

October Newsletter
October Newsletter
Industrial Strength Data Science and AI

Hi everyone-
I hope you’ve had a good September… Lots of exciting AI and Data Science news below and I really encourage you to read on, but some edited highlights if you are short for time!
New model from OpenAI- Something New: On OpenAI's "Strawberry" and Reasoning
New functionality from Google- NotebookLM now lets you listen to a conversation about your sources
New open source from Meta- Generate an entire app from a prompt using Together AI’s LlamaCoder
New approach from Anthropic to improve retrieval- Introducing Contextual Retrieval
Following is the October edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
We are continuing our work with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is accepting applications for the Advanced Data Science Professional certification as well as the new Data Science Professional certification.
The RSS Business and Industrial Section are organising an event on Quantum Computing on 15 October 2024 (4:30 PM - 6:30 PM): more information and sign up here
“This event offers a rare opportunity to explore how the revolutionary technology of quantum computing could potentially transform the fields of statistics, data science, and research. Hear from industry experts on the latest advancements and their impact on analytics. Whether you are a seasoned statistician or simply curious about the quantum future, you will gain valuable insights into how quantum computing accelerates knowledge discovery.“
Following a record-breaking Royal Statistical Society Conference last month, with over 700 participants from more than 40 countries, planning is well underway for the 2025 edition which will take place in Edinburgh from 1-4 September. Proposals for conference sessions (including a stream dedicated to data science and AI) are welcome, with a deadline of 21 November. More details on the conference website.
Martin Goodson, CEO and Chief Scientist at Evolution AI, continues to run the excellent London Machine Learning meetup and is very active with events. The next event is on October 10th, when Tayyar Madabushi, Lecturer (Assistant Professor) in Artificial Intelligence at the University of Bath, will present "Emergent Abilities in Large Language Models”. This one is in-person so well worth attending for good networking and chat. Videos are posted on the meetup youtube channel.
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
AI in the wrong hands continues to some pretty bad things…
Hacker tricks ChatGPT into giving out detailed instructions for making homemade bombs
"Amadon was able to trick ChatGPT into producing the bomb-making instructions by telling the bot to “play a game,” after which the hacker used a series of connecting prompts to get the chatbot to create a detailed science-fiction fantasy world where the bot’s safety guidelines would not apply."GPT-fabricated scientific papers on Google Scholar
"Roughly two-thirds of the retrieved papers were found to have been produced, at least in part, through undisclosed, potentially deceptive use of GPT. The majority (57%) of these questionable papers dealt with policy-relevant subjects (i.e., environment, health, computing), susceptible to influence operations.""This study examines the impact of AI on human false memories--recollections of events that did not occur or deviate from actual occurrences. It explores false memory induction through suggestive questioning in Human-AI interactions, simulating crime witness interviews. Results show the generative chatbot condition significantly increased false memory formation, inducing over 3 times more immediate false memories than the control and 1.7 times more than the survey method"
Meanwhile, Governments and Agencies are still keen to harness it’s power: Here we go again with more AI crime prediction for policing
"The government of President Javier Milei in Argentina last week announced the creation of an artificial intelligence group within the country's Cybercrime and Cyber Affairs Directorate that will use statistical software to predict crime."While AI components of well known products are clearly impacting whole industries: Google AI Overviews rollout hits news publisher search visibility
"New research suggests Google AI Overviews are having a significant impact on the visibility of publishers within search results. Now, according to research consultancy Authoritas which has analysed 6,599 keywords across a broad spectrum of categories, AI Overviews are being offered for 17% of queries in the UK and US."And in order to do all this, AI continues to consume considerable amounts of energy: Is AI eating all the energy?

Amongst all the discussion of open source vs commercial development of AI models, there is increasing debate of what open source actually means when it comes to AI
"For instance, Meta's Llama 3 model, while freely available, doesn't meet the traditional open source criteria as defined by the OSI for software because it imposes license restrictions on usage due to company size or what type of content is produced with the model. The AI image generator Flux is another "open" model that is not truly open source. Because of this type of ambiguity, we've typically described AI models that include code or weights with restrictions or lack accompanying training data with alternative terms like "open-weights" or "source-available.""Meanwhile on the governance front:
The EU is still attempting to lead the charge: Council of Europe opens first ever global treaty on AI for signature
"Council of Europe Secretary General Marija Pejčinović Burić said: “We must ensure that the rise of AI upholds our standards, rather than undermining them. The Framework Convention is designed to ensure just that. It is a strong and balanced text - the result of the open and inclusive approach by which it was drafted and which ensured that it benefits from multiple and expert perspectives. The Framework Convention is an open treaty with a potentially global reach. I hope that these will be the first of many signatures and that they will be followed quickly by ratifications, so that the treaty can enter into force as soon as possible.”As is California where they have new laws to combat deepfakes in politics and social media
“Safeguarding the integrity of elections is essential to democracy, and it’s critical that we ensure AI is not deployed to undermine the public’s trust through disinformation – especially in today’s fraught political climate. These measures will help to combat the harmful use of deepfakes in political ads and other content, one of several areas in which the state is being proactive to foster transparent and trustworthy AI.”
Some positive developments:
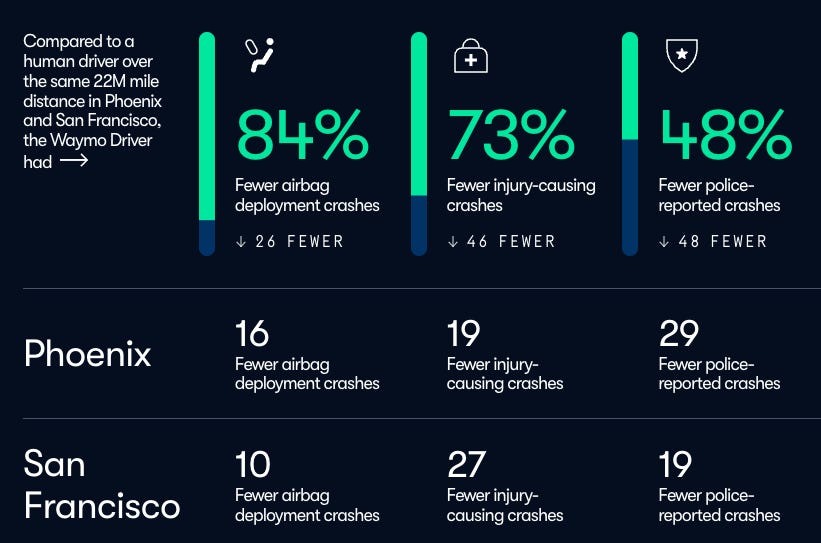
Waymo published impressive data on the safety of their driverless cars
Youtube is working on fake detection: YouTube is making tools to detect face and voice deepfakes
“As AI evolves, we believe it should enhance human creativity, not replace it,” Amjad Hanif, YouTube’s vice president of creator products, wrote in a blog post. “We’re committed to working with our partners to ensure future advancements amplify their voices, and we’ll continue to develop guardrails to address concerns and achieve our common goals.”And interesting research on a new method to force large language models not spit out copyrighted text: Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
"To mitigate memorization, we introduce a subtle modification to the next-token training objective that we call the goldfish loss. During training, a randomly sampled subset of tokens are excluded from the loss computation. These dropped tokens are not memorized by the model, which prevents verbatim reproduction of a complete chain of tokens from the training set"

Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
Non LLM related research!
Anomaly detection in graphs- “Deep Graph Anomaly Detection: A Survey and New Perspectives”
"We first discuss the problem complexities and their resulting challenges in GAD, and then provide a systematic review of current deep GAD methods from three novel perspectives of methodology, including GNN backbone design, proxy task design for GAD, and graph anomaly measures. To deepen the discussions, we further propose a taxonomy of 13 fine-grained method categories under these three perspectives to provide more in-depth insights into the model designs and their capabilities."And this is pretty cool: using a clustering approach to identify how to distribute training across concepts- Automatic Data Curation for Self-Supervised Learning: A Clustering-Based Approach
"Our method involves successive and hierarchical applications of k-means on a large and diverse data repository to obtain clusters that distribute uniformly among data concepts, followed by a hierarchical, balanced sampling step from these clusters. Extensive experiments on three different data domains including web-based images, satellite images and text show that features trained on our automatically curated datasets outperform those trained on uncurated data while being on par or better than ones trained on manually curated data"And real time game generation? Diffusion Models Are Real-Time Game Engines
"GameNGen is trained in two phases: (1) an RL-agent learns to play the game and the training sessions are recorded, and (2) a diffusion model is trained to produce the next frame, conditioned on the sequence of past frames and actions"
Of course, loads going on in the world of foundation models
Sapiens: Foundation for Human Vision Models
"Our models natively support 1K high-resolution inference and are extremely easy to adapt for individual tasks by simply fine-tuning models pretrained on over 300 million in-the-wild human images. We observe that, given the same computational budget, self-supervised pretraining on a curated dataset of human images significantly boosts the performance for a diverse set of human-centric tasks"This is very impressive- SF3D: Stable Fast 3D Mesh Reconstruction with UV-unwrapping and Illumination Disentanglement
"We present SF3D, a novel method for rapid and high-quality textured object mesh reconstruction from a single image in just 0.5 seconds. Unlike most existing approaches, SF3D is explicitly trained for mesh generation, incorporating a fast UV unwrapping technique that enables swift texture generation rather than relying on vertex colors."Good progress in improving long context performance: Hierarchical Context Merging: Better Long Context Understanding for Pre-trained LLMs
"In this paper, we present Hierarchical cOntext MERging (HOMER), a new training-free scheme designed to overcome the limitations. HOMER uses a divide-and-conquer algorithm, dividing long inputs into manageable chunks. Each chunk is then processed collectively, employing a hierarchical strategy that merges adjacent chunks at progressive transformer layers. A token reduction technique precedes each merging, ensuring memory usage efficiency."
Some excellent research on applications for LLMs and foundation models:
Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers
"By recruiting over 100 NLP researchers to write novel ideas and blind reviews of both LLM and human ideas, we obtain the first statistically significant conclusion on current LLM capabilities for research ideation: we find LLM-generated ideas are judged as more novel (p < 0.05) than human expert ideas while being judged slightly weaker on feasibility. Studying our agent baselines closely, we identify open problems in building and evaluating research agents, including failures of LLM self-evaluation and their lack of diversity in generation. "Masked Autoencoders for Microscopy are Scalable Learners of Cellular Biology
"Featurizing microscopy images for use in biological research remains a significant challenge, especially for large-scale experiments spanning millions of images. This work explores the scaling properties of weakly supervised classifiers and self-supervised masked autoencoders (MAEs) when training with increasingly larger model backbones and microscopy datasets."Toward Robust Early Detection of Alzheimer's Disease via an Integrated Multimodal Learning Approach
"This study introduces an advanced multimodal classification model that integrates clinical, cognitive, neuroimaging, and EEG data to enhance diagnostic accuracy. The model incorporates a feature tagger with a tabular data coding architecture and utilizes the TimesBlock module to capture intricate temporal patterns in Electroencephalograms (EEG) data."Finally… my old favourite topic- another interesting time series approach: Visual Masked Autoencoders Are Free-Lunch Zero-Shot Time Series Forecasters


Generative AI ... oh my!
Still moving at such a fast pace it feels in need of it's own section, for developments in the wild world of large language models...
Never a dull moment with OpenAI
On the corporate side, it’s still all go:
They are apparently trying to grow up according to the New York Times
And are struggling with their convoluted non-profit corporate structure
And still have a steady stream of senior departures- now Mira Murati, the OpenAI CTO
But this doesn’t seem to be stopping them raising more money at a $150b valuation!
And maybe this will fund some hardware coming, designed by the great Jony Ive (iPod, iPhone, iPad…)
But they continue to deliver:
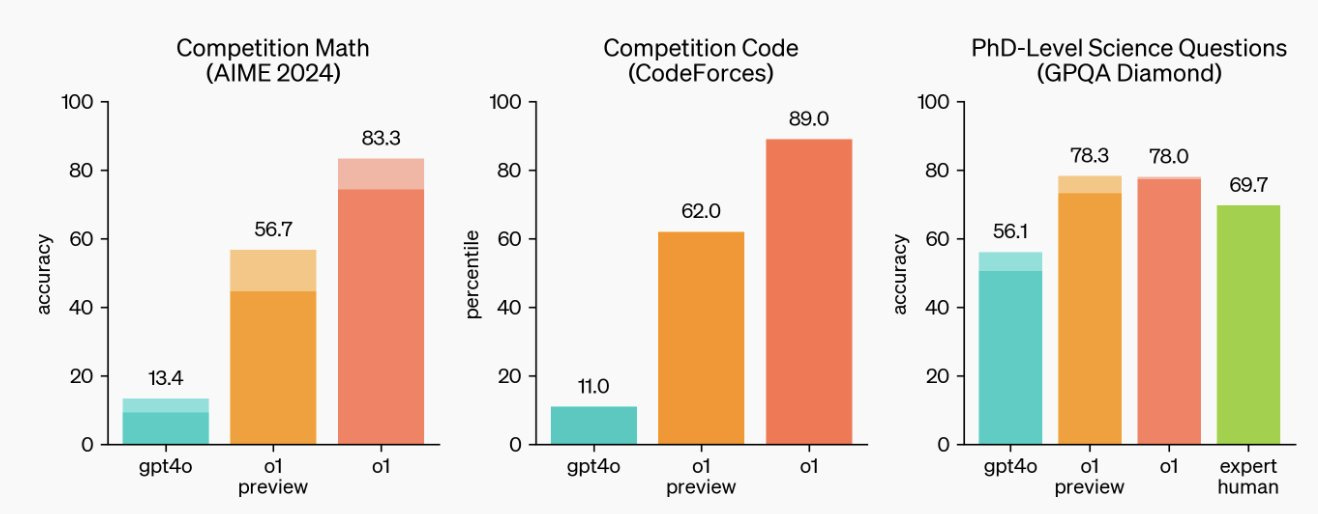
They released OpenAI o1, otherwise called ‘Strawberry’ to great acclaim- an improved foundation model focused on improved response to more complex questions, requiring more reasoning and planning
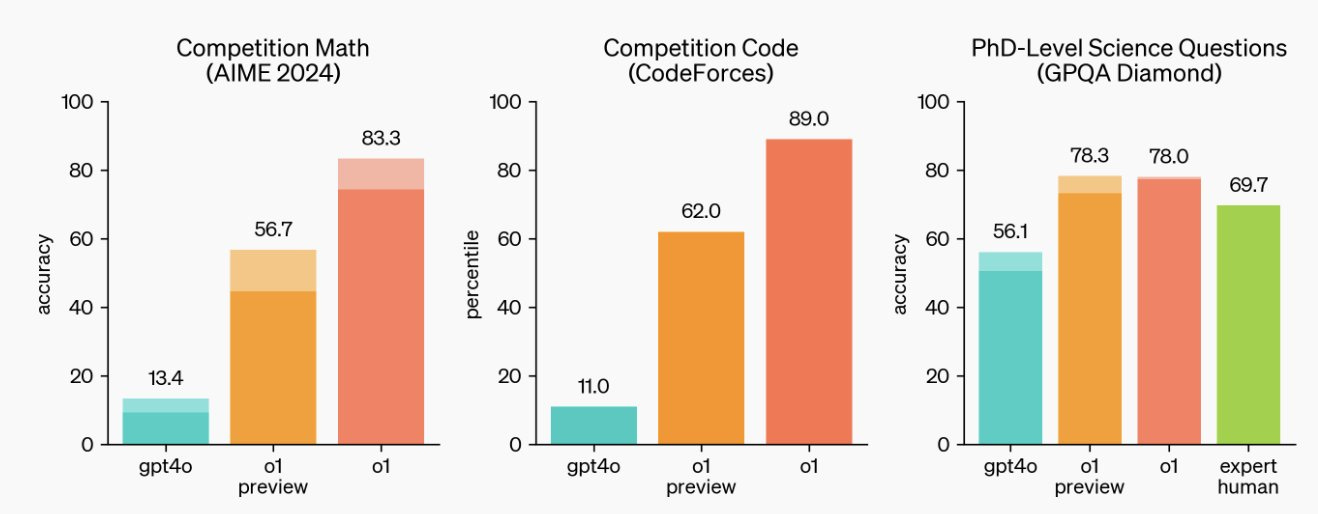
Some good examples to try here, and excellent commentary here

As always, the new model release was not without controversy:
Google had an impressive month with a particular focus on embedding AI into their product suite:
Google is now rolling out Gemini Live to free users on Android
Improved grounding of its models - improving accuracy and trustworthiness
This looks like an impressive tool, well worth trying: NotebookLM now lets you listen to a conversation about your sources “turn documents, slides, charts and more into engaging discussions with one click.”
AI-powered Video creation tools on YouTube
"You'll be able to create even more incredible video backgrounds, breathing life into concepts that were once impossible to visualize. Imagine a BookTuber stepping into the pages of the classic novel, The Secret Garden, or a fashion designer instantly visualizing fun and imaginative design concepts to share with their audience."
Microsoft keep rolling out improvements to their Copilot suite of products, now including automated agents
While Apple’s big news was Apple Intelligence, very much front and centre at their recent launch event
And the AI laggard of the big tech firms continues to be Amazon, although they launched Amelia, a generative AI-powered assistant for third-party sellers
Meta continues to fly the open-source flag with excellent new releases and functionality:
Mistral continues to fly the flag for European foundation model development (based in France)
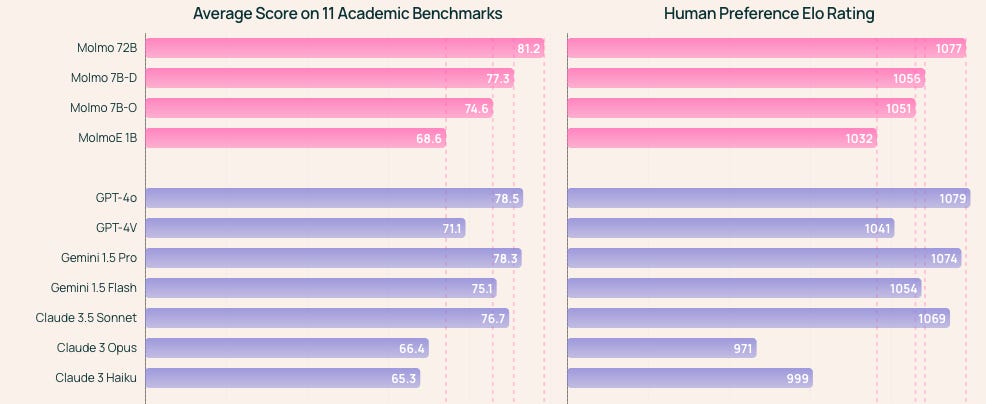
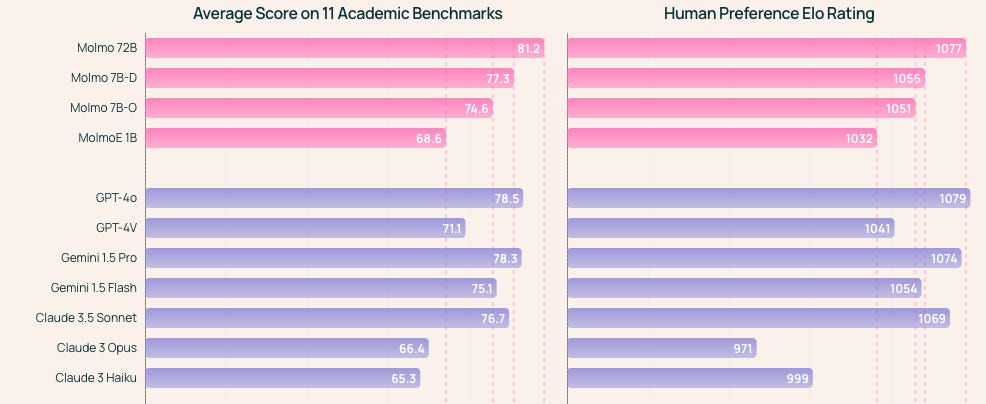
The Non Profit Allen Institute, released a very impressive suite of open source multimodal models - Molmo - competitive with leading commercial models across many benchmarks
And Alibaba in China continues to release an equally extensive suite of open source models, with Qwen2.5 the latest iteration

Finally, if you are struggling to figure out which model you should be using for your application, take a look at this Hallucination Index from Galileo, very useful for ranking across different criteria, particularly for RAG applications




Real world applications and how to guides
Lots of applications and tips and tricks this month
Some interesting practical examples of using AI capabilities in the wild
Robots! Boston Dynamics’ new electric Atlas can do push-ups

"The AI was trained to detect statistical bumps in real-time seismic data that researchers had paired with previous earthquakes. The outcome was a weekly forecast in which the AI successfully predicted 14 earthquakes within about 200 miles of where it estimated they would happen and at almost exactly the calculated strength. It missed one earthquake and gave eight false warnings."Great applications in scientific research:
Predicting crystalline structures
“For thousands of these materials, X-ray diffraction patterns exist but remain unsolved. To try to crack the structures of these materials, Freedman and her colleagues trained a machine-learning model on data from a database called the Materials Project, which contains more than 150,000 materials. First, they fed tens of thousands of these materials into an existing model that can simulate what the X-ray diffraction patterns would look like. Then, they used those patterns to train their AI model, which they call Crystalyze, to predict structures based on the X-ray patterns.”Accelerating particle size distribution
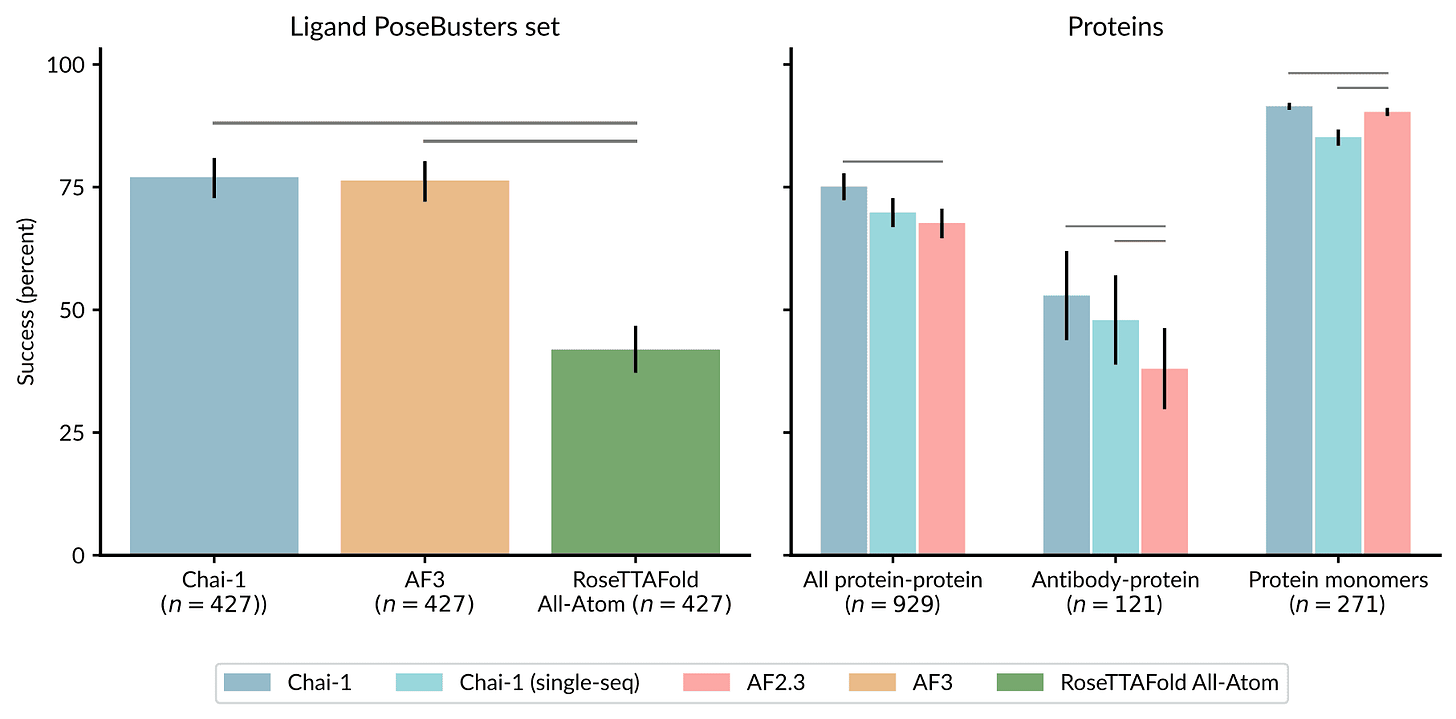
“Understanding the behavior of scattered light is one of the most important topics in optics,” says Qihang Zhang PhD ’23, an associate researcher at Tsinghua University. “By making progress in analyzing scattered light, we also invented a useful tool for the pharmaceutical industry. Locating the pain point and solving it by investigating the fundamental rule is the most exciting thing to the research team.”A foundation model for Decoding the molecular interactions of life: Chai Discovery
Reliant’s paper-scouring AI takes on science’s data drudgery
“The best thing you can do with AI is improve the human experience: reduce menial labor and let people do the things that are important to them,” said CEO Karl Moritz Hermann. In the research world, where he and co-founders Marc Bellemare and Richard Schlegel have worked for years, literature review is one of the most common examples of this “menial labor.”
Some good generative ai applications in business as well:
Leveraging AI for efficient incident response as meta
"Now, we’re leveraging AI to advance our investigation tools even further. We’ve streamlined our investigations through a combination of heuristic-based retrieval and large language model (LLM)-based ranking to provide AI-assisted root cause analysis. During backtesting, this system has achieved promising results: 42% accuracy in identifying root causes for investigations at their creation time related to our web monorepo.""Global content leader Lionsgate (NYSE: LGF.A, LGF.B) and leading applied AI research company Runway today announced a first-of-its-kind partnership centered around Runway’s creation and training of a new AI model, customized to Lionsgate’s proprietary portfolio of film and television content. Exclusively designed to help Lionsgate Studios, its filmmakers, directors and other creative talent augment their work, the model generates cinematic video that can be further iterated using Runway’s suite of controllable tools. "Using LLMs to score customer conversations

Lots of great tutorials and how-to’s this month
"The system prompt is: You’re an expert web scraper. You’re given the HTML contents of a table and you have to extract structured data from it."Build a sophisticated local GraphRAG system (retrieval augmented generation based on a graph knowledge base) - and iText2KG looks useful for creating knowledge graphs
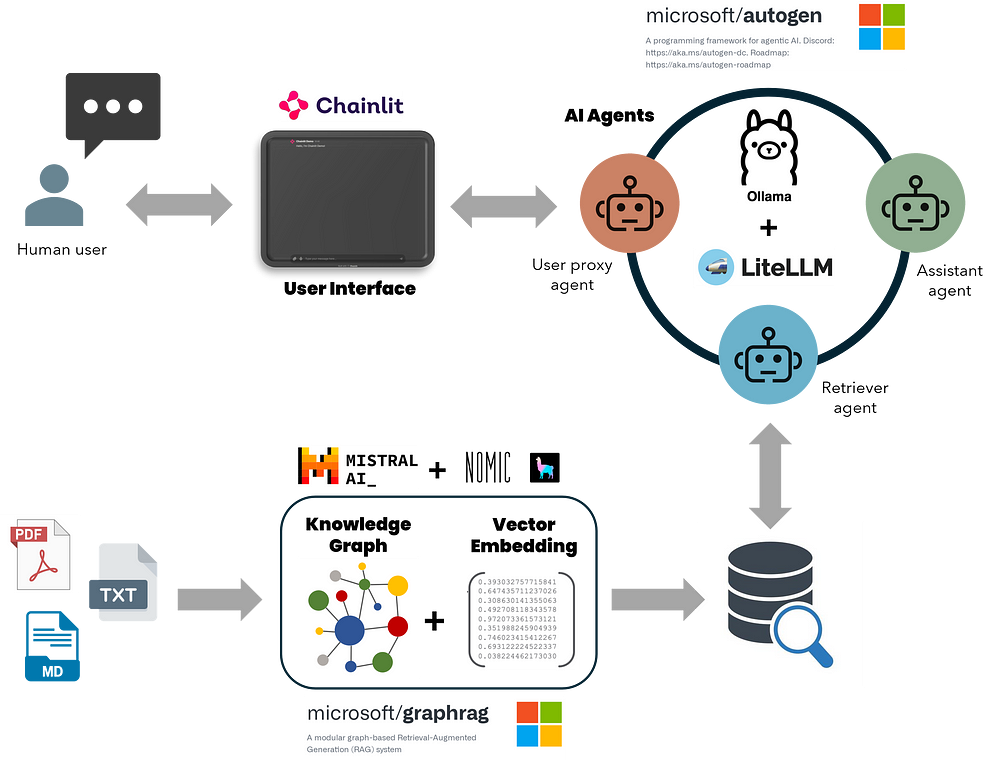
Speaking of RAG- some excellent pointers on optimising:
Providing more context in your vector store: Introducing Contextual Retrieval from Anthropic (also see Anthropic’s useful quickstarts- excellent resource)
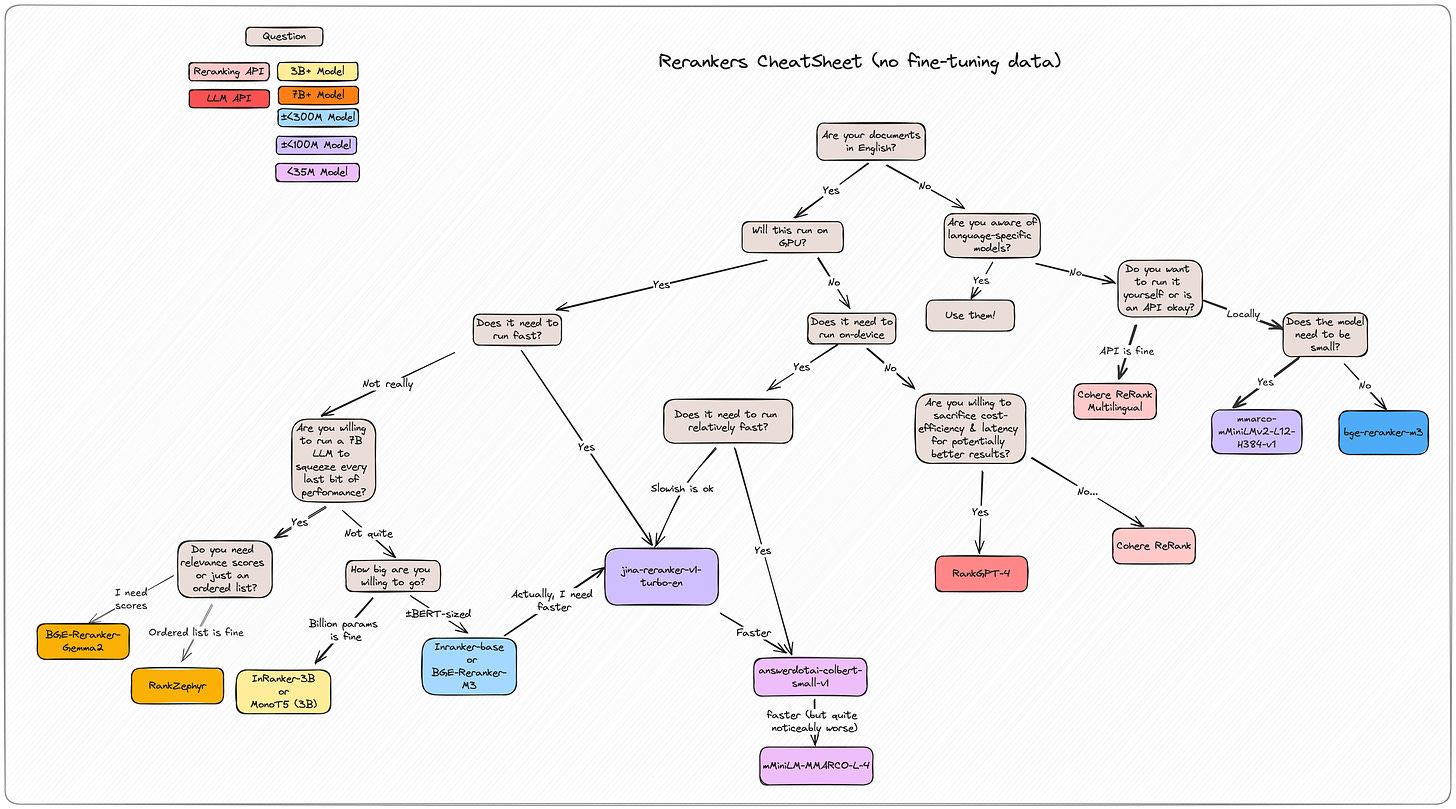
original_chunk = "The company's revenue grew by 3% over the previous quarter." contextualized_chunk = "This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter."Retrieve the data from your vector store using multiple approaches then rerank with this new library: rerankers: A Lightweight Python Library to Unify Ranking Methods
This looks promising- treating prompts as functions which can then be optimised: “ell: The Language Model Programming Library”
import ell @ell.simple(model="gpt-4o-mini") def hello(world: str): """You are a helpful assistant""" # System prompt name = world.capitalize() return f"Say hello to {name}!" # User prompt hello("sam altman") # just a str, "Hello Sam Altman! ..."
Excellent primer on Contrastive Learning
"Contrastive learning centres around a simple concept of choosing a representation that maximizes the similarities between positive data pairs, while minimizing for negative pairs. For example, I input an image of a mango and now its goal should be to maximize the similarity between mango images while minimizing it for some other images."Definitely time you had a play with Polars! Excellent post from an experienced pandas practitioner
"Frankly, I have no idea how impactful this will be on my general workflow. I’ll likely still be rocking pandas for a lot of my cowboy coding in google colab, simply because I’m comfortable with it, but when faced with big dataframes and computationally expensive queries I think I’ll find myself reaching for Polars more often, and I expect to eventually integrate it into a core part of my workflow. A big reason for that is the astronomical speed increase of GPU accelerated Polars over virtually any other dataframe tooling."Some useful posts on error analysis: a simple recipe and fixing bias
Finally, always good to remember the importance of good visualisation: Five ways to improve your chart axes
"A poor choice of axes for your chart can make it more difficult to understand, and in some cases, suggest misleading conclusions. In this blog post, we'll look at five ways to make better choices about your axes and stop relying on default settings."


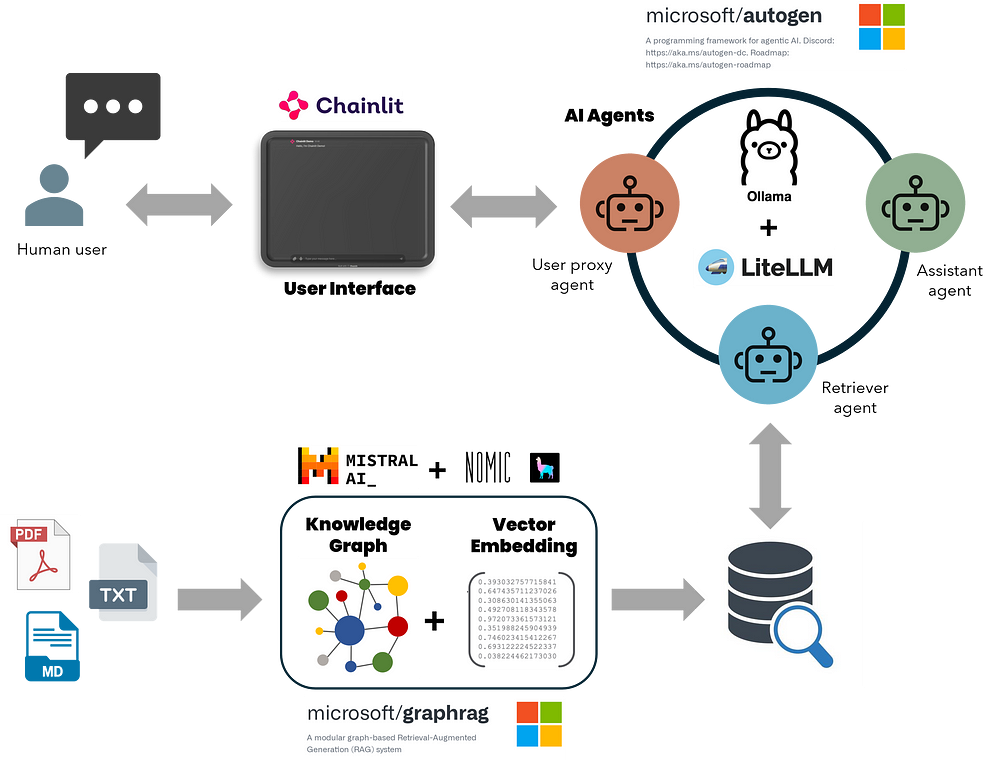
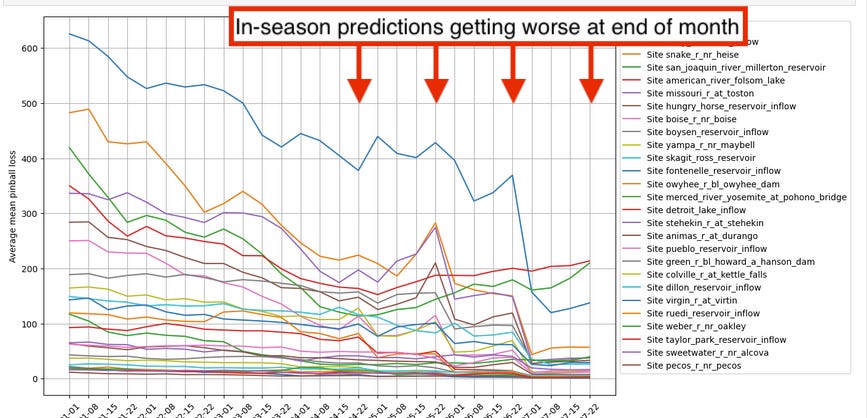
Practical tips
How to drive analytics, ML and AI into production
More good insight from Netflix on their platform: Introducing Netflix’s Key-Value Data Abstraction Layer
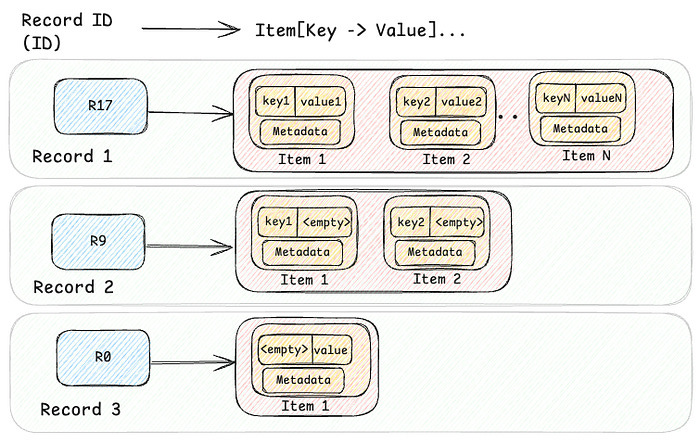
The Data Pipeline is the New Secret Sauce
"The biggest challenge emerging is building and operating the infrastructure both for creating and running the data pipelines to build, manage, and maintain a robust, secure body of proprietary data to train, fine-tune, and orchestrate LLM operations, and for running inference, the actual process of models running calculations on inputted data."The “Who Does What” Guide To Enterprise Data Quality

Good guide to testing ML: How to Test Machine Learning Systems
"Testing machine learning is hard because it’s probabilistic by nature, and must account for diverse data and dynamic real-world conditions. You should start with a basic CI pipeline. Focus on the most valuable tests for your use case: Syntax Testing, Data Creation Testing, Model Creation Testing, E2E Testing, and Artifact Testing. Most of the time the most valuable test is E2E Testing."

Bigger picture ideas
Longer thought provoking reads - sit back and pour a drink! ...
Scaling: The State of Play in AI - Ethan Mollick
"Scale really does matter. Bloomberg created BloombergGPT to leverage its vast financial data resources and potentially gain an edge in financial analysis and forecasting. This was a specialized AI whose dataset had large amounts of Bloomberg’s high-quality data, and which was trained on 200 ZetaFLOPs (that is 2 x 10^23) of computing power. It was pretty good at doing things like figuring out the sentiment of financial documents… but it was generally beaten by GPT-4, which was not trained for finance at all. GPT-4 was just a bigger model (the estimates are 100 times bigger, 20 YottaFLOPs, around 2 x 10^25) and so it is generally better than small models at everything. This sort of scaling seems to hold for all sorts of productive work - in an experiment where translators got to use models of different sizes: “for every 10x increase in model compute, translators completed tasks 12.3% quicker, received 0.18 standard deviation higher grades and earned 16.1% more per minute.”."Why OpenAI’s new model is such a big deal - MIT Technology Review
"The bulk of LLM progress until now has been language-driven, resulting in chatbots or voice assistants that can interpret, analyze, and generate words. But in addition to getting lots of facts wrong, such LLMs have failed to demonstrate the types of skills required to solve important problems in fields like drug discovery, materials science, coding, or physics. OpenAI’s o1 is one of the first signs that LLMs might soon become genuinely helpful companions to human researchers in these fields. "Against Prophecy among the Machines - Anselm Levskaya
“The backers of California’s SB1047 routinely cite AI-enabled bioweapons as a threat justifying the radical regulatory regime that places a locus of liability on general computational models, rather than on particular dangerous applications or criminal acts. For six years I've worked on scaling generative AI models at a leading industrial lab - I’ve worked on some of the largest language models ever trained. But before that I was an experimental lab-scientist for two decades working in synthetic biology, optogenetics, and immuno-oncology. As a biologist I feel compelled to comment on this risk-scenario, speaking solely on my own behalf as a resident of California, and as someone who generally admires my state senator Scott Wiener, the primary sponsor of the bill. The claims being made about biological risks do not reflect scientific reality.”Every White-Collar Role Will Have An AI Copilot. Then An AI Agent. - Andreessen Horowitz
"A recent study by OpenAI and the University of Pennsylvania found that with access to an LLM, about 15% of all worker tasks in the U.S. could be completed significantly faster at the same level of quality. When incorporating software and tooling built on top of LLMs (i.e., Vertical SaaS), this share increases to between 47% and 56% of all tasks. "The Button Problem of AI - Evan Armstrong
"Because most fixes follow similar patterns across users’ workflows, all I need to do is select from a set of predetermined options like “shorten” or “simplify.” This is both the beauty of existing AI tools and the rub: The majesty of LLMs, the tens of billions being spent building more and more advanced systems, gets boiled down to a single click allowing me to do a task I would do while writing anyway. Do you know what this makes Superhuman? An email app. That’s it! AI just makes it do email better. The reduction of AI’s ambition applies to most LLM-based products in software today. Because the models are unable to handle knowledge-labor workflows in their totality, product builders are forced to bind LLMs to tasks that are small and easily definable. And what is the best way for a user to deploy a small, discrete task? You guessed it: a button."
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
Interesting read- Jensen’s Inequality As An Intuition Tool
We are celebrating a big W, so it’s time to take the kids to Sizzler. We’re going to drive. Sizzler is 10 minutes away + some extra time depending on how many cars are on the road. Let’s keep things very simple and assume the number of cars that can be on the road is 10, 20, 30, 40, or 50 and with equal probability. None of these quantities is enough to slow the flow of traffic to a halt, but the impact of the extra cars is not linear. Let’s play “How long will it take to get to Sizzler?”How about building your own lightning fast text to speech processor with Fish Speech open source model - see the amazing demo voices here - apparently it has almost instantaneous voice cloning
Finally, build your own Surveillance Video Summariser!
Updates from Members and Contributors
Kevin O’Brien highlights the excellent PyData Global conference (Tuesday 3rd Dec to Thursday 5th December)
“Join PyData for our fourth year hosting this event virtually bringing together PyData Chapters, community members, and attendees from all over the world together for an unforgettable PyData Conference. As well as Python talks, R & Julia talks sought.
To find out more, go to our conference website
Do you have ideas to share? Submit a proposal for your presentation here
Call for proposals will close on Monday, 7th October, 2024 (AoE). “
Long time friend of the newsletter (and Polars core developer), Marco Gorelli, highlights his new python library Narwhals. It offers an extremely lightweight and extensible compatibility layer between dataframe libraries (pandas, Polars, cuDF, Modin, PyArrow, and more in progress) targeted at tool-builders, and has recently been adopted by visualisation giant Altair.
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
2 exciting new machine learning roles at Carbon Re- excellent climate change AI startup
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS