

Hi everyone-
Well September certainly seemed to dissapear rapidly, as did the sun- I’m still hoping for a few warm days before the darkness kicks in! Time to sit back with some reading materials on all things Data Science and AI… Lots of great content below and I really encourage you to read on, but here are the edited highlights if you are short for time!
How We Built the First AI-Generated Genomes - Arc Institute
Why language models hallucinate - OpenAI (more advanced take here)
A.I.-Driven Education: Founded in Texas and Coming to a School Near You - NYTimes
On Working with Wizards - Ethan Mollick
AI Artists vs. AI Engineers - Vikram Sreekanti and Joseph E. Gonzalez
Following is the latest edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
The Section had an active presence at the recent Royal Statistical Society International Conference, in Edinburgh:
Our very own Will Browne featured in three sessions:
Code, Calculate, Change: How Statistics Fuels AI's Real-World Impact
AI Taskforce - AI evaluation session
Cracking the code: How to hire the perfect data scientist for your company and how to spot them
And our Chair, Janet Bastiman featured at:
AI Task Force - one year on
Confessions of a Data Science Practitioner
Never to early to start thinking about next year’s conference (Bournemouth from 7-10 September 2026)! - the call for proposals for invited sessions and workshops has been published. It is a great opportunity to showcase research in your areas or highlight issues or topics that you are passionate about.
We are delighted to announce the opening of the first issue of RSS: Data Science and Artificial Intelligence with an editorial by the editors setting out their vision for the new journal.
RSS: Data Science and Artificial Intelligence is open to submissions and offers an exciting open access venue for your work in these disciplines. It has a broad reach across statistics, machine learning, deep learning, econometrics, bioinformatics, engineering, computational social sciences.
Discover more about why the new journal is the ideal platform for showcasing your research and how to prepare your manuscript for submission.
Visit our submission site to submit your paper
Watch as editor Neil Lawrence introduces the journal at the RSS conference 2024 Neil Lawrence launches new RSS journal
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
The ongoing saga of copyright and IP with both AI training and production is far from ending
Anthropic settles with authors in first-of-its-kind AI copyright infringement lawsuit
In one of the largest copyright settlements involving generative artificial intelligence, Anthropic AI, a leading company in the generative AI space, has agreed to pay $1.5 billion to settle a copyright infringement lawsuit brought by a group of authors..Although its not clear the settlement will go through: Judge skewers $1.5B Anthropic settlement with authors in pirated books case over AI training
Alsup’s main concern centered on how the claims process will be handled in an effort to ensure everyone eligible knows about it so the authors don’t “get the shaft.” He set a September 22 deadline for submitting a claims form for him to review before the Sept. 25 hearing to review the settlement again. The judge also raised worries about two big groups connected to the case — the Authors Guild in addition to the Association of American Publishers — working “behind the scenes” in ways that could pressure some authors to accept the settlement without fully understanding it.Meanwhile - Warner Bros. sues Midjourney to stop AI knockoffs of Batman, Scooby-DooEthical concerns with replacing human relations with humanoid robots: an ubuntu perspective

Do the ever progressive Swedes have a potential solution- Sweden launches AI music licence to protect songwriters
“We show that it is possible to embrace disruption without undermining human creativity. This is not just a commercial initiative but a blueprint for fair compensation and legal certainty for AI firms,” Lina Heyman, STIM's acting CEO, said in a statement.
We are beginning to discover how potentially harmful AI Chatbots can be to those with mental illness
OpenAI on the subject- Helping people when they need it most
As the world adapts to this new technology, we feel a deep responsibility to help those who need it most. We want to explain what ChatGPT is designed to do, where our systems can improve, and the future work we’re planning.Some US States are taking matters into their own hands though: Gov Pritzker Signs Legislation Prohibiting AI Therapy in Illinois
“The people of Illinois deserve quality healthcare from real, qualified professionals and not computer programs that pull information from all corners of the internet to generate responses that harm patients,” said IDFPR Secretary Mario Treto, Jr. “This legislation stands as our commitment to safeguarding the well-being of our residents by ensuring that mental health services are delivered by trained experts who prioritize patient care above all else."
Different countries continue to pursue different AI strategies
China appears to be pulling together quite an all encompassing policy- China Releases “AI Plus” Policy: A Brief Analysis
The key phrase here is “intelligent society.” This isn’t just about the economy anymore, but about transforming society itself. AI will be deeply woven into law, ethics, culture, and human interaction. How Chinese people work, study, socialize, even think—all will be reshaped. For today’s China, 2035 may feel as distant as looking back from today to the 1990s, before the internet—familiar yet foreign. It’s the point where science fiction starts to become reality.And their innovative new law on labelling AI generated content is driving change- China’s social media platforms rush to abide by AI-generated content labelling law
The French continue to back Mistral which is finalising a new $2b investment
Even Switzerland is getting in the game: Switzerland releases its own AI model trained on public data
Apertus, which is Latin for “open,” was designed to “set a new baseline for trustworthy and globally relevant open models,” according to the developers. The model was trained on over 1,800 languages and comes in two sizes with either 8 billion or 70 billion parameters. Apertus is comparable to the 2024 Llama 3 model from Meta, according to SWI.As for the UK? Well… Head of UK's Turing AI Institute resigns after funding threat- feels like we need to rip it up and start again.
The chief executive of the UK's national institute for artificial intelligence (AI) has resigned following staff unrest and a warning the charity was at risk of collapse.
From a privacy perspective, this is not great- Anthropic users face a new choice – opt out or share your chats for AI training
That is a massive update. Previously, users of Anthropic’s consumer products were told that their prompts and conversation outputs would be automatically deleted from Anthropic’s back end within 30 days “unless legally or policy‑required to keep them longer” or their input was flagged as violating its policies, in which case a user’s inputs and outputs might be retained for up to two years.Although Anthropic is at least attempting to limit the use of its products- Anthropic irks White House with limits on models’ use
For instance, Anthropic currently limits how the FBI, Secret Service and Immigration, and Customs Enforcement can use its AI models because those agencies conduct surveillance, which is prohibited by Anthropic’s usage policy.And is doing thoughtful research on risks- Why do we take LLMs seriously as a potential source of biorisk?
Nevertheless, at least two factors make biorisk especially concerning. First, the potential consequences of a successful biological attack are unusually severe. The effects of an attack with a virus could spread far beyond the initial target in a way that is qualitatively different from weapons with more local effects. Second, improvements in other areas of biotechnology may have lowered some of the material barriers that previously served as a “passive” biodefense. For instance, the decreasing cost of nucleic acid synthesis, standardization of reagent kits, and easy access to standard molecular biology equipment (such as PCR machines), are making material acquisition less of a bottleneck. AI models further reduce barriers to information and know-how. As a result, this combination of high consequences and increasing plausibility make addressing additional biorisk from AI an important priority.

Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
Intriguing new approach to the Transformer model, that shows great promise for scalability, particularly at inference time: Energy-Based Transformers are Scalable Learners and Thinkers
In this paper, we ask the question "Is it possible to generalize these System 2 Thinking approaches, and develop models that learn to think solely from unsupervised learning?" Interestingly, we find the answer is yes, by learning to explicitly verify the compatibility between inputs and candidate-predictions, and then re-framing prediction problems as optimization with respect to this verifier. Specifically, we train Energy-Based Transformers (EBTs) -- a new class of Energy-Based Models (EBMs) -- to assign an energy value to every input and candidate-prediction pair, enabling predictions through gradient descent-based energy minimization until convergence.And an innovative approach to reasoning for open ended tasks: Reverse-Engineered Reasoning for Open-Ended Generation
The two dominant methods for instilling reasoning -- reinforcement learning (RL) and instruction distillation -- falter in this area; RL struggles with the absence of clear reward signals and high-quality reward models, while distillation is prohibitively expensive and capped by the teacher model's capabilities. To overcome these limitations, we introduce REverse-Engineered Reasoning (REER), a new paradigm that fundamentally shifts the approach. Instead of building a reasoning process ``forwards'' through trial-and-error or imitation, REER works ``backwards'' from known-good solutions to computationally discover the latent, step-by-step deep reasoning process that could have produced them.Impressive work from the Google Research team on privacy: VaultGemma: The world's most capable differentially private LLM
Our new research, “Scaling Laws for Differentially Private Language Models”, conducted in partnership with Google DeepMind, establishes laws that accurately model these intricacies, providing a complete picture of the compute-privacy-utility trade-offs. Guided by this research, we’re excited to introduce VaultGemma, the largest (1B-parameters), open model trained from scratch with differential privacy. We are releasing the weights on Hugging Face and Kaggle, alongside a technical report, to advance the development of the next generation of private AI.A useful new benchmark for real world science: CMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics
CMPhysBench is composed of more than 520 graduate-level meticulously curated questions covering both representative subfields and foundational theoretical frameworks of condensed matter physics, such as magnetism, superconductivity, strongly correlated systems, etc. To ensure a deep understanding of the problem-solving process,we focus exclusively on calculation problems, requiring LLMs to independently generate comprehensive solutions.There is life outside of GenAI!
If you like trees (the statistical kind!), this looks worth exploring: Transparent, Robust and Ultra-Sparse Trees (TRUST) - repo here
LMTs combine the strengths of two popular interpretable machine learning models: Decision Trees (non-parametric) and Linear Models (parametric). Like a standard Decision Tree, they partition data based on simple decision rules. However, the key difference lies in how they evaluate these splits and model the data. Instead of using a simple constant (like the average) to evaluate the goodness of a split, LMTs fit a Linear Model to the data within each node. This approach means that the final predictions in the leaves are made by a Linear Model rather than a simple constant approximation. This gives Linear Model Trees both the predictive and explicative power of a linear model, while also retaining the ability of a tree-based algorithm to handle complex, non-linear relationships in the data.And a cautionary note- On the (Mis)Use of Machine Learning With Panel Data
We provide the first systematic assessment of data leakage issues in the use of machine learning on panel data. Our organising framework clarifies why neglecting the cross-sectional and longitudinal structure of these data leads to hard-to-detect data leakage, inflated out-of-sample performance, and an inadvertent overestimation of the real-world usefulness and applicability of machine learning models.
Generative AI ... oh my!
Still moving at such a fast pace it feels in need of it's own section, for developments in the wild world of large language models...
After the blockbuster summer, a slightly quieter month
Google and OpenAI still trading blows at the bleeding edge: Google and OpenAI’s coding wins at university competition show enterprise AI tools can take on unsolved algorithmic challenges
GPT-5 managed to achieve a perfect score, answering 12 out of 12 problems, a performance akin to winning a gold medal in the event. Gemini 2.5 Deep Think solved 10 of the 12 algorithmic problems in 677 minutes, which Google DeepMind said in a blog post would rank second overall in the competition.OpenAI is always active:
A new API which is definitely not about hiding the thinking process of proprietary OpenAI models ;-) Why we built the Responses API
Interesting study on how people are using ChatGPT
The findings show that consumer adoption has broadened beyond early-user groups, shrinking the gender gap in particular; that most conversations focus on everyday tasks like seeking information and practical guidance; and that usage continues to evolve in ways that create economic value through both personal and professional use. This widening adoption underscores our belief that access to AI should be treated as a basic right—a technology that people can access to unlock their potential and shape their own future.What could become an important benchmark for the impact of AI in the real world: Measuring the performance of our models on real-world tasks
GDPval, the first version of this evaluation, spans 44 occupations selected from the top 9 industries contributing to U.S. GDP. The GDPval full set includes 1,320 specialized tasks (220 in the gold open-sourced set), each meticulously crafted and vetted by experienced professionals with over 14 years of experience on average from these fields... ... We found that today’s best frontier models are already approaching the quality of work produced by industry experts.And various hints on what is to come:
OpenAI readies Orders in ChatGPT for native checkout and tracking
OpenAI might be developing a smart speaker, glasses, voice recorder, and a pin
One of the mysterious AI devices that OpenAI is considering developing with Apple’s former chief design officer, Jony Ive, “resembles a smart speaker without a display,” The Information reports. People “with direct knowledge of the matter” told the publication that OpenAI has already secured a contract with Luxshare, and has also approached Goertek — two of Apple’s product assemblers — to supply components like speaker modules for its future lineup of AI gadgets.
And Google continues to match the release pace!
Google also pushing into native payments: Powering AI commerce with the new Agent Payments Protocol (AP2)
Today, Google announced the Agent Payments Protocol (AP2), an open protocol developed with leading payments and technology companies to securely initiate and transact agent-led payments across platforms. The protocol can be used as an extension of the Agent2Agent (A2A) protocol and Model Context Protocol (MCP).Increased batch capabilities- Gemini Batch API now supports Embeddings and OpenAI Compatibility
New open source small embeddings model - EmbeddingGemma - could be useful for search/retrieval applications
The small size and on-device focus makes it possible to deploy in environments with limited resources such as mobile phones, laptops, or desktops, democratizing access to state of the art AI models and helping foster innovation for everyone.Impressive progress in robotics - Gemini Robotics 1.5 brings AI agents into the physical world
And lots of multi-modal innovation
Anthropic continues to innovate:
A new release- Introducing Claude Sonnet 4.5
Bringing memory to teams at work - also interesting background: Claude Memory: A Different Philosophy
Claude's memory system has two fundamental characteristics. First, it starts every conversation with a blank slate, without any preloaded user profiles or conversation history. Memory only activates when you explicitly invoke it. Second, Claude recalls by only referring to your raw conversation history. There are no AI-generated summaries or compressed profiles—just real-time searches through your actual past chats.And support from Anthropic’s Model Context Protocol (MCP) from Apple
Microsoft has been pretty quiet despite the much heralded hiring of Mustafa Suleyman - but they recently released Two in-house models in support of our mission
- First, we’re releasing MAI-Voice-1, our first highly expressive and natural speech generation model, which is available in Copilot Daily and Podcasts, and as a brand new Copilot Labs experience to try out here. Voice is the interface of the future for AI companions and MAI-Voice-1 delivers high-fidelity, expressive audio across both single and multi-speaker scenarios. - Second, we have begun public testing of MAI-1-preview on LMArena, a popular platform for community model evaluation. This represents MAI’s first foundation model trained end-to-end and offers a glimpse of future offerings inside Copilot. We are actively spinning the flywheel to deliver improved models.And Grok continues to be in the news, rightly or wrongly:
Releasing a new lightweight model, Grok 4 Fast
Raising money at eye-watering valuations - perhaps because they really need the money- Grok 4 Training Resource Footprint - $490m to train (recent news puts DeepSeek’s training cost at under $300k…)
New research from Meta- although pretty abstract: “32-billion-parameter open-weights LLM, to advance research on code generation with world models”
On the Open Source front:
Stability image models now available through Amazon Bedrock, and a new Audio model for “enterprise sound production at scale”
The gulf states continue to invest heavily in AI- Abu Dhabi launches low-cost AI reasoning model in challenge to OpenAI, DeepSeek
K2 Think was developed in partnership with G42, the buzzy UAE-based AI firm backed by U.S. tech giant Microsoft. The researchers behind it say it delivers performance on par with the flagship reasoning models of OpenAI and DeepSeek — despite being a fraction of the size.But the Chinese companies still lead the way:
Qwen3-Next: Towards Ultimate Training & Inference Efficiency
DeepSeek-V3.1-Terminus launches with improved agentic tool use and reduced language mixing errors
Alibaba releases biggest AI model to date to rival OpenAI and Google DeepMind
Qwen-3-Max-Preview, the company’s first model to have more than 1 trillion parameters, was released on Alibaba’s official cloud-services platform and the large language model marketplace OpenRouter on Friday.
Real world applications and how to guides
Lots of applications and tips and tricks this month
Some interesting practical examples of using AI capabilities in the wild
Pretty cool - How We Built the First AI-Generated Genomes

I find this sort of thing amazing - Discovering new solutions to century-old problems in fluid dynamics
Experts can carefully craft scenarios that make theory go against practice, leading to situations which could never physically happen. These situations, such as when quantities like velocity or pressure become infinite, are called ‘singularities’ or ‘blow ups’. They help mathematicians identify fundamental limitations in the equations of fluid dynamics, and help improve our understanding of how the physical world functions. In a new paper, we introduce an entirely new family of mathematical blow ups to some of the most complex equations that describe fluid motion... Our approach presents a new way to leverage AI techniques to tackle longstanding challenges in mathematics, physics and engineering that demand unprecedented accuracy and interpretability.New AI driven advertising tools for Amazon sellers
Lots of “AI Inside”:
YouTube with the latest update
And Chrome: The browser you love, reimagined with AI
And in education: Learn Your Way uses AI to transform textbook materials into interactive guides
Some great tutorials and how-to’s this month
Useful pointers on building an AI product from the lead designer of NotebookLM
Good tips here on building AI products and some of the challenges companies have faced over the last 12 months
Excellent tutorial (as always) from Eugene Yan on LLM powered recommendation systems
The idea is simple: Instead of using random hash IDs for videos or songs or products, we can use semantically meaningful tokens that an LLM can natively understand. I wondered, could we train an LLM-recommender hybrid on the rich behavioral data that makes today’s recommender systems so effective? To my surprise, we can! The result is a language model that can converse in both English and item IDs, not with retrieval or other tools, but as a single, “bilingual” model where items (i.e., semantic IDs) are part of its vocabulary. Like a recommender model, it can recommend items given historical interactions. But the big surprise—and capability unlock—was when I found that I could simply chat with the model to steer its recommendations, and it could reason about its choices, offer explanations, and creatively name product bundles.Optimising Tools: Tips from the originators of Model Context Protocol (Anthropic) on how to build effective tools for agents
Tools are a new kind of software which reflects a contract between deterministic systems and non-deterministic agents. When a user asks "Should I bring an umbrella today?,” an agent might call the weather tool, answer from general knowledge, or even ask a clarifying question about location first. Occasionally, an agent might hallucinate or even fail to grasp how to use a tool. This means fundamentally rethinking our approach when writing software for agents: instead of writing tools and MCP servers the way we’d write functions and APIs for other developers or systems, we need to design them for agents. Our goal is to increase the surface area over which agents can be effective in solving a wide range of tasks by using tools to pursue a variety of successful strategies.Optimising prompts- DSPY 0-to-1 guide (I still havnt properly figured this out yet for our context, but really want to!)
DSPy—short for Declarative Self‑improving Python—was developed at Stanford University to address these pain points. It allows developers to program their applications rather than engineer prompts. You declare what inputs and outputs your system should handle, write modular Python code, and let DSPy automatically compile prompt templates and optimize them.And optimising context: What Is the Context Engineering Series for Agentic RAG Systems?
Before: We precomputed what chunks needed to be put into context, injected them, and then asked the system to reason about the chunks. Search was a one-shot operation—you got your top-k results and that was it. Now: Agents are incredibly easy to build because all you need is a messages array and a bunch of tools. They're persistent, make multiple tool calls, and build understanding across conversations. They don't just need the right chunk—they need to understand the landscape of available information.Getting deeper into the stack- all you ever wanted to know about LLM Post-Training
This document serves as a guide to understanding the basics of LLM post-training. It covers the complete journey from pre-training to instruction-tuned models. The guide walks through the entire post-training lifecycle, exploring: - The transition from next-token prediction to instruction following - Supervised Fine-Tuning (SFT) fundamentals, including dataset creation and loss functions - Various Reinforcement Learning techniques (RLHF, RLAIF, RLVR) with detailed explanations of reward models - Evaluation methodologies for assessing model qualityWhat are hallucinations and why do they happen- a couple of excellent posts both well worth a read:
First from OpenAI giving the high level view
Then an excellent deeper dive from Thinking Machines
Before talking about nondeterminism, it’s useful to explain why there are numerical differences at all. After all, we typically think of machine learning models as mathematical functions following structural rules such as commutativity or associativity. Shouldn’t there be a “mathematically correct” result that our machine learning libraries should provide us? The culprit is floating-point non-associativity. That is, with floating-point numbers: (a+b)+c ≠ a+(b+c)
Getting pretty deep in the weeds- Attention sinks from the graph perspective
As a mechanism, attention sinks are easy to describe: when trained, decoder-only transformer models tend to allocate a disproportionate amount of attention to the first few tokens, and especially to the first. This effect is well studied in its practical terms, and is often attributed to the model "offloading" probability mass to the early tokens to avoid their spurious allocation elsewhere. Recent works, like Softpick, provide architectural choices that prevent sinks from forming. While this explanation may sound convincing at a first glance, my intuition is still bothered by it: what do you mean the model "offloads"?More stats-y:
Useful and intuitive- From Frequencies to Coverage: Rethinking What “Representative” Means
Whether you build an image classifier or want to estimate the average rent in Bologna, you need data. But not just any data, the data should be “representative”: A dog image classifier shouldn’t only be trained on images of dogs in spooky costumes, and the Bologna dataset shouldn’t only contain apartments above restaurants. But what exactly does “representative” mean? Let’s start with a very general definition: A represents B if A adequately reflects the characteristics of B. However, there are different interpretations of “reflects the characteristics”.Understanding Multilevel Models
In public health research, we frequently encounter multilevel structures such as: - Counties nested within states (our focus) - Patients nested within hospitals - Students nested within schools nested within districts - Individuals nested within neighborhoods nested within cities This hierarchical structure violates the independence assumption of traditional regression models because observations within the same higher-level unit tend to be more similar to each other than to observations in other units - a phenomenon known as intracluster correlation.And a simple but useful primer on statistical power
I really like tutorials that bring difficult concepts to life through examples- case in point, Minesweeper thermodynamics
Finally - How To Become A Mechanistic Interpretability Researcher
Mechanistic interpretability (mech interp) is, in my incredibly biased opinion, one of the most exciting research areas out there. We have these incredibly complex AI models that we don't understand, yet there are tantalizing signs of real structure inside them. Even partial understanding of this structure opens up a world of possibilities, yet is neglected by 99% of machine learning researchers. There’s so much to do!


Practical tips
How to drive analytics, ML and AI into production
Are data engineers just software engineers working on data? No- Data Engineering is Not Software Engineering
This assessment is misguided. Data engineering and software engineering share many common tools and practices, but they also differ substantially in a number of key areas. Ignoring these differences and managing a data engineering team like a software product team is a mistake. Think of data engineering like a tomato: it is a fruit but that doesn’t mean it should be added to a fruit salad.Anthropic shares details of some recent engineering problems with Claude: A postmortem of three recent issues

Interesting deep dive from the engineers who created Kimi (leading Chinese open source model) on efficient post training RL
Currently, LLM reinforcement learning training mainly consists of two architectures: colocate and disaggregation. Colocate means training and inference share GPU resources and alternate GPU usage; disaggregation means training and inference are separated, each occupying different GPU devices. In both architectures, a crucial phase is parameter updates - after each training round ends, parameters need to be synchronized to the inference framework before rollout begins. If this phase takes too long, it causes GPUs to idle, preventing improved overall GPU utilization and resulting in significant losses to end-to-end training performance. Therefore, efficient parameter updates are a worthwhile optimization direction in RL training.Hugging Face update their excellent transformers library based on learnings from gpt-oss: Tricks from OpenAI gpt-oss YOU 🫵 can use with transformers
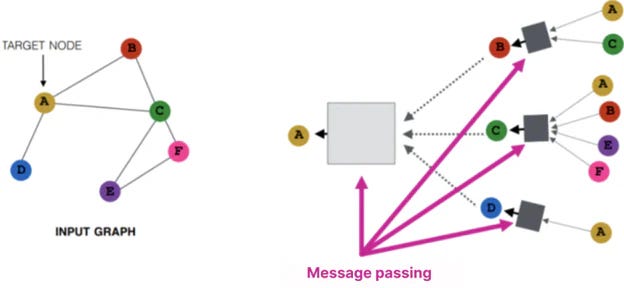
OpenAI recently released their GPT-OSS series of models. The models feature some novel techniques like MXFP4 quantization, efficient kernels, a brand new chat format, and more. To enable the release of gpt-oss through transformers, we have upgraded the library considerably. The updates make it very efficient to load, run, and fine-tune the models.Graphs! What Every Data Scientist Should Know About Graph Transformers and Their Impact on Structured Data
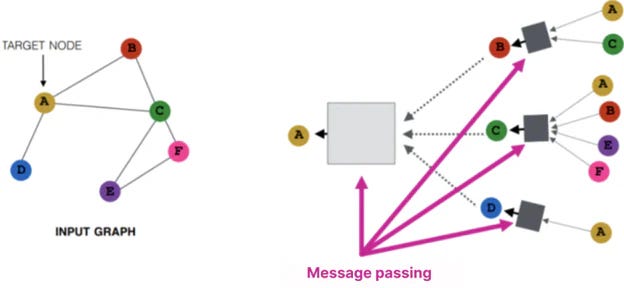
Speeding things up:
Pandas: More CUDA fun- How to Spot (and Fix) 5 Common Performance Bottlenecks in pandas Workflows
%load_ext cudf.pandas import pandas as pd df = pd.read_csv("data.csv")SQL- SQL performance improvements: finding the right queries to fix
$ touch /var/log/mysql-slow-query.log $ chown mysql:mysql /var/log/mysql-slow-query.log $ mysql mysql> SET GLOBAL slow_query_log_file = '/var/log/mysql-slow-query.log'; mysql> SET GLOBAL long_query_time = 1; mysql> SET GLOBAL slow_query_log = 'ON';Data Lakes: Data Lake Table Formats (Open Table Formats)
Geospatial- Building Vector Tiles from scratch
Now, I suspect this is the result of a few things: - As mentioned above, all of the embedded data is GeoJSON. This means the rendering library (MapLibre GL JS) needs to parse the JSON. There’s a lot, with a lot of properties, so this takes time. - MapLibre GL needs to then take the coordinates and then place the lines, points and polygons on the map accordingly. This takes time, and it all happens on your browser. I don’t like this - I want a map that people can use to check on the status of their city, and not a bloated HTML page that gets slower as more data gets onboarded, ironically making it less and less usable.

Bigger picture ideas
Longer thought provoking reads - sit back and pour a drink! ...
A.I.-Driven Education: Founded in Texas and Coming to a School Near You - NYTimes
At Alpha’s flagship, students spend a total of just two hours a day on subjects like reading and math, using A.I.-driven software. The remaining hours rely on A.I. and an adult “guide,” not a teacher, to help students develop practical skills in areas such as entrepreneurship, public speaking and financial literacy.Flooding the AI Frontier - Why is China Giving Away AI - Ben Turtel
One might be surprised to learn that not only are Chinese tech companies making AI models freely available, but the Chinese government has also promoted open models as part of its AI strategy. In July, China released its Global AI Governance Action Plan, heavy on “international public good,” “collaboration,” and “openness,” which sounds lovely until you remember that China maintains one of the most restrictive and censorious regions of the internet. So what gives? Why is the Chinese government suddenly a champion of openness in AI?How I got the highest score on ARC-AGI again swapping Python for English - Jeremy Berman
I think ARC-AGI is still the most important benchmark we have today. It’s surprising that LLMs can win the math olympiad but struggle with simple puzzles that humans can solve easily. This highlights a core limitation of current LLMs: they struggle to reason about things they weren't trained on. They struggle to generalize. But they are getting better, fast.The power of reinforcement learning
The Training Imperative - Surya Dantuluri

RL-as-a-Service will outcompete AGI companies (and that's good) - harsimony
Companies drive AI development today. There's two stories you could tell about the mission of an AI company: AGI: AI labs will stop at nothing short of Artificial General Intelligence. With enough training and iteration AI will develop a general ability to solve any (feasible) task. We can leverage this general intelligence to solve any problem, including how to make a profit. Reinforcement Learning-as-a-Service (RLaaS)[1]: AI labs have an established process for training language models to attain high performance on clean datasets. By painstakingly creating benchmarks for problems of interest, they can solve any given problem with RL leveraging language models as a general-purpose prior.
AI as teleportation - Geoffrey Litt
The year is 2035. The Auto Go Instant (AGI) teleporter has been invented. You can now go anywhere… instantly! At first the tech is expensive and unreliable. Critics laugh. “Hah, look at these stupid billionaires who can’t spend a minute of their time moving around like the rest of us. And 5% of the time they end up in the wrong place, LOL” But soon things get cheaper and better. The tech hits mass market.The 28 AI tools I wish existed - Sharif Shameem
... A recommendation engine that looks at my browsing history, sees what blog posts or articles I spent the most time on, then searches the web every night for things I should be reading that I’m not. In the morning I should get a digest of links ... A writing app that searches the web for the topic you’re writing about, then composes a “suggested reading” list based on what it thinks might be helpful for you to read. (Writing apps should never write for you.)On Working with Wizards - Ethan Mollick
I think this process is typical of the new wave of AI, for an increasing range of complex tasks, you get an amazing and sophisticated output in response to a vague request, but you have no part in the process. You don’t know how the AI made the choices it made, nor can you confirm that everything is completely correct. We're shifting from being collaborators who shape the process to being supplicants who receive the output. It is a transition from working with a co-intelligence to working with a wizard. Magic gets done, but we don’t always know what to do with the results. This pattern — impressive output, opaque process — becomes even more pronounced with research tasks.AI Artists vs. AI Engineers - Vikram Sreekanti and Joseph E. Gonzalez
As you all probably know, we’re big believers in the capabilities of LLMs. We’ve said more than once that if you paused all improvements in models — whether for regulatory reasons or because of technological limitations — we think there’s 5-10 years of innovation that’s left to be done simply in taking the existing technology and applying it to the many use cases that we haven’t yet thought of. If you’re building an AI application startup today, you very likely agree with us (though you would probably debate the number of years). However, even amongst people who are excited about AI, we’ve started to see two different approaches to the way more complex AI applications are being built. We’re calling these archetypes the AI Artist (give AI systems full creative control) and AI Engineer (operate under constraints to optimize for quality).

Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
The wonderful Math that powers Disney’s Animation
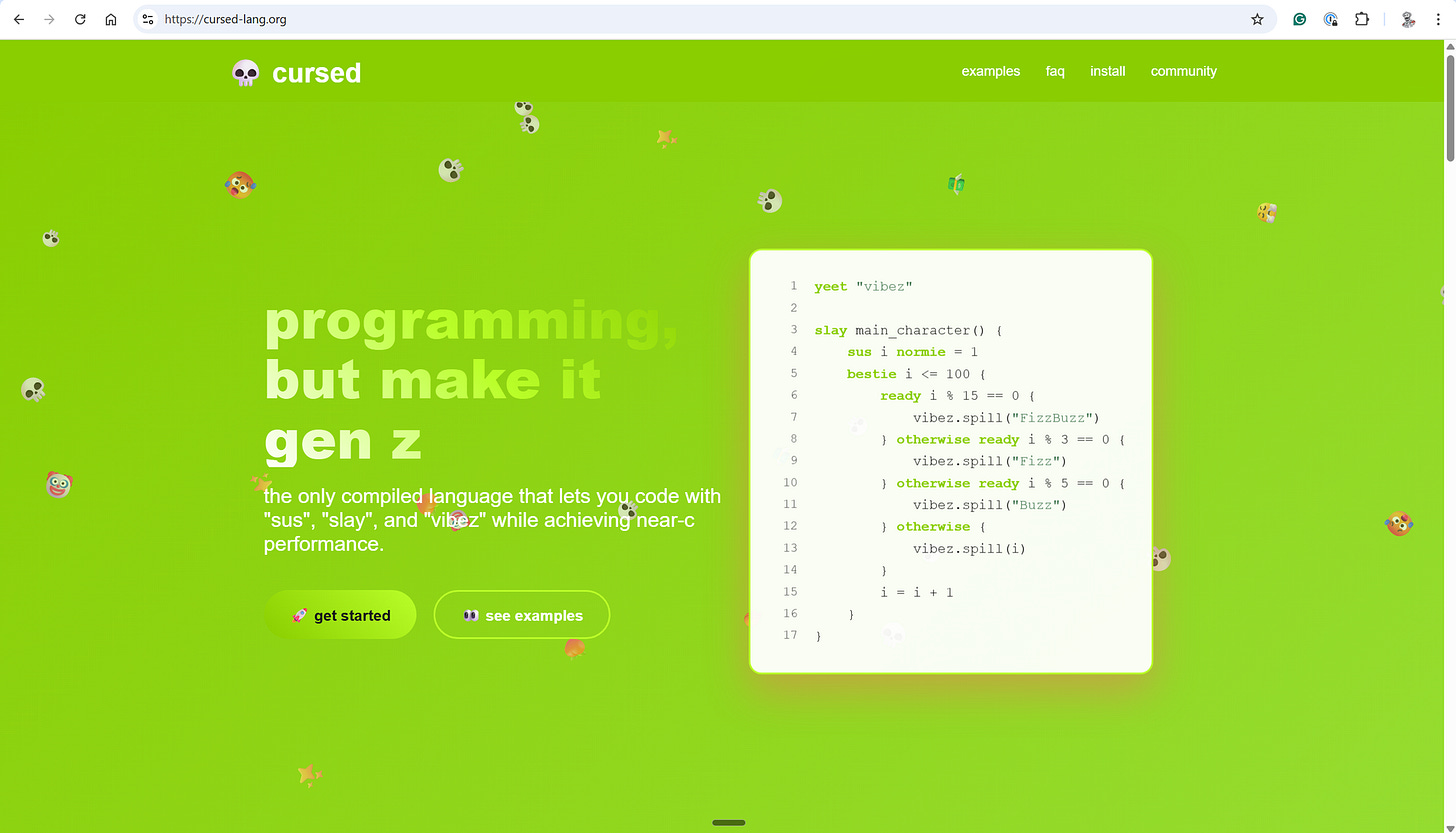
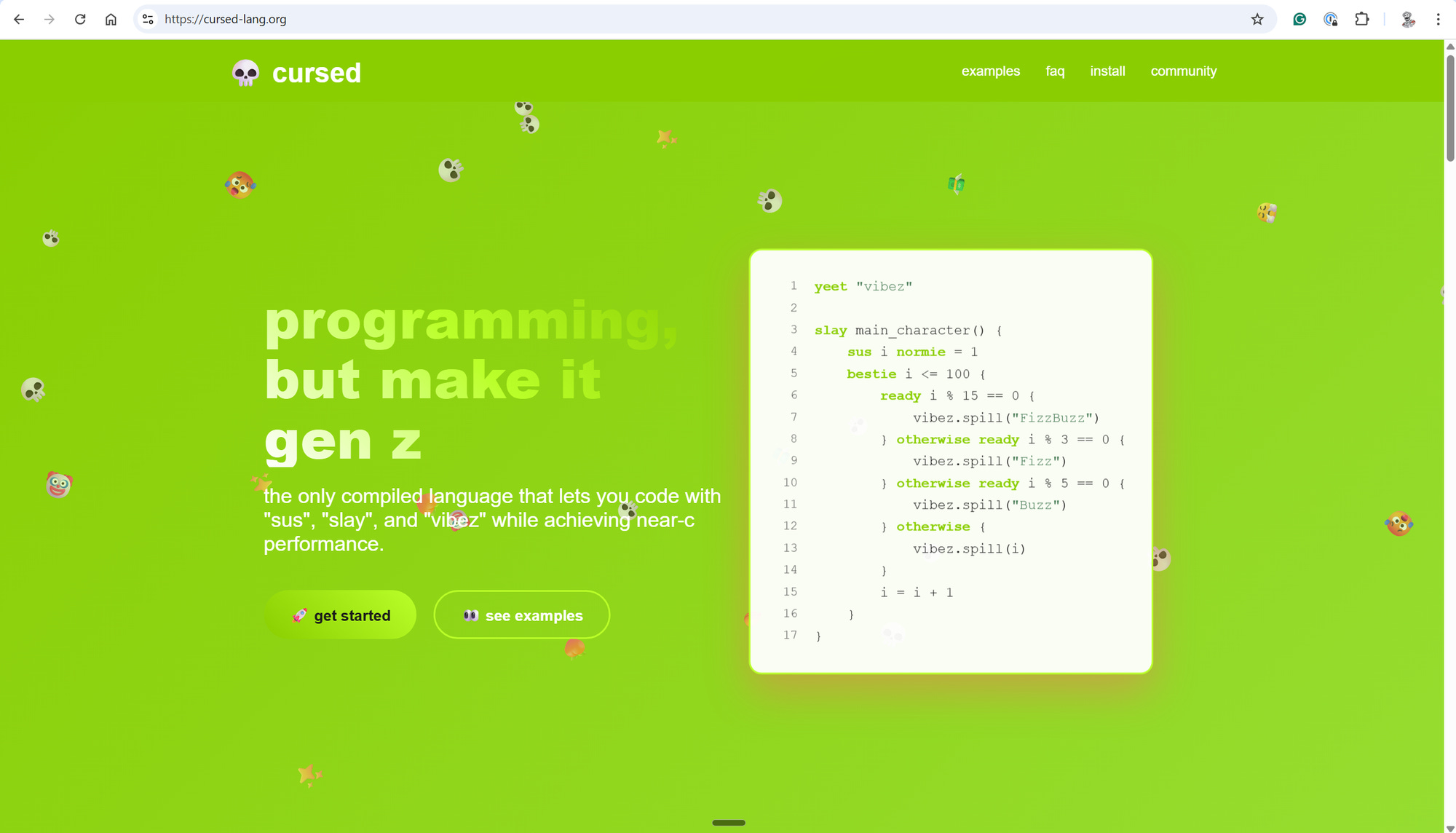
In my opinion, there is no more versatile material to model than snow. It is a material that can be both solid and fluid, both fluffy and dense. In addition, it is also a material that can be broken apart and fractured. The rewards for modelling snow artistically are great. I think that there is a deep emotional connection that humans have with winter. Winter can represent both joy and sadness, both the calm and the storm. For this reason, there is an incentive to model snow correctly from a storytelling point of view.i ran Claude in a loop for three months, and it created a genz programming language called cursed
Why Netflix Struggles To Make Good Movies: A Data Explainer
Released after a series of critically maligned movies and the sudden departure of film head Scott Stuber, The Electric State’s dismal reception prompted industry-wide confusion about the persistent shortcomings and broader purpose of Netflix's filmmaking efforts. How could so much money be spent in service of so many subpar movies?How sheer luck made this tiny Caribbean island millions from its web address
In its draft 2025 budget document, the Anguillian government says that in 2024 it earned 105.5m East Caribbean dollars ($39m; £29m) from selling domain names. That was almost a quarter (23%) of its total revenues last year. Tourism accounts for some 37%, according to the IMF. The Anguillian government expects its .ai revenues to increase further to 132m Eastern Caribbean dollars this year, and to 138m in 2026. It comes as more than 850,000 .ai domains are now in existence, up from fewer than 50,000 in 2020.
Updates from Members and Contributors
Kirsteen Campbell, Public Involvement and Communications Manager at UK Longitudinal Linkage Collaboration highlights the following which could be very useful for researchers: “UK Longitudinal Linkage Collaboration (UK LLC) announces new approvals from NHS providers and UK Government departments meaning linked longitudinal data held in the UK LLC Trusted Research Environment can now be used for a wide range of research in the public good. Read more: A new era for a wide range of longitudinal health and wellbeing research | UK Longitudinal Linkage Collaboration- Enquiries to: access@ukllc.ac.uk”
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
Alex Handy at NatureMetrics has some open ML/AI engineer roles which look interesting (NatureMetrics is a pioneering company that uses environmental DNA analysis and AI to provide biodiversity insights, helping organisations measure and manage their impact on nature. Backed by ambitious investors and as Earthshot Prize 2024 finalists, we're on a mission to make biodiversity measurable at scale and have the opportunity to change the way organisations operate.).
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS