

Hi everyone-
Hope you all enjoyed the recent Easter weekend, and are managing to avoid thinking too hard about the current geopolitical turmoil… Definitely time for some distraction with a deep dive into all things Data Science and AI… Lots of great reading materials below and I really encourage you to read on, but here are the edited highlights if you are short for time! (some particularly good longer reads this month)
Will AI R&D Automation Cause a Software Intelligence Explosion? - Forethought
AI 2027- D. Kokotajlo, S. Alexander, T. Larsen, E. Lifland, R. Dean
On Jagged AGI: o3, Gemini 2.5, and everything after - Ethan Mollick
The artifact isn’t the art: Rethinking creativity in the age of AI - Ashish Bhatia
Welcome to the Era of Experience - David Silver
Following is the May edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
The RSS has a new open access journal! - RSS: Data Science and Artificial Intelligence.

It offers an exciting venue for your work in these disciplines with a broad reach across statistics, machine learning, deep learning, econometrics, bioinformatics, engineering, computational social sciences. The journal is peer reviewed by editors esteemed in their field and is open to submission. Discover more about why the new journal is the ideal platform for showcasing your
Work continues within the RSS AI Task Force progressing the support for the RSS on communications, evaluation, policy, and needs of practitioners. Many thanks for the emails sent after last month's newsletter - the Task Force are still working through them. If you would like to engage directly with the task force, then please do email at aitf@rss.org.uk
It’s not too late to submit a talk or poster to the RSS 2025 conference!
Martin Goodson, CEO and Chief Scientist at Evolution AI, continues to run the excellent London Machine Learning meetup and is very active with events. The last event was on Wednesday, April 16th when Max Bartolo, Researcher at Cohere, gave a great presentation- Building Robust Enterprise-Ready Large Language Models - followed by a thought provoking question and answer session. Videos are posted on the meetup youtube channel.

This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
What will life look like as governments, corporations and society in general embrace AI?
Interesting to look to China to see how far things have gone already: Humanoid workers and surveillance buggies: ‘embodied AI’ is reshaping daily life in China

AI is already affecting business models: As AI Takes His Readers, A Leading History Publisher Wonders What’s Next
“There used to be this implicit agreement between publishers and Google that basically, Google could scrape, analyze, process, and do whatever they wanted with publishers’ content and in return, they would send traffic to the publishers, send them readers,” he told me. “Now, this unspoken contract is kind of breaking.”And changing what we listen to: AI-generated music accounts for 18% of all tracks uploaded to Deezer
Students are definitely embracing AI- Anthropic Education Report: How University Students Use Claude

And many people are forming relationships with Chatbots
"Many respondents said they used chatbots to help them manage different aspects of their lives, from improving their mental and physical health to advice about existing romantic relationships and experimenting with erotic role play. They can spend between several hours a week to a couple of hours a day interacting with the apps."
As we have discussed in previous editions, the ongoing copyright saga regarding the data used to train Foundation Models used in AI is still far from resolved: OpenAI’s models ‘memorized’ copyrighted content, new study suggests
"The co-authors probed several OpenAI models, including GPT-4 and GPT-3.5, for signs of memorization by removing high-surprisal words from snippets of fiction books and New York Times pieces and having the models try to “guess” which words had been masked. If the models managed to guess correctly, it’s likely they memorized the snippet during training, concluded the co-authors."And certainly the costs of generating the training data and who pays is becoming more contentious
"Costs of Wikipedia infrastructure have grown by 50% since January 2024 due to bots and AI scrapers. 65% of our most expensive traffic comes from bots, a disproportionate amount given that bot pageviews account for around 1/3 of the total."The leading AI providers are very keen to reassure us all that they are doing everything they can to make the models as safe as they can be:
Google and DeepMind:
OpenAI
Our updated Preparedness Framework
"This update introduces a sharper focus on the specific risks that matter most, stronger requirements for what it means to “sufficiently minimize” those risks in practice, and clearer operational guidance on how we evaluate, govern, and disclose our safeguards."
Anthropic
But is that really the case?
Google is shipping Gemini models faster than its AI safety reports
"But the ramped-up release time frame appears to have come at a cost. Google has yet to publish safety reports for its latest models, including Gemini 2.5 Pro and Gemini 2.0 Flash, raising concerns that the company is prioritizing speed over transparency."OpenAI slashes AI model safety testing time
OpenAI has reduced the time and resources allocated to safety testing its most powerful artificial intelligence (AI) models, sparking internal and external concern that its latest releases are being rushed without adequate safeguards. ... “We had more thorough safety testing when [the technology] was less important,” said one current evaluator, calling the process “a recipe for disaster.”
Military use of AI continues to progress- Generative AI is learning to spy for the US military
And AI driven Cyberattacks are an increasing threat:
Cyberattacks by AI agents are coming
"Agents are also significantly smarter than the kinds of bots that are typically used to hack into systems. Bots are simple automated programs that run through scripts, so they struggle to adapt to unexpected scenarios. Agents, on the other hand, are able not only to adapt the way they engage with a hacking target but also to avoid detection—both of which are beyond the capabilities of limited, scripted programs, says Volkov"So good news that Google is launching specialist models designed to counter this threat: Google announces Sec-Gemini v1, a new experimental cybersecurity model



Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
We still struggle to really understand the inner workings of the current Foundation models- no surprising when they have billions of individual weights. Interesting research from Anthropic to try and dig into the underlying behaviour: Circuit Tracing: Revealing Computational Graphs in Language Models

Still lots of work going on trying to make the training and inference process more efficient
This is intriguing: taking a leaf out of the humble fruit-fly to embed positional relationships as complex weights (“spin”)- Comply: Learning Sentences with Complex Weights inspired by Fruit Fly Olfaction
"Biologically inspired neural networks offer alternative avenues to model data distributions. FlyVec is a recent example that draws inspiration from the fruit fly's olfactory circuit to tackle the task of learning word embeddings. Surprisingly, this model performs competitively even against deep learning approaches specifically designed to encode text, and it does so with the highest degree of computational efficiency"Microsoft Research pushing the boundaries of quantisation with their new (fully open weight) 1-bit release (all weights are simple binary values, 1 or 0!)- BitNet b1.58 2B4T Technical Report (more here)
"We introduce BitNet b1.58 2B4T, the first open-source, native 1-bit Large Language Model (LLM) at the 2-billion parameter scale. Trained on a corpus of 4 trillion tokens, the model has been rigorously evaluated across benchmarks covering language understanding, mathematical reasoning, coding proficiency, and conversational ability. Our results demonstrate that BitNet b1.58 2B4T achieves performance on par with leading open-weight, full-precision LLMs of similar size, while offering significant advantages in computational efficiency, including substantially reduced memory footprint, energy consumption, and decoding latency."An open source approach to “adding reasoning” to any model: Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
"Through extensive experiments, we demonstrate that a minimalist approach, vanilla PPO with GAE (λ=1, γ=1) and straightforward rule-based rewards, without any KL regularization, is sufficient to scale up both response length and benchmark performance, similar to the phenomenon observed in DeepSeek-R1-Zero."And more progress on improving inference-time efficiency from DeepSeek: Inference-Time Scaling for Generalist Reward Modeling
"A key challenge of RL is to obtain accurate reward signals for LLMs in various domains beyond verifiable questions or artificial rules. In this work, we investigate how to improve reward modeling (RM) with more inference compute for general queries, i.e. the inference-time scalability of generalist RM, and further, how to improve the effectiveness of performance-compute scaling with proper learning methods."We now have examples of training performant models on non-Nvidia hardware (Ascend NPUs are made by Huawei in China): Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
"We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). ... Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters."And now also examples of distributed training: INTELLECT-2: Launching the First Globally Distributed Reinforcement Learning Training of a 32B Parameter Model
"With the release of OpenAI's O1 and DeepSeek's R1, a second scaling paradigm beyond pre-training emerged last year—one that allows models to spend more time reasoning, optimized through reinforcement learning. In our previous release, we argued why we believe these reasoning models, trained via reinforcement learning, are even better suited for decentralized training approaches than standard LLM pre-training. Today, we are proving this with INTELLECT-2."
Just as popular on the research front are narrower specialised applications, driving up performance in specific fields and tasks
debug-gym: A Text-Based Environment for Interactive Debugging
"Large Language Models (LLMs) are increasingly relied upon for coding tasks, yet in most scenarios it is assumed that all relevant information can be either accessed in context or matches their training data. We posit that LLMs can benefit from the ability to interactively explore a codebase to gather the information relevant to their task. To achieve this, we present a textual environment, namely debug-gym, for developing LLM-based agents in an interactive coding setting."AI masters Minecraft: DeepMind program finds diamonds without being taught
Increasing understanding of the animal kingdom…
MouseGPT: A Large-scale Vision-Language Model for Mouse Behavior Analysis
"Here, we introduce MouseGPT, a Vision-Language Model (VLM) that integrates visual cues with natural language to revolutionize mouse behavior analysis. Built upon our first-of-its-kind dataset—incorporating pose dynamics and open-vocabulary behavioral annotations across over 42 million frames of diverse psychiatric conditions—MouseGPT provides a novel, context-rich method for comprehensive behavior interpretation. Our holistic analysis framework enables detailed behavior profiling, clustering, and novel behavior discovery, offering deep insights without the need for labor-intensive manual annotation."DolphinGemma: How Google AI is helping decode dolphin communication
A foundation model for geospatial inference
"In continued pursuit of this objective, today we are pleased to introduce a novel geospatial foundation model, built on aggregated data to preserve privacy, which we describe in “General Geospatial Inference with a Population Dynamics Foundation Model”. We designed the model (referred to as PDFM) so users could easily fine-tune it to a wide variety of downstream tasks. We are also releasing a dataset of unique location embeddings derived from the PDFM and code recipes users can employ to enhance their existing geospatial models. The dataset and code recipes aim to provide insights that can be applied to machine learning (ML) problems that rely on an understanding of populations and the characteristics of their local environments. They are easily adapted to many data science questions, enabling a more holistic and nuanced understanding of population dynamics around the world."IMAGGarment-1: Fine-Grained Garment Generation for Controllable Fashion Design

I find DeepMinds’ AlphaGeometry absolutely amazing: Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2
"We present AlphaGeometry2, a significantly improved version of AlphaGeometry introduced in Trinh et al. (2024), which has now surpassed an average gold medalist in solving Olympiad geometry problems. To achieve this, we first extend the original AlphaGeometry language to tackle harder problems involving movements of objects, and problems containing linear equations of angles, ratios, and distances. This, together with support for non-constructive problems, has markedly improved the coverage rate of the AlphaGeometry language on International Math Olympiads (IMO) 2000-2024 geometry problems from 66% to 88%."To end with, do we finally have competitors to my favourite tree based approaches for small tabular data? Accurate predictions on small data with a tabular foundation model - I’m definitely going to have a play with this one
"Although deep learning has revolutionized learning from raw data and led to numerous high-profile success stories3,4,5, gradient-boosted decision trees6,7,8,9 have dominated tabular data for the past 20 years. Here we present the Tabular Prior-data Fitted Network (TabPFN), a tabular foundation model that outperforms all previous methods on datasets with up to 10,000 samples by a wide margin, using substantially less training time. In 2.8 s, TabPFN outperforms an ensemble of the strongest baselines tuned for 4 h in a classification setting. As a generative transformer-based foundation model, this model also allows fine-tuning, data generation, density estimation and learning reusable embeddings."


Generative AI ... oh my!
Still moving at such a fast pace it feels in need of it's own section, for developments in the wild world of large language models...
OpenAI continues to churn out an impressive array of news and updates
Cash shouldn’t be a worry, certainly, having just raised a further $40b at a $300b valuation. And they certainly have huge traction: the most downloaded app globally in March, with a billion weekly users
They released more new models: o3 and o4-mini with full tool access. Interesting assessment here from Simon Wilison, and also from ARC prize
New image reasoning capabilities: Thinking with images (and also in the API)
As well as a new series of GPT models: Introducing GPT-4.1 in the API (although rather confusingly they are phasing out GPT-4.5…)
And the arch commercial provider is apparently considering open source
Google keeps up the pace
Lots of product news:
Along with their latest model
It currently (late April) sits at the top of the Chatbot Arena and is getting pretty glowing reviews
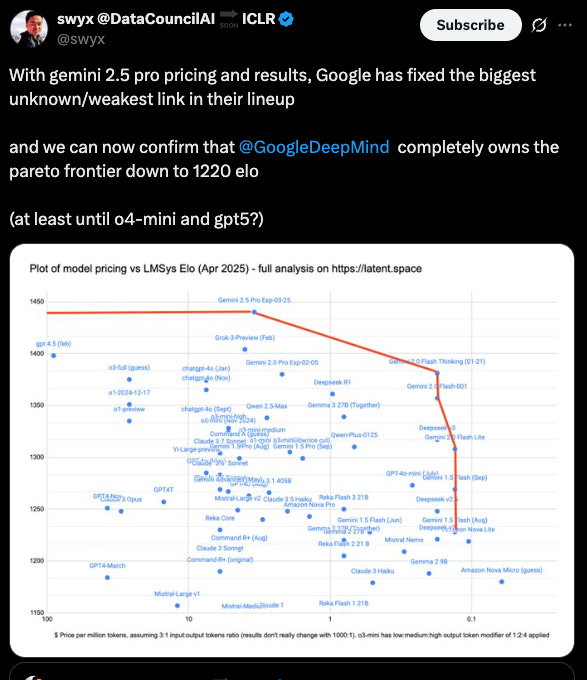
In fact Google now seems to have the most cost effective models at all the different performance points

This is quite a turnaround from the earlier days of LLMs when Google was thought to be a laggard
"That left some tech giants, including Google, behind the curve. The breakthrough research paper on the transformer architecture that underpins large language models came from Google in 2017, yet the company is often remembered more for its botched launch of Bard in 2023 than for its innovative AI research. But strong new LLMs from Google, and misfires from Meta and OpenAI, are shifting the vibe."
Microsoft is launching an AI Companion and relaunching the controversial Recall product (which takes screenshots of your computer at regular intervals)
Anthropic launched a $200 a month version of Claude, as well as their offering in the “Deep Research” space, integrated into Google Workspace
And Amazon released some new models: Nova Act (with browser based tools), Nova Sonic (speech to speech) and Nova Reel (multi-shot videos)
Meta was also busy
They released several useful new open source building blocks for LLMs
And updated their Llama family of models to Llama 4, their first natively multimodal models and their first Mixture of Experts architecture (more info here)

Useful deep dive here from Devansh
Mistral continued to released more specialised offerings- Classifier Factory - allowing clients to streamline building custom classification models
And as always lots going on in the world of open source
Hot off the press, DeepSeek have released R2
"DeepSeek-R2 represents more than just another AI model—it signals China's growing confidence and capability in developing frontier AI technologies that can compete on the global stage. With its innovative training techniques, emphasis on efficiency, and focus on multilingual capabilities, DeepSeek-R2 addresses several limitations of current leading models."And they have been true to their open source principles and have released a lot of background on their architecture and engineering set up: The Path to Open-Sourcing the DeepSeek Inference Engine
"A few weeks ago, during Open Source Week, we open-sourced several libraries. The response from the community has been incredibly positive - sparking inspiring collaborations, productive discussions, and valuable bug fixes. Encouraged by this, we’ve decided to take another step forward: contributing our internal inference engine back to the open-source community."Another excellent released from the Allen Institute, this time a tool to identify which pretraining data will be most important: DataDecide
 scale of models pretrained from scratch on those datasets.")
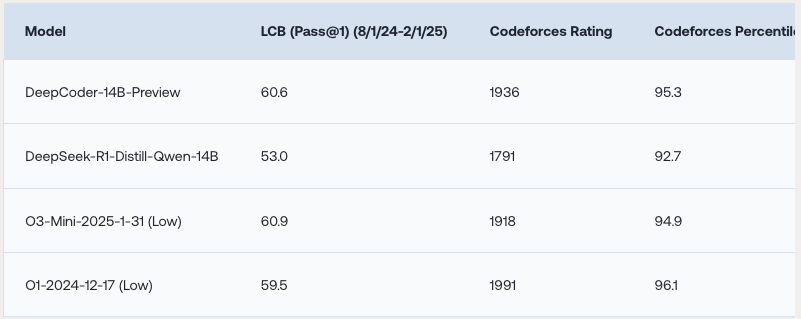
An open source AI code assistant from together.ai: DeepCoder: A Fully Open-Source 14B Coder at O3-mini Level

And if you are feeling the need to create your own reasoning-style foundation model…:
Here’s the training data to use from Bespoke Labs
Here’s a library to do the reinforcement learning locally! nanoAhaMoment: Single File "RL for LLM" Library
And here’s how you can run it locally: prima.cpp

 scale of models pretrained from scratch on those datasets.")
Real world applications and how to guides
Lots of applications and tips and tricks this month
Some interesting practical examples of using AI capabilities in the wild
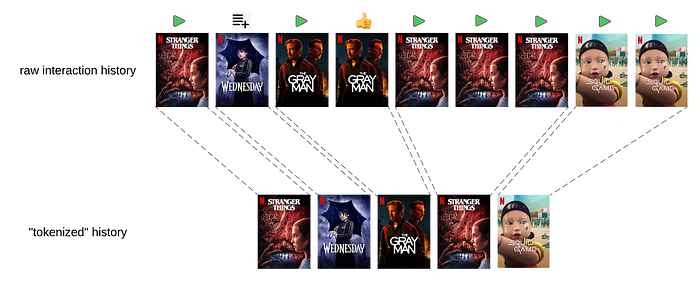
Netflix talking about how they now use LLMs to help personalise their recommendations: Foundation Model for Personalized Recommendation. Elegant stuff- adapting the structure of content interactions so they can be used in the semi-supervised “next-token prediction” context.
Customer service seems to be at the forefront of AI applications: Wells Fargo’s AI assistant just crossed 245 million interactions – no human handoffs, no sensitive data exposed
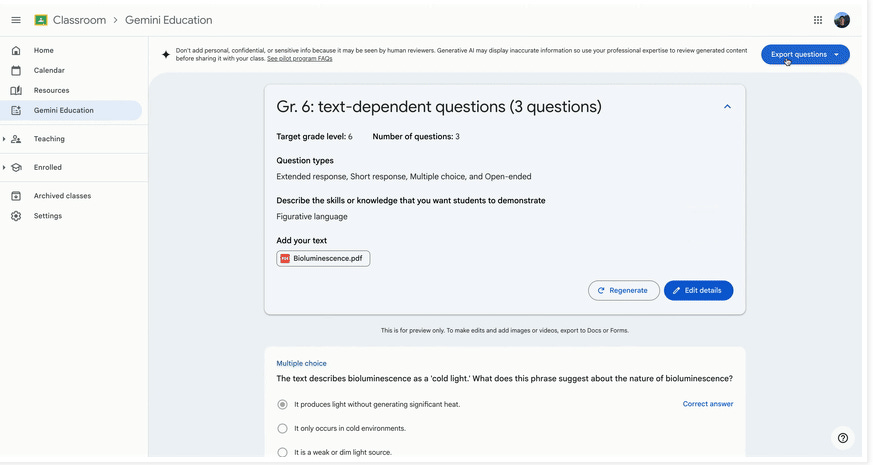
"The system works through a privacy-first pipeline. A customer interacts via the app, where speech is transcribed locally with a speech-to-text model. That text is then scrubbed and tokenized by Wells Fargo’s internal systems, including a small language model (SLM) for personally identifiable information (PII) detection. Only then is a call made to Google’s Flash 2.0 model to extract the user’s intent and relevant entities. No sensitive data ever reaches the model."Teachers using Google Gemini to generate questions or quizzes for the classroom
Earth AI’s algorithms found critical minerals in places everyone else ignored
"“The actual, real frontier [in mining] is not so much geographical as it is technological,” Roman Teslyuk, founder and CEO of Earth AI, told TechCrunch. Earth AI has identified deposits of copper, cobalt, and gold in the Northern Territory and silver, molybdenum, and tin at another site in New South Wales, 310 miles (500 kilometers) northwest of Sydney."
Lots of great tutorials and how-to’s this month
AI Code assistants are proving popular, but are not straightforward to use- some best practices from Anthropic for using their new Claude Code
An excellent resource if you are looking to work with voice applications: Voice AI and Voice Agents
"Building production-ready voice agents is complicated. Many elements are non-trivial to implement from scratch. If you build voice AI apps, you'll likely rely on a framework for many of the things discussed in this document. But we think it's useful to understand how the pieces fit together, whether you are building them all from scratch or not."Some insight from Google on how they gave been building various AI products:
If you’ve always wanted to dig into Graph based approaches but never known where to start…. this is where to start! The evolution of graph learning
"The story of graph theory begins in 1736 with famed mathematician Leonhard Euler, who wondered if one could walk through the city of Königsberg in Prussia (now Kaliningrad, Russia) and cross each of its seven bridges without crossing any of them more than once. In proving that there was no valid solution given this crossing constraint, Euler developed the foundations of modern graph theory. His simple question about bridge crossings is now recognized as one of the famous mathematical problems — the “Seven Bridges of Königsberg” problem."Crash course in Monte Carlo simulation, starting with a good review of Continuous Probability
Getting a bit more hard core - An Introduction to Stochastic Calculus
Which leads nicely into a Visual Exploration of Gaussian Processes

Good primer on a key workhorse of search- the BM25 algorithm
"First introduced in 1994, BM25 eventually made its way into popular search engines like Apache Lucene and has been powering search bars across the internet for decades. Because it works well with keyword search engines, BM25 is efficient to compute over massive datasets. It also performs well in diverse settings, providing good out-of-the-box ranking in a variety of domains like site search, legal search, and more."I’ve always found operations and simulations elegant- how you can build up complex use cases from relatively simply assumptions. Good introduction to queuing theory

A dive into model interpretation: SHAP Interpretations Depend on Background Data — Here’s Why
"Estimating Shapley values requires a background dataset for sampling. The key idea behind Shapley values is that features act as a "team," and the prediction is fairly distributed among them. The algorithm computes what predictions different coalitions (subsets of features) would receive. Since most ML models require all features to be filled in, missing values are sampled from the background data. However, the background data is not just a technical necessity—it fundamentally changes how we interpret SHAP values."




Practical tips
How to drive analytics, ML and AI into production
Orchestration and automation are so important to modern data systems: 4 Levels of GitHub Actions: A Guide to Data Workflow Automation

We often talk about transactions… but what are they really? Decomposing Transactional Systems
"Spanner is a bit more complicated, partly because lock-related operations involved in transaction validation are stretched across the whole text. It also tries to trick you by talking about details out of execution order, so make sure to always read closely for "then" to give hints on the ordering of the steps."Some engineering insight from DeepSeek: An Intro to DeepSeek's Distributed File System



Bigger picture ideas
Longer thought provoking reads - sit back and pour a drink! ...
A few takes on the current state of AI and what it might look like in the future
The 2025 AI Index Report - HAI, Stanford University
"From healthcare to transportation, AI is rapidly moving from the lab to daily life. In 2023, the FDA approved 223 AI-enabled medical devices, up from just six in 2015. On the roads, self-driving cars are no longer experimental: Waymo, one of the largest U.S. operators, provides over 150,000 autonomous rides each week, while Baidu’s affordable Apollo Go robotaxi fleet now serves numerous cities across China."A well thought through if scary view on what the next few years might look like: AI 2027 - Daniel Kokotajlo, Scott Alexander, Thomas Larsen, Eli Lifland, Romeo Dean
"With Agent-1’s help, OpenBrain is now post-training Agent-2. More than ever, the focus is on high-quality data. Copious amounts of synthetic data are produced, evaluated, and filtered for quality before being fed to Agent-2.42 On top of this, they pay billions of dollars for human laborers to record themselves solving long-horizon tasks.43 On top of all that, they train Agent-2 almost continuously using reinforcement learning on an ever-expanding suite of diverse difficult tasks: lots of video games, lots of coding challenges, lots of research tasks. Agent-2, more so than previous models, is effectively “online learning,” in that it’s built to never really finish training. Every day, the weights get updated to the latest version, trained on more data generated by the previous version the previous day."And another excellent piece more specifically about when and how AI gets to the stage when it can improve itself: Will AI R&D Automation Cause a Software Intelligence Explosion? - Forethought. Interestingly OpenAI have just released a new benchmark on this topic
"AI companies are increasingly using AI systems to accelerate AI research and development. These systems assist with tasks like writing code, analyzing research papers, and generating training data. While current systems struggle with longer and less well-defined tasks, future systems may be able to independently handle the entire AI development cycle – from formulating research questions and designing experiments, to implementing, testing, and refining new AI systems. Some analysts have argued that such systems, which we call AI Systems for AI R&D Automation (ASARA), would represent a critical threshold in AI development. The hypothesis is that ASARA would trigger a runaway feedback loop: ASARA would quickly develop more advanced AI, which would itself develop even more advanced AI, resulting in extremely fast AI progress – an “intelligence explosion.”
ASI existential risk: reconsidering alignment as a goal - Michael Nielsen
"Why is there such strong disagreement between well-informed people, on an issue so crucial for humanity? An explanation I often hear is that it's due to differences in short-term self-interest – this is sometimes coarsely described as the xrisk-concerned wanting publicity or making money through safety not-for-profits, while the xrisk-skeptics want to get richer and more powerful through control of AGI. But while those explanations are convenient, they're too glib. Many prominent people concerned about xrisk are making large financial sacrifices, sometimes forgoing fortunes they could make working toward ASI, in favour of merely well-paid work on safety7. And while it's true xrisk-skeptics have an incentive to make money and acquire power, they have far more interest in remaining alive. I believe the disagreement is due primarily to sincerely held differences in underlying assumptions. In this text we'll try to better understand those differences."More good stuff from Ethan Mollick:
On Jagged AGI: o3, Gemini 2.5, and everything after
"First, a little context. Over the past couple of weeks, two new AI models, Gemini 2.5 Pro from Google and o3 from OpenAI were released. These models, along with a set of slightly less capable but faster and cheaper models (Gemini 2.5 Flash, o4-mini, and Grok-3-mini), represent a pretty large leap in benchmarks."No elephants: Breakthroughs in image generation
"Multimodal image generation, on the other hand, lets the AI directly control the image being made. While there are lots of variations (and the companies keep some of their methods secret), in multimodal image generation, images are created in the same way that LLMs create text, a token at a time. Instead of adding individual words to make a sentence, the AI creates the image in individual pieces, one after another, that are assembled into a whole picture. This lets the AI create much more impressive, exacting images."
MCP - It's Hot, But Will It Win? - Steven Sinofsky
"MCP is quite definitionally the classic middleware playbook. That it was introduced by one of the key leaders in the field is itself a classic aspect of the middleware playbook. The industry has a long history of middleware. Many might not recall or even know, but the initial Dept. of Justice antitrust case against Microsoft was all about middleware and at the time the browser itself was viewed as middleware, as was Java.”Some great advice on evaluating GenAI applications - Andrew Ng
"I encourage you to approach building evals differently. It’s okay to build quick evals that are only partial, incomplete, and noisy measures of the system’s performance, and to iteratively improve them. They can be a complement to, rather than replacement for, manual evaluations. Over time, you can gradually tune the evaluation methodology to close the gap between the evals’ output and human judgments."The artifact isn’t the art: Rethinking creativity in the age of AI - Ashish Bhatia
"This is the aspect of creativity that AI lacks. It doesn’t feel tension. It doesn’t labor through ambiguity. It doesn’t explore. Where AI can offer 10 answers to a problem instantly, humans may wrestle for years to arrive at one — but it could be the only one that matters."
Welcome to the Era of Experience - David Silver


Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
Calendar heatmaps! You know you want to…

A love letter to the humble csv format!
"Every month or so, a new blog article declaring the near demise of CSV in favor of some "obviously superior" format (parquet, newline-delimited JSON, MessagePack records etc.) find its ways to the reader's eyes. Sadly those articles often offer a very narrow and biased comparison and often fail to understand what makes CSV a seemingly unkillable staple of data serialization."Still 2 months to go to win the $1m Konwinski Prize…
"I'm Andy, and I’m giving $1M to the first team that exceeds 90% on a new version of the SWE-bench benchmark containing GitHub issues we collect after we freeze submissions. I want to see what a contamination-free leaderboard looks like. Your challenge is to build an AI that crushes this yet-to-be-collected set of SWE-bench issues."
Updates from Members and Contributors
Hilary Till highlights what looks like an interesting event - AI/ML in Finance, Shaping the Future of Financial Markets at the London School of Economics on Tuesday 24th June at 5.45pm. Register for free here. Confirmed speakers include:
Giovanni Beliossi – Head of Investment Strategies at Axyon AI, UK
Petter Kolm – Professor at NYU Courant Institute of Mathematical Sciences, USA
Hilary Till – Principal at Premia Research, USA; Bretton Woods Committee AI Working Group Member; & Fellow, Royal Statistical Society
Arthur Turrell, Senior Manager Research and Data at the Bank of England, has another great blog post, this time on his new smartrappy Python package- which looks very useful for understanding dependencies in projects
Kevin O’Brien highlights the upcoming PyData London 2025 conference
“PyData London has always been a premier gathering for data science professionals, engineers, researchers, and enthusiasts who want to explore the latest developments in machine learning, AI, and open-source analytics. This year’s schedule is packed with insightful talks, hands-on tutorials, and exciting networking opportunities designed to inspire, educate, and connect.
📅 Conference Dates:
🔹 Tutorials Day: Friday, 6th June 2025
🔹 Talks & Workshops: Saturday, 7th June – Sunday, 8th June 2025
🚀 Website: PyData London | 2025”
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
Exciting new Head of Data Science opportunity at biomodal to lead the Computational Biology / Data Science efforts. Application and details here
“It's an exciting time for us, with the first peer-reviewed publication using our 6-base sequencing technology appearing in Nature Structural & Molecular Biology in April, with more to follow. We are just getting started in understanding the translational utility of 6-base genomics and there is plenty of interesting, innovative analysis method development work required to get us there. The role can be based in Cambridge (Chesterford Research Park) or London (Vauxhall)”
Interesting new role - at Prax Value (a dynamic European startup at the forefront of developing solutions to identify and track 'enterprise intelligence'): Applied Mathematics Engineer
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS