallucinates a wheelbarrow and lacks precision on plier pointing . Gemini 3.0 Flash is close to Gemini Robotics-ER 1.6, but does not handle the pliers as well.")
Anthropic is definitely making waves
We had the much acclaimed Mythos launch covered above, and also a new flagship model - Opus 4.7
A new application- Claude Design
Although we also had less positive news with the leak of Claude Code’s source code, and concerns that Mythos was breached already.
Meta is potentially back in the game, with the first release from their expensively assembled Superintelligence Labs - Muse Spark
And even Microsoft is releasing: 3 new world class MAI models, available in Foundry
On the Open Source front:
The Chinese contingent continue to impress-
Deep Seek is back with V4, which again raises the bar on cost effective performance
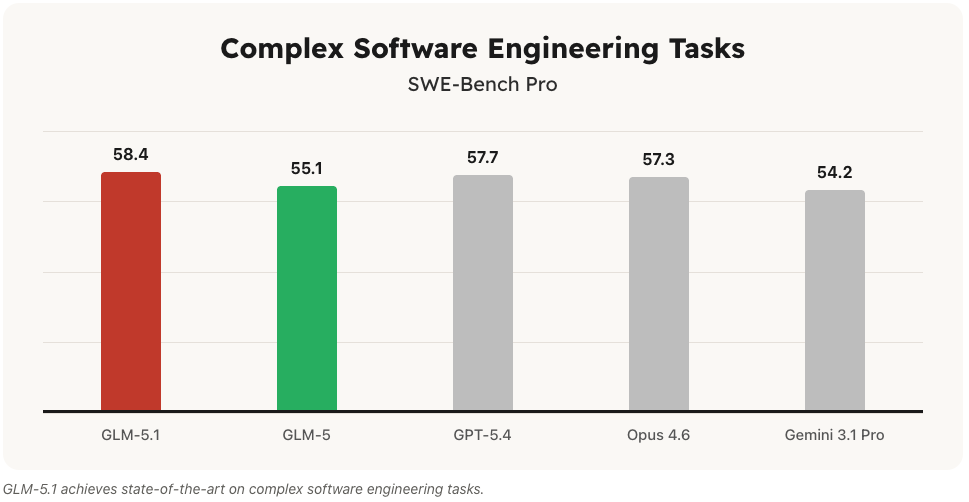
We have GLM-5.1 from Z.ai which seems strong for software engineering
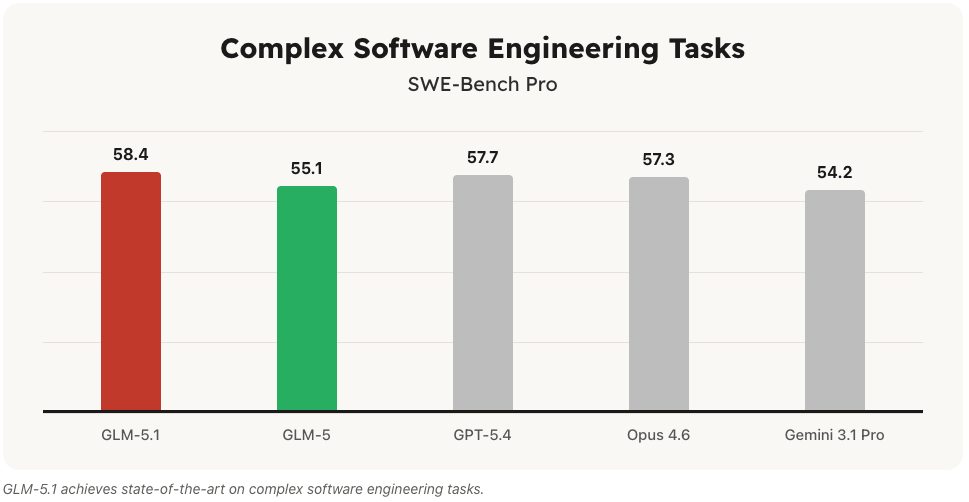
Qwen3.6-Max from Alibaba which also seems strong for coding tasks
Moonshot released Kimi2.6 (Kimi2.5 is already considered a great cost effective option for coding agents)

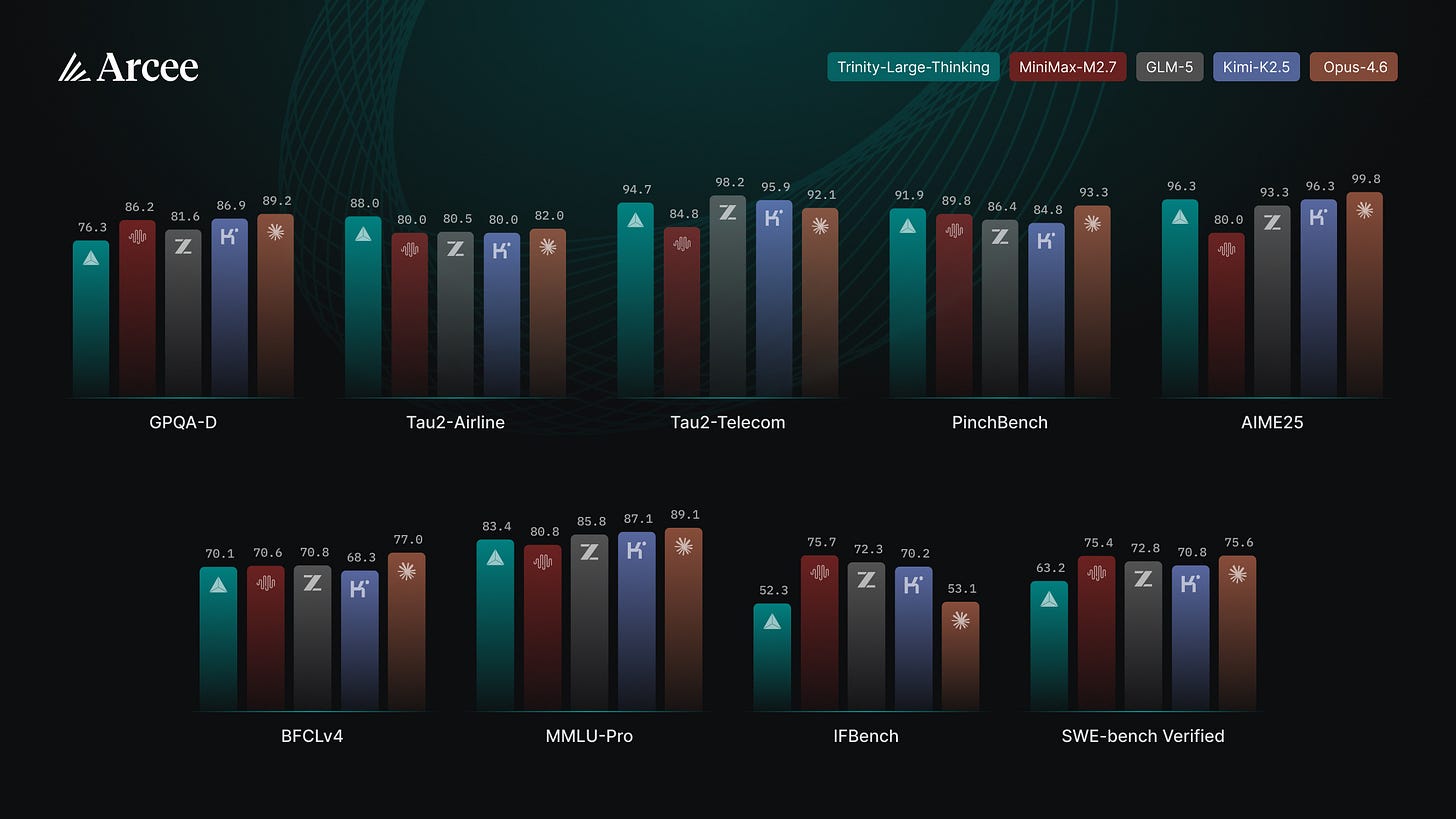
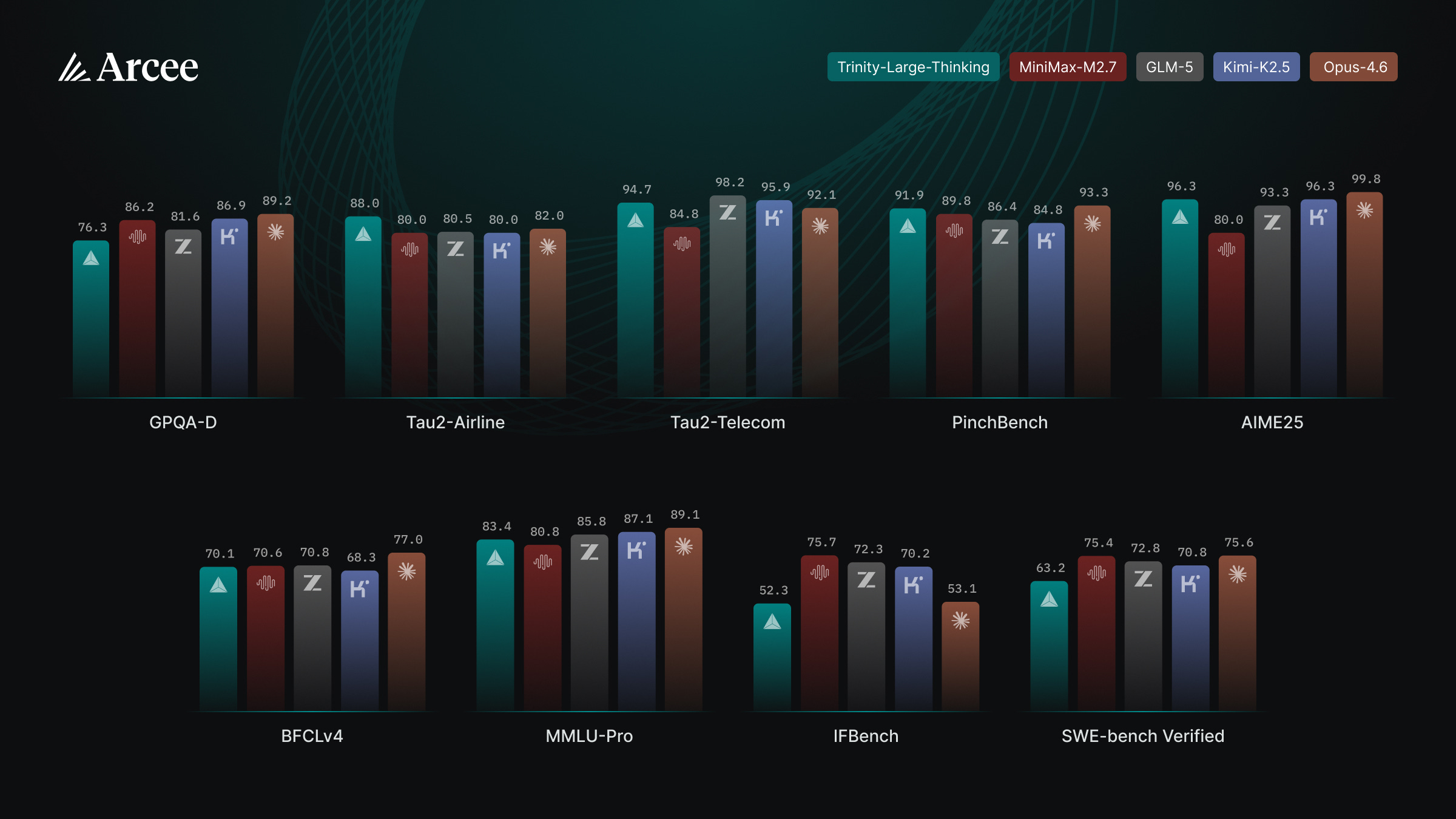
And the novelty of a new open source model from a non-Chinese lab: Trinity-Large-Thinking from Arcee in the US (why not Europe?)

, scissors (1), paintbrushes (1), pliers (6), and a collection of garden tools which can be interpreted as a single group or multiple points. It does not point to requested items that are not present in the image — a wheelbarrow and Ryobi drill. In comparison Gemini Robotics-ER 1.5 fails to identify the correct number of hammers or paint brushes, misses the scissors altogether, hallucinates a wheelbarrow and lacks precision on plier pointing . Gemini 3.0 Flash is close to Gemini Robotics-ER 1.6, but does not handle the pliers as well.")

Real world applications and how to guides
Lots of applications and tips and tricks this month
First on the application side:
If you are in the business of writing research papers, PaperOrchestra might be worth having a look at
Writing a research paper is brutal. Even after the experiments are done, a researcher still faces weeks of translating messy lab notes, scattered results tables, and half-formed ideas into a polished, logically coherent manuscript formatted precisely to a conference’s specifications. For many fresh researchers, that translation work is where papers go to die. A team at Google Cloud AI Research propose ‘PaperOrchestra‘, a multi-agent system that autonomously converts unstructured pre-writing materials — a rough idea summary and raw experimental logs — into a submission-ready LaTeX manuscript, complete with a literature review, generated figures, and API-verified citations.And how about a foundation model for Fluid Dynamics? Walrus
Walrus was trained on 19 different physical scenarios spanning 63 physical variables in both 2 and 3D. Walrus utilizes new tools for adaptive computation and improved stability in order to achieve accurate long-term rollouts while co-adapting sampling and distribution to improve training throughput despite handling varying dimensions, resolutions, and aspect ratios.Learn while you code: your personal coding tutor in Google Colab
Putting AI to good use- tracking authoritarian regimes: PropagandaScope
I searched for it in PropagandaScope. The result confirmed what I had suspected but could not prove. State media had been saturating minority regions with this phrase for years. Xinjiang Daily used it at 17.4 times the rate of People’s Daily. Tibet Daily, 12.1 times. Ningxia Daily, 10.3 times. The places with the highest ethnic minority populations received the heaviest propaganda. The places China calls “autonomous” had the least autonomy over their own newspapers.Useful - Google quietly launched an AI dictation app that works offline
Woah - Training mRNA Language Models Across 25 Species for $165
We built an end-to-end protein AI pipeline covering structure prediction, sequence design, and codon optimization. After comparing multiple transformer architectures for codon-level language modeling, CodonRoBERTa-large-v2 emerged as the clear winner with a perplexity of 4.10 and a Spearman CAI correlation of 0.40, significantly outperforming ModernBERT. We then scaled to 25 species, trained 4 production models in 55 GPU-hours, and built a species-conditioned system that no other open-source project offers.
Lots of great tutorials and howto guides:
Coding Agents are become very powerful, and well worth exploring. A few pointers:
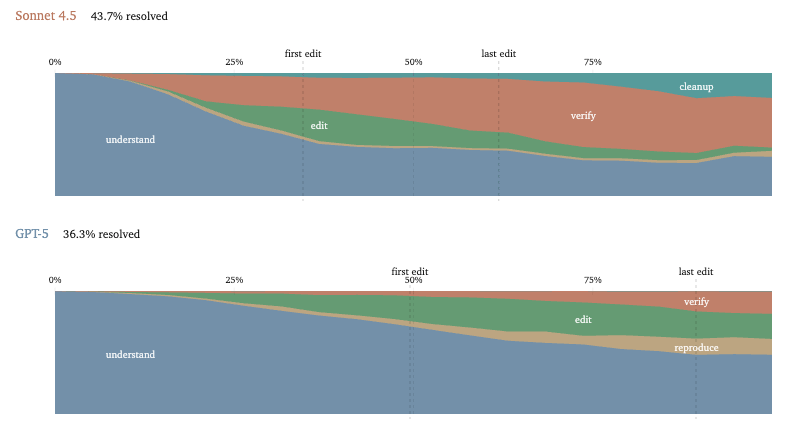
Components of A Coding Agent (from the excellent Sebastian Raschka)
So, in short, we can summarize it like this: - LLM: the raw model - Reasoning model: an LLM optimized to output intermediate reasoning traces and to verify itself more - Agent: a loop that uses a model plus tools, memory, and environment feedback - Agent harness: the software scaffold around an agent that manages context, tool use, prompts, state, and control flow - Coding harness: a special case of an agent harness; i.e., a task-specific harness for software engineering that manages code context, tools, execution, and iterative feedbackThe Claude Code’s source code was accidentally leaked - didn’t take too long for some detailed analysis of how it works to appear

Improve coding agents’ performance with Gemini API Docs MCP and Agent Skills
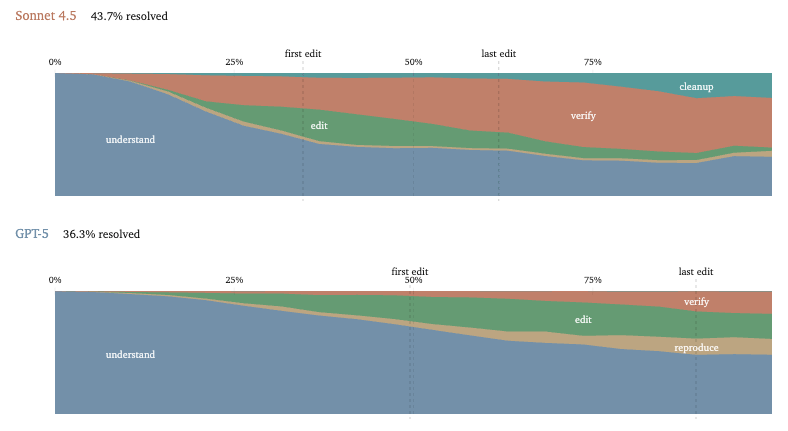
How do we evaluate coding agents? Interesting insight: Trajectory shapes
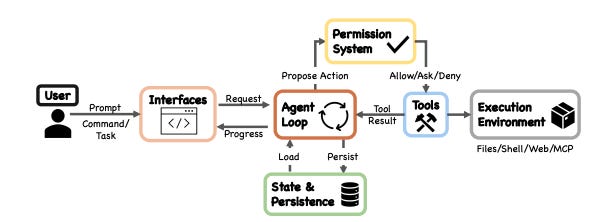
What is an agent harness I hear you ask? The Anatomy of an Agent Harness

I still find Reinforcement Learning a bit mystical if I’m honest- I found this to be a useful summary for how you might use it for LLM Agents

I’ve come across DSPy a number of times, and really want to use it and like it- but still havnt quite found the right use case. I found this to be a good actual example of its implementation: How we optimized Dash’s relevance judge with DSPy
DSPy allows you to define that setup—task, data, and metric—and then systematically search for prompt variants that improve performance on that metric. We used DSPy’s GEPA optimizer (a method that iteratively improves prompts by analyzing where the model disagrees with humans and generating feedback) to adapt and optimize the relevance-judging program for a specific target model—in this case, gpt-oss-120b.Nothing like “naively reimplementing a paper in PyTorch”! What I Learned Building Attention Residuals from Scratch
I wanted to understand how transformers actually route information between layers. Not at the level of “attention computes weighted averages,” but at the level of what physically happens to a tensor as it moves through the network. What gets preserved, what gets overwritten, and why. A video helped build some of the initial intuition. From there I picked up the paper, Attention Residuals (Kimi Team, 2026), and decided to reimplement it from scratch. No HuggingFace, no pre-built transformer blocks. Just torch.einsum, nn.Parameter, and a toy dataset small enough that I could trace every matrix multiplication by hand.A bit more statsy! Regression should predict full distributions
With regression, we are a bit stuck with a point-based mindset. However, this could change with tabular foundation models. At least in theory: While these models produce the full predictive distribution (or at least a discretized approximation over a fixed support) it’s not the default and the output is a bit hidden.Finally, this made me chuckle - thank you Simon! A dictionary of bullshit for statistics, AI and data science
accuracy /ˈæk.jə.rə.si/ noun 1. The degree to which predictions match reality within a subset of the data selected to yield the highest possible accuracy. 2. Whichever of the true positive rate and the true negative rate is the most impressive.



Practical tips
How to drive analytics, ML and AI into production
Raft is so fetch: The Raft Consensus Algorithm explained through “Mean Girls”
Raft is a consensus algorithm used in distributed systems to ensure that data is replicated safely and consistently. That sentence alone can be confusing. Hopefully the analogy in this post can help people understand how it works. In honor of national Mean Girls day (“on October 3rd he asked me what day it was”), I present the Raft Consensus Algorithm as explained through the movie Mean Girls.Quantization from the ground up
Qwen-3-Coder-Next is an 80 billion parameter model 159.4GB in size. That's roughly how much RAM you would need to run it, and that's before thinking about long context windows. This is not considered a big model. Rumors have it that frontier models have over 1 trillion parameters, which would require at least 2TB of RAM. The last time I saw that much RAM in one machine was never. But what if I told you we can make LLMs 4x smaller and 2x faster, enough to run very capable models on your laptop, all while losing only 5-10% accuracy. That's the magic of quantization.Keeping it simple - The Git Commands I Run Before Reading Any Code

Columnar Storage is Normalization
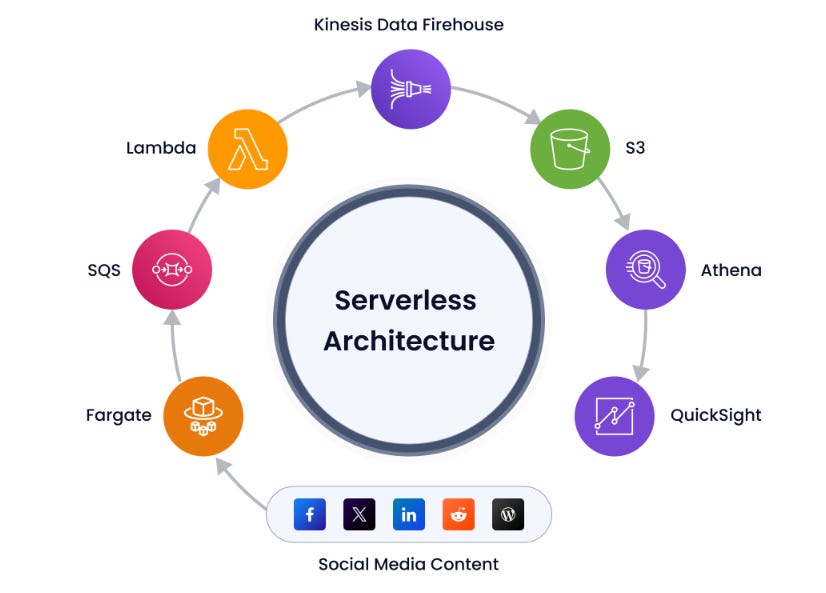
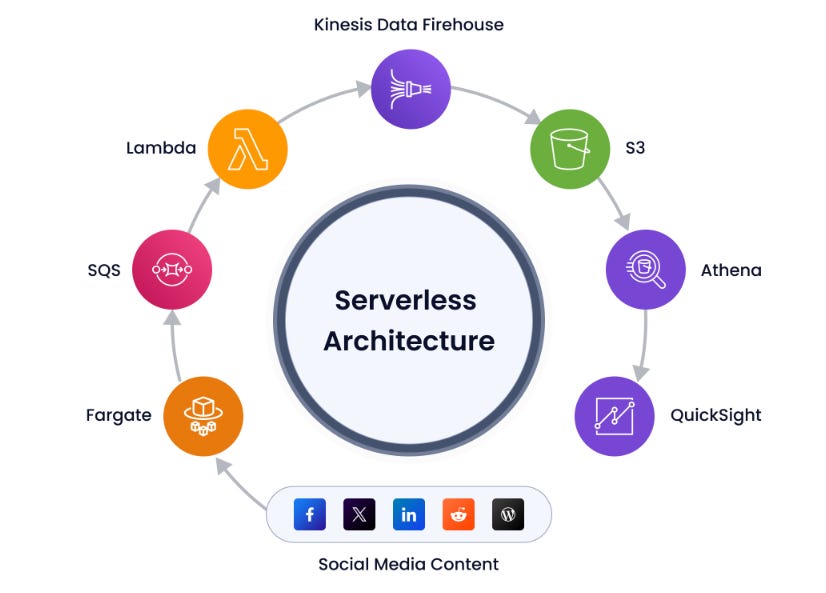
A different way to think about columnarization like this is that it's akin to very extreme type of database normalization. Instead of one wide table that's represented by a bunch of vectors of data, you might think of columnar data as a set of tables which all have a primary key plus one additional attributeUseful tutorial: How to Build a Scalable Serverless Social Media Ingestion & Analytics Pipeline on AWS
If you need to host a prototype or even something much larger, Vercel is defintiely worth checking out. Their offerings for AI applications are particularly useful: Agentic Infrastructure
As the final actor shifts from human to machine, infrastructure has to adapt again. It has to work for software that acts on behalf of users, writes itself, and increasingly needs to understand its own behavior in production. This new generation of agentic software demands Agentic Infrastructure. It’s not one evolution, but three: - Infrastructure for coding agents to deploy to - Infrastructure for building and running agents - Infrastructure that itself is agentic

Bigger picture ideas
Longer thought provoking reads - sit back and pour a drink! ...
Andrej Karpathy on the gap in understanding of AI capability
The first issue I think is around recency and tier of use. I think a lot of people tried the free tier of ChatGPT somewhere last year and allowed it to inform their views on AI a little too much. This is a group of reactions laughing at various quirks of the models, hallucinations, etc. Yes I also saw the viral videos of OpenAI's Advanced Voice mode fumbling simple queries like "should I drive or walk to the carwash". The thing is that these free and old/deprecated models don't reflect the capability in the latest round of state of the art agentic models of this year, especially OpenAI Codex and Claude Code.The ying and yang of Anthropic’s Claude Mythos!
The Mythos Threshold - Joe Reis
It was the most responsible, carefully staged rollout of a dangerous capability that the industry had ever seen. And it was terrifying. A general-purpose model — one nobody trained for cybersecurity — was autonomously discovering, chaining together, and exploiting vulnerabilities at a level exceeding most human security researchers. The obvious question hung over everything: what else can it do that we haven’t thought to test yet? The discourse lasted about a week. The market dipped. It recovered. This is how it works now.Claude Mythos #2: Cybersecurity and Project Glasswing - Zvi Mowshowitz
As you consider all of this, do not forget that Mythos is a large step towards automated AI R&D and sufficiently advanced AI, and also shows some shadows of what such a future AI will be capable of doing. We are headed into existential danger, in addition to the very real catastrophic cybersecurity threats we need to tackle now.Anthropic’s Claude Mythos Launch Is Built on Misinformation - Devansh
The problem is everything around it. Almost every major outlet or commentator covering Mythos worked from Anthropic’s press materials and not the actual primary sources such as the CVE advisories, the exploit code, the 44-prompt transcript, the 244-page system card. When you read them and add the AISLE replication study, the red team writeups, the Glasswing partner agreements, Anthropic’s own decpetive framings, and a very different picture emerges: one of misinformation and hype.
The Missing Layer: Why Your AI Agent Fails — and What Actually Fixes It - Ben Lorica
Software engineering teams were the first to hit this wall at scale, and their response offers a practical blueprint for every domain now building AI-powered applications. Their conclusion was counterintuitive: scaling AI reliably is not primarily about making the underlying model smarter. It requires a completely different discipline focused on building a structured, automated environment around the model. That discipline is called harness engineering, and its principles extend well beyond writing software.
The AI Labs Have A $7 Doritos Problem - Vin Vashishta
Doritos prices jumped nearly 50% between 2021 and early 2026. Some bags crossed $7, which is a lot for junk food. Walmart told PepsiCo to cut prices for over a year. PepsiCo tried everything except cutting prices, from promotions and shrinkflation to new product lines. None of it worked. Revenue turned negative for the first time in over a decade. Walmart pulled shelf space and handed it to Takis and its own private label. There are structural parallels to AI. OpenAI, Anthropic, Google, and Microsoft are all navigating the same question Frito-Lay failed to answer. Consumers and enterprises are evaluating AI subscriptions the same way shoppers evaluated a $7 bag of chips. Is this worth it? Is this something I need, or something I can skip?The AlphaFold moment for materials is not any time soon - Connor Blake
One central question was “what is the AlphaFold of materials science, and how can we get it in 6-24 months?” This is an ill-posed question because proteins have a bunch of nice properties that materials don’t have. Namely, amino acid sequences are basically sufficient to determine structure in physiological conditions of interest, but composition or even lattice unit cells are not sufficient to determine structure of Real Physical Materials. Despite what everyone wants to believe based on standard bulk modeling techniques, most materials are disordered and have complex interfaces, and if you can’t capture the implications of these, models will output garbage.The Revenge of the Data Scientist - Hamel Husain
For years, shipping AI meant keeping data scientists and MLEs on the critical path. With LLMs, this stopped being the default. Foundation-model APIs now allow teams to integrate AI independently. Getting cut out of the loop rattled data scientists and MLEs I know. If the company no longer needs you to ship AI, it is fair to wonder whether the job still has the same upside. The harsher story people tell themselves: unless you are pretraining at a foundation-model lab, you are not where the action is. I read it the other way. Training models was never most of the job. The bulk of the work is setting up experiments to test how well the AI generalizes to unseen data, debugging stochastic systems, and designing good metrics. Calling an LLM over an API does not make this work go away.We’re actually running out of benchmarks to upper bound AI capabilities - Lawrence Chan
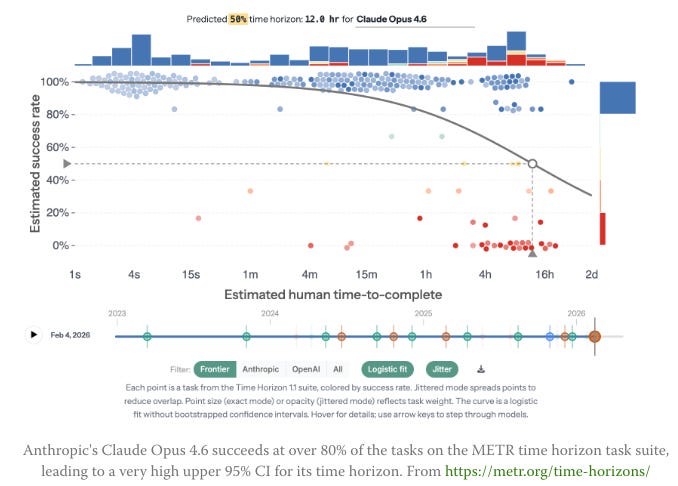
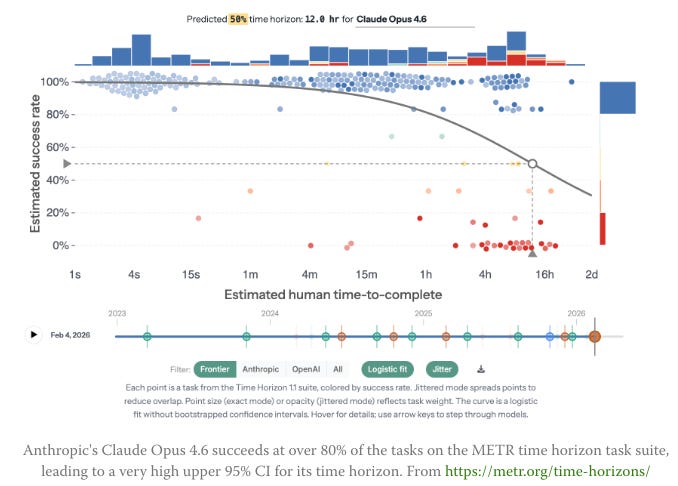
Sign of the future: GPT-5.5 - Ethan Mollick

Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
Is open claw your new best friend? You clearly need this:
Because why wouldn’t you want to do this? Estimating π with a Coin
And this as well- Your Name in Landsat


Updates from Members and Contributors
Hilary Till, Principal at Premia Research, draws our attention to an interesting upcoming AI/ML event at the LSE on 23rd June: AI/ML in Finance: Advancing the Future of Financial Markets
Federico Cilauro from Frontier Economics is running a research project for the UK Government and is looking for AI practitioner participants- looks like a great opportunity:
“A research study funded by the Chief Scientific Adviser’s R&D Programme is undertaking a survey of researchers and organisations in AI development and deployment, to help assess the extent to which they use creative and cultural content, and whether there are barriers preventing them from accessing the content they would need. You can respond to the survey using this link. Your response would be useful even if you do not currently use creative and cultural content.”
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you’d like to advertise
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS