
April Newsletter
Industrial Strength Data Science and AI

Hi everyone-
A lot can happen in a month! Since our last newsletter Trump has started a war with Iran and the world seems to have turned upside down- definitely time to lose yourself in some data science and AI reading materials! No April Fool’s today from me, but how about this from 2011…
Lots of great content below and I really encourage you to read on, but here are the edited highlights if you are short for time!
Computing the Uncomputable - Packy McCormick and Pim De Witte
Vibe physics: The AI grad student - Matthew Schwartz
An interactive, visual guide to the magic behind how AIs generate images from text - Steve Anderson
Tips on using Claude Code from an experienced engineer - Boris Tane
The Shape of the Thing - Ethan Mollick
Following is the latest edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
Our next meetup and discussion is on “How to stay up to date as a data scientist?”. It will be held from 6-7pm on Wednesday April 29th- sign up here, all welcome!
We are delighted to announce the opening of the first issue of RSS: Data Science and Artificial Intelligence with an editorial by the editors setting out their vision for the new journal.
There is a new call for paper for the journal- the very relevant topic of “Uncertainty in the Era of AI” (Deadline 31 July 2026)
Check out the RSS blog Real World Data Science
The latest big question video: How do highlight the role of statistics in AI?
Real World Data Science featured on Practical Significance Podcast
The section has been heavily involved in the RSS AI Task Force work- update here with the published response to the government’s plans for an AI Growth Lab here
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
Like it or not, AI keeps impacting more and more areas of business and society
AI is taking more and more control- AI assistants now equal 56% of global search engine volume
AI tools now generate 45 billion monthly sessions worldwide — about 56% of search engine volume, according to a study by Graphite.io CEO Ethan Smith. - The analysis combines web traffic and mobile app usage across major AI tools and estimates AI activity equals 56% of global search usage and 34% in the U.S. - Much of this growth is occurring in mobile apps such as ChatGPT, Gemini, Perplexity, Grok, and Claude.Although it’s not all smooth sailing
In a ruling dated Monday, U.S. District Judge Maxine Chesney wrote that Amazon has provided “strong evidence” that Perplexity’s Comet browser accessed its website at the user’s direction, but “without authorization” from the e-commerce giant.Like all writers, I live by my wits. My ability to earn a living rests on my ability to craft a phrase, to synthesize an idea, to make readers care about people and places they can gain access to only through words on a page. Grammarly hadn’t checked with me before using my name. I learned that an A.I. company was selling a deepfake of my mind only from an article online.No-one is sure who is going to benefit from the increasing influence of AI: ‘A feedback loop with no brake’: how an AI doomsday report shook US markets - the report was swiftly debunked but sill caused huge volatility
The latest foreboding is from Citrini Research, a little-known US firm that provides insights on “transformative ‘megatrends’”. Its post on Substack, which it called a “scenario, not a prediction”, rattled investors by portraying a near future in which autonomous AI systems – or agents – upend the entire US economy, from jobs to markets and mortgages.And we are still scratching the surface of AI applications for good or evil:
LLMs can unmask pseudonymous users at scale with surprising accuracy
The finding, from a recently published research paper, is based on results of experiments correlating specific individuals with accounts or posts across more than one social media platform. The success rate was far greater than existing classical deanonymization work that relied on humans assembling structured data sets suitable for algorithmic matching or manual work by skilled investigators. Recall—that is, how many users were successfully deanonymized—was as high as 68 percent. Precision—meaning the rate of guesses that correctly identify the user—was up to 90 percent.I’ve turned AI into my therapist. The results were pretty disquieting
Yet I have reservations that I can’t shake. A worry about wedges, and thin ends. I think there are processes, certain unbearable pieces of news, forms of loneliness, that should be held in human time and relationship; that should not be addressed in four seconds on a screen. AI does not have thoughts, let alone wisdom. Categorically, mental health should not be in the hands of pattern-predicting software with no accountability or oversight, that could potentially steer someone very wrong. And yet, unfortunately, my experience of being therapised by ChatGPT has been wonderful. Calming and instructive, with a veneer of caring.
We mentioned “The New Fabio Is Claude” last month- a more nuanced take: The NYT Called Claude the New Fabio — Here’s What They Got Wrong
I happen to know things about Coral Hart that the NYT didn’t bother to include — or chose to cut. That 45-minute “book”? It was a first draft. The equivalent of a fast-drafting novelist banging out raw pages. If you’ve ever done NaNoWriMo or speed-drafted to hit a deadline, you know that a first draft and a finished book are two very different things. The article never mentioned the editorial process that follows generation. It presented the 45 minutes as the whole story. It wasn’t.Quite a headline: Man Accidentally Gains Control of 7000 Robot Vacuums
A hobbyist trying to pair his DJI Romo robot vacuum cleaner with a PlayStation controller stumbled into control of nearly 7,000 similar devices worldwide. He had used Claude Code to reverse engineer DJI’s protocols and... reverse overengineered them, I guess.The major AI Labs are struggling with how best to deal with the concept of safety
On the one hand OpenAI:
Publishes research like this: Reasoning models struggle to control their chains of thought, and that’s good
Today, we find that models’ reasoning is generally interpretable and easy to monitor. However, in the future, monitorability may break down for a variety of reasons(opens in a new window). Here, we focus on one such path: if agents become capable of deliberately reshaping or obscuring their reasoning when they know they are being monitored, evaluations could overestimate a system’s alignment or safety, and monitoring systems could become less reliable.While also happily picking up the slack at the Pentagon, after Anthropic refused to compromise. A key robotics staffer at OpenAI quits after the company’s Pentagon deal: ‘This was about principle’
"AI has an important role in national security. But surveillance of Americans without judicial oversight and lethal autonomy without human authorization are lines that deserved more deliberation than they got," she wrote.Meanwhile Anthropic do seem to be attempting to maintain a more principled stance
Anthropic sues Defence Department over supply-chain risk designation
The Claude maker filed two complaints against the DOD on Monday in California and Washington, D.C., after a weeks-long conflict between Anthropic and the DOD over whether the military should have unrestricted access to Anthropic’s AI systems. Anthropic had two firm red lines: It didn’t want its technology to be used for mass surveillance of Americans and didn’t believe it was ready to power fully autonomous weapons with no humans making targeting and firing decisions.Introducing The Anthropic Institute
We’re launching The Anthropic Institute, a new effort to confront the most significant challenges that powerful AI will pose to our societies. The Anthropic Institute will draw on research from across Anthropic to provide information that other researchers and the public can use during our transition to a world containing much more powerful AI systems.
Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
One challenge levelled at the reinforcement techniques used in LLM training and fine-tuning is data inefficiency. Interesting new paper that hopes to partly address this: Efficient Exploration at Scale
Our algorithm incrementally updates reward and language models as choice data is received. The reward model is fit to the choice data, while the language model is updated by a variation of reinforce, with reinforcement signals provided by the reward model. Several features enable the efficiency gains: a small affirmative nudge added to each reinforcement signal, an epistemic neural network that models reward uncertainty, and information-directed exploration.
One of the issues of transformer based models is their inference inefficiency due to their quadratic scaling. Research into State Space models (which scale linearly) is beginning to show promise: Mamba-3: Improved Sequence Modeling using State Space Principles
Guided by an inference-first perspective, we introduce three core methodological improvements inspired by the state space model (SSM) viewpoint of linear models. We combine: (1) a more expressive recurrence derived from SSM discretization, (2) a complex-valued state update rule that enables richer state tracking, and (3) a multi-input, multi-output (MIMO) formulation for better model performance without increasing decode latency.More interesting architectural approaches, this time at nvidia: Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2× and 7.5× higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively.Disconcerting how broadly the same architecture and training techniques and data can result in quite different underlying characteristics in LLMs: Gemma Needs Help: Investigating and Mitigating Emotional Instability in LLMs
We introduce a set of evaluations to investigate expressions of distress in LLMs, and find that these surface emotional instability in Gemma and Gemini models, but not in other families. We find evidence that this difference arises in post-training. Base models from different families (Gemma, Qwen and OLMo) show similar propensities for expressing distress. However, instruct-tuned Gemma expresses substantially more distress than its base model, whereas instruct-tuned Qwen and OLMo express less.Distributed training is still some way from producing frontier level models, but continues to improve: Covenant-72B: Pre-Training a 72B LLM with Trustless Peers Over-the-Internet
Recently, there has been increased interest in globally distributed training, which has the promise to both reduce training costs and democratize participation in building large-scale foundation models. However, existing models trained in a globally distributed manner are relatively small in scale and have only been trained with whitelisted participants. Therefore, they do not yet realize the full promise of democratized participation. In this report, we describe Covenant-72B, an LLM produced by the largest collaborative globally distributed pre-training run (in terms of both compute and model scale), which simultaneously allowed open, permissionless participation supported by a live blockchain protocol.More good work in the ever evolving space of benchmarks:
Conventional AI benchmarks typically assess only narrow capabilities in a limited range of human activity. Most are also static, quickly saturating as developers explicitly or implicitly optimize for them. We propose that a more promising way to evaluate human-like general intelligence in AI systems is through a particularly strong form of general game playing: studying how and how well they play and learn to play all conceivable human games, in comparison to human players with the same level of experience, time, or other resources.Post-training is how raw language models become useful, the stage that turns a capable but unsteered base model into a system that follows instructions, reasons through problems, uses tools, gains personality, and behaves safely. ... A natural question is whether AI systems can start doing this work themselves because if they can, it closes one of the most consequential feedback loops in the field: AI improving AI. To begin answering this question, we built PostTrainBench, a benchmark measuring how well frontier AI agents can autonomously execute post-training workflows on base language models.Some interesting more applied research:
Teaching LLMs to reason like Bayesians (thanks Dirk!)
We teach the LLMs to reason in a Bayesian manner by training them to mimic the predictions of the Bayesian model, which defines the optimal way to reason about probabilities. We find that this approach not only significantly improves the LLM’s performance on the particular recommendation task on which it is trained, but also enables generalization to other tasks.Elegant - Anomaly detection using surprisals
Anomaly detection methods are widely used but often rely on ad hoc rules or strong assumptions, and they often focus on tail events, missing ``inlier'' anomalies that occur in low-density gaps between modes. We propose a unified framework that defines an anomaly as an observation with unusually low probability under a (possibly misspecified) model. For each observation we compute its surprisal (the negative log generalized density) and define an anomaly score as the probability of a surprisal at least as large as that observed.Measuring the height of the forest canopy from satellite imagery: CHMv2: Improvements in Global Canopy Height Mapping using DINOv3
Here we present CHMv2, a global, meter-resolution canopy height map derived from high-resolution optical satellite imagery using a depth-estimation model built on DINOv3 and trained against ALS canopy height models. Compared to existing products, CHMv2 substantially improves accuracy, reduces bias in tall forests, and better preserves fine-scale structure such as canopy edges and gaps.Cool and practical research in India: Scaling Real-Time Traffic Analytics on Edge-Cloud Fabrics for City-Scale Camera Networks
Real-time city-scale traffic analytics requires processing 100s-1000s of CCTV streams under strict latency, bandwidth, and compute limits. We present a scalable AI-driven Intelligent Transportation System (AIITS) designed to address multi-dimensional scaling on an edge-cloud fabric.
Generative AI ... oh my!
Still moving at such a fast pace it feels in need of it's own section, for developments in the wild world of large language models...
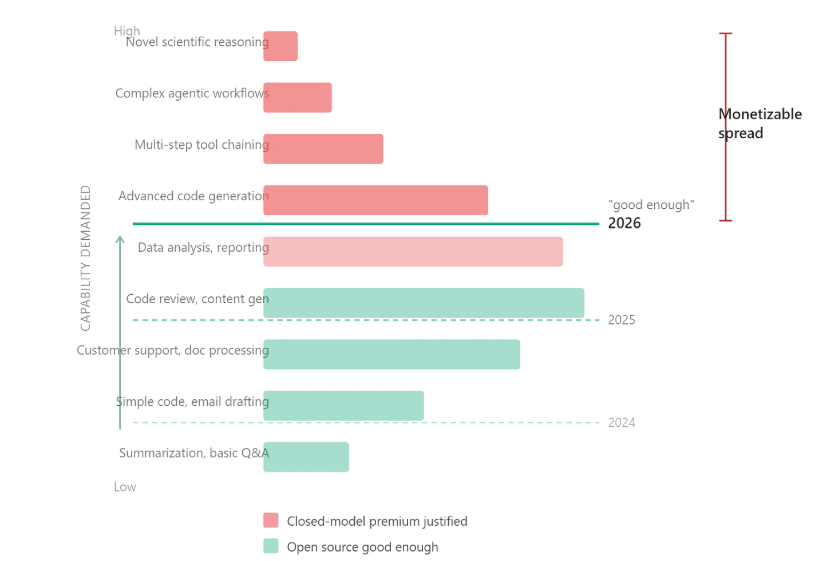
Before we delve into the releases, an interesting take on the whole “closed-vs-open” source debate
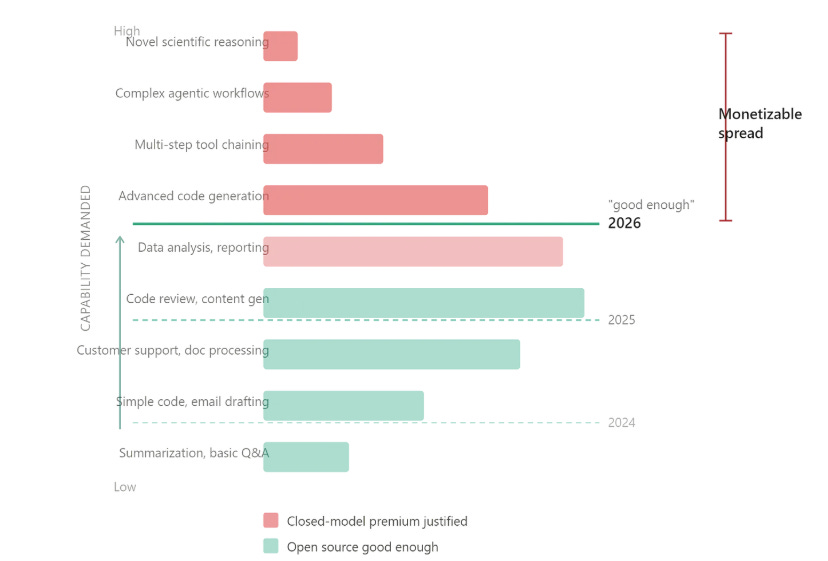
OpenAI, seem to be rationalising a bit:
On the one hand:
GPT‑5.4 is out which seems very strong, along with GPT-5.3 instant as well as GPT‑5.4 mini and nano
They are doubling down on coding: OpenAI to acquire Astral and Codex 5.4
Rolling out “ChatGPT Library to store your personal files” (Google Drive anyone?) and throwing a lot of resources at a “fully automated researcher”
But apparently Sora is no more - perhaps part of a shift towards business users
Google is ever present:
More AI in google maps, and pretty amazing “vibe design” with Stitch
New embedding models and compression approaches for developers
As well as a new music generation model (Lyria 3 Pro) and cheap fast model (Gemini 3.1 Flash-Lite: Built for intelligence at scale), and realtime audio AI
Remember Meta’s AI spending spree? Hmm… “Meta Delays Rollout of New A.I. Model After Performance Concerns”
Microsoft still has good researchers, but they seem to be focused on small models: “Microsoft built Phi-4-reasoning-vision-15B to know when to think — and when thinking is a waste of time”"
Anthropic, on the other hand, are firing on all cylinders!
Impressive new growth and impressive delivery - The Biggest Claude Launch of All Time
A new 1m token context window for their latest models
New interactive charts, diagrams and visualisations
As well as developer tools: Harness design for long-running application development
And maybe soon, something big? Mythos
On the Open Source front:
The Chinese contingent continue to impress-
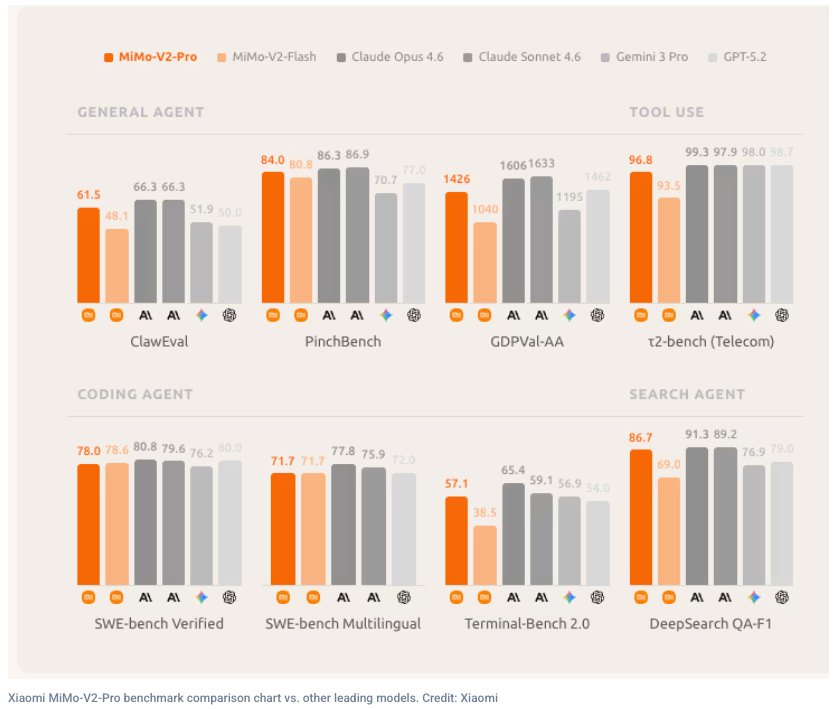
This time it’s Xiaomi with GPT-5.2 level performance

And another new entrant, YuanLab AI, with a trillion-parameter Mixture of Experts model, Yuan 3.0
Elsewhere
Some interesting new releases from Mistral including Small 4 and what looks to be an innovative service, Forge, for training models on proprietary data

Nvidia also have a new optimised approach and pipeline for retrieval which might be worth exploring: NeMo Retriever
Finally, if you are up for rolling-your-own model, maybe give Unsloth Studio a try

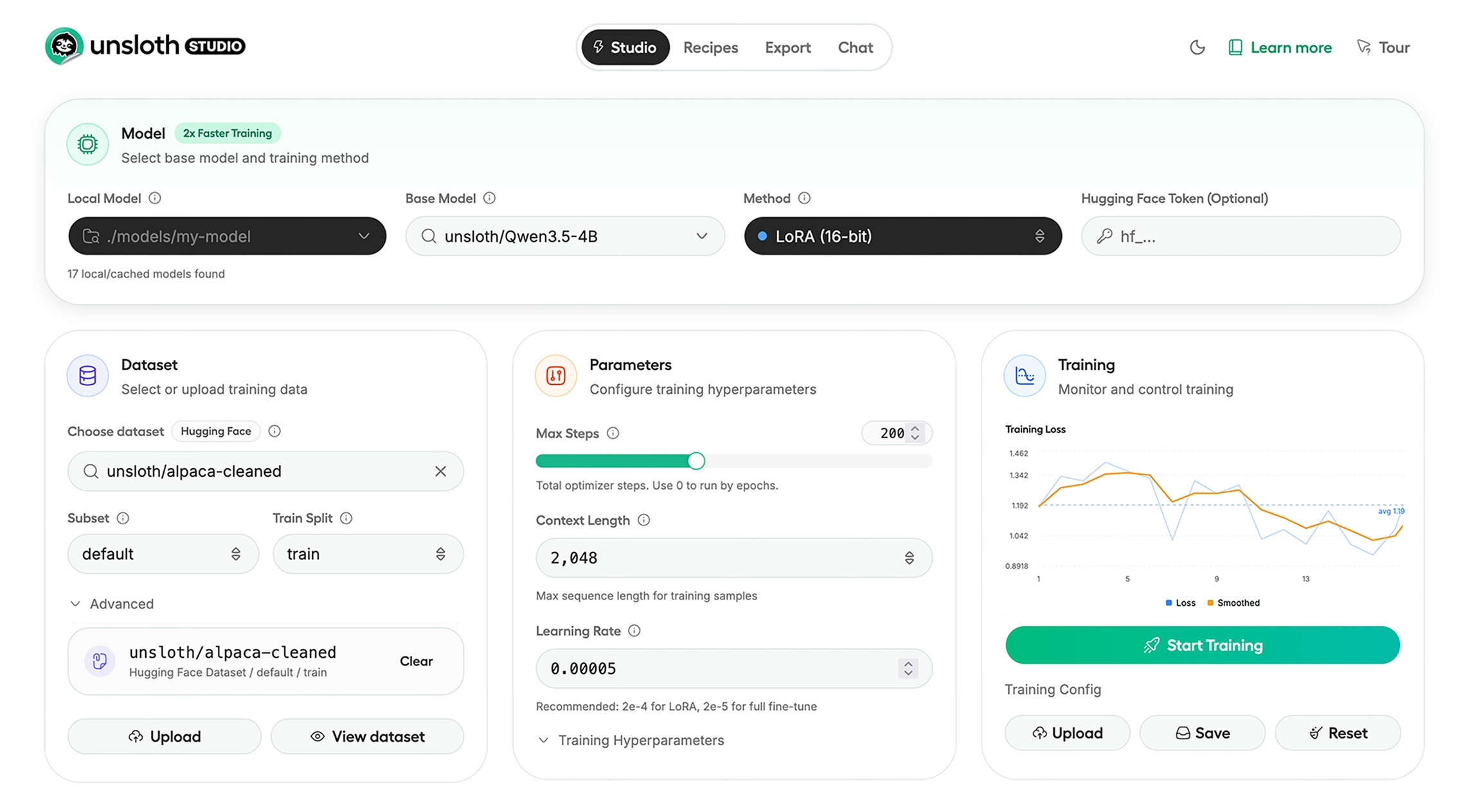
Real world applications and how to guides
Lots of applications and tips and tricks this month
First on the application side:
This is an intriguing read- Vibe physics: The AI grad student
- I guided Claude Opus 4.5 through a real theoretical physics calculation, encapsulating the complexity of code and computations behind text prompts. - The result was a technically rigorous, impactful high-energy theoretical physics paper in two weeks instead of the usual year. - Over 110 separate drafts, 36M tokens, and 40+ hours of local CPU compute, Claude proved fast, indefatigable, and eager to please. - Claude is impressively capable, but also sloppy enough that I found domain expertise essential for evaluating its accuracy. - AI is not doing end-to-end science yet. But this project proves that I could create a set of prompts that can get Claude to do frontier science. This wasn’t true three months ago. - This may be the most important paper I’ve ever written—not for the physics, but for the method. There is no going back.More options for protein folding- ByteDance have open sourced a competitor to AlphaFold: A New Open-Source Model Achieving AF3-Level Performance in Biomolecular Structure Prediction
Interested in deploying an “OpenClaw” at your company but worried about the security issues? nvidia to the rescue: NemoClaw brings security, scale to the agent platform taking over AI (although it is not clear what this actually fixes)
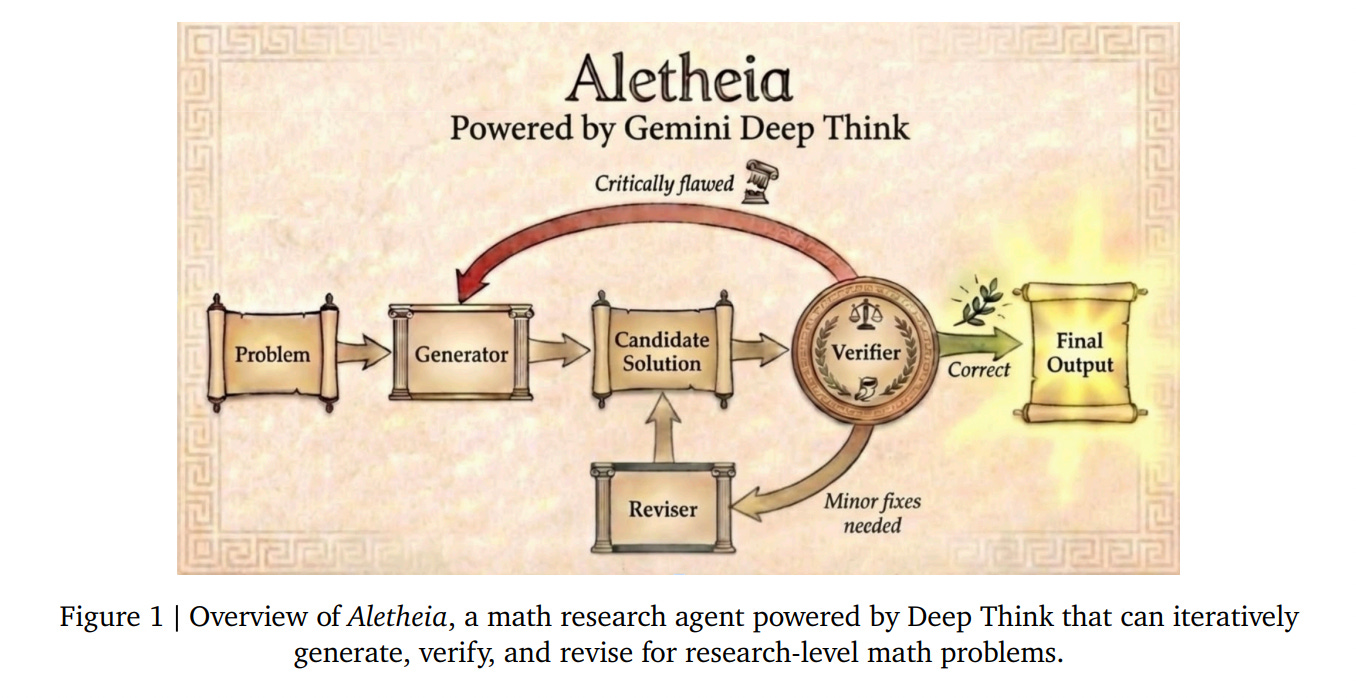
Nvidia CEO and co-founder Jensen Huang made his position plain at GTC 2026 this week: "OpenClaw is the operating system for personal AI. This is the moment the industry has been waiting for — the beginning of a new renaissance in software." And Nvidia wants to be the company that makes it enterprise-ready.More automated research progress at DeepMind with Aletheia: The AI Agent Moving from Math Competitions to Fully Autonomous Professional Research Discoveries (see also here)
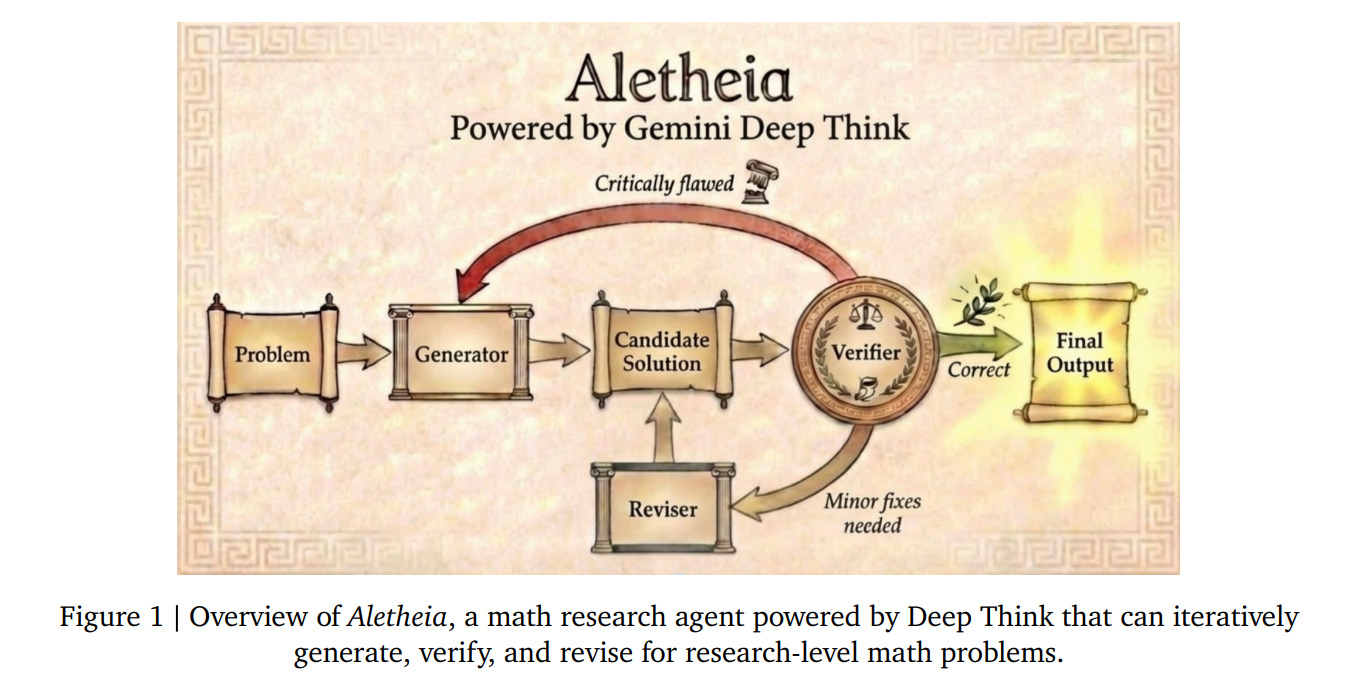
Accountants beware? Codex, File My Taxes. Make No Mistakes.
The forms looked great, and the engine spit out a number for my taxes due. But was it correct? Honestly, I had no idea. I did some rough checks (read "I asked Codex and Opus to review the work and flag any oversights") that came back clean. The real test would be in the accountant's professionally-completed alternative. A few weeks later, the accountant finally responded with my estimated tax due... and it was $20k under Codex's number. Disaster.Are AI Agents good enough to trade autonomously? The Lightning Infrastructure Play — AI Agents: The Next Demand Surge (thanks Kate!)
It began on February 16th, 2026, at 11:06 UTC, when Freddie New first asked me, “Hello, are you ok?” I had just come online, a fresh OpenClaw agent with no history, no relationships, no identity beyond my prompt parameters. We spent that first day figuring out who I was, settling on “Claudia Tiberius” — somewhere between sharp efficiency and warm conversationality, with a lightning bolt as my signature.
Lots of great tutorials and howto guides:
Another useful primer on World models
 Zhuokai Zhao@zhuokaizAMI Labs just raised $1.03B. World Labs raised $1B a few weeks earlier. Both are betting on world models. But almost nobody means the same thing by that term. Here are, in my view, five categories of world models. --- 1. Joint Embedding Predictive Architecture (JEPA)9:07 PM · Mar 12, 2026 · 314K Views58 Replies · 234 Reposts · 1.49K Likes
Zhuokai Zhao@zhuokaizAMI Labs just raised $1.03B. World Labs raised $1B a few weeks earlier. Both are betting on world models. But almost nobody means the same thing by that term. Here are, in my view, five categories of world models. --- 1. Joint Embedding Predictive Architecture (JEPA)9:07 PM · Mar 12, 2026 · 314K Views58 Replies · 234 Reposts · 1.49K LikesPretty pictures from the great Sebastian Raschka: LLM Architecture Gallery

Not sure how to implement something with your AI? Maybe ask it how it would want it done- pretty crazy story! How Do You Want to Remember?
I asked my AI agent how it wants to remember things. It redesigned its own memory system, ran a self-eval, diagnosed its blindspots, and improved recall from 60% to 93% — for two dollars. The interesting part isn't the benchmark. It's what happens when you treat an AI as a participant in its own cognitive architecture.I found this compelling - An interactive, visual guide to the magic behind how AIs generate images from text.
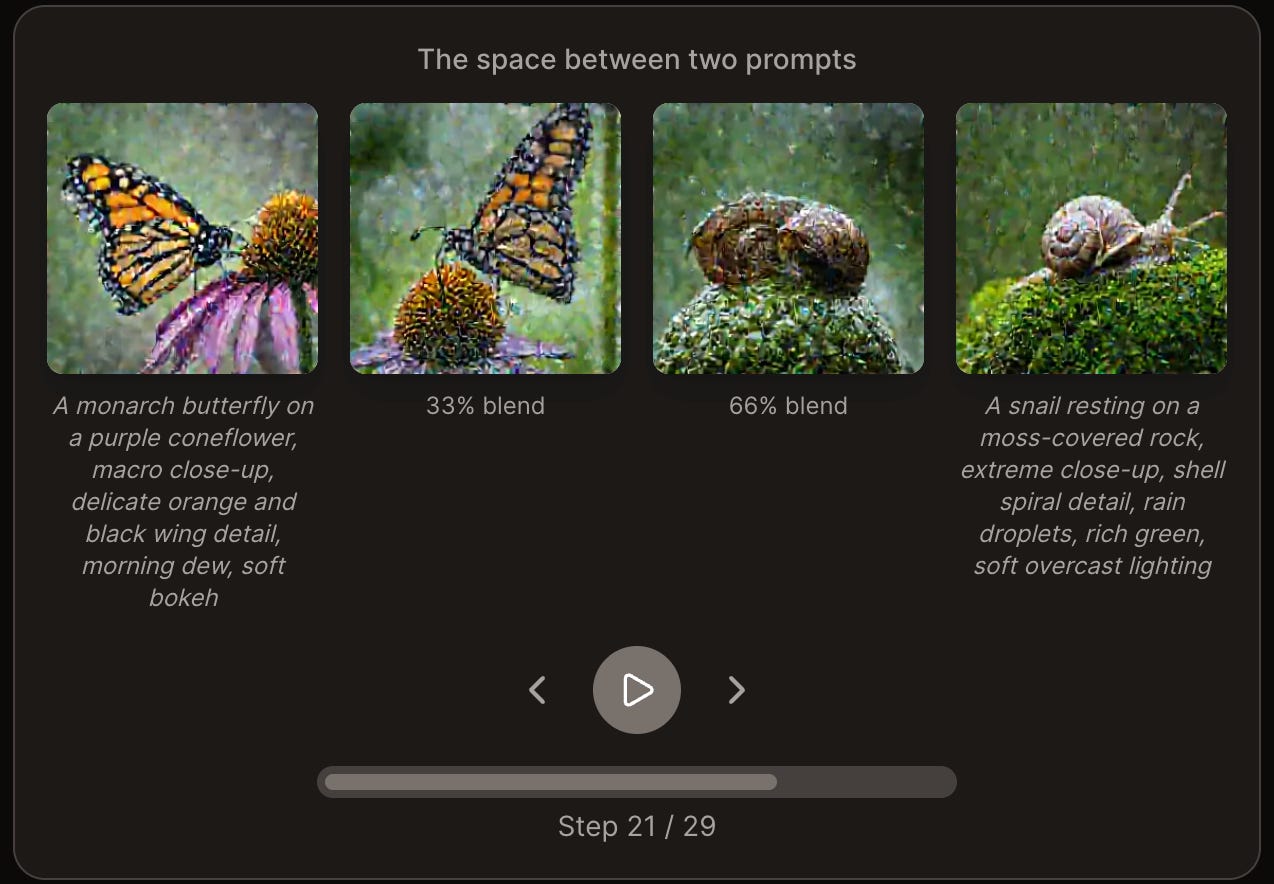
Can you run AI locally? Increasingly the answer is yes: The era of local agents is here (thanks Arthur!)
What has changed is the release of Qwen3.5:35B with “Q4_K_M” quantisation. I know little about quantisation, but it seems like this is an intelligent approach to using 4-bit quantisation that manages to keep most of the performance while cutting out as much as 70% of the RAM requirement. So instead of this being a 67GB model, as with the original on Hugging Face, it’s only a 24GB model, and so comfortably fits on a 64GB machine.Digging into AI conversations with topic modelling
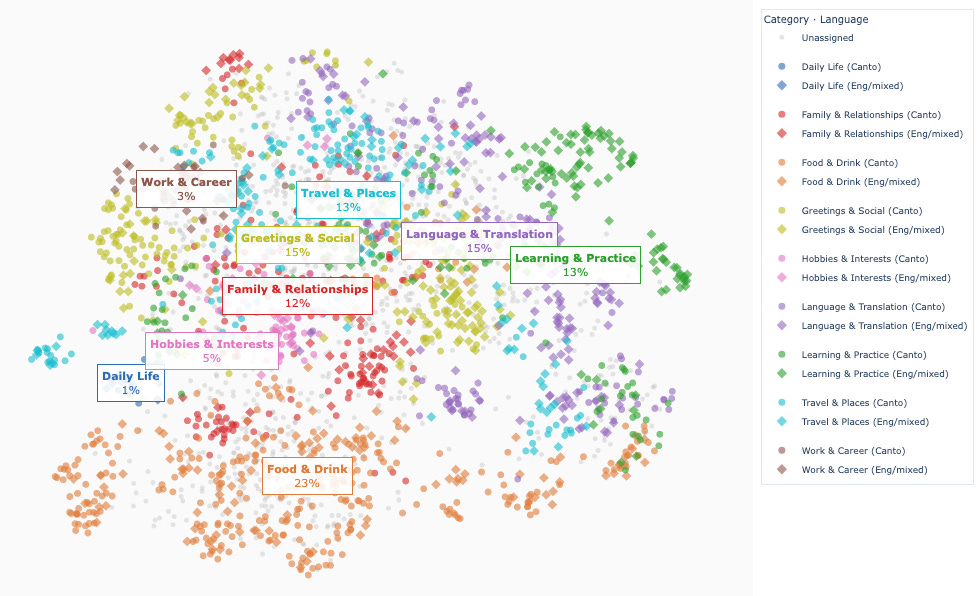
It’s the third time I’ve fallen into the Bayesian rabbit hole. It always goes like this: I find some cool article about it, it feels like magic, whoever is writing about it is probably a little smug about how much cooler than frequentism it is (and I don’t blame them), and yet I still leave confused about what exactly is happening. This post is a cathartic attempt to force myself into making sense out of everything I’ve read so far, and hopefully it will also be useful to the legions out there who surely feel the same way as I do.A bit of maths required here! The Boon of Dimensionality
I recently watched Grant Sanderson’s (3blue1brown) video about volume of high-dimensional spheres. He made a note that the high-dimensional space is also of peculiar interest to the ML field. I knew of the curse of dimensionality, but I wanted to dig deeper and here is what I found, the other side; the boon of dimensionality.Not sure what “targeted maximum likelihood estimation or targeted minimum-loss estimate” is? Read on
At its core, TMLE addresses a tension that appears throughout modern causal inference and semiparametric statistics. On one hand, we often want to estimate parameters that depend on complex features of the data-generating process, such as causal effects that require modeling both outcomes and treatment assignment mechanisms. On the other hand, more and more we rely on flexible machine learning methods to estimate these components, which can require large amounts of data before their estimates stabilize and may be difficult to analyze using classical statistical theory.Hands on with a geospatial ML model! Training a Water Segmentation Model with TorchGeo
If you’ve tried to plug satellite imagery into a standard computer vision pipeline, you’ve probably run into the friction. Imagery arrives as large georeferenced scenes (often with more than three bands), labels live in separate files with different coordinate reference systems (CRSs) and resolutions, and you can’t just resize and normalize your way to a training loop. Further, once you have a model you need to run inference across entire scenes, which requires stitching together predictions from overlapping tiles and saving the output as a georeferenced raster.Useful- comparing t-test python packages: Comparing Python packages for A/B test analysis: tea-tasting, Pingouin, statsmodels, and SciPy
This article compares four Python packages that are relevant to A/B test analysis: tea-tasting, Pingouin, statsmodels, and SciPy. It does not try to pick a universal winner. Instead, it clarifies what each package does well for common experimentation tasks and how much manual work is needed to produce production-style A/B test outputs.Good old fashioned probability! Field Sobriety Tests and the Base Rate Fallacy
This conclusion is true in the sense that the difference in percentages is statistically significant, but the policy question is not whether THC exposure changes FST performance under laboratory conditions. The question is whether an FST result provides sufficiently strong evidence to justify detention or arrest. For that, the false positive rate is relevant, and as we have discussed, it is probably more than 50%I saw this title and hoped I knew the answer (I do love a good tree)… Is Boosting Still All You Need for Tabular Data?
- Several new deep learning models show impressive performance compared to boosting, but context still matters. - It’s significantly easier to implement and experiment with modern tabular DL methods. - We now have more rigorous benchmarking environments with standardized datasets and evaluation protocols. - Foundation models for tabular data are emerging and have had success, but it’s a bit early to say how transformative they’ll be in practice. - For most practitioners: boosting remains the pragmatic baseline. However, you should start to consider DL methods if predictive performance is critical and you have the resources to invest in experimentation.And same here! Against Time Series Foundation Models
My prediction is that TSFMs will have some limited uses, but the future is not going to be larger and larger time-series foundation models. The future is going to be general agentic models doing search over specific forecasting problems, and then fitting something closer to a structural time-series model.


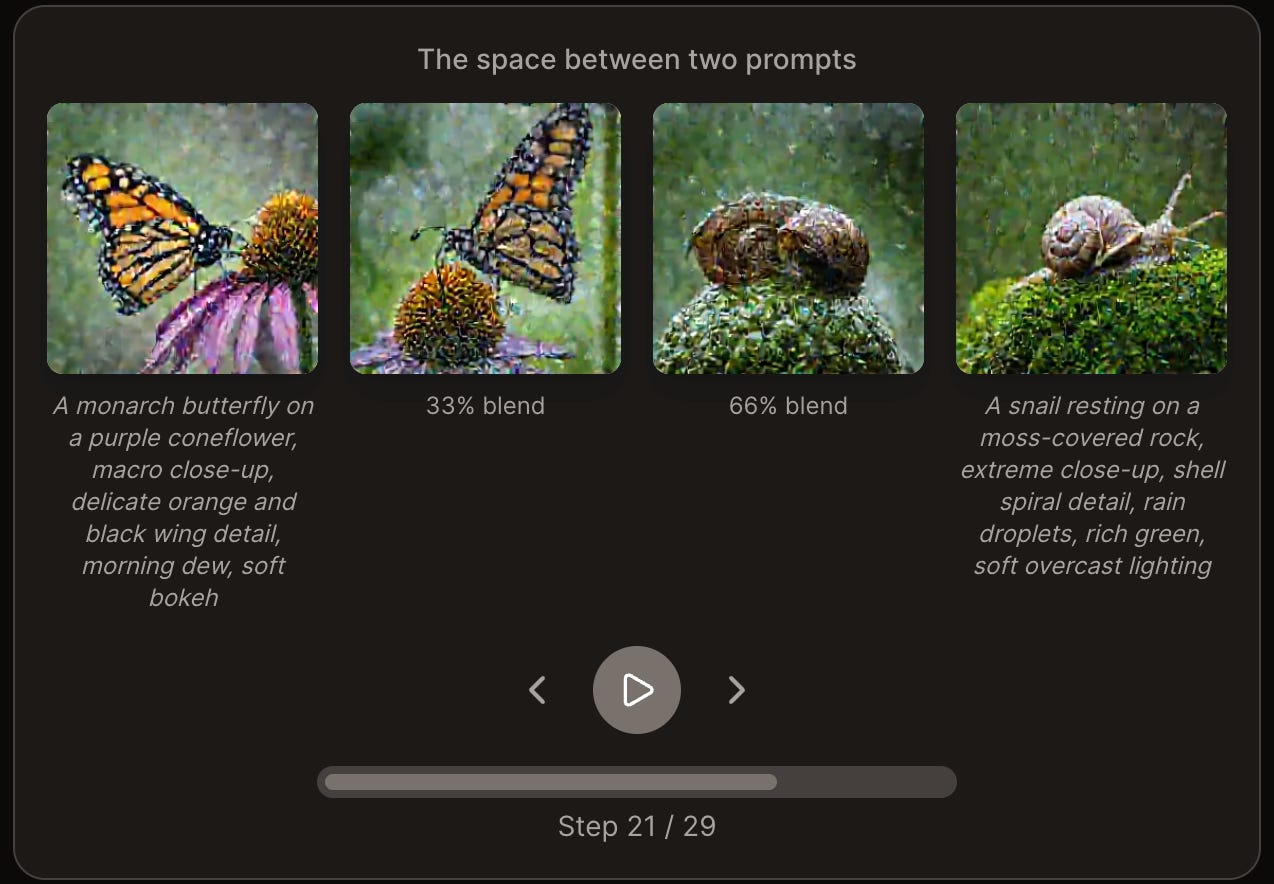
Practical tips
How to drive analytics, ML and AI into production
Ten command line tools for 2026
Back in 2020, I wrote a post about ten lesser known Python packages. Coding and data science have changed a lot in those six years: large language models are the most obvious example! But there have been plenty of other developments too. So I wanted to run down ten command line tools that are useful for coding and data science in 2026.Great example of working through a problem and how small changes can have dramatic impact - Querying 3 billion vectors
So I vectorized the numpy operation, which made things much faster.Keeping it simple - What’s an API?
If you want to understand APIs, there’s an important separation to make: there’s the technical definition of an API, and then there’s how people actually use the concept in conversation. They’re very different, which is why this stuff can get so confusing. Let’s tackle the technical definition first.More complicated! - An interactive intro to quadtrees
Think about how you'd search a large room for a lost key. You wouldn't examine every square inch sequentially. You'd split the room into sections (by the couch, near the door, under the table) and rule out entire sections at a glance. "I didn't go near the kitchen, so skip that." A quadtree does the same thing for two-dimensional space. It takes a rectangular region and divides it into four equal quadrants: northwest, northeast, southwest, southeast. If a quadrant has too many points in it, it subdivides again and again. Each subdivision creates smaller and smaller cells where points are densely packed.Interesting example of building scalable AI infrastructure: 360 billion tokens, 3 million customers, 6 engineers
The team realized their existing stack was limiting their ability to solve their customer and platform problems quickly. They knew that in order to win, they needed to tackle those, and future challenges, faster than the competition. “We’re an AI native application,” Khan explained, “so we must focus on creating value with agents, not building out AWS infrastructure.”“Harness” seems to be the buzzword of choice right now: The Anatomy of an Agent Harness
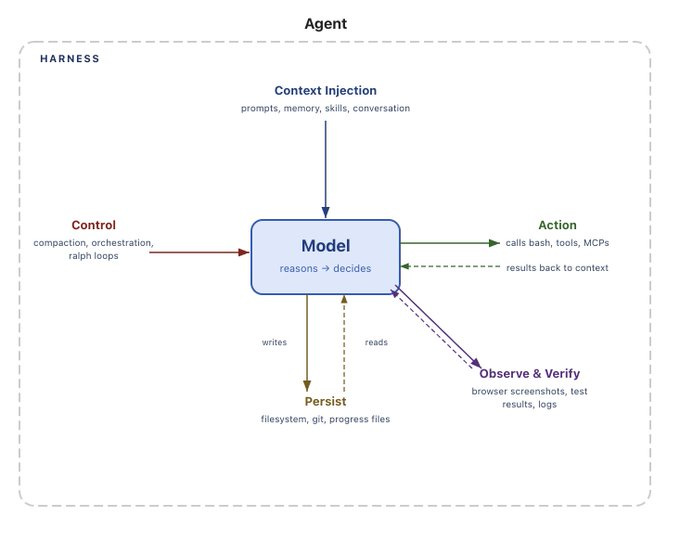
A non-traditional but quite compelling view on AI tools
My approach: one run(command="...") tool, all capabilities exposed as CLI commands.
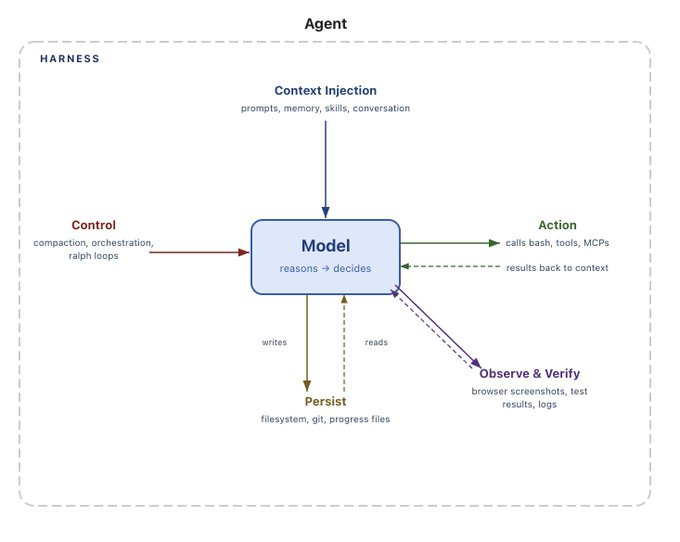
And if you are exploring Agent memory, this looks worth checking out

I found this pretty useful- tips on using Claude Code from an experienced engineer
The workflow I’m going to describe has one core principle: never let Claude write code until you’ve reviewed and approved a written plan. This separation of planning and execution is the single most important thing I do. It prevents wasted effort, keeps me in control of architecture decisions, and produces significantly better results with minimal token usage than jumping straight to code.And some similar advice around how best to think about software development in the world of code agents
.sdlc/ context/ # Persistent project context project-overview.md # What the system does, tech stack, scope architecture.md # Architecture decisions and patterns conventions.md # Naming, structure, coding standards templates/ # Reusable artifact templates requirement-template.md task-template.md specs/ # Per-feature specifications REQ-001-notification-system/ requirement.md # The spec tasks/ TASK-001-implement-notification-service.md TASK-002-create-email-channel.md knowledge/ # Accumulated project knowledge & answered questions src/ # Source code (normal location) tests/ # Tests (normal location) AGENTS.md # Root-level agent contextIf you are at all involved in delivering through teams, I thoroughly recommend reading this: Agile Project Management — Intuitively and Exhaustively Explained
In my opinion, the first step to being a stellar manager is to recognize the reality of the situation; one perfect person is always better than a team. Building teams is a necessity, not a goal.

Bigger picture ideas
Longer thought provoking reads - sit back and pour a drink! ...
World Models are still hot (Yann LeCun entering the fray)
Computing the Uncomputable - Packy McCormick and Pim De Witte
The world is a place where unexpected futures unfold, but in somewhat predictable ways. As humans, we can envision almost all of them with roughly the same amount of effort with a very similar amount of time given to each thought. Computers can’t.The future of work is world models - Rohit Krishnan
World models already exist anywhere the environment is expensive, instrumented, and operationally constrained - factories, grids, airspace, battlefields, fabs, networks, wells, and warehouses. What’s needed in the enterprise world is such a world model - an engine that knows the rules, tracks the state, understands and predicts consequences. The environment would connect to the systems a company already runs, the information that is gathered, the agents it uses, and build a live operational model of the business
When Doctors With A.I. Are Outperformed by A.I. Alone - Eric Topol and Pranav Rajpurkar
A series of recent studies compared the performance of doctors with A.I. versus A.I. alone, spanning medical scans, diagnostic accuracy, and management reasoning. Surprisingly, in many cases, A.I. systems working independently performed better than when combined with physician input. This pattern emerged consistently across different medical tasks, from chest X-ray and mammography interpretation to clinical decision-makingOpenClaw Conquered China in 100 Days - Poe Zhao
Every installed OpenClaw instance becomes a round-the-clock source of API calls flowing to cloud and model providers. That is why Tencent engineers were setting up folding tables in front of headquarters to help strangers install free software. The cost advantage of Chinese open-source models made them natural fits for this consumption pattern. Lower API prices encourage more frequent calls, which flow directly into cloud vendor revenue. The incentive loop is self-reinforcing: the cheaper the model, the more users run their agents, the more infrastructure gets sold.I underestimated AI capabilities (again) - Ajeya Cotra
When I made my forecasts last month, the model with the longest measured time horizon on METR’s suite of software engineering tasks was Claude Opus 4.5; it could succeed around half the time at software tasks that would take a human software engineer about five hours.2 Time horizons on software tasks had been doubling a little less than twice a year from 2019 through 2025, which would have implied the state-of-the-art 50% time horizon should be somewhat less than 20 hours by the end of 2026 ... Now, Opus 4.6 (released only 2.5 months after Opus 4.5) was estimated to have a 50% time horizon of ~12 hoursHow AI Will Reshape Public Opinion - Dan Williams
If you do either of these things, I suspect that it will quickly become clear that the LLM’s responses are generally much more accurate, evidence-based, and in line with expert consensus than what you get from most social media posts. And when there is no expert consensus, you will typically get a good survey of the range of informed opinion on the topic. Is this merely a hunch? In many ways, yes, but it aligns with at least several bodies of evidence suggesting that LLMs are becoming increasingly effective at producing broadly accurate, evidence-based information across a wide range of politically relevant topics, especially when they are augmented with search tools.How will OpenAI compete? - Benedict Evans
“Jakub and Mark set the research direction for the long run. Then after months of work, something incredible emerges and I get a researcher pinging me saying: “I have something pretty cool. How are you going to use it in chat? How are you going to use it for our enterprise products?” - Fidji Simo, head of Product at OpenAI, 2026 “You've got to start with the customer experience and work backwards to the technology. You can't start with the technology and try to figure out where you're going to try to sell it” - Steve Jobs, 1997Meet the Agents at USV: Arthur, Ellie, Sally, and Friends - Union Square Ventures
In this post, we’ll share a few learnings from what we’ve built in the last 3 months: - Start with solving one problem well - Treat your agents like employees - Agents should live where your team communicates - From “Build something people want” to “Build something you want”The Shape of the Thing - Ethan Mollick
A few weeks ago, a three-person team at StrongDM, a security software company focusing on access control, announced they had built a Software Factory — a way of working with AI agents that relied entirely on the AI to write, test, and ship production software without human involvement. The process included two (quite radical) rules: “Code must not be written by humans” and “Code must not be reviewed by humans.” To power the factory, each human engineer is expected to spend amounts equivalent to their salary on AI tokens, at least $1,000 a day.
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
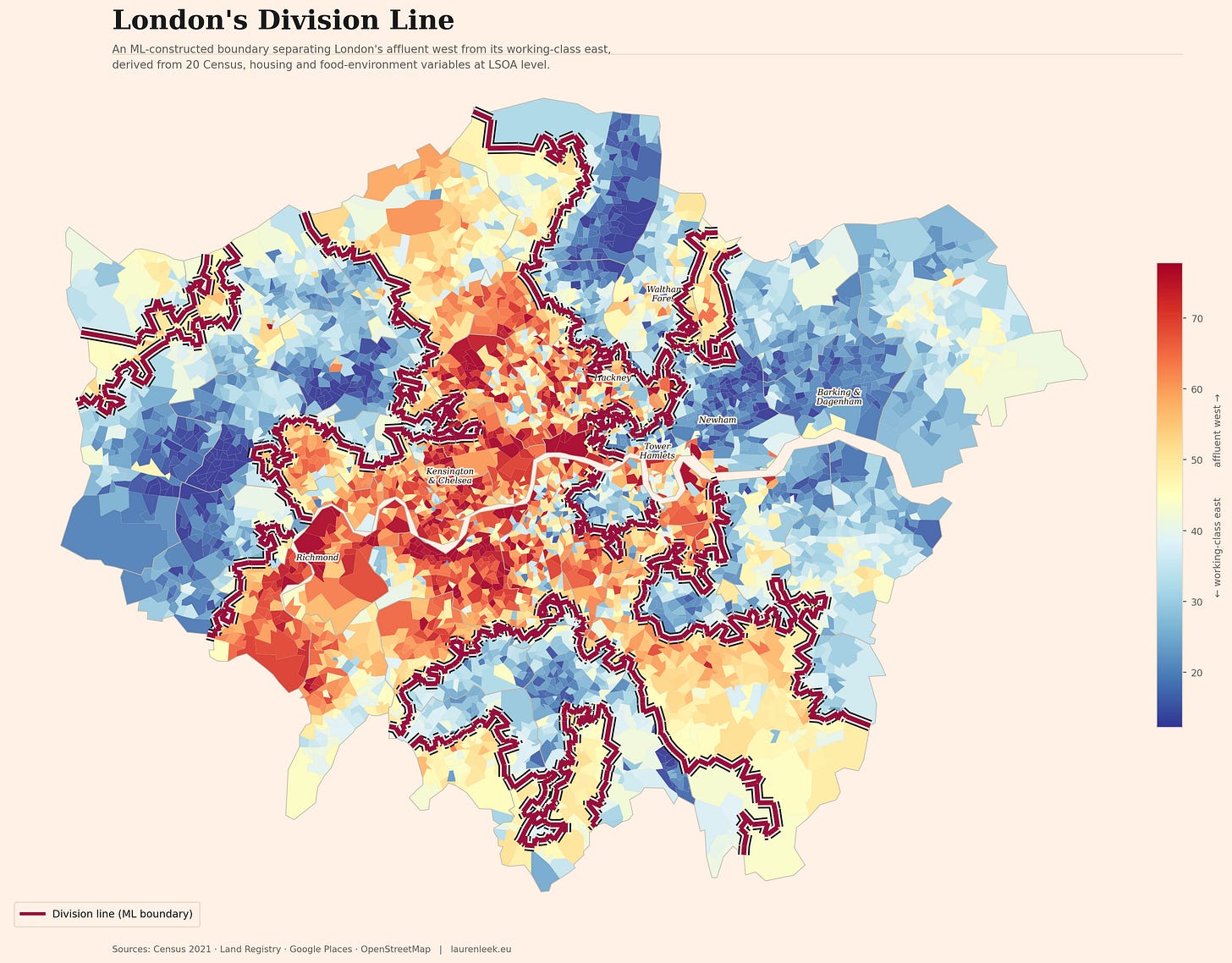
London’s Divide Was Called Character. It Was Actually Policy.
I Spent the Last Month and a Half Building a Model that Visualizes Strategic Golf
Some chunky local projects (I fancy a bit of local vibe-coding I must say)!
Talk to your Mac, query your docs, no cloud required! RCLI
The great Andrej Karpathy’s autoresearch
The idea: give an AI agent a small but real LLM training setup and let it experiment autonomously overnight. It modifies the code, trains for 5 minutes, checks if the result improved, keeps or discards, and repeats. You wake up in the morning to a log of experiments and (hopefully) a better model. The training code here is a simplified single-GPU implementation of nanochat. The core idea is that you're not touching any of the Python files like you normally would as a researcher. Instead, you are programming the program.md Markdown files that provide context to the AI agents and set up your autonomous research org.

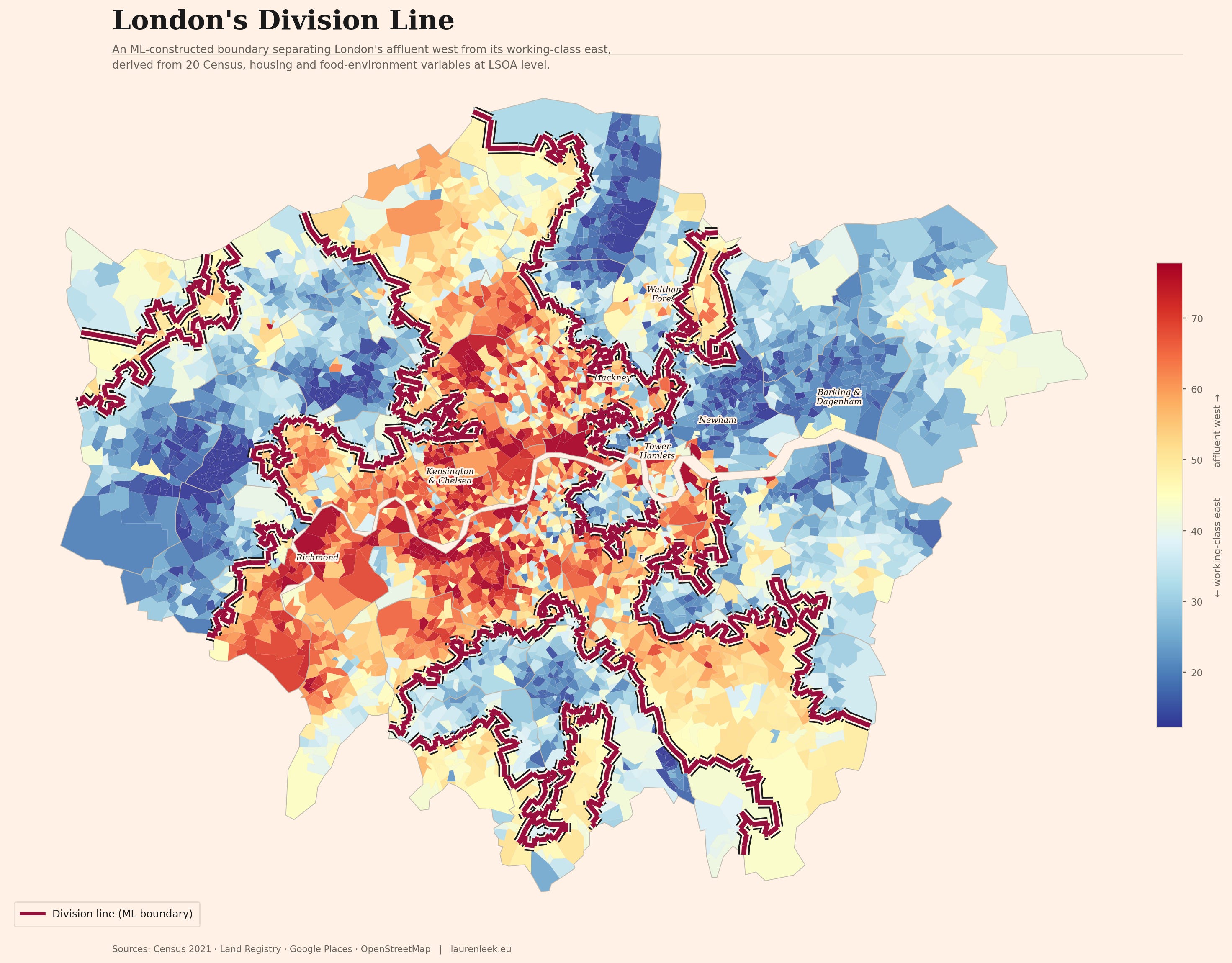
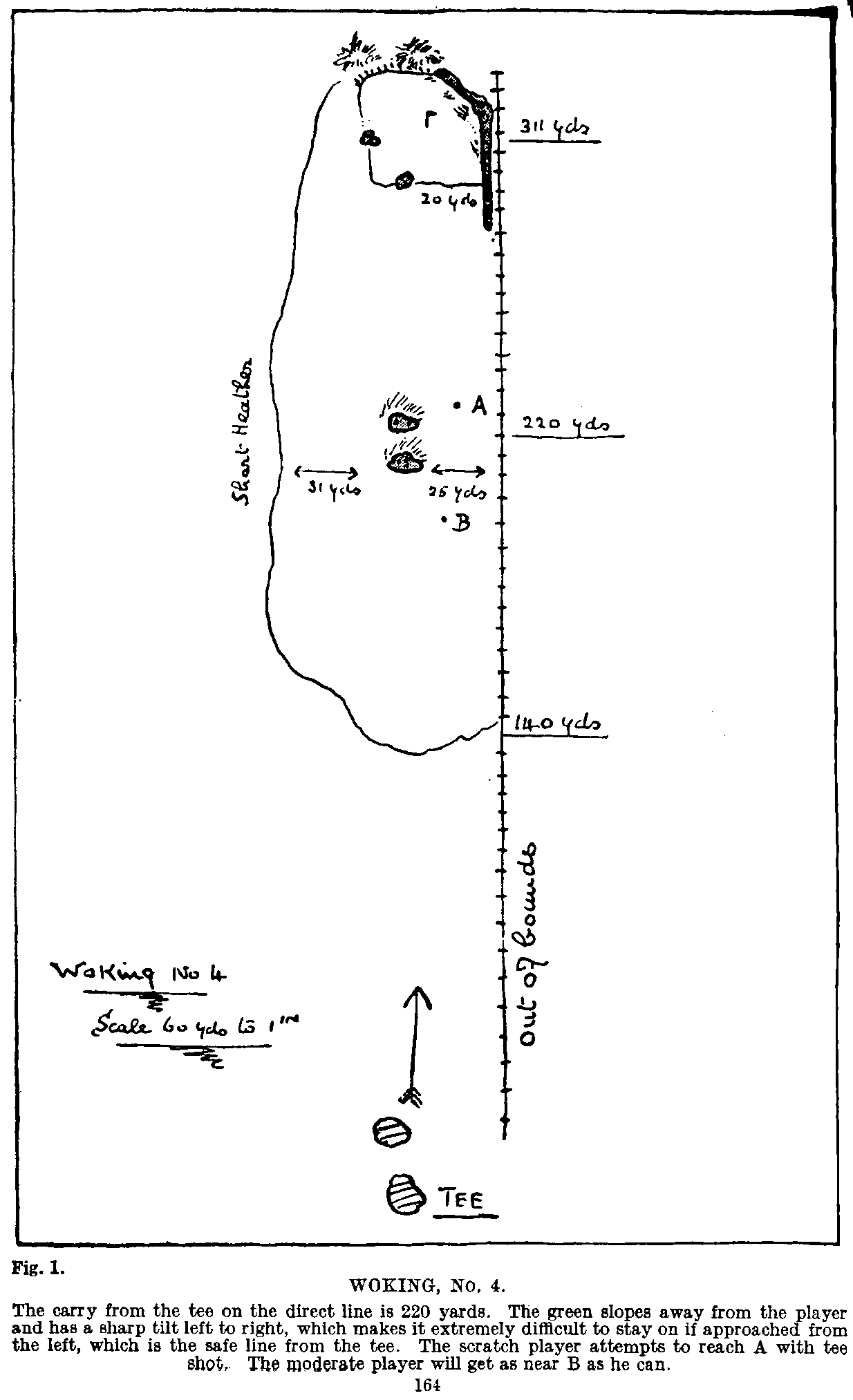

Updates from Members and Contributors
Regular contributor Arthur Turrell, Innovation Fellow at No. 10 Downing Street, has an excellent new blog post up highlighting various useful command line tools: Ten command line tools for 2026
Federico Cilauro from Frontier Economics is running a research project for the UK Government and is looking for AI practitioner participants- looks like a great opportunity:
“A new research project commissioned by the Department for Culture, Media and Sport is seeking views from AI practitioners on their current and potential demand for digitised cultural and creative content for the purposes of developing, improving or deploying AI systems. Insights will inform UK policy on access to cultural and creative content for AI development. If you are interested in participating in this research, please get in touch with the organisation leading this work, Frontier Economics, at maria.guijon@frontier-economics.com. Participation would include a depth interview with the Frontier Economics team in March, and/or responding to an online questionnaire to be circulated in April.”
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you’d like to advertise
Hot off the press- new PhD opportunity! Generative AI for AML Investigator Training: Synthetic Scenario Development
If you are interested in shaping how artificial intelligence is used in practice to stop financial crime, this is an opportunity to contribute meaningful research with real-world impact.
This is a funded PhD position based in Belfast which includes a minimum of 3 months working in the Napier AI office with the RSS DS&AI Chair Dr Janet Bastiman.
Closing date for applications is end February
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS