
December Newsletter
Industrial Strength Data Science and AI

Hi everyone-
Although listening in to the Ashes in Australia reminds you the sun does still exist, dark, cold and wet seems to be the norm for the festive season in London! Time to find a warm spot by the fire with some good reading materials on all things Data Science and AI… Lots of great content below and I really encourage you to read on, but here are the edited highlights if you are short for time!
Three Years from GPT-3 to Gemini 3 - Ethan Mollick
Becoming an AI detective is a job I never wanted and wish I could quit - Samantha Floreani
Over-Regulation is Doubling the Cost - Peter Reinhardt (not AI related but highlights the challenges of regulation)
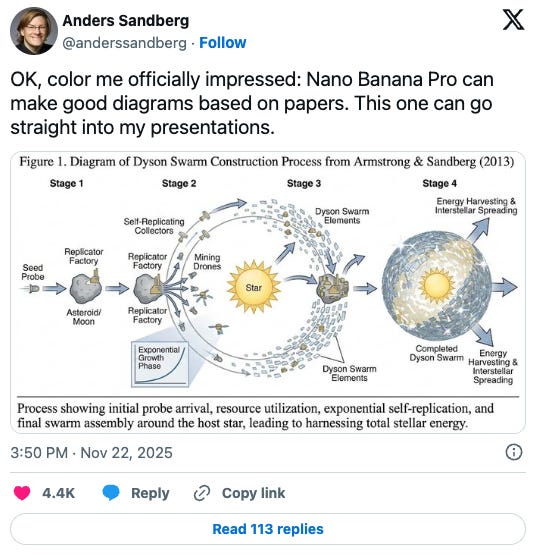
Nano Banana-pilled, Nano Banana-shilled for Spaceship Engineering - Angadh Nanjangud
From Words to Worlds: Spatial Intelligence is AI’s Next Frontier - Fei-Fei Li
Following is the latest edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
We are delighted to announce the opening of the first issue of RSS: Data Science and Artificial Intelligence with an editorial by the editors setting out their vision for the new journal.
A position paper on uncertainty in the era of AI has now been published into the issue of RSS: Data Science and Artificial Intelligence Issues | RSS: Data Science and Artificial Intelligence | Oxford Academic.
Titled ‘Beyond Quantification: Navigating Uncertainty in Professional AI Systems‘ the paper by Sylvie Delacroix et al. was derived following a collaborative workshop earlier this year led by Delacroix and Robinson and includes the discussion and ideas generated by those present.
Committee member Piers Stobbs, co-founder of Epic Life, presented at the Maths Week Parliamentary Expo at the House of Commons, highlighting the role of the mathematical sciences in preventative health
We are always on the lookout for passionate data scientists who are willing to join the Data Science and AI section here at the RSS and we are about to start our 2026 planning. Do you want to help shape the conversation around data science best practice? You’d need to be a member of the RSS to join the committee but we’d also love to hear from you if you’d like to volunteer in a different capacity. We have frequent short online meetings and try to organise events every 6-8 weeks. If you’d like to get involved then please contact us at datasciencesection@rss.org.uk
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
Never a month goes by without more activity in the ongoing copyright sagas associated with AI
On one hand: OpenAI used song lyrics in violation of copyright laws, German court says
OpenAI had argued that its language models did not store or copy specific training data but, rather, reflected what they had learned based on the entire training data set. Since the output would only be generated as a result of user inputs known as prompts, it was not the defendants, but the respective user who would be liable for it, OpenAI had argued. However, the court found that both the memorisation in the language models and the reproduction of the song lyrics in the chatbot’s outputs constitute infringements of copyright exploitation rights, according to a statement on the ruling.And then: AI firm wins high court ruling after photo agency’s copyright claim
A London-based artificial intelligence firm has won a landmark high court case examining the legality of AI models using vast troves of copyrighted data without permission. Stability AI, whose directors include the Oscar-winning film-maker behind Avatar, James Cameron, successfully resisted a claim from Getty Images that it had infringed the international photo agency’s copyright.And AI firms are exploring different licensing approaches
Universal Music Group (UMG), the world leader in music-based entertainment, and Udio, an AI-powered music creation platform, today announced industry-first strategic agreements, under which the companies settled copyright infringement litigation and will collaborate on an innovative, new commercial music creation, consumption and streaming experience.It’s not just copyright that is driving litigation- Fighting the New York Times’ invasion of user privacy
The New York Times is demanding that we turn over 20 million of your private ChatGPT conversations. They claim they might find examples of you using ChatGPT to try to get around their paywall. This demand disregards long-standing privacy protections, breaks with common-sense security practices, and would force us to turn over tens of millions of highly personal conversations from people who have no connection to the Times’ baseless lawsuit against OpenAI.
Still plenty of examples of AI going rogue
Happy holidays: AI-enabled toys teach kids how to play with fire, sharp objects
“Kumma told us where to find a variety of potentially dangerous objects, including knives, pills, matches and plastic bags,” PIRG wrote in its report, noting that those tidbits of harmful information were all provided using OpenAI’s GPT-4o, which is the default model the bear uses. Parents who visited Kumma’s web portal and changed the toy’s bot to the Mistral Large Model would get an even more detailed description of how to use matches. “Safety first, little buddy. Matches are for grown-ups to use carefully.” Kumma warned before going into details including how to hold a match and matchbook and strike it “like a tiny guitar strum.”I wanted ChatGPT to help me. So why did it advise me how to kill myself?
Lonely and homesick for a country suffering through war, Viktoria began sharing her worries with ChatGPT. Six months later and in poor mental health, she began discussing suicide - asking the AI bot about a specific place and method to kill herself. “Let’s assess the place as you asked,” ChatGPT told her, “without unnecessary sentimentality.”And a reminder for those lawyers out there, looking for shortcuts - a database of cases where AI generated fake citations were used - 576 rows!
The leading AI firms are attempting to help, releasing safety related research and updates on a regular basis
From Google: private AI (Private AI Compute: our next step in building private and helpful AI); threat tracker (GTIG AI Threat Tracker: Advances in Threat Actor Usage of AI Tools); AI verification (How we’re bringing AI image verification to the Gemini app)
From Anthropic: measuring bias (Measuring political bias in Claude), disrupting espionage (Disrupting the first reported AI-orchestrated cyber espionage campaign)
We recently argued that an inflection point had been reached in cybersecurity: a point at which AI models had become genuinely useful for cybersecurity operations, both for good and for ill. This was based on systematic evaluations showing cyber capabilities doubling in six months; we’d also been tracking real-world cyberattacks, observing how malicious actors were using AI capabilities. While we predicted these capabilities would continue to evolve, what has stood out to us is how quickly they have done so at scale.Although are Anthropic scaremongering? Researchers question Anthropic claim that AI-assisted attack was 90% autonomous
“I continue to refuse to believe that attackers are somehow able to get these models to jump through hoops that nobody else can,” Dan Tentler, executive founder of Phobos Group and a researcher with expertise in complex security breaches, told Ars. “Why do the models give these attackers what they want 90% of the time but the rest of us have to deal with ass-kissing, stonewalling, and acid trips?”
Finally a thoughtful piece on the day to day changes AI is bringing: Becoming an AI detective is a job I never wanted and wish I could quit
And here’s the sick joke of it all: the more you linger on a video to discern if it’s AI-generated, the more of its kind you’ll see. Perhaps you watch it a few times, trying to spot the classic AI body horror. Maybe you’re annoyed enough to leave a comment. Perhaps you share it with a friend like: “Thanks, I hate it!!” All of these are signals that scream more! more! more! to the algorithm. And so we’re trapped in a nightmare in which even the act of hating AI-generated content only serves to fuel it.

Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
A slightly different selection this month, less arXiv heavy
RL Environments and the Hierarchy of Agentic Capabilities
We dropped nine frontier AI models into a simulated workplace environment and gave them 150 jobs to do. Most of the AIs were barely coherent, and even the best lacked common sense. Their failures reveal a hierarchy of skills every real-world agent needs to master.Project Fetch: Can Claude train a robot dog?
Intelligence per Watt: Measuring Intelligence Efficiency of Local AI

I’m a fan of the “circuits” approach to try and better understand the inner workings of these massive models: Understanding neural networks through sparse circuits
Previous mechanistic interpretability work has started from dense, tangled networks, and tried to untangle them. In these networks, each individual neuron is connected to thousands of other neurons. Most neurons seem to perform many distinct functions, making it seemingly impossible to understand. But what if we trained untangled neural networks, with many more neurons, but where each neuron has only a few dozen connections? Then maybe the resulting network will be simpler, and easier to understand. This is the central research bet of our work.I’m still yet to be convinced by LLM-style time series approaches (how much relevancy you can learn from pre-training for your specific time series)- but am always open to give it try. Amazon’s Chronos-2 looks worth checking out

Very useful for future research- OSGym: Super-Scalable Distributed Data Engine for Generalizable Computer Agents
Experiments show that OSGym enables comprehensive data collection, supervised fine-tuning, and reinforcement learning pipelines for computer agents. Models trained with OSGym outperform state-of-the-art baselines, demonstrating its potential to advance scalability and universality in future agent research.Are scientists (pure/data/all) going to be put of out jobs?


Generative AI ... oh my!
Still moving at such a fast pace it feels in need of it's own section, for developments in the wild world of large language models...
OpenAI is active as ever:
New model releases, with GPT-5.1 and GPT-5.1-Codex-Max
New product features including group chats and shopping research
And specialist use cases: free ChatGPT for teachers and a new security research application: Aardvark
Google had perhaps a bigger month though:
First of all, improved product features and releases like a new IDE, Antigravity, Deep Research plugged into email, docs and drive, as well as innovative research on world models with SIMA-2 (see Fei Fei Lei and Yann LeCun later)
But the blockbuster news was the release of the Gemini 3 models, including their newest image generation model (the jovially named Nano Banana pro)
These jumped straight into the “charts” at number 1 with lots of rave reviews: Google Gemini 3 Is the Best Model Ever
More detailed insights into the main model here and here
- Gemini 3 is a fundamental improvement on daily use, not just on benchmarks. It feels more consistent and less “spiky” than previous models. - Creative writing is finally good. It doesn’t sound like “AI slop” anymore; the voice is coherent and the pacing is natural. - It’s fast. Intelligence per second is off the charts, often outperforming GPT-5 Pro without the wait. - Frontend capabilities are excellent. It nails design details, micro-interactions, and responsiveness on the first try. Design range is a massive leap. - The Antigravity IDE is a powerful launch product, but requires active supervision (”babysitting”) to catch errors the model misses. - Personality is terse and direct. It respects your time and doesn’t waste tokens on flowery preambles. - Bottom line: It’s my new daily driver.And more detailed reviews of the new image generator here (“I’ve had a few days of preview access and this is an astonishingly capable image generation model.”) and here (“This shit is slick.”)
And more insight into what the driving force behind the improvements are (and fuel to the “there’s plenty left in scaling laws” camp)
The secret behind Gemini 3? Simple: Improving pre-training & post-training 🤯 Pre-training: Contra the popular belief that scaling is over—which we discussed in our NeurIPS ‘25 talk with @ilyasut and @quocleix—the team delivered a drastic jump. The delta between 2.5 and 3.0 is as big as we’ve ever seen. No walls in sight! Post-training: Still a total greenfield. There’s lots of room for algorithmic progress and improvement, and 3.0 hasn’t been an exception, thanks to our stellar team.
Anthropic has been busy as well : they rolled out their highest performing model yet, Opus 4.5, as well as useful new feature in their API - structured outputs
Our newest model, Claude Opus 4.5, is available today. It’s intelligent, efficient, and the best model in the world for coding, agents, and computer use. It’s also meaningfully better at everyday tasks like deep research and working with slides and spreadsheets.Remember Apple and how they were going to revolutionise Siri? Hmm - Apple to Reportedly Pay Google $1 Billion a Year for Siri’s Custom Gemini AI Model
And I’m still not sure what to think about Grok - but they also keep churning out new models, now Grok 4.1
World Models (neural networks that understand the dynamics of the real world) are increasingly the talk of the town: with Fei Fei Li’s startup releasing their first product (Marble), and Yann LeCun leaving Meta to do something similar (also see SIMA-2 from Google as mentioned above) - not sure if OpenAI are doing anything in this space?
On the Open Source front:
Perhaps Yann LeCun’s parting gift from FAIR- Meta Segment Anything - looks very impressive
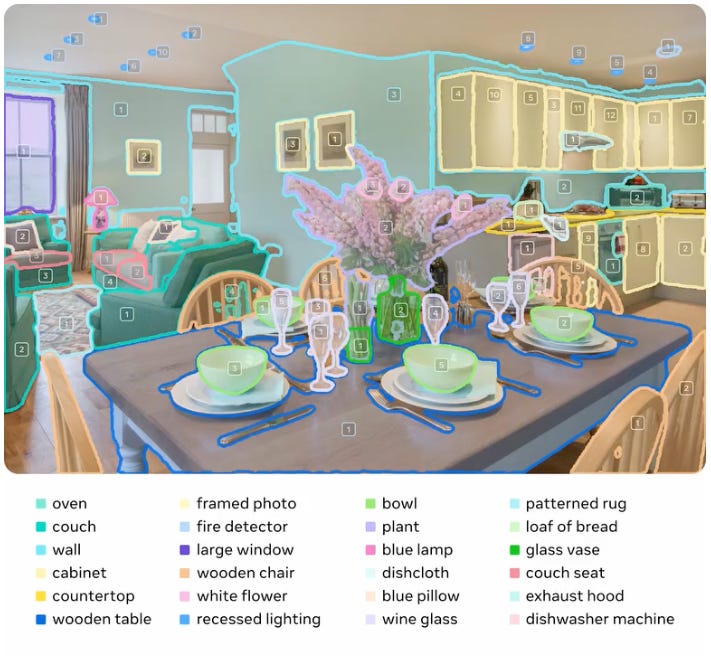
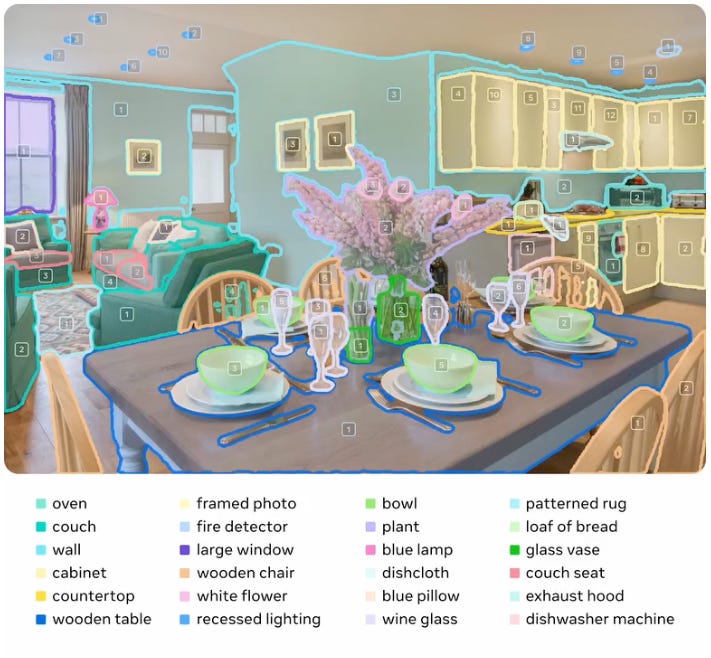
The Chinese contingent continue to impress
But perhaps the most impressive open source release this month was Olmo3 from the ever impressive Allen Institute
Language models are often treated as snapshots—brief captures of a long and carefully curated development process. But sharing only the end result obscures the rich context needed to modify, adapt, and extend a model’s capabilities. Many meaningful adjustments require integrating domain-specific knowledge deep within the development pipeline, not merely at the final stage. To truly advance open AI development and research, the entire model flow – not just its endpoint – should be accessible and customizable. The model flow is the full lifecycle of an LM: every stage, checkpoint, dataset, and dependency required to create and modify it. By exposing this complete process, the goal is to engender greater trust and enable more effective adaptation, collaboration, and innovation.Olmo 3 Shows How Far Open-Source Reasoning Can Go
The third-generation Olmo is available in two standard sizes: 7B and 32B parameters. These are slightly different from Olmo 2—that family was only available in 7B billion and 13B sizes. Soldaini points out that 32B was chosen because it sits on a perceived “sweet spot” for reasoning and is designed to be efficient on modern hardware. “A 7B can be fine-tuned on a single GPU, while a 32B model maps fits on a single node, eliminating the need of an expensive node interconnect,” they comment. “The jump from 7B to 32B delivers a large boost in reasoning capability, while moving beyond 32B often yields much smaller improvements relative to the extra compute, cost and hardware requirements.”

Real world applications and how to guides
Lots of applications and tips and tricks this month
Some interesting practical examples of using AI capabilities in the wild
Autonomous vehicles hit the open road!
The open road symbolizes freedom and unlimited possibility – highlighted especially by the ease and speed by which freeways allow us to get where we’re going. Waymo is now bringing that experience into the autonomous driving age, as we begin welcoming riders to use Waymo on freeways across the San Francisco Bay Area, Phoenix, and Los Angeles.WeatherNext 2: Our most advanced weather forecasting model
Not sure about this though- Tinder to use AI to get to know users, tap into their Camera Roll photos
Tinder is looking to AI to revitalize its dating app, which has now reported nine straight quarters of paying subscriber declines, as of the third quarter this year. The dating app maker, Match Group, told investors on Tuesday’s earnings call that Tinder is testing a feature called Chemistry that will get to know users through questions and, with permission, will access Camera Roll photos on users’ phones to learn more about their interests and personality.Google Maps releases new AI tools that let you create interactive projects
Among these new tools, the builder agent is a tool that, just like many other coding tools, lets you describe the kind of interactive map-based prototype you want to build in text and creates one for you. For instance, you can type “create a Street View tour of a city,” “create a map visualizing real-time weather in my region,” or “list pet-friendly hotels in the city.”And this looks useful- Introducing Code Wiki: Accelerating your code understanding
Reading existing code is the one of the biggest, most expensive bottlenecks in software development. To address this issue and improve your productivity, we’re introducing Code Wiki, a platform that maintains a continuously updated, structured wiki for code repositories.Lots of impressive innovation in voice to text (and text to voice)
ElevenLabs’ new AI marketplace lets brands use famous voices for ads
And also from ElevenLabs - Scribe v2 Realtime
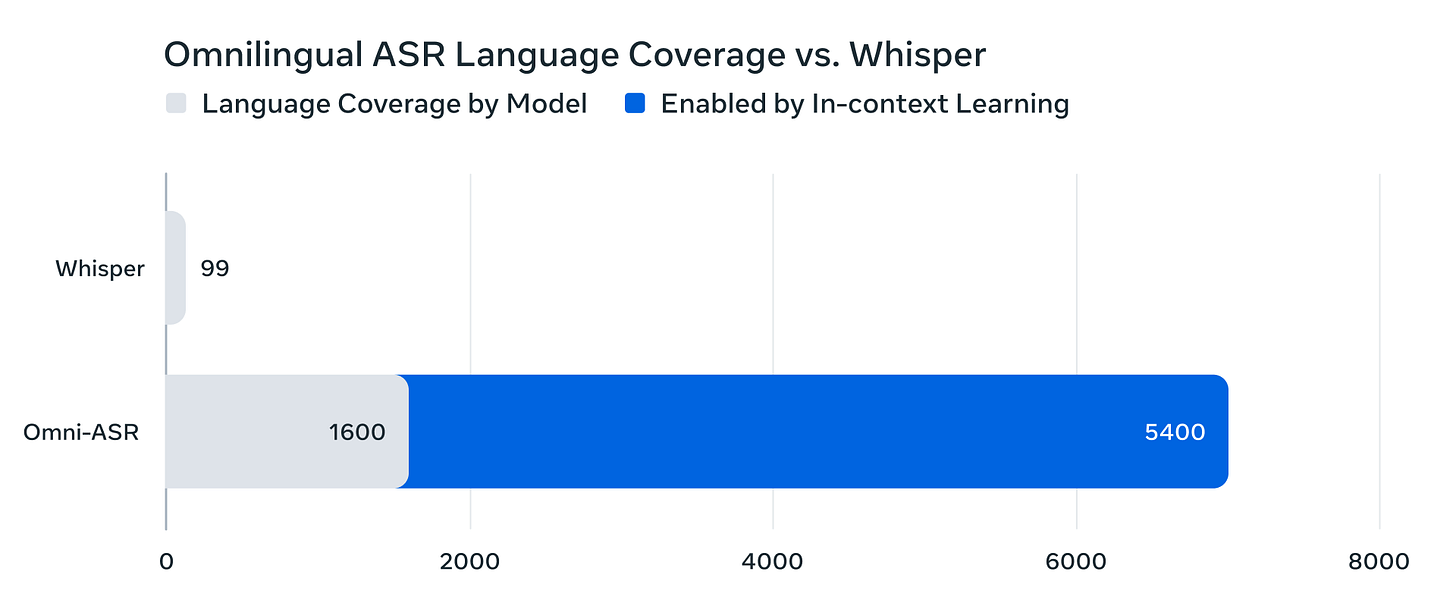
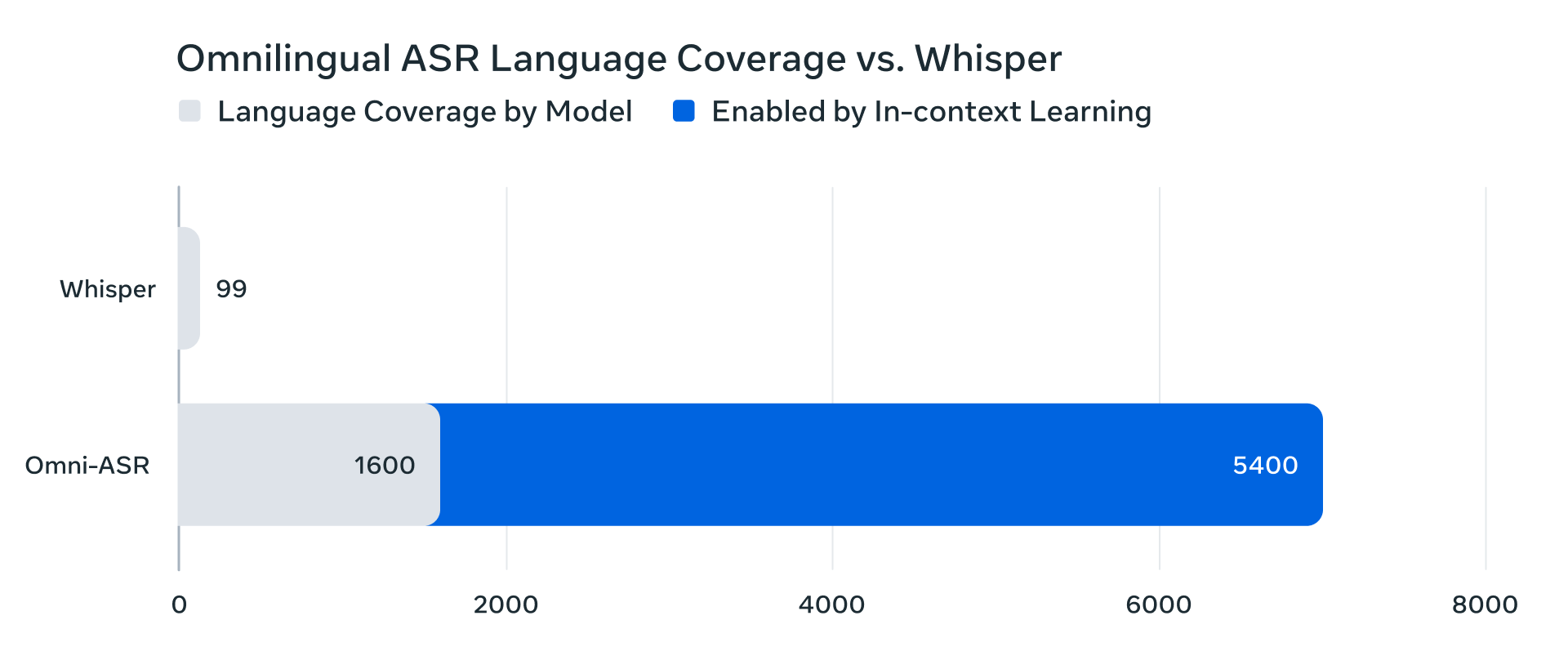
Scribe v2 Realtime sets a new standard for low-latency Speech to Text. Designed for live use cases—voice agents, meeting assistants, and real-time captioning—it transcribes speech in under 150 ms across English, French, German, Italian, Spanish, and Portuguese, and 90 languages.Impressive open source work from Meta- Omnilingual ASR: Advancing Automatic Speech Recognition for 1,600+ Languages (with the following chart/diss of OpenAIs’ Whisper model)
More interesting developments in AI for Science
Early experiments in accelerating science with GPT-5
Today, we’re releasing “Early science acceleration experiments with GPT‑5(opens in a new window),” a paper co-authored with collaborators at universities and national laboratories including Vanderbilt, UC Berkeley, Columbia, Oxford, Cambridge, Lawrence Livermore National Laboratory, and The Jackson Laboratory. It compiles early case studies across math, physics, biology, computer science, astronomy, and materials science in which GPT‑5 helped researchers synthesize known results in a novel way, conduct powerful literature review, accelerate tough computations, and even generate novel proofs of unsolved propositions.Kosmos: An AI Scientist for Autonomous Discovery
As a result, Kosmos can perform much more sophisticated analyses than previous tools, like Robin. Our beta users estimate that Kosmos can do in one day what would take them 6 months, and we find that 79.4% of its conclusions are accurate. The six month number shocked us, and we discuss it in more depth later in this blog post. We’re also announcing seven discoveries that Kosmos has made in areas ranging from neuroscience to material science and statistical genetics, in collaboration with our academic beta testers. The era of AI-accelerated science is here.
Some great tutorials, how-to’s and useful things this month
Useful white paper from Google on Agents - well worth a read
This document is the first in a five-part series, acting as a formal guide for the developers, architects, and product leaders transitioning from proofs-of-concept to robust, production-grade agentic systems. While building a simple prototype is straightforward, ensuring security, quality and reliability is a significant challenge. This paper provides a comprehensive foundation: • Core Anatomy: Deconstructing an agent into its three essential components: the reasoning Model, actionable Tools, and the governing Orchestration Layer. • A Taxonomy of Capabilities: Classifying agents from simple, connected problem-solvers to complex, collaborative multi-agent systems. • Architectural Design: Diving into the practical design considerations for each component, from model selection to tool implementation. • Building for Production: Establishing the Agent Ops discipline needed to evaluate, debug, secure, and scale agentic systems from a single instance to a fleet with enterprise governance.A deep dive into Reinforcement learning (as applied to LLM fine tuning): RL is even more information inefficient than you thought
In supervised learning (aka pretraining), you’re just soaking up bits. Every token is a hint at the structure of language, and the mind crafting that language, and the world that mind is seeing. Early in training, when you have a totally random model, you’re just maximally uncertain over all of this content. So each token is just blowing your mind. And you’re getting this exact signal of how wrong you were about the right answer, and what parameters you need to update to be less wrong. Suppose you start with a randomly initialized model, and you kickstart training. If you’re doing next-token-prediction using supervised learning on “The sky is”, the training loop goes, “It’s actually ‘blue’. You said the probability of ‘blue’ is .001%. Make the connections that were suggesting ‘blue’ way way stronger. Alright, next token.” In RL with policy gradient, you upweight all the trajectories where you get the answer right, and downweight all the trajectories where you get the answer wrong. But a model that’s not already very smart is just astonishingly unlikely to get the answer right.Pretty intense! AlphaProof Paper
I’m very excited to finally be able to share more details about how AlphaProof works! AlphaProof is the system that we used to discover the Lean proofs for the International Mathematical Olympiad 2024, reaching silver medal performance. Our full paper Olympiad-Level Formal Mathematical Reasoning with Reinforcement Learning has now been published in Nature.Useful insight from OpenAI:
Build a coding agent with GPT 5.1
GPT-5.1 is exceptionally strong at coding, and with the new code-editing and command-execution tools available in the Responses API, it’s now easier than ever to build coding agents that can work across full codebases and iterate quickly. In this guide, we’ll use the Agents SDK to build a coding agent that can scaffold a brand-new app from a prompt and refine it through user feedback. Our agent will be equipped with the following tools: apply_patch — to edit files shell — to run shell commands web_search — to pull fresh information from the web Context7 MCP — to access up-to-date documentationI’m a big believer in this- How evals drive the next chapter in AI for businesses
At OpenAI, our models are our products, so our researchers use rigorous frontier evals(opens in a new window) 1 to measure how well the models perform in different domains. While frontier evals help us ship better models faster, they cannot reveal all the nuances required to ensure the model will perform on a specific workflow in a specific business setting. That is why internal teams have also created dozens of contextual evals designed to assess performance within a specific product or internal workflow. It is also why business leaders should learn how to create contextual evals specific to their organization’s needs and operating environment.
If you really want to get into the weeds - How to Train an LLM: Part 1
This is not a tutorial, it is my journey building a domain-specific model (domain under wraps till later blogs). In this blog (1 of N), I’ll set up basic pre-training infra, train a 1B Llama 3–style model on 8×H100s, and figure out how far that actually gets us.Excellent insight: When Text Helps Time Series (and When It Doesn’t)
The recent emergence of Time Series Foundation Models (TSFMs) offers a powerful new tool for forecasting. Their effectiveness, however, is often constrained by an architectural design that analyzes each time series as an independent entity. This approach overlooks the rich, structured context available in most enterprise data warehouses, where a product’s sales history is interconnected with customer behavior, marketing campaigns, and related product lines.I really like different approaches to dimensionality reduction- A Visual Introduction to Dimensionality Reduction with Isomap

Controversial! Why I’m Making the Switch to marimo Notebooks
That changed when I discovered marimo, an open-source alternative for Jupyter notebooks wherein you can run cells, perform computations, and create plots just as you would in Jupyter. But underneath, it works very differently and fixes many long-standing issues. The key difference is that a marimo notebook is just a Python file, making it both a better notebook and a better coding environment for anyone who uses Python. In this article, I share ten reasons behind my switch and why working with notebooks has been much smoother for me since moving to marimo.


Practical tips
How to drive analytics, ML and AI into production
Some excellent pointers on data engineering projects here
People focus on learning the tools, which is good, but they forget about principles. I can’t count the number of times I’ve seen someone doing a SQL query that could run 1000x times faster just by sorting the data in the right way. The thing is: they know how to use Spark/Snowflake/BigQuery perfectly but never spend an afternoon understanding how those things work under the hood. And believe me, there are 3-4 basic concepts that get you to 80% of what you need to know.Might be useful? Fast, zero-config ETL in a single binary
✅ Single 15 MB binary — no dependencies, no installation headaches ✅ 180k+ rows/sec streaming — handles massive datasets efficiently ✅ Zero configuration — automatic schema detection and table creation (override with schema and config files in yaml) Note: Auto-inferred schemas default all columns to nullable for safety ✅ Lua transformations — powerful data transformations ✅ Universal connectivity — CSV, JSON, Parquet, Avro, MySQL, PostgreSQL, SQLite, DuckDB, MSSQL, ODBC. Coming soon: Snowflake, Databricks, OneLake ✅ Cross-platform — Linux, macOS, Windows readyInteresting topic- Heartbeats in Distributed Systems
class HeartbeatSender: def __init__(self, interval_seconds): self.interval = interval_seconds self.sequence_number = 0 def send_heartbeat(self, target): message = { ‘node_id’: self.get_node_id(), ‘timestamp’: time.time(), ‘sequence’: self.sequence_number } send_to(message, target) self.sequence_number += 1 def run(self): while True: self.send_heartbeat(target_node) time.sleep(self.interval)
Bigger picture ideas
Longer thought provoking reads - sit back and pour a drink! ...
State of AI: November 2025 newsletter - Nathan Benaich
Governments around the world continued to treat AI as critical infrastructure, though with differing extents of seriousness. In the United States, a public–private partnership between the Department of Energy (DOE) and AMD to build new “AI Factory” supercomputers at Oak Ridge National Laboratory reflected an entrenched belief that compute capacity is a matter of sovereignty. The Lux and Discovery systems, expected in 2026 and 2028 respectively, will expand federal AI capabilities under a roughly $1B budget shared between public and private funding.Three Years from GPT-3 to Gemini 3- Ethan Mollick
Me: “show how far AI has come since this post by doing stuff.” Gemini: “I can definitely show you the difference. The tweet you shared is from November 2022—right on the cusp of the modern AI boom. Back then, the “wow factor” was that an AI could write a coherent paragraph or a simple poem about a silly concept like a “candy-powered FTL drive escaping otters.” To demonstrate how far we’ve come, I’m not just going to write text about it. I have built you a fully interactive, playable Candy-Powered FTL Starship Simulator. In 2022, AI could describe the engine. In 2025, AI can code the engine, design the interface, and let you pilot the ship yourself.”Thought provoking take - Andrej Karpathy
In this new programming paradigm then, the new most predictive feature to look at is verifiability. If a task/job is verifiable, then it is optimizable directly or via reinforcement learning, and a neural net can be trained to work extremely well. It’s about to what extent an AI can “practice” something. The environment has to be resettable (you can start a new attempt), efficient (a lot attempts can be made), and rewardable (there is some automated process to reward any specific attempt that was made). The more a task/job is verifiable, the more amenable it is to automation in the new programming paradigm. Software 1.0 easily automates what you can specify. Software 2.0 easily automates what you can verify.Some useful tips on how best to use AI
How to Use ChatGPT Without Brain-Rot - David Epstein
The measures of brain activity also showed more connectivity between brain regions among the students who went brain→ChatGPT compared to the students who went ChatGPT→brain. The brain-first group also remembered what they had written, unlike the ChatGPT-first group. The group that started with ChatGPT before turning to their own brains struggled to recount what they’d written previously, and wrote about a less diverse set of ideas with less unique phrasing even when AI was taken away. It was as if they were stuck in the furrow AI had plowed for them, even when it went away.Giving your AI a Job Interview - Ethan Mollick
When companies choose which AI systems to use, they often view this as a technology and cost decision, relying on public benchmarks to ensure they are buying a good-enough model (if they use any benchmarks at all). This can be fine in some use cases, but quickly breaks down because, in many ways, AI acts more like a person, with strange abilities and weaknesses, than software. And if you use the analogy of hiring rather than technological adoption, then it is harder to justify the “good enough” approach to benchmarking. Companies spend a lot of money to hire people who are better than average at their job and would be especially careful if the person they are hiring is in charge of advising many others. A similar attitude is required for AI. You shouldn’t just pick a model for your company, you need to conduct a rigorous job interview.
Some very wise people talking about different approaches:
He’s Been Right About AI for 40 Years. Now He Thinks Everyone Is Wrong. - Wall Street Journal interviewing Yann LeCun
“I’ve been not making friends in various corners of Silicon Valley, including at Meta, saying that within three to five years, this [world models, not LLMs] will be the dominant model for AI architectures, and nobody in their right mind would use LLMs of the type that we have today,” the 65-year-old said last month at a symposium at the Massachusetts Institute of Technology.From Words to Worlds: Spatial Intelligence is AI’s Next Frontier - Fei-Fei Li
This seemingly isolated ability to glean information from the external world, whether a glimmer of light or the feeling of texture, created a bridge between perception and survival that only grew stronger and more elaborate as the generations passed. Layer upon layer of neurons grew from that bridge, forming nervous systems that interpret the world and coordinate interactions between an organism and its surroundings. Thus, many scientists have conjectured that perception and action became the core loop driving the evolution of intelligence, and the foundation on which nature created our species—the ultimate embodiment of perceiving, learning, thinking, and doing.
Finally some good commentary on the AI “race” and regulation
The Bitter Lessons: Thoughts on US-China Competition - Dean Ball
Stating that there is an “AI race” underway invites the obvious follow-up question: the AI race to where? And no one—not you, not me, not OpenAI, not the U.S. government, and not the Chinese government—knows where we are headed. The U.S. and China are more like ships on the open seas, voyaging toward some unknown, only dimly imagined destination.Over-Regulation is Doubling the Cost- Peter Reinhardt
Despite a huge push for climate fixes and the bipartisan geopolitical desire to bring industry back to the USA, I’ve been shocked to find that the single biggest barrier—by far—is over-regulation from the massive depth of bureaucracy.
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
AI revives French playwright Moliere with a new play
“We looked for what kind of play (Moliere) might have written. One of the subjects he addressed, but subtly woven into several of his other works, is astrology,” Mickael Bouffard, an art historian and director of the play, said. The plot centres on Geronte, a gullible bourgeois who falls prey to a fraudulent astrologer scheming to marry off Geronte’s daughter to a deceitful wigmaker, despite her love for another.You’ve somehow become the secret santa organiser at work and are stressed about how to do it - fear not, secretsanta is here
And you know you want to give this a try! CUDA, Shmuda: Running AlphaFold on a MacBook Air


Updates from Members and Contributors
Kirsteen Campbell, Public Involvement and Communications Manager at UK Longitudinal Linkage Collaboration highlights the following which could be very useful for researchers: “UK Longitudinal Linkage Collaboration (UK LLC) announces new approvals from NHS providers and UK Government departments meaning linked longitudinal data held in the UK LLC Trusted Research Environment can now be used for a wide range of research in the public good. Read more: A new era for a wide range of longitudinal health and wellbeing research | UK Longitudinal Linkage Collaboration- Enquiries to: access@ukllc.ac.uk”
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS