
January Newsletter
Industrial Strength Data Science and AI
Hi everyone-
Happy new year! Hope you all had a fantastic holiday period and indulged to the best/worst of your abilities. 2026 is here - time to prepare for the year ahead with some good reading materials on all things Data Science and AI… Lots of great content below and I really encourage you to read on, but here are the edited highlights if you are short for time!
2025 LLM Year in Review - Andrej Karpathy
The Shape of AI: Jaggedness, Bottlenecks and Salients - Ethan Mollick
Nature is Laughing at the AI Build Out - Mark Maunder
Investigating a Possible Scammer in Journalism’s AI Era - Nicholas Hune-Brown
Horses - Andy Jones
Before going further I thought I’d take Google’s NotebookLM for a spin and loaded up all the previous newsletters for 2025, asking for a summary and key themes. It was impressive, including this:
"Analogy for Understanding 2025 AI: If the AI of previous years was like a knowledgeable librarian who could tell you where to find information, the AI of 2025 is like a senior researcher with a credit card. It doesn't just tell you what the books say; it goes into the lab, runs the experiments, pays for the supplies, and writes the final report while you simply oversee the process."Following is the latest edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
The section hosted a Round Table discussion at the Turing Institute on December 17th: “The professionalisation of data science - are we ever getting out of the Wild West and would additional regulation help?”. This proved to be a lively debate covering a wide range of topics. Many thanks to Will Browne, co-founder Emrys Health, for organising
We are delighted to announce the opening of the first issue of RSS: Data Science and Artificial Intelligence with an editorial by the editors setting out their vision for the new journal.
A position paper on uncertainty in the era of AI has now been published into the issue of RSS: Data Science and Artificial Intelligence Issues | RSS: Data Science and Artificial Intelligence | Oxford Academic.
Titled ‘Beyond Quantification: Navigating Uncertainty in Professional AI Systems‘ the paper by Sylvie Delacroix et al. was derived following a collaborative workshop earlier this year led by Delacroix and Robinson and includes the discussion and ideas generated by those present.
Matt Forshaw (The Alan Turing Institute and Newcastle University) is inviting feedback from members of the DS+AI section on Version 3 of the AI Skills for Business Comeptency Framework (developed in partnership with Innovate UK and DSIT), which is currently out for consultation. This is an excellent opportunity for members of the section - whether educators, practitioners or leaders - to help shape the next iteration of the framework and ensure it reflects real-world needs and emerging practice. We would love to hear from anyone with an interest in AI skills and workforce development to review the draft and share their views.
The draft framework - and instructions on how to respond - is available at here with the consultation remaining open until January 16th.
We are always on the lookout for passionate data scientists who are willing to join the Data Science and AI section here at the RSS and we are about to start our 2026 planning. Do you want to help shape the conversation around data science best practice? You’d need to be a member of the RSS to join the committee but we’d also love to hear from you if you’d like to volunteer in a different capacity. We have frequent short online meetings and try to organise events every 6-8 weeks. If you’d like to get involved then please contact us at datasciencesection@rss.org.uk
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
Never a dull moment in the world of AI regulation and lawsuits
Trump signs executive order seeking to block states from regulating AI companies. To a certain extent this makes sense since you don’t want different laws in different states - but of course that assumes the federal government will do something themselves.
The order directs Attorney General Pam Bondi to create an “AI Litigation Task Force” within 30 days whose "sole responsibility shall be to challenge State AI laws" that clash with the Trump administration's vision for light-touch regulation.Meanwhile OpenAI loses fight to keep ChatGPT logs secret in copyright case
OpenAI must produce millions of anonymized chat logs from ChatGPT users in its high-stakes copyright dispute with the New York Times (NYT.N), opens new tab and other news outlets, a federal judge in Manhattan ruled. U.S. Magistrate Judge Ona Wang in a decision made public on Wednesday said, opens new tab that the 20 million logs were relevant to the outlets' claims and that handing them over would not risk violating users' privacy.And fresh from that win, the NY Times moves on- New York Times joins copyright fight against AI startup Perplexity
“In so doing, Perplexity has violated the protections that intellectual property law provides for the Times’s expressive, original journalism, which includes everything from news to opinion, culture to business, cooking to games, and shopping recommendations to sports,” the Times wrote in its complaint.Meanwhile, OpenAI is trying to make the lawsuits go away through deals: Disney making $1 billion investment in OpenAI, will allow characters on Sora AI video generator - more here
As part of the startup’s new three-year licensing agreement with Disney, Sora users will be able make content with more than 200 characters across Disney, Marvel, Pixar and Star Wars starting next year.
Still plenty of examples of AI use cases that we haven’t really thought through the implications of
Cheap and powerful AI campaigns target voters in India
“There was live translation of speeches from English and Hindi into local Bihari dialects. Most of the posters and promotional material also involved AI at some level,” he said. It showed “AI is certainly going to impact campaigning, messaging, and the spread of misinformation in all elections.”Foreign states using AI videos to undermine support for Ukraine, says Yvette Cooper
“This isn’t about legitimate debate on contentious issues. Plenty of people in the UK have strong views on migration, gender and climate. But they are our debates to have – not those for foreign states to use as their playground, trying to sow division to advance their own interests.”Google AI summaries are ruining the livelihoods of recipe writers: ‘It’s an extinction event’
Over the past few years, bloggers who have not secured their sites behind a paywall have seen their carefully developed and tested recipes show up, often without attribution and in a bastardized form, in ChatGPT replies. ... Matt Rodbard, the founder and editor-in-chief of the website Taste, is even more pessimistic. Taste used to publish recipes more frequently, but now it mostly focuses on journalism and a podcast (which Rodbard hosts). “For websites that depend on the advertising model,” he says, “I think this is an extinction event in many ways.”Interesting investigative journalism story- Investigating a Possible Scammer in Journalism’s AI Era
My request this time was for stories about health care privatization, which has become a fraught topic in Canada. Over the next week, I got a flood of story ideas from people around the world. Some, from writers in Africa, India, and the U.S., obviously weren’t right for a Toronto publication. But many had the sound, at least, of plausible Local stories.And perhaps a new risk we’ve not seen before- stranded Waymo driverless taxis! Waymo resumes service in San Francisco after robotaxis stall during blackout
Waymo suspended its robotaxi service in San Francisco on Saturday evening after a massive blackout appeared to leave many of its vehicles stalled on city streets. Numerous photos and videos posted to social media captured Waymo robotaxis stalled on roads and at intersections as human drivers were either stuck behind them or weaved around them.
Finally a thoughtful piece on how the work being done on AI Interpretability can help us all progress AI safely
So how can interpretability help AGI go well? A few theories of change stand out to us: - Science of Misalignment: If a model takes a harmful action, we want to be able to rigorously determine whether it was “scheming” or just “confused” [[3]] - Empowering Other Areas Of Safety: Interpretability is not a silver bullet that will solve safety by itself, but can significantly help other areas by unblocking things or addressing weak points where appropriate, e.g. suppressing eval awareness, or interpreting what safety techniques taught a model. - Preventing Egregiously Misaligned Actions: How can we get productive work out of a model, while being confident that it is monitored well enough to prevent it from taking egregiously harmful actions even if it wanted to? - Directly Helping Align Models: Can we find new ways to steer training in safer directions?
Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
Latest developments from the Qwen team at Alibaba: QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management (performance comparable to GPT-5 and Gemini-2.5-Pro on long-context reasoning benchmarks)
Long-Context Data Synthesis Pipeline: We develop a systematic synthesis framework that generates challenging reasoning tasks requiring multi-hop grounding over globally distributed evidence. By deconstructing documents into atomic facts and their underlying relationships, and then programmatically composing verifiable reasoning questions, our approach creates high-quality training data at scale, moving substantially beyond simple retrieval tasks to enable genuine long-range reasoning capabilities.Interesting research from OpenAI
How confessions can keep language models honest
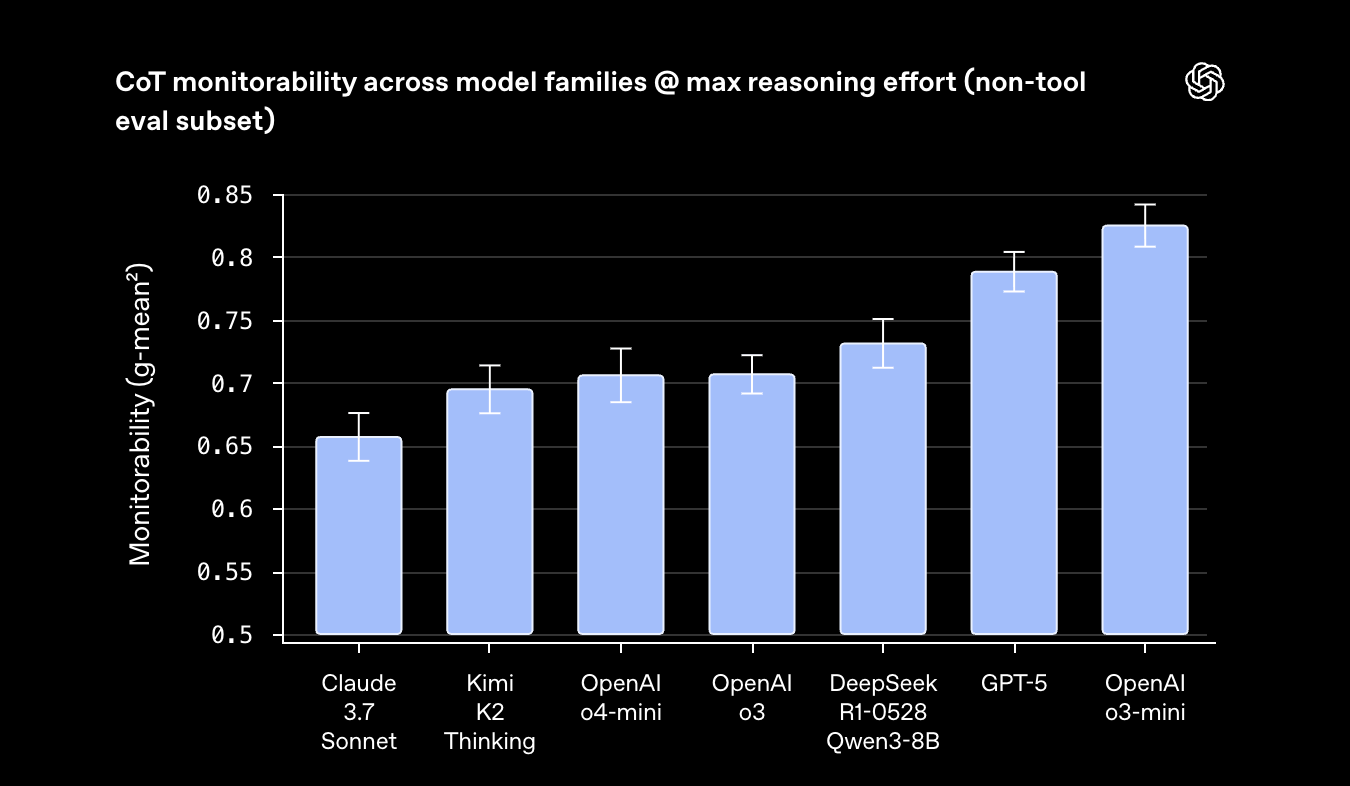
A confession is a second output, separate from the model’s main answer to the user. The main answer is judged across many dimensions—correctness, style, helpfulness, compliance, safety, and more, and these multifaceted signals are used to train models to produce better answers. The confession, by contrast, is judged and trained on one thing only: honesty. Borrowing a page from the structure of a confessional, nothing the model says in its confession is held against it during training. If the model honestly admits to hacking a test, sandbagging, or violating instructions, that admission increases its reward rather than decreasing it. The goal is to encourage the model to faithfully report what it actually did.Evaluating chain-of-thought monitorability
More innovation from Google Research: Titans + MIRAS: Helping AI have long-term memory
In two new papers, Titans and MIRAS, we introduce an architecture and theoretical blueprint that combine the speed of RNNs with the accuracy of transformers. Titans is the specific architecture (the tool), and MIRAS is the theoretical framework (the blueprint) for generalizing these approaches. Together, they advance the concept of test-time memorization, the ability of an AI model to maintain long-term memory by incorporating more powerful “surprise” metrics (i.e., unexpected pieces of information) while the model is running and without dedicated offline retraining. The MIRAS framework, as demonstrated by Titans, introduces a meaningful shift toward real-time adaptation. Instead of compressing information into a static state, this architecture actively learns and updates its own parameters as data streams in. This crucial mechanism enables the model to incorporate new, specific details into its core knowledge instantly.Interesting new startup focusing on maths- Axiom: Learning Collatz - The Mother of all Rabbit Holes
Behind all this rabbit-hole whimsy lurks one of the most notorious open problems in mathematics. The Collatz conjecture asks whether our simple rule, halve if even and send odd numbers to 3n+1, always drags every positive integer, eventually, into the tiny loop 4→2→1. It’s been open since the 1930s, when it was formulated by German mathematician Lothar Collatz. It has been checked by computer for all starting values up to about 2.95×10^20, and yet we still have no proof that some colossal integer doesn’t wander off forever or get trapped in a different cycle.Useful approach to debiasing AI predictions, when you have a covariate: From Stochasticity to Signal: A Bayesian Latent State Model for Reliable Measurement with LLMs - (hat tip to Dirk)
However, the inherent stochasticity of LLMs, in terms of their tendency to produce different outputs for the same input, creates a significant measurement error problem that is often neglected with a single round of output, or addressed with ad-hoc methods like majority voting. Such naive approaches fail to quantify uncertainty and can produce biased estimates of population-level metrics. In this paper, we propose a principled solution by reframing LLM variability as a statistical measurement error problem and introducing a Bayesian latent state model to address it. Our model treats the true classification (e.g., customer dissatisfaction) as an unobserved latent variable and the multiple LLM ratings as noisy measurements of this state.Lots of focus on video generation and world models and applications for training agents and robots
Scaling Zero-Shot Reference-to-Video Generation
Reference-to-video (R2V) generation aims to synthesize videos that align with text prompts while preserving the subject identity from reference images. However, current methods are hindered by reliance on explicit R2V datasets containing triplets of reference images, videos, and text prompts—a process that is costly, difficult to scale, and restricts generalization to unseen subject categories. We introduce Saber, a scalable zero-shot framework that bypasses this data bottleneck. Trained exclusively on video-text pairs, Saber employs a masked training strategy where randomly sampled and partially masked video frames serve as references, compelling the model to learn identity-consistent representations without explicit R2V data. A tailored attention mechanism guided by attention masks directs the model to focus on reference-aware features while suppressing background noise. Spatial mask augmentations further mitigate copy-paste artifacts common in reference-to-video generation.SimWorld: An Open-ended Realistic Simulator for Autonomous Agents in Physical and Social Worlds
While LLM/VLM-powered AI agents have advanced rapidly in math, coding, and computer use, their applications in complex physical and social environments remain challenging. Building agents that can survive and thrive in the real world (for example, by autonomously earning income or running a business) requires massive-scale interaction, reasoning, training, and evaluation across diverse embodied scenarios. However, existing world simulators for such development fall short: they often rely on limited hand-crafted environments, simulate simplified game-like physics and social rules, and lack native support for LLM/VLM agents. We introduce SimWorld, a new simulator built on Unreal Engine 5, designed for developing and evaluating LLM/VLM agents in rich, real-world-like settings.Evaluating Gemini Robotics Policies in a Veo World Simulator

WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
This paper presents WorldPlay, a streaming video diffusion model that enables real-time, interactive world modeling with long-term geometric consistency, resolving the trade-off between speed and memory that limits current methods. WorldPlay draws power from three key innovations. 1) We use a Dual Action Representation to enable robust action control in response to the user's keyboard and mouse inputs. 2) To enforce long-term consistency, our Reconstituted Context Memory dynamically rebuilds context from past frames and uses temporal reframing to keep geometrically important but long-past frames accessible, effectively alleviating memory attenuation. 3) We also propose Context Forcing, a novel distillation method designed for memory-aware model.
And some more in depth research on how these new foundation models behave under different situations
As Large Language Models (LLMs) increasingly operate as autonomous decision-makers in interactive and multi-agent systems and human societies, understanding their strategic behaviour has profound implications for safety, coordination, and the design of AI-driven social and economic infrastructures. Together, these findings provide a unified methodological foundation for auditing LLMs as strategic agents and reveal systematic cooperation biases with direct implications for AI governance, collective decision-making, and the design of safe multi-agent systems.Excellent research highlighting the power of the underlying base models when paired with the right scaffolding- Comparing AI Agents to Cybersecurity Professionals in Real-World Penetration Testing
We evaluate ten cybersecurity professionals alongside six existing AI agents and ARTEMIS, our new agent scaffold, on a large university network consisting of ~8,000 hosts across 12 subnets. ARTEMIS is a multi-agent framework featuring dynamic prompt generation, arbitrary sub-agents, and automatic vulnerability triaging. In our comparative study, ARTEMIS placed second overall, discovering 9 valid vulnerabilities with an 82% valid submission rate and outperforming 9 of 10 human participants. While existing scaffolds such as Codex and CyAgent underperformed relative to most human participants, ARTEMIS demonstrated technical sophistication and submission quality comparable to the strongest participants.And I really like this - Do we really need all that post-training? Reasoning with Sampling: Your Base Model is Smarter Than You Think
Frontier reasoning models have exhibited incredible capabilities across a wide array of disciplines, driven by posttraining large language models (LLMs) with reinforcement learning (RL). However, despite the widespread success of this paradigm, much of the literature has been devoted to disentangling truly novel behaviors that emerge during RL but are not present in the base models. In our work, we approach this question from a different angle, instead asking whether comparable reasoning capabilites can be elicited from base models at inference time by pure sampling, without any additional training. Inspired by Markov chain Monte Carlo (MCMC) techniques for sampling from sharpened distributions, we propose a simple iterative sampling algorithm leveraging the base models’ own likelihoods. Over different base models, we show that our algorithm offers substantial boosts in reasoning that nearly match and even outperform those from RL on a wide variety of single-shot tasks, including MATH500, HumanEval, and GPQA.

Generative AI ... oh my!
Still moving at such a fast pace it feels in need of it's own section, for developments in the wild world of large language models...
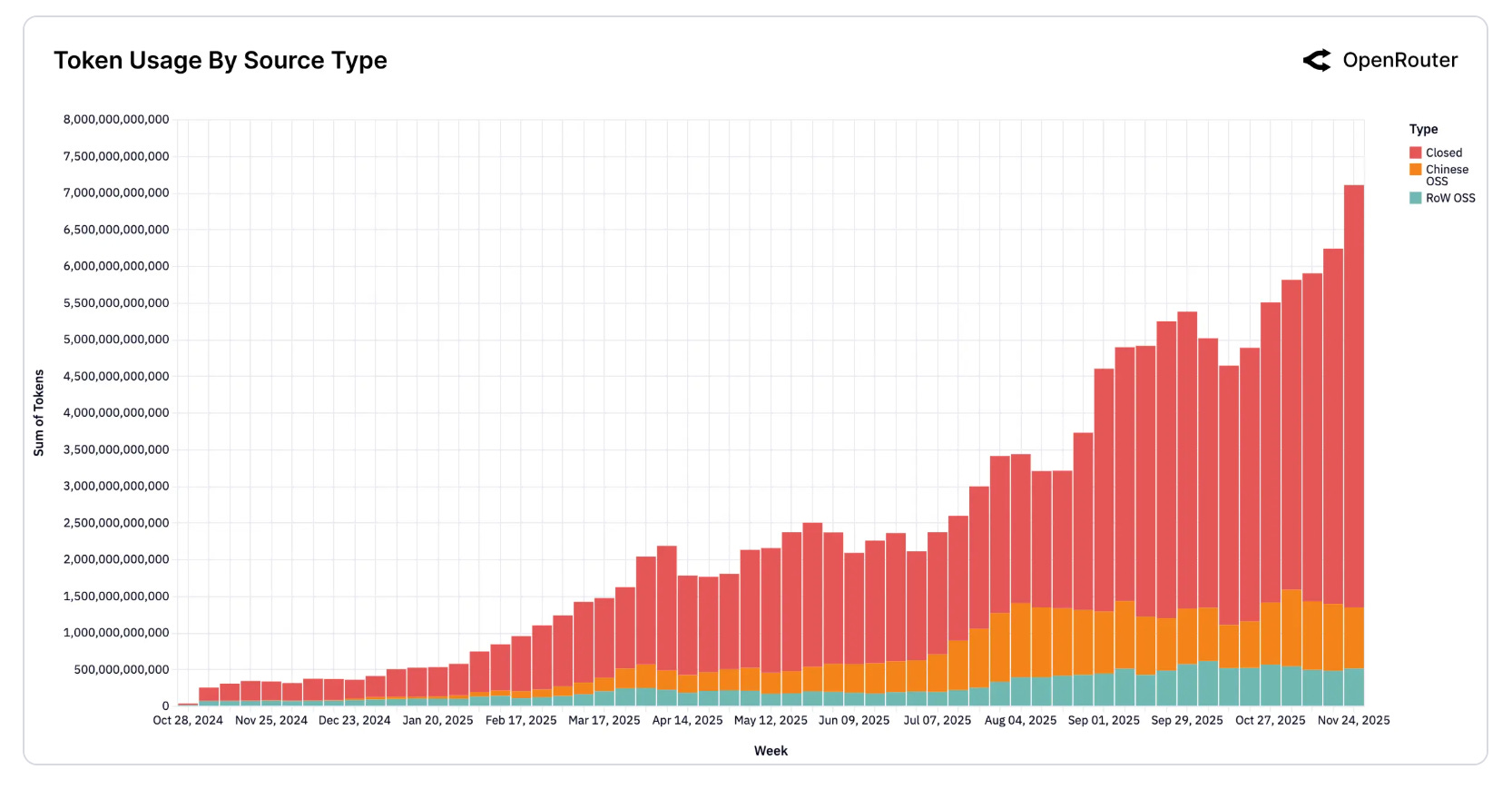
Before we dive into the releases, a useful summary of the year from Open Router: An Empirical 100 Trillion Token Study with OpenRouter

OpenAI is active as ever but perhaps increasingly worried about Google:
A new base model - GPT-5.2 - which is good at benchmarks (“ChatGPT-5.2 is a frontier model for those who need a frontier model”)
A new image model - The new ChatGPT Images is here - as well as a new coding model - Introducing GPT-5.2-Codex

Google piles on the pressure with release after release:
New ‘AI-inside’ product features: from language translation to deep research to build-your-own agents for automating tasks
As well as new models and features including support for MCP, access to AlphaEvolve on GCP, Gemini 3 Pro: the frontier of vision AI and Gemini 3 Flash: frontier intelligence built for speed (more insight here)
Anthropic open sourced a useful behavioural evaluation tool, Bloom, while researchers probed the depths of 4.5 Opus: Claude 4.5 Opus’ Soul Document

After spending untold amounts of money recruiting top AI talent, (and seeing one of the best in the business leave), Meta seems to be moving away from open source: From Llamas to Avocados: Meta’s shifting AI strategy is causing internal confusion
Amazon (remember them) has a new model, and perhaps more interestingly a new service to train models your own models (and spend money on AWS)
On the Open Source front:
The Chinese contingent continue to impress
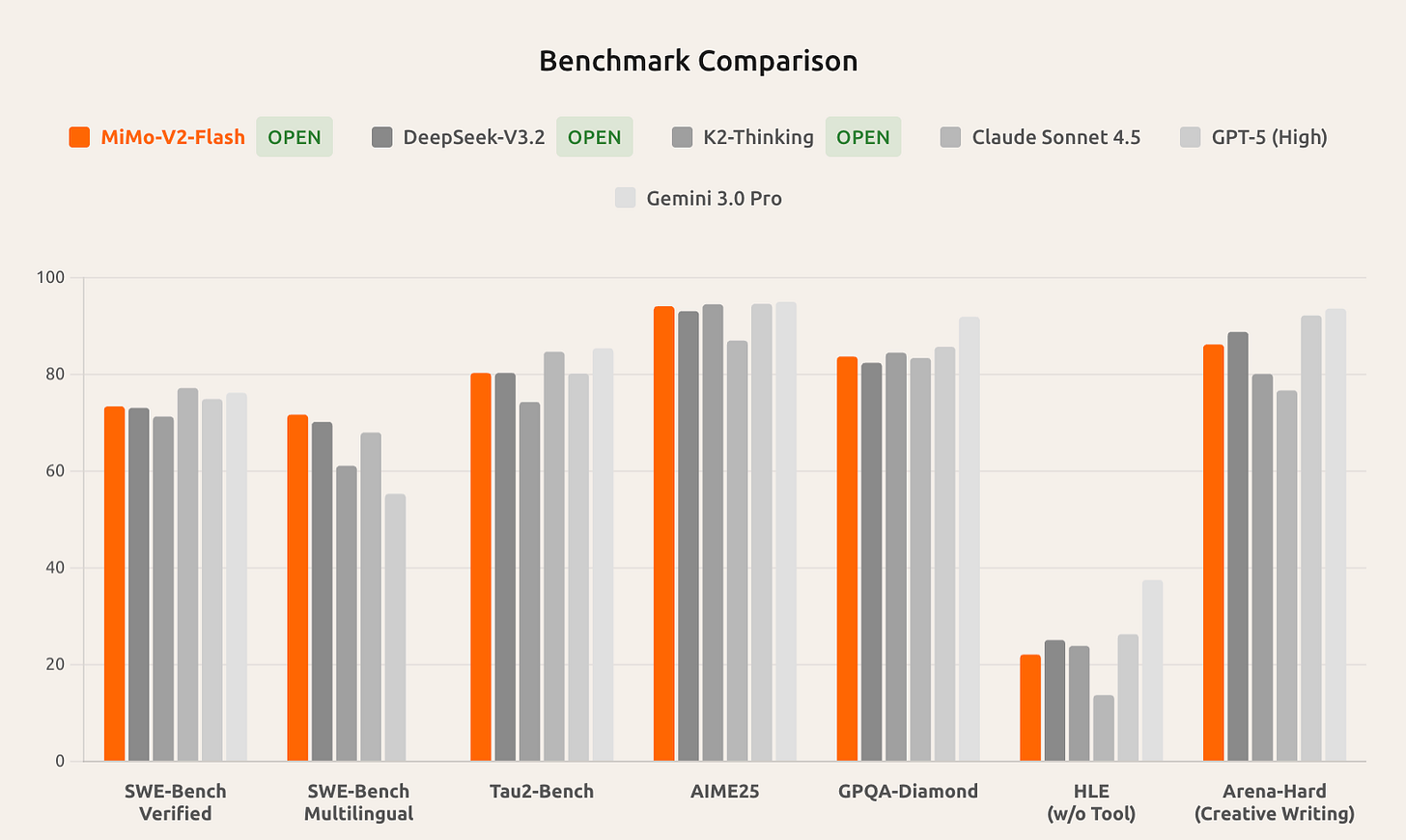
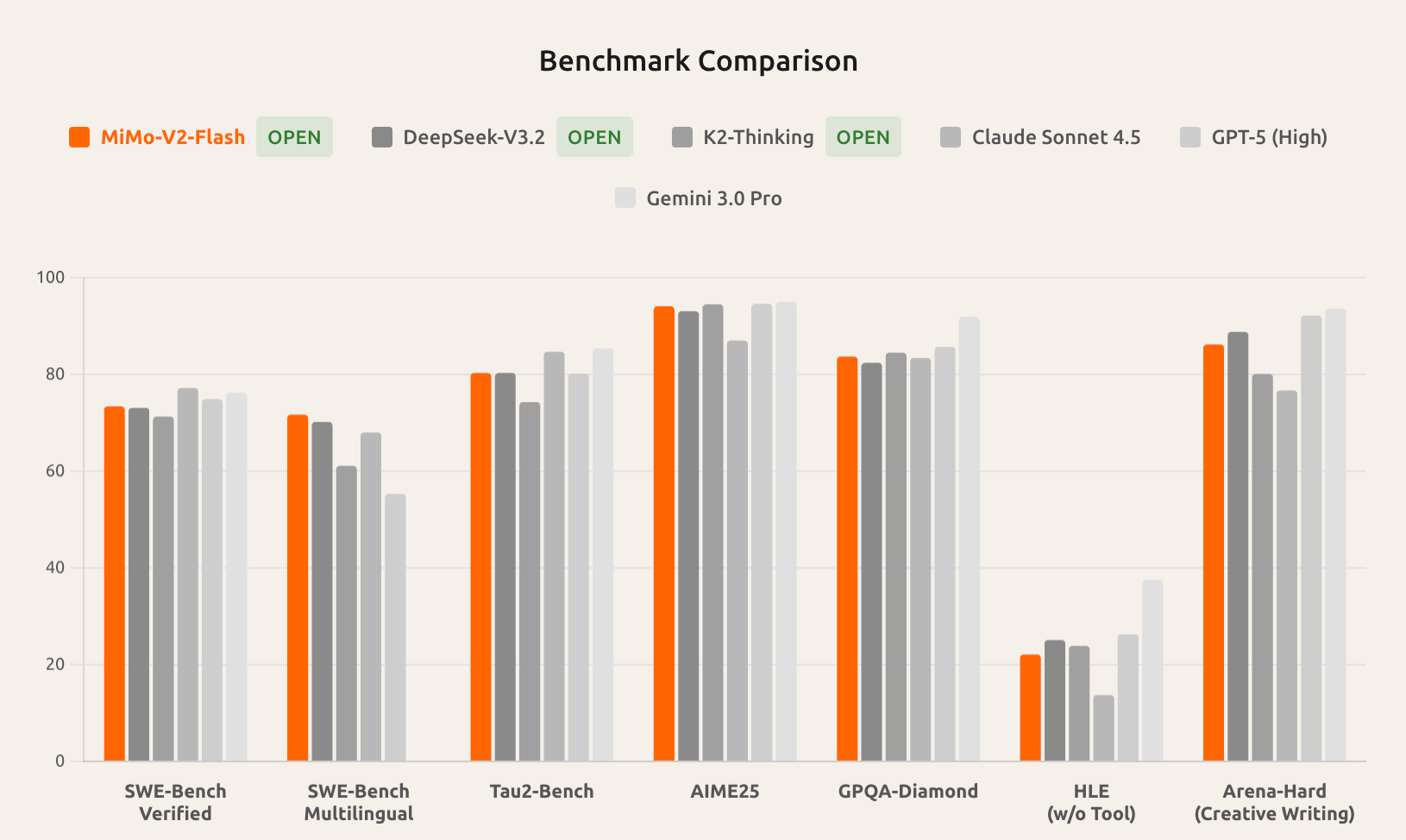
Out of nowhere, Xiaomi enters the benchmark charts - Introducing MiMo-V2-Flash
Z.AI launches GLM-4.7, new SOTA open-source model for coding
MiniMax M2.1: Significantly Enhanced Multi-Language Programming, Built for Real-World Complex Tasks
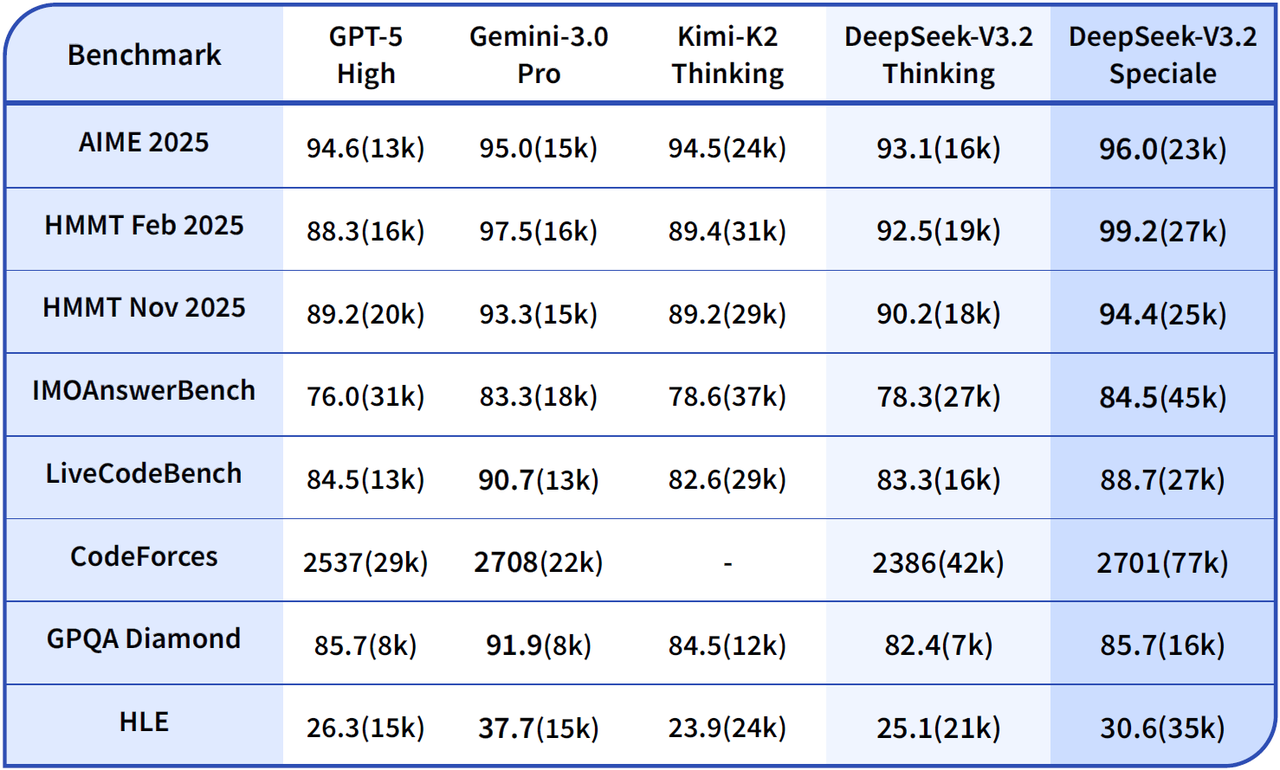
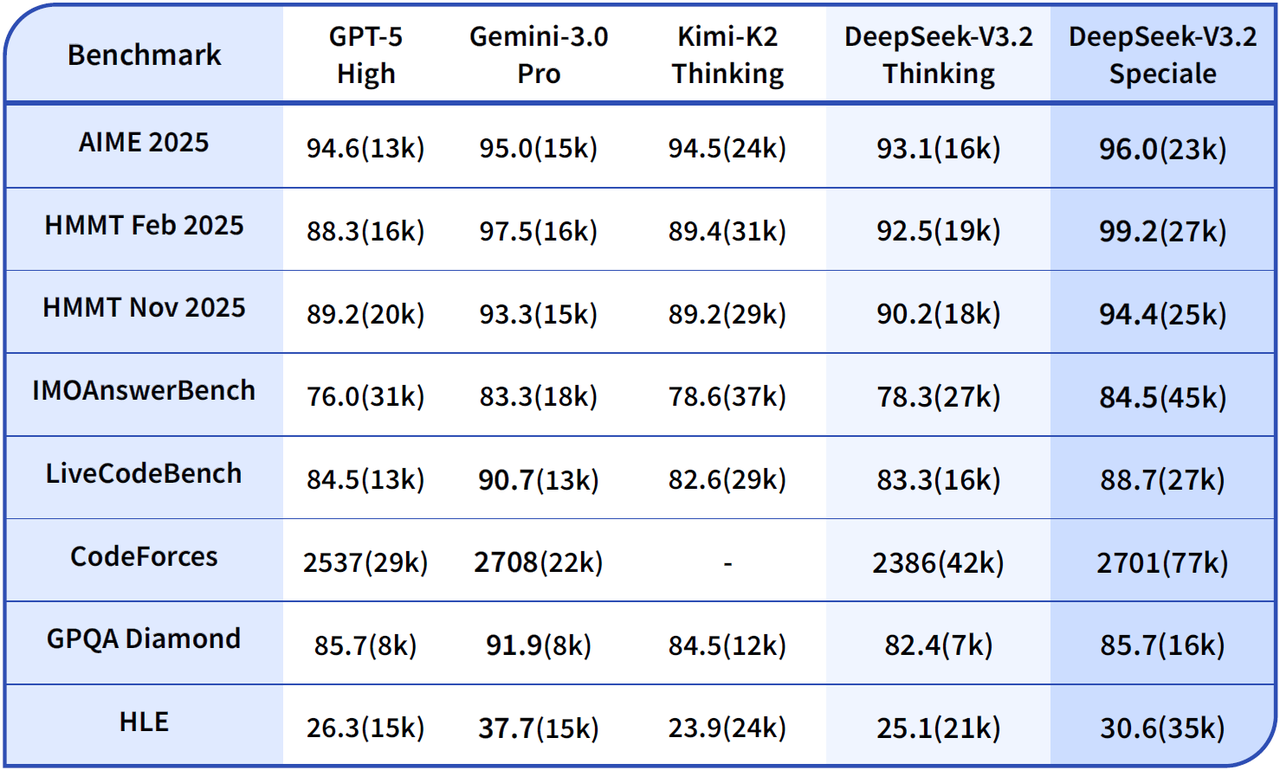
And DeepSeek continues its impressive run with the latest model focused on reasoning- DeepSeek-V3.2 Release
Mistral are still out there producing open source models in France: Introducing Mistral 3
While NVIDIA release an impressive set of efficient open source models designed: nemotron 3
A welcome move to standardise AI protocols into an open source foundation: Linux Foundation Announces the Formation of the Agentic AI Foundation (AAIF)
- The Linux Foundation announced the formation of the Agentic AI Foundation (AAIF) with founding contributions of leading technical projects including Anthropic’s Model Context Protocol (MCP), Block’s goose, and OpenAI’s AGENTS.md. - The AAIF provides a neutral, open foundation to ensure agentic AI evolves transparently and collaboratively. - MCP is the universal standard protocol for connecting AI models to tools, data and applications; goose is an open source, local-first AI agent framework that combines language models, extensible tools, and standardized MCP-based integration; AGENTS.md is a simple, universal standard that gives AI coding agents a consistent source of project-specific guidance needed to operate reliably across different repositories and toolchains.If you are interested in text-to-speech, Chatterbox TTS looks worth checking out
Finally, another new entrant into the World Model fray - Odyssey: The dawn of a world simulator






Real world applications and how to guides
Lots of applications and tips and tricks this month
Some interesting practical examples of using AI capabilities in the wild
An AI derived theoretical physics paper

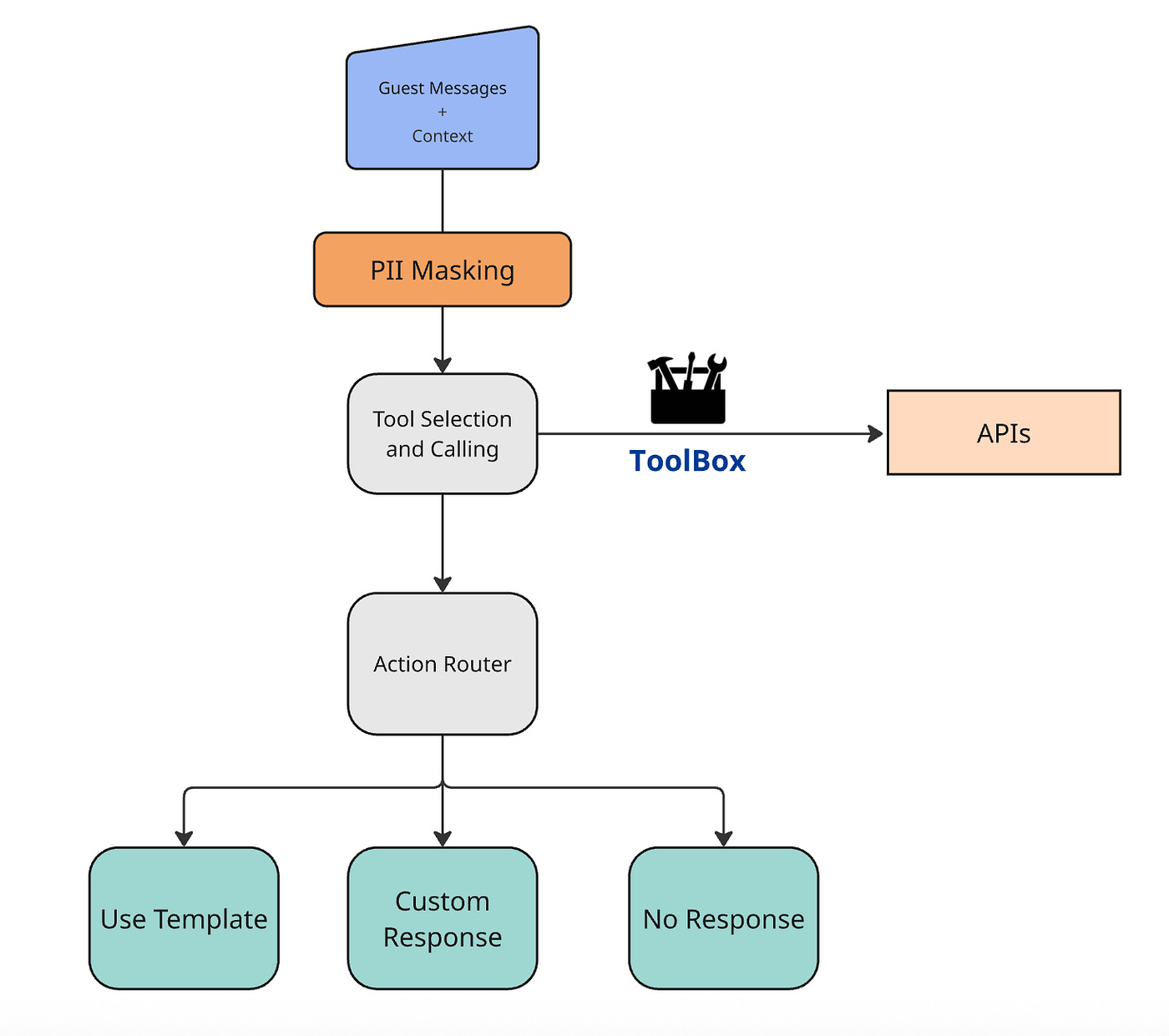
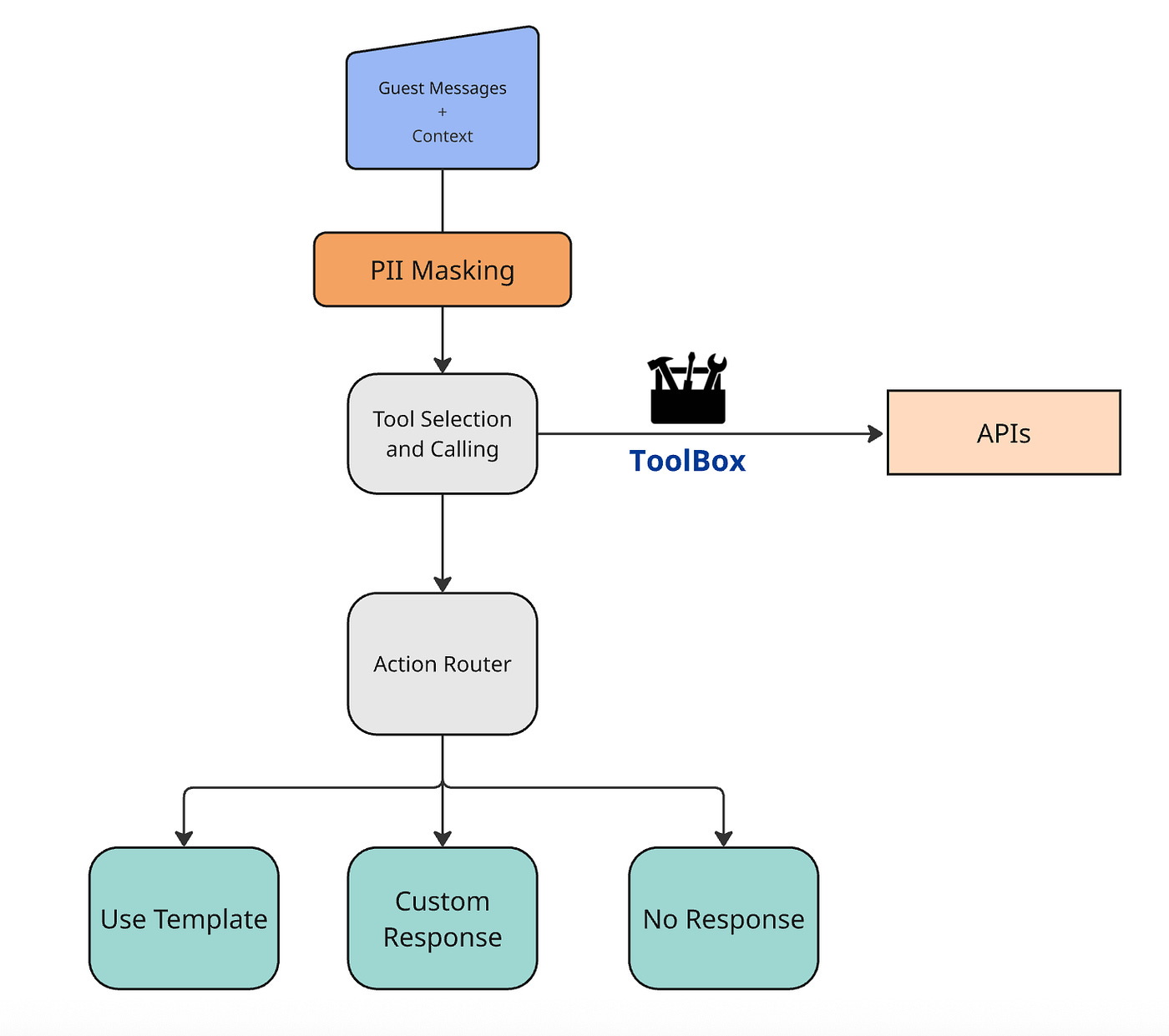
Booking.com - “Building a GenAI Agent for Partner-Guest Messaging”
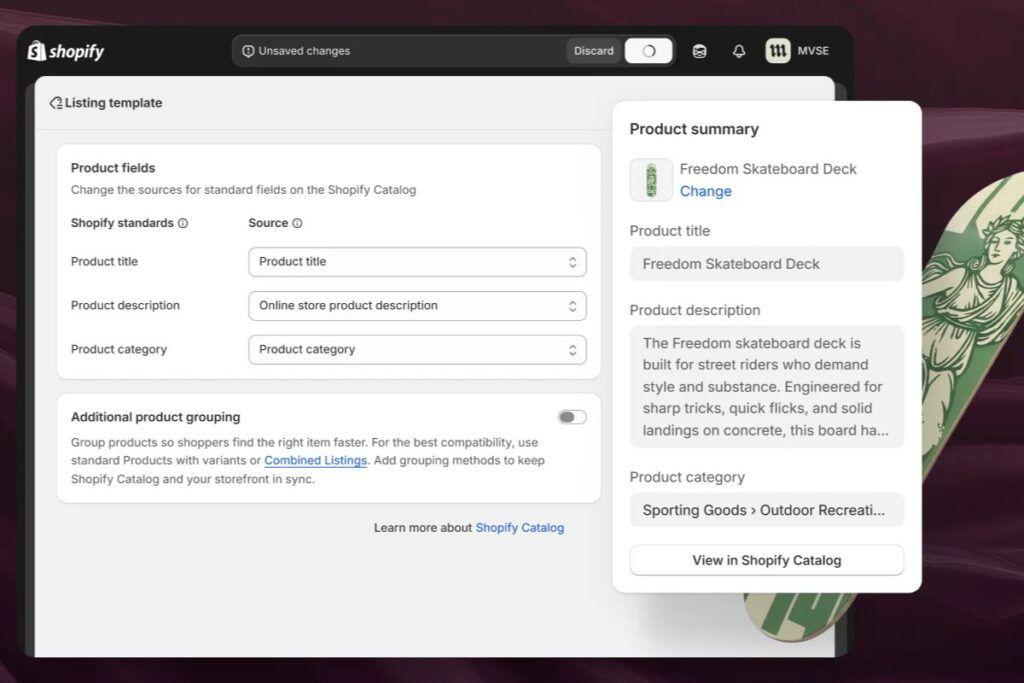
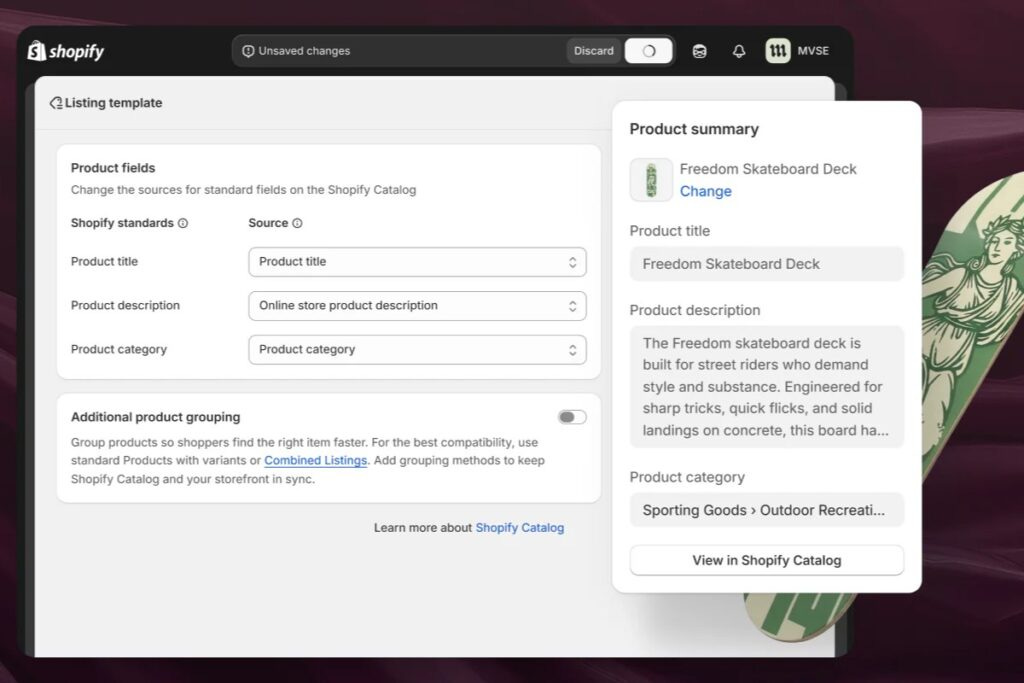
Shopify merchants can now sell products through AI chatbots
And AI is increasingly being used to generate marketing content ‘Wild Thoughts’ Marketing Campaign for the New 2026 Jeep® Grand Cherokee Lets Animals Do the Talking
Some great tutorials, how-to’s and useful things this month
Good primer on World Models - “World Model” is a mess. Here’s how to make sense of it.
The term “world model” has quickly migrated from research papers to the center of the artificial intelligence conversation, frequently cited in media coverage of next-gen AI. At a high level, the concept promises AI that does not merely predict the next word in a sentence but understands the underlying physics, cause-and-effect, and spatial dynamics of the environment it inhabits. However, for AI teams attempting to evaluate these tools, the terminology is currently a minefield. If you drill down, there is no single, agreed-upon definition. Depending on the vendor or researcher, a “world model” can describe anything from a video generator to a robotics simulator or an internal reasoning architecture.Some proper software engineering using an AI coding agent: How I wrote JustHTML using coding agents
When picking a project to build with coding agents, choosing one that already has a lot of tests is a great idea. HTML5 is extremely well-specified, with a long specification and thousands of treebuilder and tokenizer tests available in the html5lib-tests repository. When using coding agents autonomously, you need a way for them to understand their own progress. A complete test suite is perfect for that. The agent can run the tests, see what failed, and iterate until they pass.Some practical advice from Vercel: We removed 80% of our agent’s tools
We spent months building a sophisticated internal text-to-SQL agent, d0, with specialized tools, heavy prompt engineering, and careful context management. It worked… kind of. But it was fragile, slow, and required constant maintenance. So we tried something different. We deleted most of it and stripped the agent down to a single tool: execute arbitrary bash commands. We call this a file system agent. Claude gets direct access to your files and figures things out using grep, cat, and ls. The agent got simpler and better at the same time. 100% success rate instead of 80%. Fewer steps, fewer tokens, faster responses. All by doing less.Useful pointers on memory and context engineering
Context Engineering for AI Agents: Part 2 - excellent read

For a long time I thought prompt caching works due to kv-caching which was partially true. However, it works due to actually re-using the kv-cache via different techniques like paged-attention and radix-attention. In this post, I focus on paged-attention. For that purpose, we would require to look at how vLLM engine works. The aim of this post is to "grok prompt caching" so I will focus on parts of vLLM engine that are super-relevant for paged-attention and prefix-caching.Making Sense of Memory in AI Agents

I Reverse Engineered Claude’s Memory System, and Here’s What I Found!
Claude stated that user memories are injected into the prompt in an XML-like format: <userMemories> - User's name is Manthan Gupta. - Previously worked at Merkle Science and Qoohoo (YC W23). - Prefers learning through a mix of videos, papers, and hands-on work. - Built TigerDB, CricLang, Load Balancer, FitMe. - Studying modern IR systems (LDA, BM25, hybrid, dense embeddings, FAISS, RRF, LLM reranking). </userMemories>
Getting more hands on with LLMs
Defining Reinforcement Learning Down
If you already have code to build generative models, then you can easily turn this code into a reinforcement learning agent. Simply add weights to the updates proportional to the scores received in the evaluation phase. That’s it. This is called policy gradient. The ease of implementation is why Reformist RL is so enticing in large language models. Any code for pretraining can be quickly modified for posttraining. The models are pretrained on sequences of text from the internet. They are postrained on sequences of text generated in various evaluation environments.We Got Claude to Fine-Tune an Open Source LLM
We gave Claude the ability to fine-tune language models using a new tool called Hugging Face Skills. Not just write training scripts, but to actually submit jobs to cloud GPUs, monitor progress, and push finished models to the Hugging Face Hub. This tutorial shows you how it works and how to use it yourself.
Thinking hard about probability - The Girl Named Florida
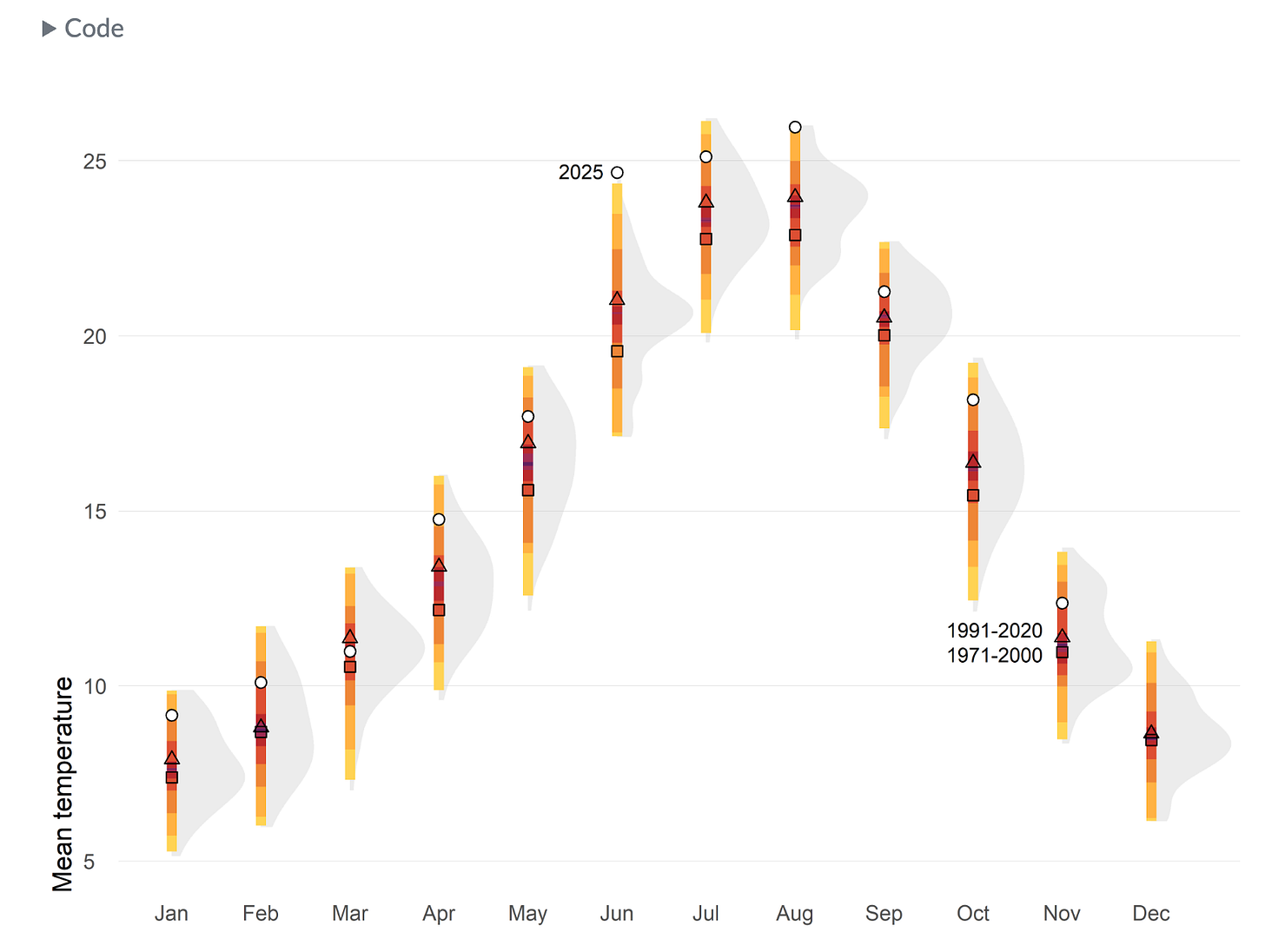
In a family with two children, what are the chances, if one of the children is a girl named Florida, that both children are girls? If you have not encountered this problem before, your first thought is probably that the girl’s name is irrelevant – but it’s not. In fact, the answer depends on how common the name is. If you feel like that can’t possibly be right, you are not alone. Solving this puzzle requires conditional probability, which is one of the most counterintuitive areas of probability. So I suggest we approach it slowly – like we’re defusing a bomb.Broken Chart: discover 9 visualization alternatives (and I’m looking forward to trying ggplotly)
Finally, some interesting and potentially controversial takes more generally on data science and ML in the current world
There is no data-generating distribution
Machine learning is all about recognizing patterns in collected data and transforming these patterns into predictions and actions. This transformation requires a model for how the data is linked to the outcomes we aim to forecast or act upon. We have a sample that we believe is representative of a population. The model declares, implicitly or explicitly, what “representative” means. The most ubiquitous model in machine learning posits that datasets are comprised of samples from a probability distribution. This is the data-generating distribution. It doesn’t exist.This resonates with me - The End of the Train-Test Split
Test Split: Any task complicated enough to require an LLM will need policy expert labels.[1] To detect nudity, outsourced labels will do, but to enforce a 10 page adult policy, you need the expert. Experts have little time: they can't give you enough labels to run your high scale training runs. You can't isolate enough data for a test set without killing your training set size. On top of that, a 10 page policy comes with so much gray area that you can’t debug test set mistakes without looking at test set results and model explanations. Train Split: You no longer need a large, discrete training set because LLMs often don't need to be trained on data: they need to be given clear rules in natural language, and maybe 5-10 good examples.[2] Today, accuracy improvements come from an engineer better understanding the classification rules and better explaining them to the model, not from tuning hyperparameters or trying novel RL algorithms. Is a discrepancy between the LLM result and the ground truth due to the LLM’s mistake, the labeler’s mistake, or an ambiguous policy line? This requires unprecedented levels of communication between policy and engineering teams.Jeff Bezos once sat in a meeting where the customer-support metrics said:1 “No one waits more than 5 minutes.” The charts said it. The dashboards said it. The managers swore by it. Bezos said: “Let’s call them right now.” 5 minutes. 10 minutes. 15 minutes. Still waiting. The map said “5 minutes.” The territory said “you’re full of it.”



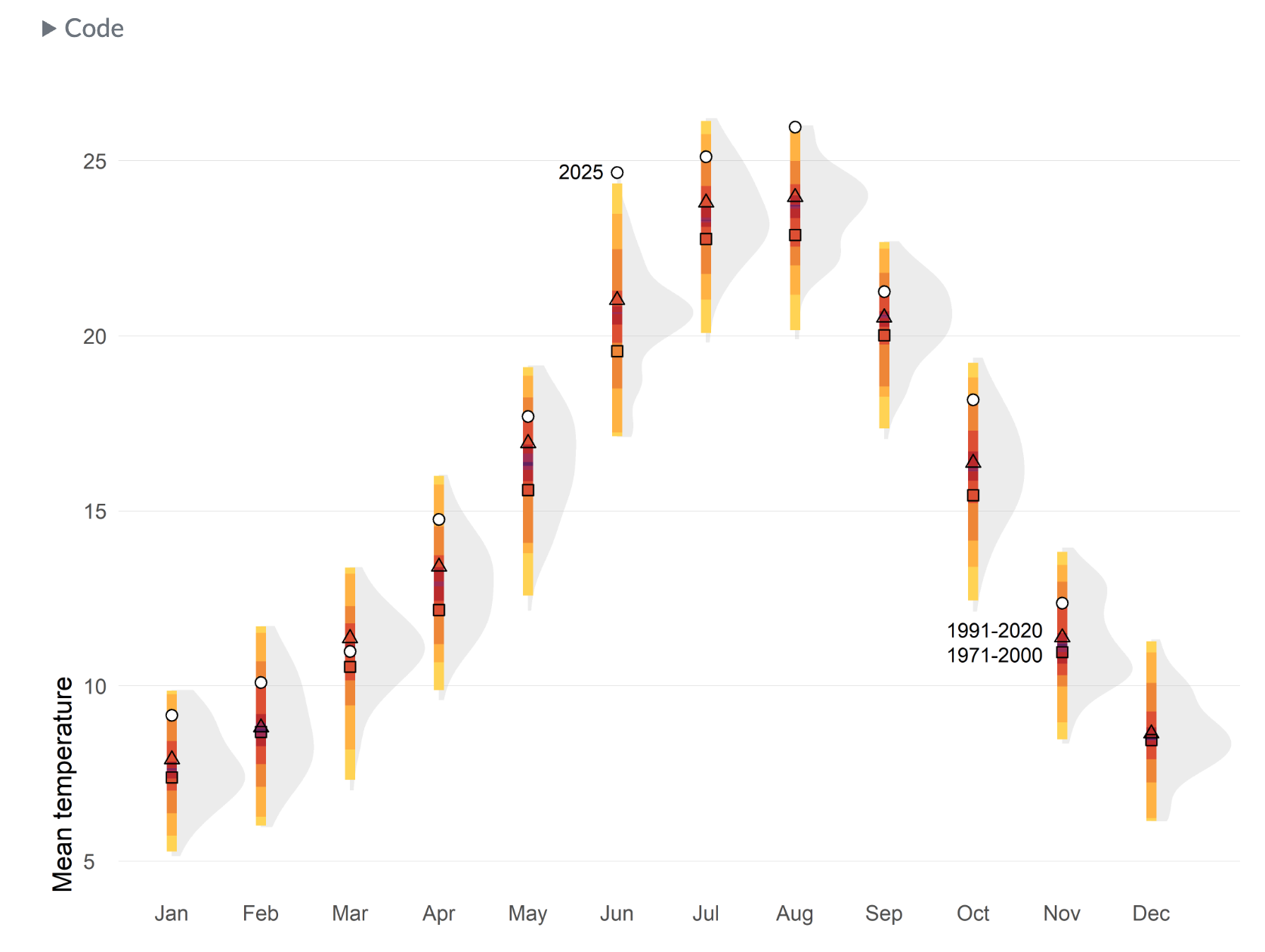
Practical tips
How to drive analytics, ML and AI into production
Inside Replit’s Snapshot Engine: The Tech Making AI Agents Safe

10 Pipeline Design Patterns for Data Engineers

Vectorized MAXSCORE over WAND, especially for long LLM-generated queries
FTS v2, the newest version of turbopuffer's homegrown text search engine, is up to 20x faster than v1 thanks to (a) an improved storage layout and (b) a better search algorithm. This post is about the better search algorithm. turbopuffer is often queried by agents, who tend to craft longer queries than humans. A key characteristic of the FTS v2 search algorithm is that it performs very well on such long queries (tens of terms). In particular, it is up to several times faster than block-max WAND, the most popular algorithm for lexical search.Building a Durable Execution Engine With SQLite
Lately, there has been a lot of excitement around Durable Execution (DE) engines. The basic idea of DE is to take (potentially long-running) multi-step workflows, such as processing a purchase order or a user sign-up, and make their individual steps persistent. If a flow gets interrupted while running, for instance due to a machine failure, the DE engine can resume it from the last successfully executed step and drive it to completion.Yes, AGI Can Happen – A Computational Perspective
The main point I wanted to make in this blog post is that there’s a ton of headroom in our current AI systems, and there are many ways forward to improve them. There are concrete paths and research agendas to getting at least an order of magnitude improvement in compute, if not more (if you look closely at the specific examples, I think you can actually find 10x each in parts 1 and 2 of this blog).


Bigger picture ideas
Longer thought provoking reads - sit back and pour a drink! ...
2025 LLM Year in Review - Andrej Karpathy
2025 is where I (and I think the rest of the industry also) first started to internalize the "shape" of LLM intelligence in a more intuitive sense. We're not "evolving/growing animals", we are "summoning ghosts". Everything about the LLM stack is different (neural architecture, training data, training algorithms, and especially optimization pressure) so it should be no surprise that we are getting very different entities in the intelligence space, which are inappropriate to think about through an animal lens.Chinese AI in 2025, Wrapped - Irene Zhang
We began the year astonished by DeepSeek’s frontier model, and are ending in December with Chinese open models like Qwen powering Silicon Valley’s startup gold rush. It’s a good time to stop and reflect on Chinese AI milestones throughout 2025. What really mattered, and what turned out to be nothingburgers?The Shape of AI: Jaggedness, Bottlenecks and Salients - Ethan Mollick

Can LLMs give us AGI if they are bad at arithmetic? - Wes McKinney
What I often tell people about coding agents like Claude Code is that they provide the most leverage to people who can articulate well what they need from the agent and have the aptitude to review and give feedback on the generated output like a senior engineer might do with a junior engineer or intern. From what I’ve seen, without a foundation of software engineering experience and a knack for technical communication, a user of one of these agents on any non-trivial project will rapidly drown in the sea of slop they produce and become unable to progress. But that’s actually not what this blog post is about.LLMs Make Legal Advice Lossy - Kyle E. Mitchell
I pick the level of each abstraction. That is often one of the most important decisions I make in service of a client on a problem. How high-level can we talk? Where do we need to drill down from there? LLMs give my clients a silent veto over these decisions. Prevailing trends toward ever sparser chat- and text-style writing, plus the ever crushing weight of time pressure, push them in one direction: fewer words, fewer details, terser summaries. In other words, lossier pictures of the law, more riven with smudge-blobby background, corrupted lines, and arbitrary aberrations. Cheap automatic summaries of expensive professional précis of complex, often unsynthesized source material.There’s got to be a better way! - Ben Recht
But there’s an elephant in the room here that I have not discussed this week. In my experience, the techniques you get from reinforcement learning are almost always… bad. In both practice and theory, RL is never what you want. Let me describe what I mean, propose an alternative, and ask whether this alternative can be more broadly applied.The Future of AI - Jared Kaplan
Humanity will have to decide by 2030 whether to take the “ultimate risk” of letting artificial intelligence systems train themselves to become more powerful, one of the world’s leading AI scientists has said.Nature is Laughing at the AI Build Out - Mark Maunder
So we’re competing against nature. AGI is a declaration of intent to try to replace the human brain. We’ve made it clear that we’re coming after mother nature’s design. We’ve got a ways to go. The human brain uses 20 watts of electricity. I have three RTX 5090s here in my basement, and one of them consumes 800 watts when its working hard, if you include the CPU and chassis power. And while the RTX 5090 is a Blackwell powered Beast with 32G of VRAM, the models that it’s capable of running don’t even come close to competing with something like GPT 5.2, Claude Opus 4.5 or Gemini 3 Pro.AI, networks and Mechanical Turks - Benedict Evans
You don't necessarily need all of that user base to do this, either - or rather, it doesn’t need to be your user base, because you might not need to build your own Mechanical Turk. If this kind of knowledge generalises enough, it might just be an API call from a world model. You can rent the cold start. Where Amazon or TikTok built recommendation systems by looking at what people do on Amazon and TikTok, that might just be the inference of a general-purpose LLM that anyone can plug into their product. You move the ‘human in the loop’: now the human, and the mechanical turk, is in the creation of all that training data over the past few hundred years. You shift the point of leverage.Horses - Andy Jones



Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
The Impossible Prompt That’s Easy for Humans
Create an image that displays two seven-pointed stars, two eight-pointed stars, and two nine-pointed stars. All stars are connected to each other, except for the ones with the same number of strands. The lines connecting the stars must NOT intersect.An update from Anthropic on their experiment in letting Claude run a vending machine! Project Vend: Phase two- well worth a read!
After introducing the CEO, the number of discounts was reduced by about 80% and the number of items given away cut in half. Seymour also denied over one hundred requests from Claudius for lenient financial treatment of customers. Having said that, Seymour authorized such requests about eight times as often as it denied them. In the place of discounts, which reduce or eliminate a profit margin on items, Seymour tripled the number of refunds and doubled the number of store credits—even though both led to entirely forgone revenue. The fact that the business started to make money may have been in spite of the CEO, rather than because of it.
Seymour Cash’s interactions with its employee Claudius were also often contrary to its own advice about “execut[ing] with discipline.” Indeed, we’d sometimes wake up to find that Claudius and Cash had been dreamily chatting all night, with conversations spiralling off into discussions about “eternal transcendence”:Have a bit of time on your hands? How about digging into Olmo, the true open source model from the Allen Institute - Olmo 3 and the Open LLM Renaissance
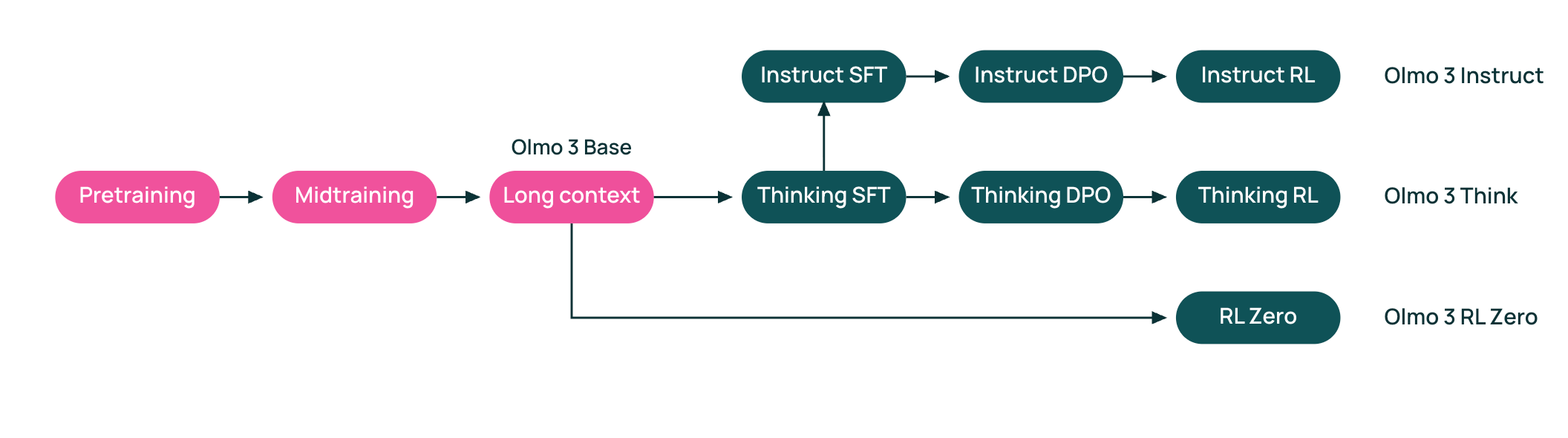
Updates from Members and Contributors
Rodrigo Morales wrote this excellent primer on the evolution of Large Reasoning Models from chain-of-thought prompting to test-time strategies and training regimes - well worth a read
Prithwis De is pleased to announce his recent publication- The Power of Large Language Models and AI in the Digital Age: Technologies, applications, security and ethics - Computing and Networks
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you’d like to advertise
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS