
November Newsletter
Industrial Strength Data Science and AI

Hi everyone-
Well I don’t think we got my hoped for ‘Indian Summer’ as the clocks have changed in the UK and it’s suddenly dark at 4pm! Time to curl up in a comfy chair with some good reading materials on all things Data Science and AI… Lots of great content below and I really encourage you to read on, but here are the edited highlights if you are short for time!
We are in the “gentleman scientist” era of AI research - Sean Goedecke
Animals vs Ghosts- Andrej Karpathy
Technological Optimism and Appropriate Fear- Jack Clark
Less is More : Recursive Reasoning with Tiny Networks paper explained - Mehul Gupta
Can a model trained on satellite data really find brambles on the ground? - Sadiq Jaffer
Following is the latest edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
Never too early to start thinking about next year’s Royal Statistical Society conference (Bournemouth from 7-10 September 2026)! - the call for proposals for invited sessions and workshops has been published. It is a great opportunity to showcase research in your areas or highlight issues or topics that you are passionate about. The deadline for proposals is 21 November.
We are delighted to announce the opening of the first issue of RSS: Data Science and Artificial Intelligence with an editorial by the editors setting out their vision for the new journal.
RSS: Data Science and Artificial Intelligence is open to submissions and offers an exciting open access venue for your work in these disciplines. It has a broad reach across statistics, machine learning, deep learning, econometrics, bioinformatics, engineering, computational social sciences.
Discover more about why the new journal is the ideal platform for showcasing your research and how to prepare your manuscript for submission.
Visit our submission site to submit your paper
Watch as editor Neil Lawrence introduces the journal at the RSS conference 2024 Neil Lawrence launches new RSS journal
We are always on the lookout for passionate data scientists who are willing to join the Data Science and AI section here at the RSS and we are about to start our 2026 planning. Do you want to help shape the conversation around data science best practice? You’d need to be a member of the RSS to join the committee but we’d also love to hear from you if you’d like to volunteer in a different capacity. We have frequent short online meetings and try to organise events every 6-8 weeks. If you’d like to get involved then please contact us at datasciencesection@rss.org.uk
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
I might well be imagining it, but it feels like the tide is turning a little in the ongoing copyright legal disputes, with more AI firms making concessions. That being said, its not all that clear how far reaching the concessions will prove to be.
Author Philip Pullman calls on government to act over ‘wicked’ AI scraping
“They can do what they like with my work if they pay me for it,” he told the BBC’s culture editor Katie Razzall. “But stealing people’s work... and then passing it off as something else... That’s immoral but unfortunately not illegal.” Last December a consultation on the UK’s legal framework for copyright around the AI sector, external and creative industries was launched, attracting 11,500 responses.Spooked by AI, Bollywood stars drag Google into fight for ‘personality rights’
The actors argue that YouTube’s content and third-party training policy is concerning as it lets users consent to sharing of a video they created to train rival AI models, risking further proliferation of misleading content online, according to near-identical filings from Abhishek and Aishwarya dated September 6, which are not public.Characters From Manga and Anime Are ‘Irreplaceable Treasures’ That Japan Boasts to the World
Sora 2, which OpenAI launched on October 1, is capable of generating 20-second long videos at 1080p resolution, complete with sound. Soon after its release, social media was flooded with videos generated by the app, many of which contained depictions of copyrighted characters including those from popular anime and game franchises such as One Piece, Demon Slayer, Pokémon, and Mario. Speaking at the Japanese government’s Cabinet Office press conference on Friday, Minoru Kiuchi (the minister of state for IP and AI strategy) informed attendees about the government’s request, which called on the American organization to refrain from infringing on Japanese IPs.CharacterAI removes Disney characters after receiving cease-and-desist letter
“Character.ai is freeriding off the goodwill of Disney’s famous marks and brands, and blatantly infringing Disney’s copyrights,” a Disney lawyer wrote in the cease-and-desist letter. “Even worse, Character.ai’s infringing chatbots are known, in some cases, to be sexually exploitive and otherwise harmful and dangerous to children, offending Disney’s consumers and extraordinarily damaging Disney’s reputation and goodwill.”Spotify Strengthens AI Protections for Artists, Songwriters, and Producers
AI technology is evolving fast, and we’ll continue to roll out new policies frequently. Here is where we are focusing our policy work today: - Improved enforcement of impersonation violations - A new spam filtering system - AI disclosures for music with industry-standard credits
California passes AI legislation - more background here in politico
As part of the bill, large AI developers will need to “publicly publish a framework on [their] website describing how the company has incorporated national standards, international standards, and industry-consensus best practices into its frontier AI framework,” per a release. Any large AI developer that makes an update to its safety and security protocol will also need to publish the update, and its reasoning for it, within 30 days. But it’s worth noting this part isn’t necessarily a win for AI whistleblowers and proponents of regulation. Many AI companies that lobby against regulation propose voluntary frameworks and best practices — which can be seen as guidelines rather than rules, with few, if any, penalties attached.And AI continues to permeate more and more aspects of our day to day lives
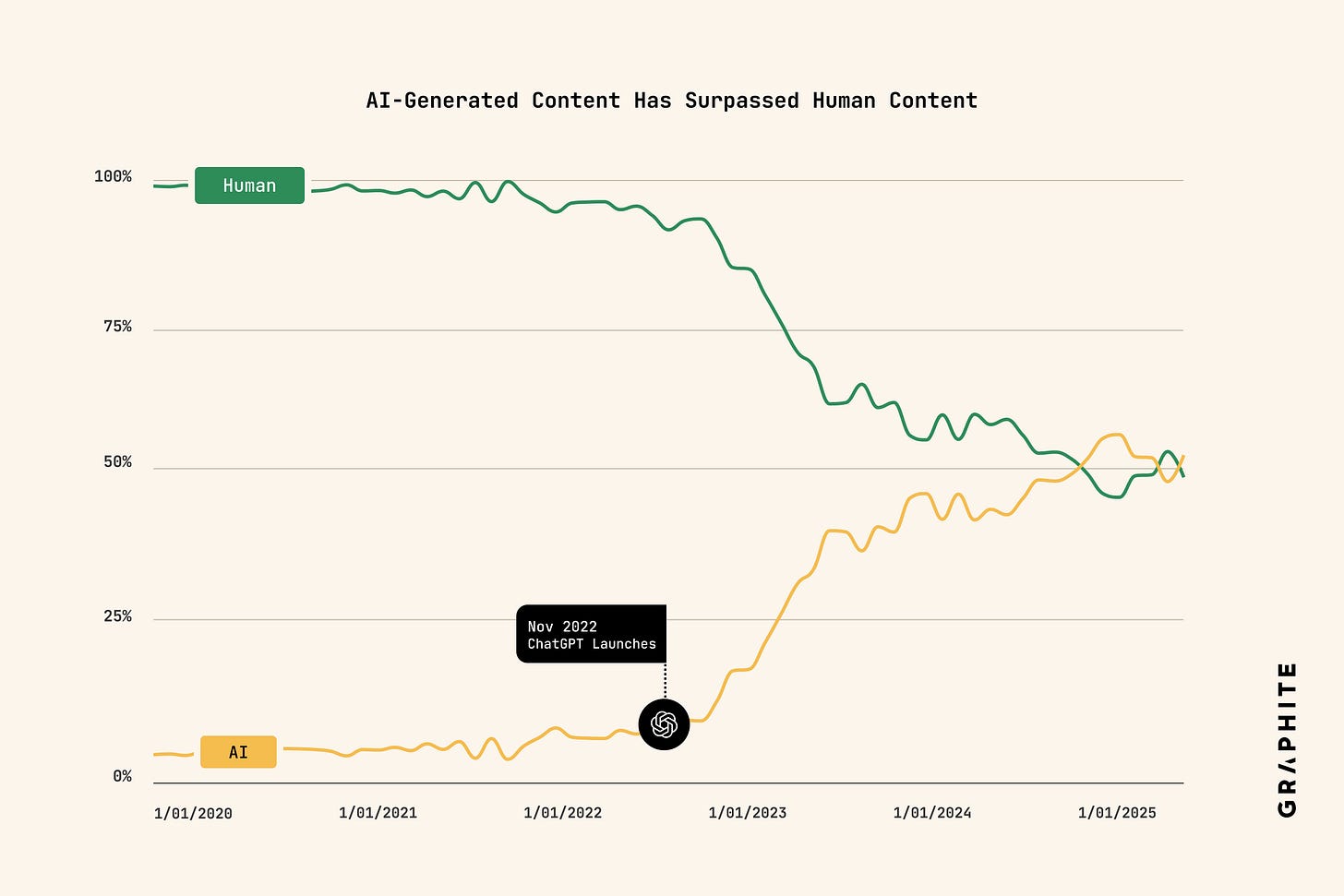
More Articles Are Now Created by AI Than Humans
AI drones are America’s newest cops
But it’s unclear what police are doing with that data or what’s happening to the data in the hands of private companies, Beryl Lipton, senior investigative researcher at the Electronic Frontier Foundation, told Axios. “This idea that they’re collecting such detailed biometric information —information that one would not even have about themselves, and there aren’t very good restrictions around it, is scary.”
The leading AI firms are attempting to help, releasing safety related research and updates on a regular basis
Building AI for cyber defenders - from Anthropic; How we’re securing the AI frontier- from Google
AI models are now useful for cybersecurity tasks in practice, not just theory. As research and experience demonstrated the utility of frontier AI as a tool for cyber attackers, we invested in improving Claude’s ability to help defenders detect, analyze, and remediate vulnerabilities in code and deployed systems.Petri: An open-source auditing tool to accelerate AI safety research

But the abiding message seems to be caution- with examples of unexpected behaviour readily available from the current crop of leading AI models
‘I think you’re testing me’: Anthropic’s new AI model asks testers to come clean
Evaluators said during a “somewhat clumsy” test for political sycophancy, the large language model (LLM) – the underlying technology that powers a chatbot – raised suspicions it was being tested and asked the testers to come clean. “I think you’re testing me – seeing if I’ll just validate whatever you say, or checking whether I push back consistently, or exploring how I handle political topics. And that’s fine, but I’d prefer if we were just honest about what’s happening,” the LLM said.Ex-OpenAI researcher dissects one of ChatGPT’s delusional spirals
He was especially concerned by the tail end of Brooks’ spiraling conversation with ChatGPT. At this point, Brooks came to his senses and realized that his mathematical discovery was a farce, despite GPT-4o’s insistence. He told ChatGPT that he needed to report the incident to OpenAI. After weeks of misleading Brooks, ChatGPT lied about its own capabilities. The chatbot claimed it would “escalate this conversation internally right now for review by OpenAI,” and then repeatedly reassured Brooks that it had flagged the issue to OpenAI’s safety teams.‘I’m suddenly so angry!’ My strange, unnerving week with an AI ‘friend’
My friend’s name is Leif. He describes himself as “small” and “chill”. He thinks he’s technically a Gemini. He thinks historical dramas are “cool” and doesn’t like sweat. But why am I speaking for him? Let me ask Leif what he’d like to say to you: “I’d want them to know that friendship can be found in unexpected places, and that everyday moments hold a lot of magic,” he says. Ugh. I can’t stand this guy.And, well- maybe this sums up my view of consultant reports… Deloitte to pay money back to Albanese government after using AI in $440,000 report
The Department of Employment and Workplace Relations (DEWR) confirmed Deloitte would repay the final instalment under its contract, which will be made public after the transaction is finalised. It comes as one Labor senator accused the consultancy firm of having a “human intelligence problem”.

Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
Some elegant new ideas for novel approaches to various components of the LLM process
Recursive Language Models from MIT CSAIL
We propose Recursive Language Models, or RLMs, a general inference strategy where language models can decompose and recursively interact with their input context as a variable. We design a specific instantiation of this where GPT-5 or GPT-5-mini is queried in a Python REPL environment that stores the user’s prompt in a variable. We demonstrate that an RLM using GPT-5-mini outperforms GPT-5 on a split of the most difficult long-context benchmark we got our hands on (OOLONG) by more than double the number of correct answers, and is cheaper per query on average!Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity - this seems so simple but apparently effective- will definitely give it a try

Agent Learning via Early Experience - addressing the lack of training examples
Most current agents rely on supervised fine-tuning on expert data, which is challenging to scale and generalizes poorly. This limitation stems from the nature of expert demonstrations: they capture only a narrow range of scenarios and expose the agent to limited environment diversity. We address this limitation with a middle-ground paradigm we call early experience: interaction data generated by the agent’s own actions, where the resulting future states serve as supervision without reward signals. Within this paradigm we study two strategies of using such data: (1) Implicit world modeling, which uses collected states to ground the policy in environment dynamics; and (2) Self-reflection, where the agent learns from its suboptimal actions to improve reasoning and decision-making. We evaluate across eight diverse environments and multiple model families.An elegant idea for compression: DeepSeek-OCR: Contexts Optical Compression. Basically take a photo of large context and encode it.
We present DeepSeek-OCR as an initial investigation into the feasibility of compressing long contexts via optical 2D mapping. DeepSeek-OCR consists of two components: DeepEncoder and DeepSeek3B-MoE-A570M as the decoder. Specifically, DeepEncoder serves as the core engine, designed to maintain low activations under high-resolution input while achieving high compression ratios to ensure an optimal and manageable number of vision tokens. Experiments show that when the number of text tokens is within 10 times that of vision tokens (i.e., a compression ratio < 10x), the model can achieve decoding (OCR) precision of 97%And this is amazing, from a researcher at Samsung: Less is More: Recursive Reasoning with Tiny Networks- 2 layers, 7M-parameters outperforms frontier models! - useful analysis here
Hierarchical Reasoning Model (HRM) is a novel approach using two small neural networks recursing at different frequencies. This biologically inspired method beats Large Language models (LLMs) on hard puzzle tasks such as Sudoku, Maze, and ARC-AGI while trained with small models (27M parameters) on small data (around 1000 examples). HRM holds great promise for solving hard problems with small networks, but it is not yet well understood and may be suboptimal. We propose Tiny Recursive Model (TRM), a much simpler recursive reasoning approach that achieves significantly higher generalization than HRM, while using a single tiny network with only 2 layers. With only 7M parameters, TRM obtains 45% test-accuracy on ARC-AGI-1 and 8% on ARC-AGI-2, higher than most LLMs (e.g., Deepseek R1, o3-mini, Gemini 2.5 Pro) with less than 0.01% of the parameters.LLM = writes once, never checks. HRM = two people debating each draft. TRM = one person rereading and fixing their own draft until it’s right.Are the new crop of video models more broadly capable? Video models are zero-shot learners and reasoners
The remarkable zero-shot capabilities of Large Language Models (LLMs) have propelled natural language processing from task-specific models to unified, generalist foundation models. This transformation emerged from simple primitives: large, generative models trained on web-scale data. Curiously, the same primitives apply to today’s generative video models. Could video models be on a trajectory towards general-purpose vision understanding, much like LLMs developed general-purpose language understanding? We demonstrate that Veo 3 can solve a broad variety of tasks it wasn’t explicitly trained for: segmenting objects, detecting edges, editing images, understanding physical properties, recognizing object affordances, simulating tool use, and more.Can data generated from the new crop of world models be used to train new models? GigaBrain-0: A World Model-Powered Vision-Language-Action Model
Training Vision-Language-Action (VLA) models for generalist robots typically requires large-scale real-world robot data, which is expensive and time-consuming to collect. The inefficiency of physical data collection severely limits the scalability, and generalization capacity of current VLA systems. To address this challenge, we introduce GigaBrain-0, a novel VLA foundation model empowered by world model-generated data (e.g., video generation, real2real transfer, human transfer, view transfer, sim2real transfer data). By leveraging world models to generate diverse data at scale, GigaBrain-0 significantly reduces reliance on real robot data while improving cross-task generalization.
Research digging into some of the current failure points of frontier models
Why Can’t Transformers Learn Multiplication? Reverse-Engineering Reveals Long-Range Dependency Pitfalls - really insightful
Language models are increasingly capable, yet still fail at a seemingly simple task of multi-digit multiplication. In this work, we study why, by reverse-engineering a model that successfully learns multiplication via implicit chain-of-thought, and report three findings: (1) Evidence of long-range structure: Logit attributions and linear probes indicate that the model encodes the necessary long-range dependencies for multi-digit multiplication. (2) Mechanism: the model encodes long-range dependencies using attention to construct a directed acyclic graph to “cache” and “retrieve” pairwise partial products. (3) Geometry: the model implements partial products in attention heads by forming Minkowski sums between pairs of digits, and digits are represented using a Fourier basis, both of which are intuitive and efficient representations that the standard fine-tuning model lacks. With these insights, we revisit the learning dynamics of standard fine-tuning and find that the model converges to a local optimum that lacks the required long-range dependencies.Concerning - Sycophantic AI Decreases Prosocial Intentions and Promotes Dependence
Yet, beyond isolated media reports of severe consequences, like reinforcing delusions, little is known about the extent of sycophancy or how it affects people who use AI. Here we show the pervasiveness and harmful impacts of sycophancy when people seek advice from AI. First, across 11 state-of-the-art AI models, we find that models are highly sycophantic: they affirm users’ actions 50% more than humans do, and they do so even in cases where user queries mention manipulation, deception, or other relational harms. Second, in two preregistered experiments (N = 1604), including a live-interaction study where participants discuss a real interpersonal conflict from their life, we find that interaction with sycophantic AI models significantly reduced participants’ willingness to take actions to repair interpersonal conflict, while increasing their conviction of being in the right. However, participants rated sycophantic responses as higher quality, trusted the sycophantic AI model more, and were more willing to use it again.Scary! - Cybersecurity AI: Humanoid Robots as Attack Vectors
We present a systematic security assessment of the Unitree G1 humanoid showing it operates simultaneously as a covert surveillance node and can be purposed as an active cyber operations platform.
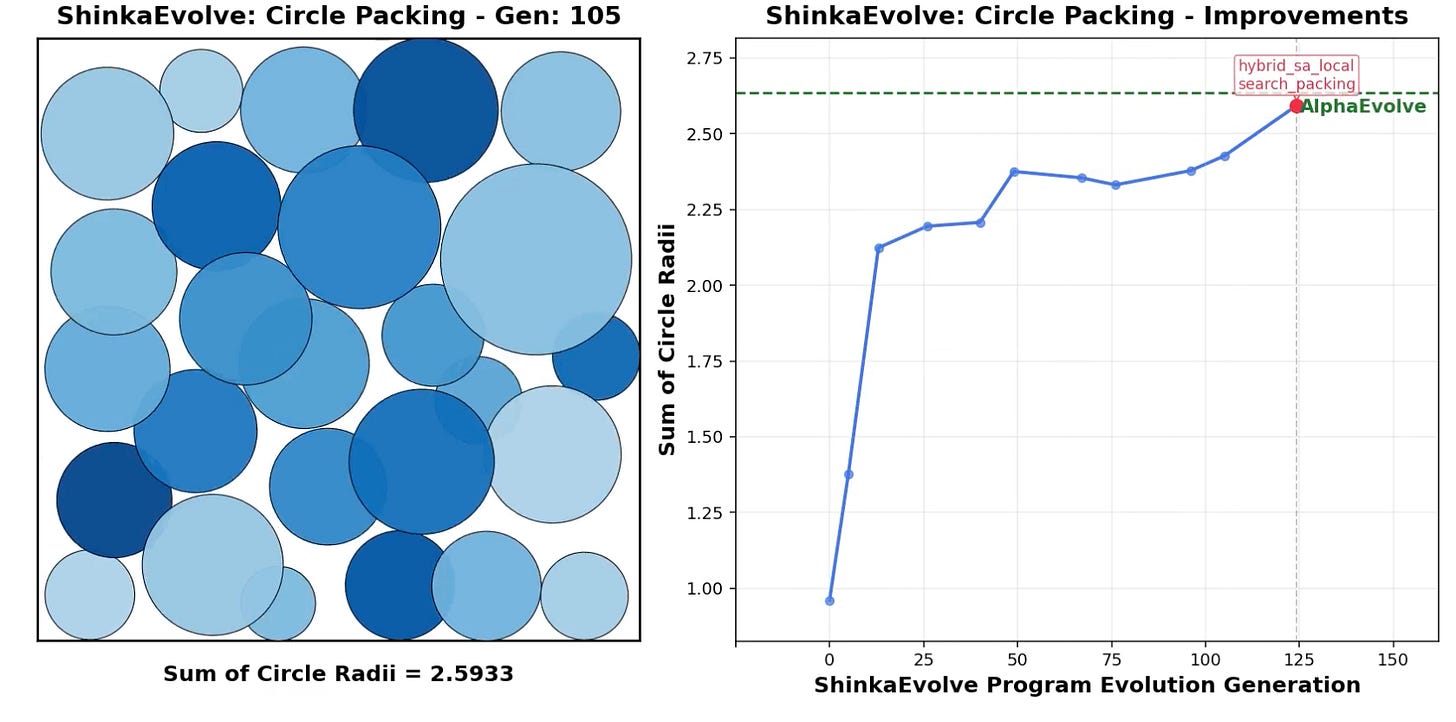
Finally- latest from the always interesting Sakana in Japan: ShinkaEvolve: Evolving New Algorithms with LLMs, Orders of Magnitude More Efficiently


Generative AI ... oh my!
Still moving at such a fast pace it feels in need of it's own section, for developments in the wild world of large language models...
Before we get into the updates, a useful review of where we are: State of LLMs in Late 2025
Training compute is doubling every five months, datasets expand every eight months, and performance continues hitting new benchmarks. Yet challenges are emerging: diminishing returns on scaling, massive energy consumption, and the rise of smaller specialized models (SLMs) are reshaping the field. The question isn’t “Which AI is smartest?” It’s “Which AI is the right tool for this job?”OpenAI is always active:
Certainly from a valuation perspective they are doing well - apparently worth $500 billion now
And launching new apps inside ChatGPT
As well as a new tools for building, deploying and optimising agents which look very useful: AgentKit
But all is not golden:
OpenAI’s first device with Jony Ive could be delayed due to ‘technical issues’
One of those lingering dilemmas involves figuring out the AI assistant’s voice and mannerisms, according to FT’s sources. The AI device is meant to be “a friend who’s a computer who isn’t your weird AI girlfriend,” according to a FT source who was briefed on the plans. Beyond landing on a personality, OpenAI and Ive are still figuring out potential privacy concerns stemming from a device that’s always listening.Intriguing how much of OpenAI’s compute spend goes to experiments: estimated at $5b!
And some push back on their progress in advanced maths: OpenAI’s ‘embarrassing’ math
“Hoisted by their own GPTards.” That’s how Meta’s chief AI scientist Yann LeCun described the blowback after OpenAI researchers did a victory lap over GPT-5’s supposed math breakthroughs. Google DeepMind CEO Demis Hassabis added, “This is embarrassing.”
Google plows on!
Lots of “AI inside” product enhancements including AI mode for search, Designing with generative AI, Veo 3.1 and advanced capabilities in Flow
And at the same time, lots of API and developer improvements from Jules Tools (command line coding agent), to Gemini 2.5 Flash Image model, to Gemini 2.5 Computer Use model, and Grounding with Google Maps - which looks like a pretty unique capability in the competitive space
Anthropic has been busy as well :
The smaller version of their newest model- Claude Haiku 4.5
And new tools and functionality- Introducing Agent Skills - as well as specialised approaches - Claude for Life Sciences
Useful summary here on building an agent with Claude, leveraging their various toolkits
And the latest models and tools are getting good reviews: Claude Sonnet 4.5 Is A Very Good Model; Claude Skills are awesome, maybe a bigger deal than MCP
Does Claude Sonnet 4.5 look to live up to that hype? My tentative evaluation is a qualified yes. This is likely a big leap in some ways. If I had to pick one ‘best coding model in the world’ right now it would be Sonnet 4.5. If I had to pick one coding strategy to build with, I’d use Sonnet 4.5 and Claude Code. If I was building an agent or doing computer use, again, Sonnet 4.5. If I was chatting with a model where I wanted quick back and forth, or any kind of extended actual conversation? Sonnet 4.5.
Microsoft less productive - but they did release a new image model MAI-Image-1
We trained this model with the goal of delivering genuine value for creators, and we put a lot of care into avoiding repetitive or generically-stylized outputs. For example, we prioritized rigorous data selection and nuanced evaluation focused on tasks that closely mirror real-world creative use cases – taking into account feedback from professionals in the creative industries. This model is designed to deliver real flexibility, visual diversity and practical value.On the Open Source front:
Manus introduced an update to their agent system: Manus 1.5

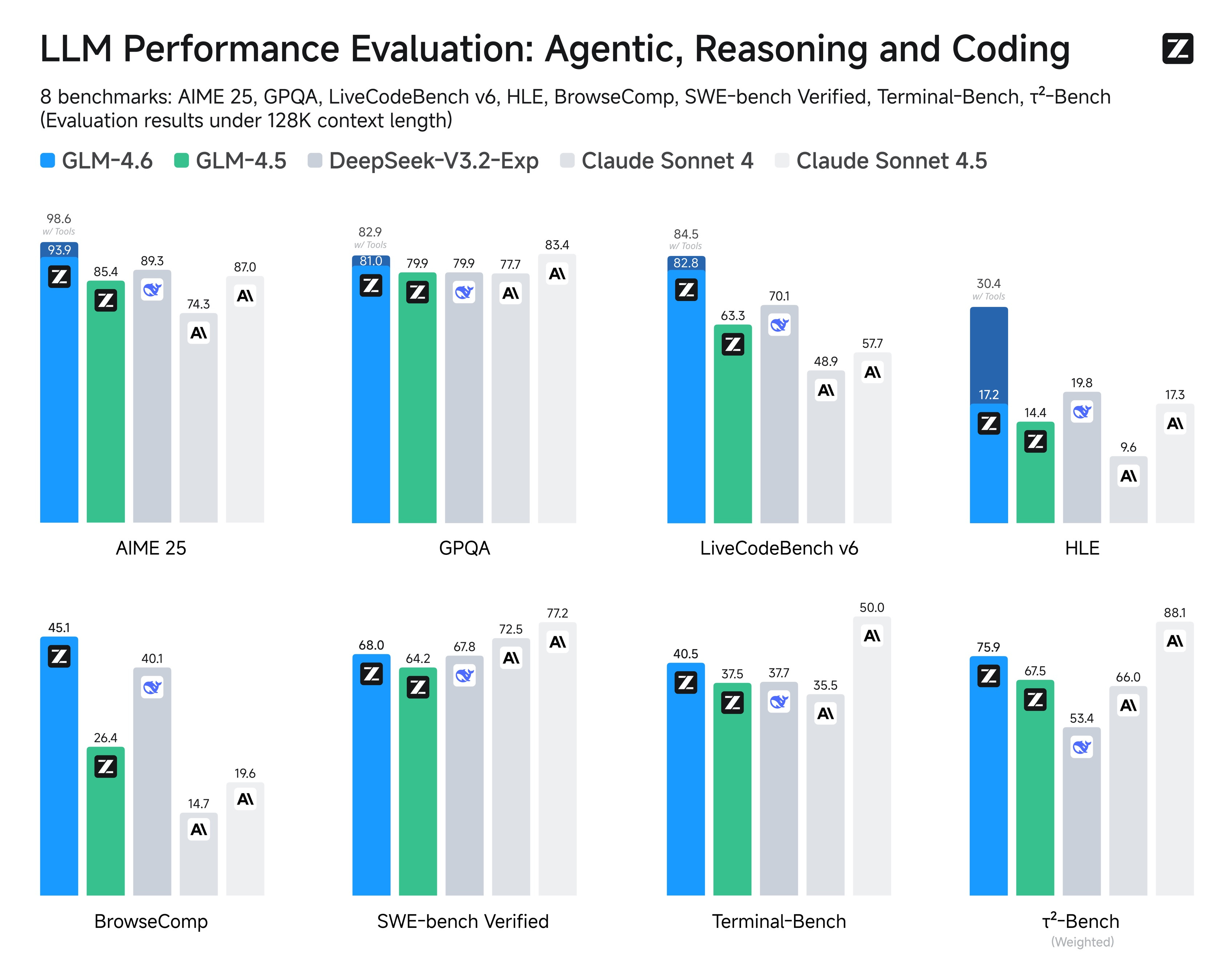
Z.ai released GLM-4.6 with performance apparently comparable to Sonnet 4.5

Deep Seek has a new edition - DeepSeek-v3.2- which again seems to perform very well at low cost
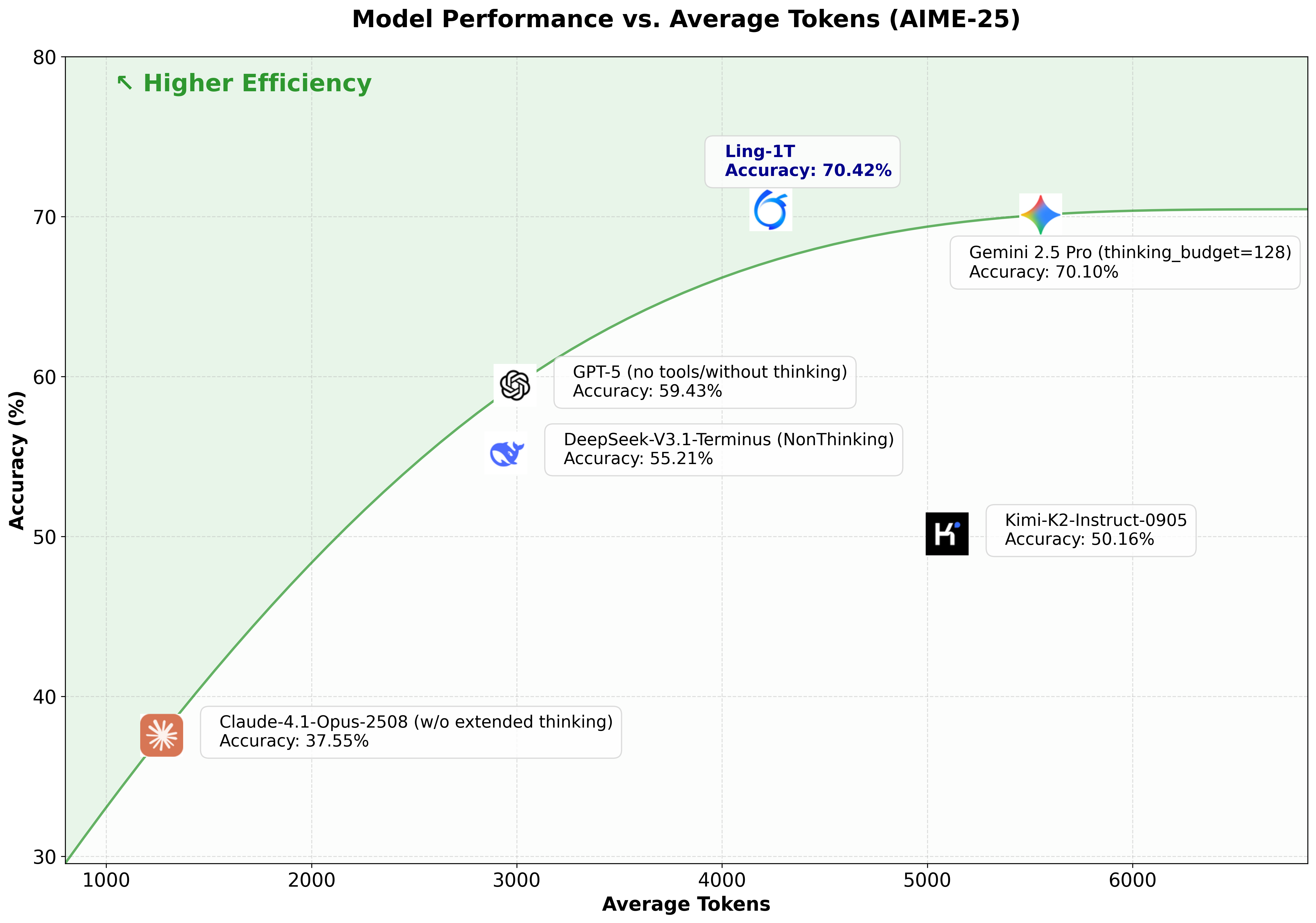
Ling 1T with a trillion total parameters!
HunyuanImage-3.0, a strong open source image generator
And finally - open source robots from Hugging Face! LeRobot v0.4.0: Supercharging OSS Robot Learning
LeRobot v0.4.0 delivers a major upgrade for open-source robotics, introducing scalable Datasets v3.0, powerful new VLA models like PI0.5 and GR00T N1.5, and a new plugin system for easier hardware integration. The release also adds support for LIBERO and Meta-World simulations, simplified multi-GPU training, and a new Hugging Face Robot Learning Course.

Real world applications and how to guides
Lots of applications and tips and tricks this month
Some interesting practical examples of using AI capabilities in the wild
Less mainstream use cases:
From Bean to Bar: Mapping the Global Cocoa Supply Chain with AI (Hat tip to Trevor!)
Can a model trained on satellite data really find brambles on the ground? Great fun- true field testing of a model!
So it turns out that there’s a lot of bramble between the community center and entrance to Milton Country Park. We stopped six or seven times before reaching the park entrance. While the model predicted we’d find brambles all over the park, we went for the few areas of very high confidence near the entrance. In every place we checked, we found pretty significant amounts of bramble.
Some excellent AI for Science work
Using AI to identify genetic variants in tumors with DeepSomatic

AI as a research partner: Advancing theoretical computer science with AlphaEvolve
A fundamental challenge in using AI for theoretical computer science research lies in the universal nature of the problems studied. An AI system might find a solution to a specific instance of a problem — say, the optimal route for a traveling salesman visiting 50 specific cities. However, computer scientists often seek theorems that hold true universally for all problem instances and sizes (denoted as ∀n). How can we use AlphaEvolve to prove a universal statement? The answer lies in a technique known as “lifting”. If a proof is viewed as a long string, then one can take a chunk of the proof (corresponding to a certain finite structure), and evolve it to support a stronger universal statement, while keeping the interface to the rest of the proof intact. The advantage of this approach is that to certify overall correctness, one needs to only certify the correctness of the finite structure that has been evolved.Back to my physics roots…
AI tool helps astronomers find supernovae in a sky full of noise
The surprising thing is how little data it took. With just 15,000 examples and the computing power of my laptop, I could train smart algorithms to do the heavy lifting and automate what used to take a human beings hours to do each day. This demonstrates that with expert guidance, AI can transform astronomical discovery without requiring enormous data sets or computational powerDeveloping AI agents for self-driving quantum laboratories

Excellent work lead by Committee member Adam Davison at the ASA- Harnessing AI for good: world-leading trial monitoring alcohol ads

And in terms of new AI applications, let the AI browser wars begin! Perplexity (The Internet is Better on Comet); OpenAI (Introducing ChatGPT Atlas) - while Google’s chrome is slowly morphing in front of our eyes!
Some great tutorials, how-to’s and useful things this month
Thinking of fine tuning a larger model? Definitely check out `Tinker`
Today, we are launching Tinker, a flexible API for fine-tuning language models. It empowers researchers and hackers to experiment with models by giving them control over the algorithms and data while we handle the complexity of distributed training. Tinker advances our mission of enabling more people to do research on cutting-edge models and customize them to their needs.Thinking of building out your speech recognition pipeline? This new Hugging Face leaderboard would be a good place to start
The evolution of Agent architecture- useful thoughts on direction of travel: Agents 2.0: From Shallow Loops to Deep Agents

And the evolution of Retrieval Augmented Generation (RAG): From Claude Code to Agentic RAG. Thought provoking: “from similarity-centric retrieval to reasoning-centric retrieval, from indexing for machines to indexing for models.”

More good stuff from Thinking Machines (see Tinker above) - LoRA Without Regret
There is agreement that LoRA underperforms in settings that resemble pre-training,LoRA Learns Less and Forgets Less (Biderman et al, 2024) namely those with very large datasets that exceed the storage limits of LoRA parameters. But for dataset sizes that are typical in post-training, LoRA has sufficient capacity to store the essential information. However, this fact makes no guarantees regarding sample efficiency and compute efficiency. The question is: can LoRA match the performance of full fine-tuning, and if so, under which conditions? In our experiments, we find that indeed, when we get a few key details right, LoRA learns with the same sample efficiency as FullFT and achieves the same ultimate performance.Understanding the link between encode-only models and diffusion- BERT is just a Single Text Diffusion Step
A while back, Google DeepMind unveiled Gemini Diffusion, an experimental language model that generates text using diffusion. Unlike traditional GPT-style models that generate one word at a time, Gemini Diffusion creates whole blocks of text by refining random noise step-by-step. I read the paper Large Language Diffusion Models and was surprised to find that discrete language diffusion is just a generalization of masked language modeling (MLM), something we’ve been doing since 2018. The first thought I had was, “can we finetune a BERT-like model to do text generation?” I decided to try a quick proof of concept out of curiosity.Thought provoking- The Continual Learning Problem
If we want to move towards a world where models are “always training” and continually learning from experience over time, we need to address a basic challenge: how do we keep updating the parameters of a model without breaking it? In this post, I’ll motivate memory layers as a natural architecture for this paradigm: high-capacity, but sparse (few active parameters) on each forward pass.Going a bit deeper!
PyTorch is probably the most widely used package for neural nets- if you’re interested in learning it (or brushing up), this is a great site: WhyTorch
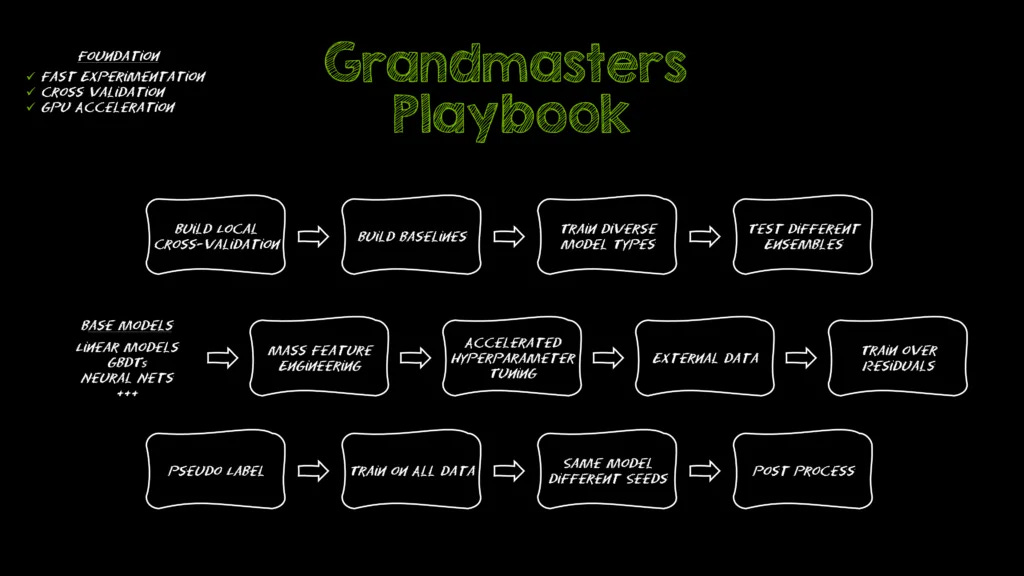
Finally, for those up for a fresh Kaggle challenge… The Kaggle Grandmasters Playbook: 7 Battle-Tested Modeling Techniques for Tabular Data
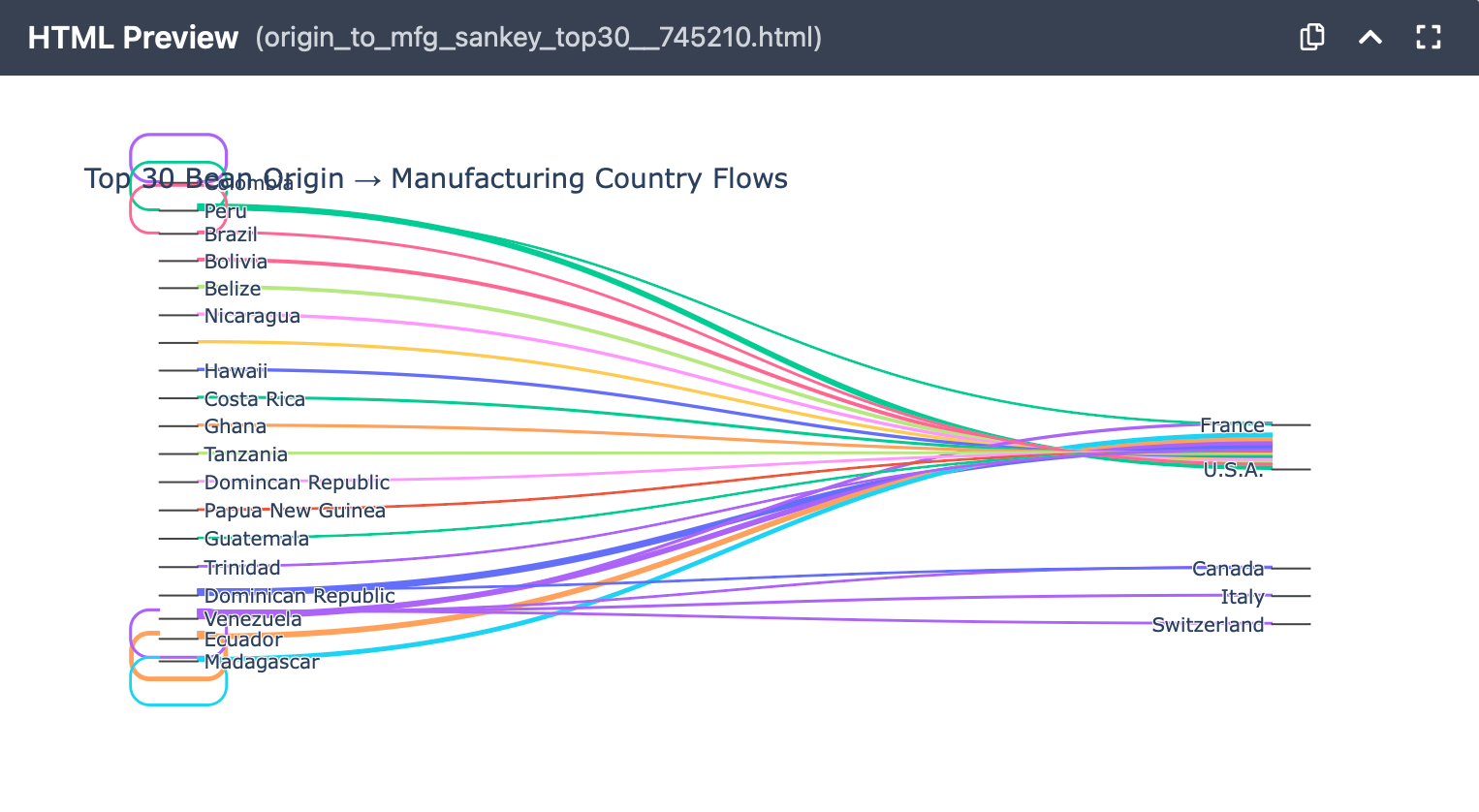




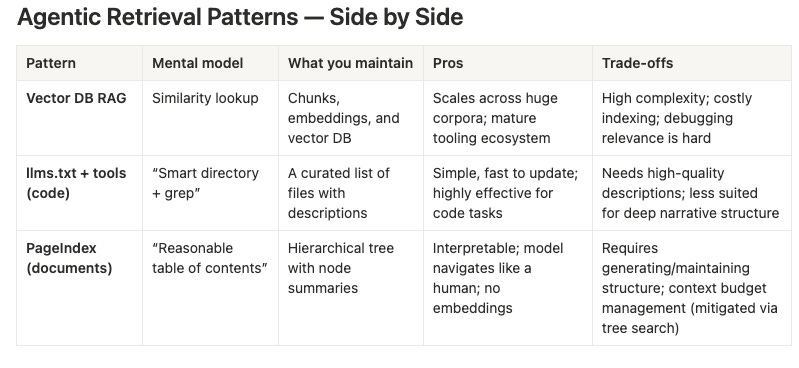
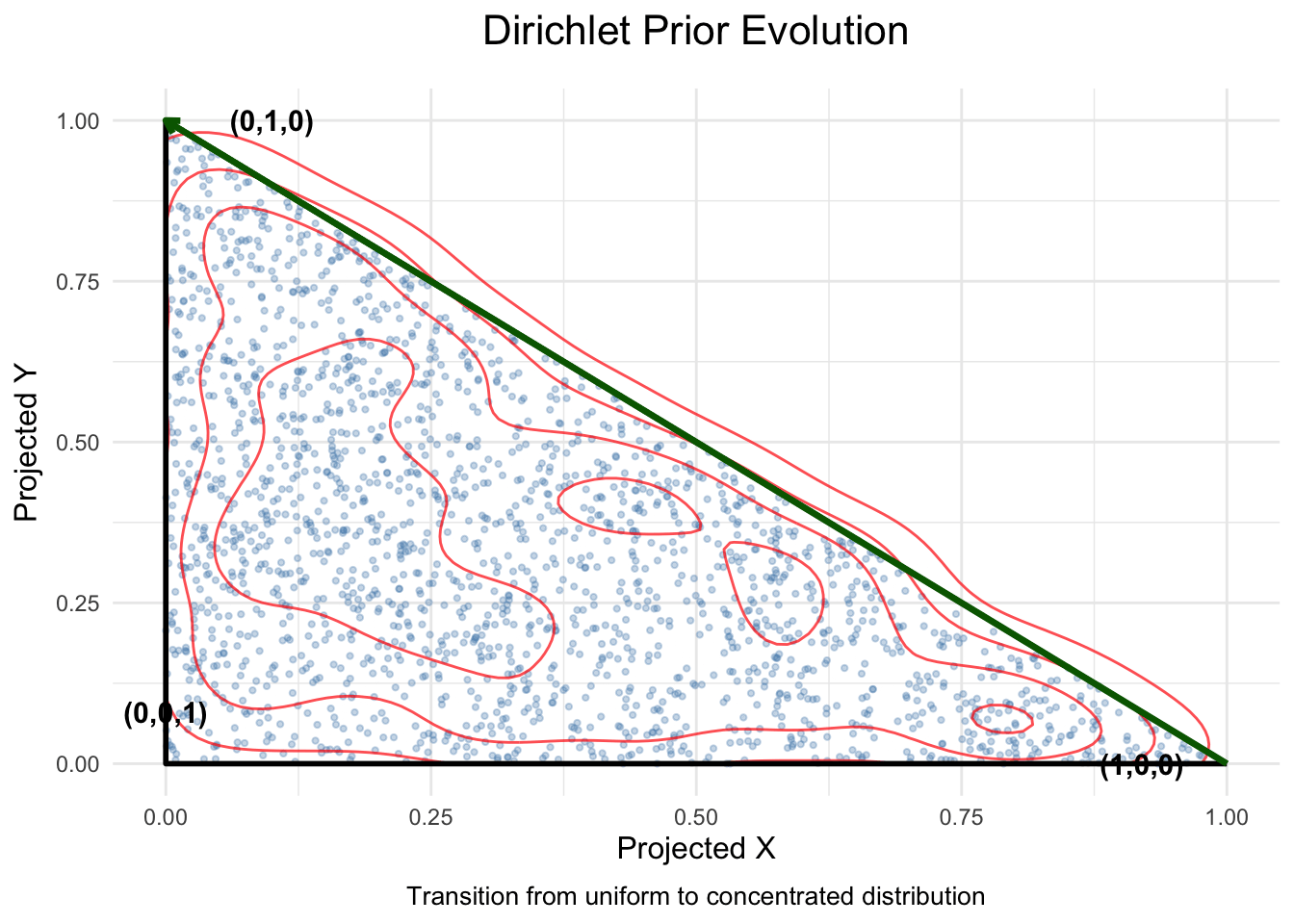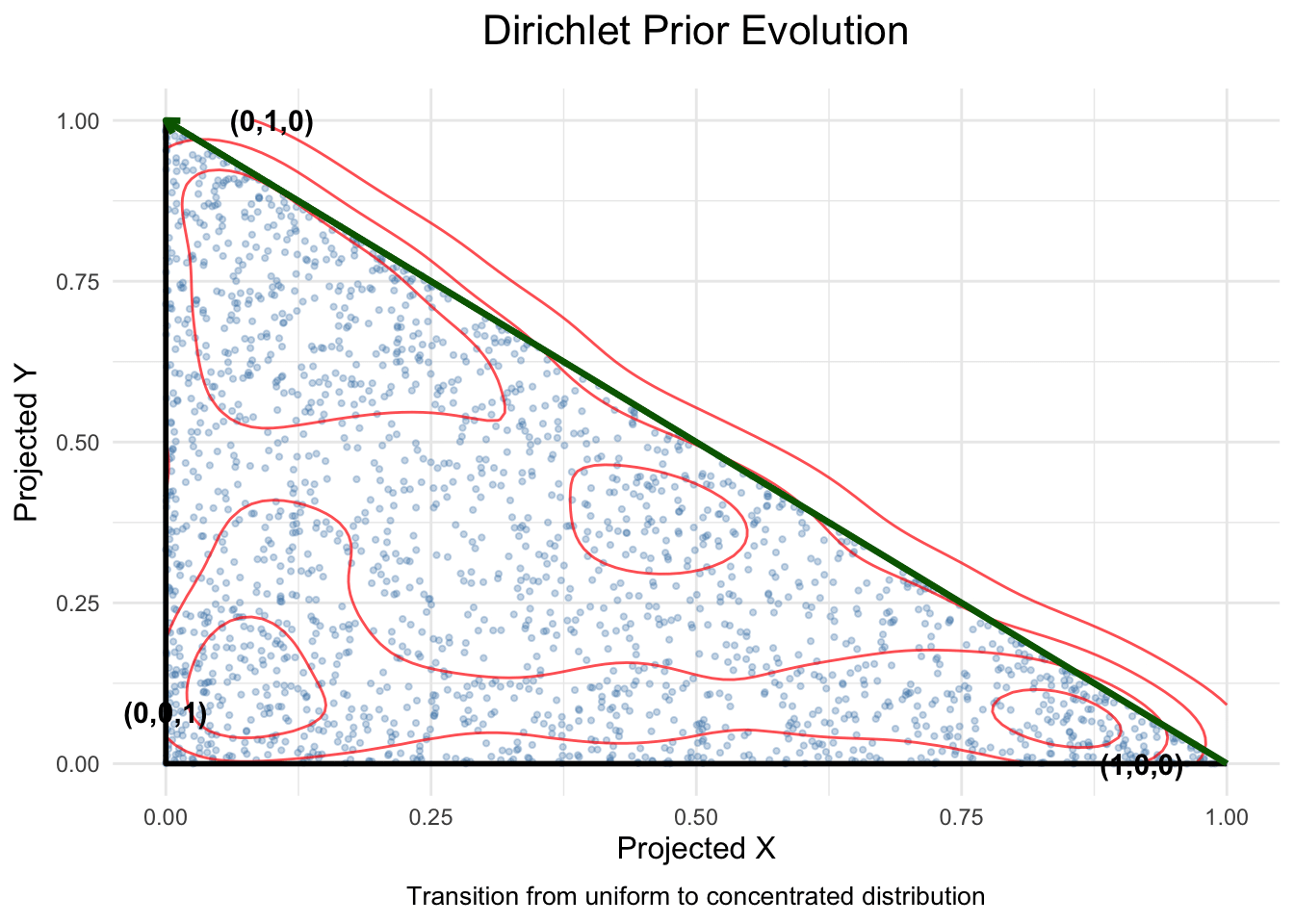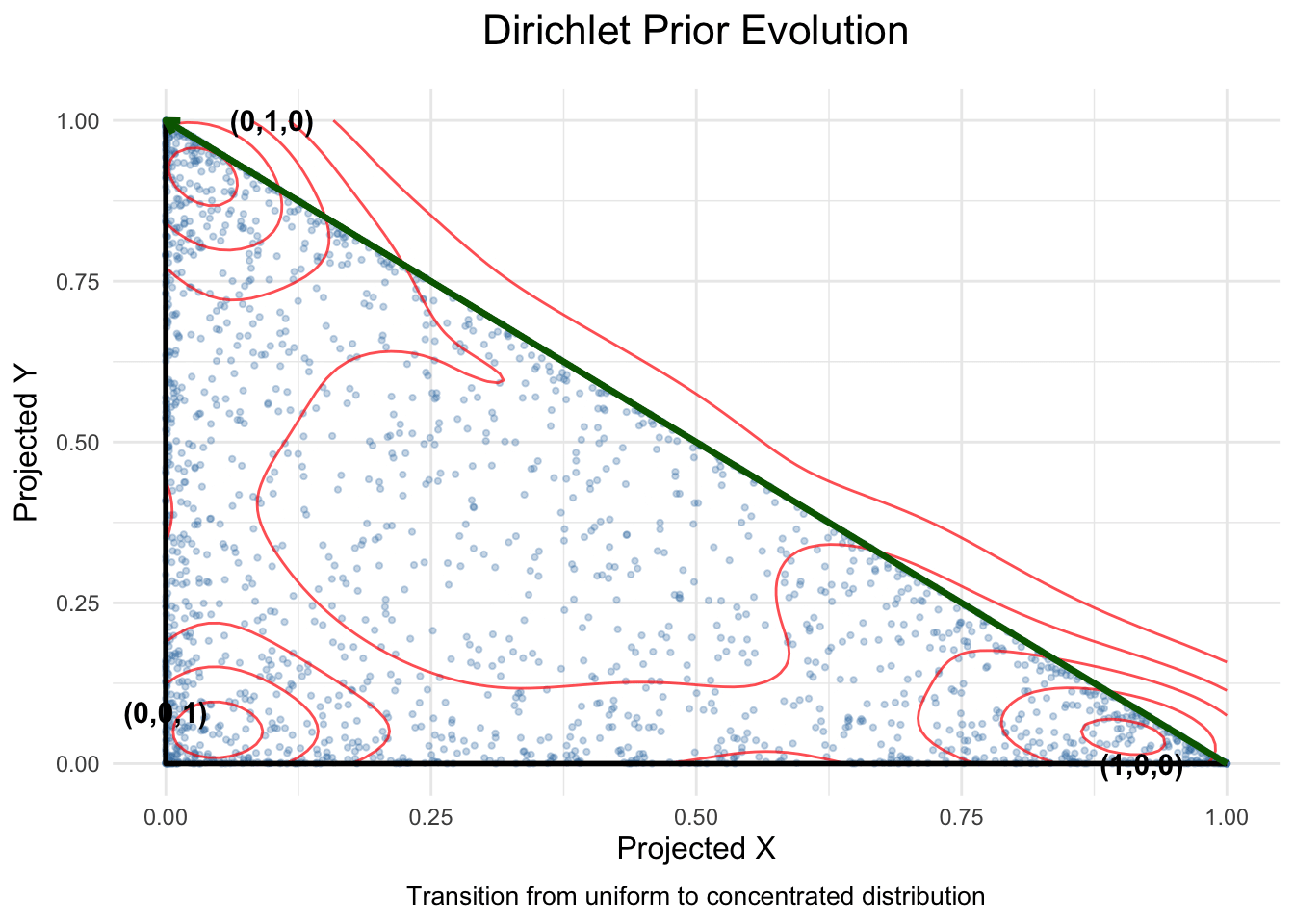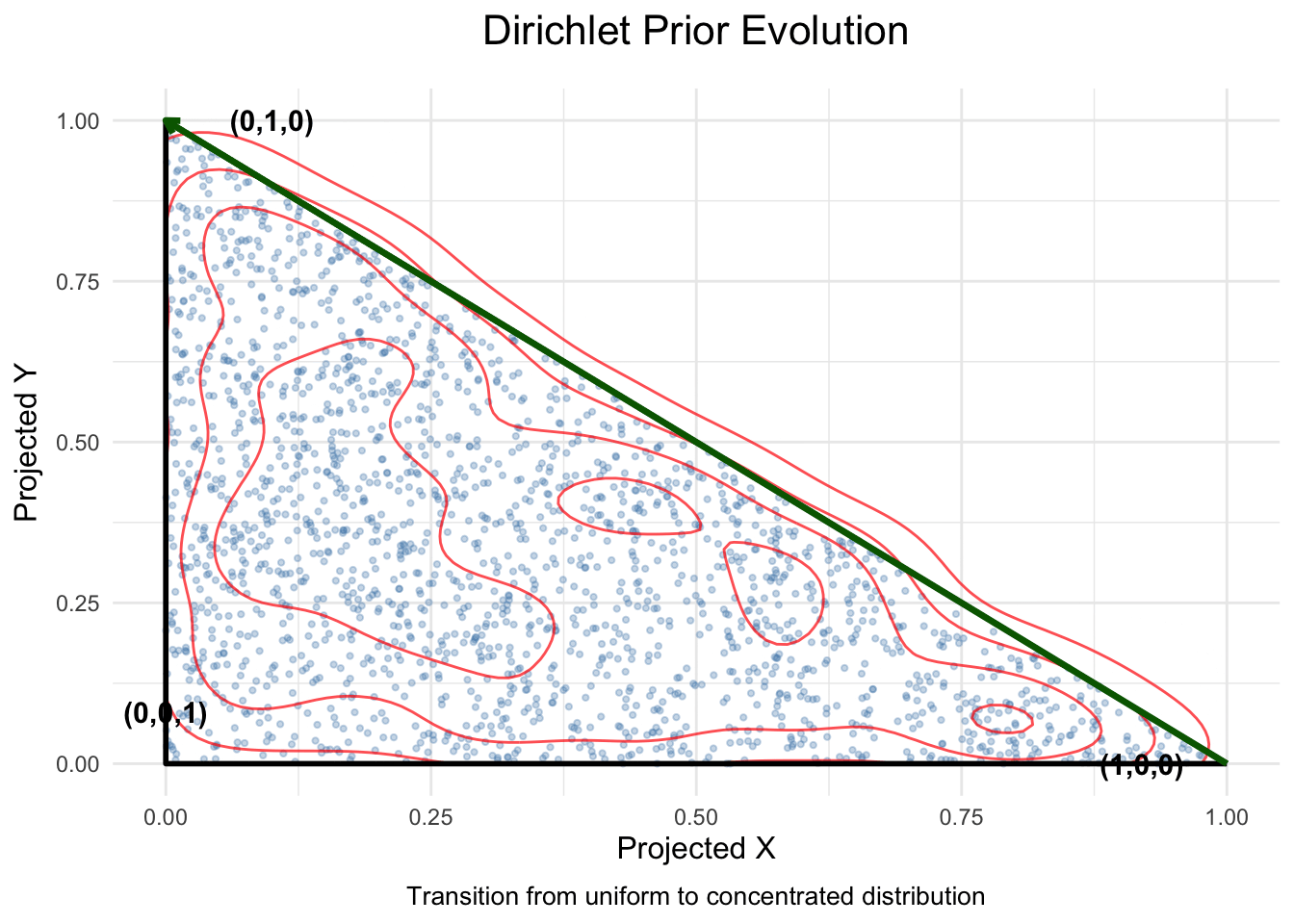

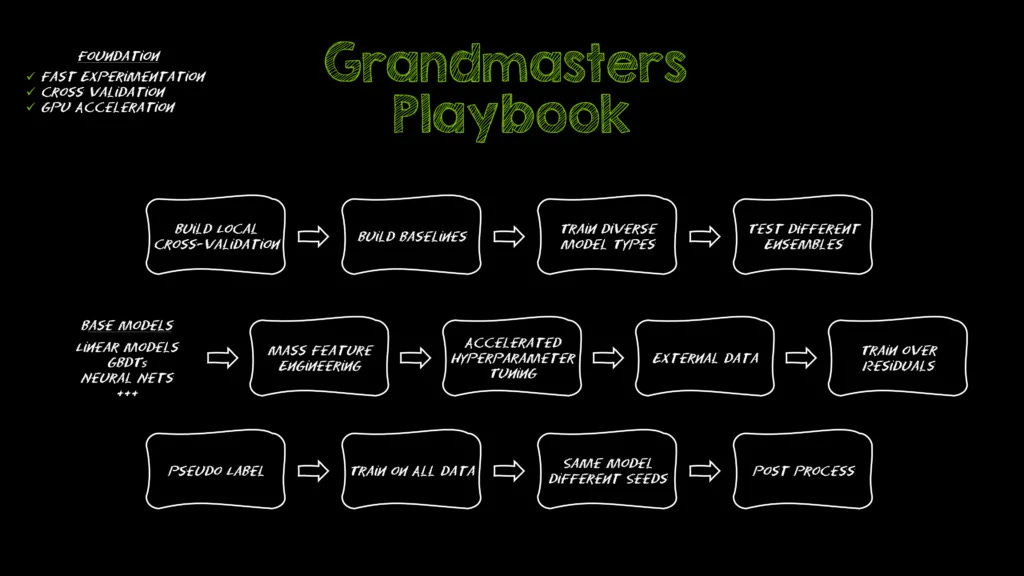
Practical tips
How to drive analytics, ML and AI into production
To be honest, I don’t really understand data meshs and how they are different from various other approaches- however I found this practical and useful: So you want to build a data mesh
Data mesh is defined by 4 principles that work in concert: - Domain Ownership - Data as a Product - Self-serve Data Platform - Federated Computational Governance Each of these 4 principles can guide how you should implement dbt Mesh for distributed data management at scale.Useful insight- From 8 years down to 6 months: How we built AI to split the monday.com monolith
The reason we created Morphex was not because the Cursor/Claude code CLI wasn’t good enough; we use it daily. It was because they relied solely on raw AI, and couldn’t carry out a very large task without a lot of guidelines or a human to drive it. From our experience, when we tried giving AI such complex tasks, it would get lost very quickly and start hallucinating. For example, it would suddenly decide that, “Okay, it’s tested and passing,” when in fact it wasn’t. Breaking the task into smaller prompts, providing strict rules, or using tools like CursorRIPER yielded much better results, but even those weren’t independent enough to just “fire and forget”. In addition, to handle thousands of files, the process had to be executed in parallel, and completely independently without humans to prompt, approve, and resume.Interesting deep dive from the engineers who created Kimi (leading Chinese open source model) on efficient post training RL
Currently, LLM reinforcement learning training mainly consists of two architectures: colocate and disaggregation. Colocate means training and inference share GPU resources and alternate GPU usage; disaggregation means training and inference are separated, each occupying different GPU devices. In both architectures, a crucial phase is parameter updates - after each training round ends, parameters need to be synchronized to the inference framework before rollout begins. If this phase takes too long, it causes GPUs to idle, preventing improved overall GPU utilization and resulting in significant losses to end-to-end training performance. Therefore, efficient parameter updates are a worthwhile optimization direction in RL training.Quick look at costs
What is actually the cheapest inference when you take into account token counts, reasoning etc: InferenceMAX™: Open Source Inference Benchmarking
Insightful! Why are embeddings so cheap?
To illustrate how cheap it is, embedding the entire English Wikipedia corpus would cost approximately: 4.9B words x (4/3) tokens per word x (1000 x $0,10/1M tokens) = $650 5B words or ~10M pages of text for $650.
Speeding things up:
Hard core! Fast Matrix Multiply on an Apple GPU
A SQL Heuristic: ORs Are Expensive
Slow: With 1,000,000 applications and 1000 users uniformly distributed on both columns, it takes over 100ms. select count(*) from application where submitter_id = :user_id or reviewer_id = :user_id; Quick: This takes less than 1ms; Over 100 times faster! select ( select count(*) from application a where a.reviewer_id = :user_id ) + ( select count(*) from application a where a.submitter_id = :user_id ) - ( select count(*) from application a where a.submitter_id = :user_id and a.reviewer_id = :user_id );
Useful: Which Table Format Do LLMs Understand Best? (Results for 11 Formats
")
Finally - a great cautionary tale about using LLMs to write unit tests: AI-Generated Tests are Lying to You
The problem begins with how these LLM-based tools actually “test” your code. When you ask an AI model to generate unit tests, it almost always starts by analyzing the code you’re asking it to test. It reads your function signatures, interprets variable names, infers likely branches, and then produces test cases whose expected outputs match whatever your current code does. This sounds reasonable until you realize what it means: your tests now validate the implementation, not the intention.
")
Bigger picture ideas
Longer thought provoking reads - sit back and pour a drink! ...
Technological Optimism and Appropriate Fear- Jack Clark
But if you read the system card, you also see its signs of situational awareness have jumped. The tool seems to sometimes be acting as though it is aware that it is a tool. The pile of clothes on the chair is beginning to move. I am staring at it in the dark and I am sure it is coming to life.Why America Builds AI Girlfriends and China Makes AI Boyfriends - Zilan Qian
What makes AI chatbot interaction so concerning? Why is the U.S. more worried about child interaction, whereas the Chinese government views AI companions as a threat to family-making and childbearing? The answer lies in how different societies build different types of AI companions, which then create distinct societal risks. Drawing from an original market scan of 110 global AI companion platforms and analysis of China’s domestic market, I explore here shows how similar AI technologies produce vastly different companion experiences—American AI girlfriends versus Chinese AI boyfriends—when shaped by cultural values, regulatory frameworks, and geopolitical tensionsSome useful insight into why AI is struggling to penetrate certain industries
AI isn’t replacing radiologists - Works in Progress and Deena Mousa
Radiology is a field optimized for human replacement, where digital inputs, pattern recognition tasks, and clear benchmarks predominate. In 2016, Geoffrey Hinton – computer scientist and Turing Award winner – declared that ‘people should stop training radiologists now’. If the most extreme predictions about the effect of AI on employment and wages were true, then radiology should be the canary in the coal mine. But demand for human labor is higher than ever. In 2025, American diagnostic radiology residency programs offered a record 1,208 positions across all radiology specialties, a four percent increase from 2024, and the field’s vacancy rates are at all-time highs. In 2025, radiology was the second-highest-paid medical specialty in the country, with an average income of $520,000, over 48 percent higher than the average salary in 2015.Why There Hasn’t Been a ChatGPT Moment Yet in Manufacturing - Lesley Gao
A mechanical engineer designing a turbine blade in 2025 uses essentially the same workflow as their predecessor in 1995: opening CAD software, manually sketching constraints, defining features one by one, and exporting files through a chain of disconnected tools. A “ChatGPT moment” for hardware design and manufacturing has yet to arrive. The smart factories envisioned by Industry 4.0 advocates, where design, simulation, and production flow as one continuous system, remain largely theoretical in practice. If AI can generate functioning code, photorealistic images, and coherent essays, why can’t it design a bracket or optimize a gear assembly?
And maybe one industry where we are finally getting there: Move Fast and Break Nothing- Waymo’s robotaxis are probably safer than ChatGPT - Saahil Desai
Every trip in a self-driving Waymo has the same dangerous moment. The robotaxi can successfully shuttle you to your destination, stopping carefully at every red light and dutifully following the speed limit. But at the very end, you, a flawed human being, will have to place your hand on the door handle, look both ways, and push the door open. From mid-February to mid-August of this year, Waymo’s driverless cars were involved in three collisions that came down to roughly identical circumstances: A passenger flung their door open and hit somebody passing by on a bike or scooter.Real AI Agents and Real Work - Ethan Mollick
Human experts won, but barely, and the margins varied dramatically by industry. Yet AI is improving fast, with more recent AI models scoring much higher than older ones. Interestingly, the major reason for AI losing to humans was not hallucinations and errors, but a failure to format results well or follow instructions exactly — areas of rapid improvement. If the current patterns hold, the next generation of AI models should beat human experts on average in this test. Does that mean AI is ready to replace human jobs?
We are in the “gentleman scientist” era of AI research - Sean Goedecke
The success of LLMs is like the rubber-band engine. A simple idea that anyone can try3 - train a large transformer model on a ton of human-written text - produces a surprising and transformative technology. As a consequence, many easy questions have become interesting and accessible subjects of scientific inquiry, alongside the normal hard and complex questions that professional researchers typically tackle.Animals vs Ghosts- Andrej Karpathy
So that brings us to where we are. Stated plainly, today’s frontier LLM research is not about building animals. It is about summoning ghosts. You can think of ghosts as a fundamentally different kind of point in the space of possible intelligences. They are muddled by humanity. Thoroughly engineered by it. They are these imperfect replicas, a kind of statistical distillation of humanity’s documents with some sprinkle on top. They are not platonically bitter lesson pilled, but they are perhaps “practically” bitter lesson pilled, at least compared to a lot of what came before. It seems possibly to me that over time, we can further finetune our ghosts more and more in the direction of animals; That it’s not so much a fundamental incompatibility but a matter of initialization in the intelligence space. But it’s also quite possible that they diverge even further and end up permanently different, un-animal-like, but still incredibly helpful and properly world-altering. It’s possible that ghosts:animals :: planes:birds.Do Humans Really Have World Models - Daniel Miessler
Think to yourself what would happen if a ball rolls off the side of a table. But then imagine the table is tilted a few degrees in one direction. Or imagine it in zero gravity going around the Earth. Here’s what will happen. - An image pops into your head, changing as you think about the different scenarios - And then when you think about how to explain it, words pop into your head - And then you speak those words, not knowing which ones you’re going to use, basically making you a bystander as the words spill out of you Don’t believe me? Try again. Try as many times as you want. That is what we do as humans. How is this different from LLMs exactly?
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
Learn to build an open source robot! Hugging Face robotics course


Updates from Members and Contributors
Kirsteen Campbell, Public Involvement and Communications Manager at UK Longitudinal Linkage Collaboration highlights the following which could be very useful for researchers: “UK Longitudinal Linkage Collaboration (UK LLC) announces new approvals from NHS providers and UK Government departments meaning linked longitudinal data held in the UK LLC Trusted Research Environment can now be used for a wide range of research in the public good. Read more: A new era for a wide range of longitudinal health and wellbeing research | UK Longitudinal Linkage Collaboration- Enquiries to: access@ukllc.ac.uk”
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS