

Hi everyone-
I hope you’ve all been having an excellent summer… there’s certainly been lots to keep us occupied. How about some thought provoking AI and Data Science reading materials to fill the daily Olympics highlights hole! I really encourage you to read on, but some edited highlights if you are short for time!
Mark Zuckerberg doubles down on Meta’s open source commitment: Open Source AI Is the Path Forward
Always worth reading Bengio: Reasoning through arguments against taking AI safety seriously
Great achievement from DeepMind: AI achieves silver-medal standard solving International Mathematical Olympiad problems
Bill Gates on education: My trip to the frontier of AI education
Amazing: The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Following is the September edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
We are continuing our work with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is accepting applications for the Advanced Data Science Professional certification as well as the new Data Science Professional certification.
We successfully ran a very well attended event on July 17th: ‘Designing the perfect data science project for every environment - Github repository templates’. Many thanks to those who came along- we will publish a write up shortly
Martin Goodson, CEO and Chief Scientist at Evolution AI, continues to run the excellent London Machine Learning meetup and is very active with events. The next event is on September 11th, when Yong Jae Lee, Associate Professor in the Department of Computer Sciences at the University of Wisconsin-Madison, will present "Next Steps in Generalist Multimodal Models”. Videos are posted on the meetup youtube channel - definitely check out the last one (The Importance of High-Quality Data in Building Your LLMs - from the Mosaic team at Databricks) which was very insightful.
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
Given the timing, we couldn’t not include an Olympics story: “At the Olympics, AI is watching you”
"Levain is concerned the AI surveillance systems will remain in France long after the athletes leave. To her, these algorithms enable the police and security services to impose surveillance on wider stretches of the city. “This technology will reproduce the stereotypes of the police,” she says. “We know that they discriminate. We know that they always go in the same area. They always go and harass the same people. And this technology, as with every surveillance technology, will help them do that."AI driven products are increasingly readily available- “The AI job interviewer will see you now”
"She is also troubled by the focus on scale. While the system requires training data to improve, the flood of data often makes it harder to interrogate why a particular decision is being made. “In hiring, more data isn’t always solving the problem,” said Schellman. “The more data we give it, the more potential there is for bias.”"Hollywood stars’ estates agree to the use of their voices with AI
"Actress Judy Garland never recorded her voice to read an audiobook of The Wonderful Wizard of Oz, but you’ll soon be able to hear her rendition of the children’s novel that inspired the movie nonetheless. Earlier this week, AI company ElevenLabs said it is bringing digitally produced celebrity voice-overs of deceased actors, including Garland, James Dean and Burt Reynolds, to its newly launched Reader app. The company said the app takes articles, PDF, ePub, newsletters, e-books or any other text on your phone and turns it into voice-overs."Meanwhile, lots going on with regulations:
To start with - “The EU’s AI Act is now in force” - although what developers need to do to comply is still far from clear
"What exactly GPAI (general purpose AIs) developers will need to do to comply with the AI Act is still being discussed, as Codes of Practice are yet to be drawn up. Earlier this week, the AI Office, a strategic oversight and AI-ecosystem building body, kicked off a consultation and call for participation in this rule-making process, saying it expects to finalize the Codes in April 2025."Not surprisingly, this has caused concern: “Meta pulls plug on release of advanced AI model in EU”
"“We will release a multimodal Llama model over the coming months – but not in the EU due to the unpredictable nature of the European regulatory environment,” the spokesperson said."Meanwhile, the UN is making the case for unified global AI governance - “Inside the United Nations’ AI policy grab”, great insight from Politico
"Yet, the U.N. report argues, even in AI policy there are haves and have-nots. While the members of the G7 industrialized nations — the U.S., the U.K., France, Germany, Italy, Japan and Canada — are party to all key AI-related initiatives, 118 countries in the so-called global South are not involved in any of it. “In terms of representation, whole parts of the world have been left out of international AI governance conversations,” the report said. The implication is that giving the U.N. a key role in AI matters would address this global imbalance."In the US, positive news regarding Open Source models- “White House says no need to restrict ‘open-source’ artificial intelligence — at least for now”
"The NTIA’s report says “current evidence is not sufficient” to warrant restrictions on AI models with “widely available weights.” Weights are numerical values that influence how an AI model performs. But it also says U.S. officials must continue to monitor potential dangers and “take steps to ensure that the government is prepared to act if heightened risks emerge.”"California is keen to be at the regulatory forefront but is attempting to navigate a delicate balance: “California weakens bill to prevent AI disasters before final vote, taking advice from Anthropic”
"Most notably, the bill no longer allows California’s attorney general to sue AI companies for negligent safety practices before a catastrophic event has occurred. This was a suggestion from Anthropic. Instead, California’s attorney general can seek injunctive relief, requesting a company to cease a certain operation it finds dangerous, and can still sue an AI developer if its model does cause a catastrophic event."And, inline with previous White House orders on AI, OpenAI “pledges to give U.S. AI Safety Institute early access to its next model”
"The timing of OpenAI’s agreement with the U.S. AI Safety Institute seems a tad suspect in light of the company’s endorsement earlier this week of the Future of Innovation Act, a proposed Senate bill that would authorize the Safety Institute as an executive body that sets standards and guidelines for AI models. The moves together could be perceived as an attempt at regulatory capture — or at the very least an exertion of influence from OpenAI over AI policymaking at the federal level."
Useful work from MIT researches on better defining AI risk: “MIT releases comprehensive database of AI risks”
“We started our project aiming to understand how organizations are responding to the risks from AI,” Peter Slattery, incoming postdoc at MIT FutureTech and project lead, told VentureBeat. “We wanted a fully comprehensive overview of AI risks to use as a checklist, but when we looked at the literature, we found that existing risk classifications were like pieces of a jigsaw puzzle: individually interesting and useful, but incomplete.”Just in case we weren’t clear on the risks, Yoshua Bengio gives us a primer
"The most important thing to realize, through all the noise of discussions and debates, is a very simple and indisputable fact: while we are racing towards AGI or even ASI, nobody currently knows how such an AGI or ASI could be made to behave morally, or at least behave as intended by its developers and not turn against humans. It may be difficult to imagine, but just picture this scenario for one moment: Entities that are smarter than humans and that have their own goals: are we sure they will act towards our well-being? "Some positive development on the detection and mitigation front:
Mapping the misuse of generative AI from DeepMind
"By analyzing media reports, we identified two main categories of generative AI misuse tactics: the exploitation of generative AI capabilities and the compromise of generative AI systems. Examples of the technologies being exploited included creating realistic depictions of human likenesses to impersonate public figures; while instances of the technologies being compromised included ‘jailbreaking’ to remove model safeguards and using adversarial inputs to cause malfunctions."And Google released a new tool allowing users to easily “remove claimed content from videos”
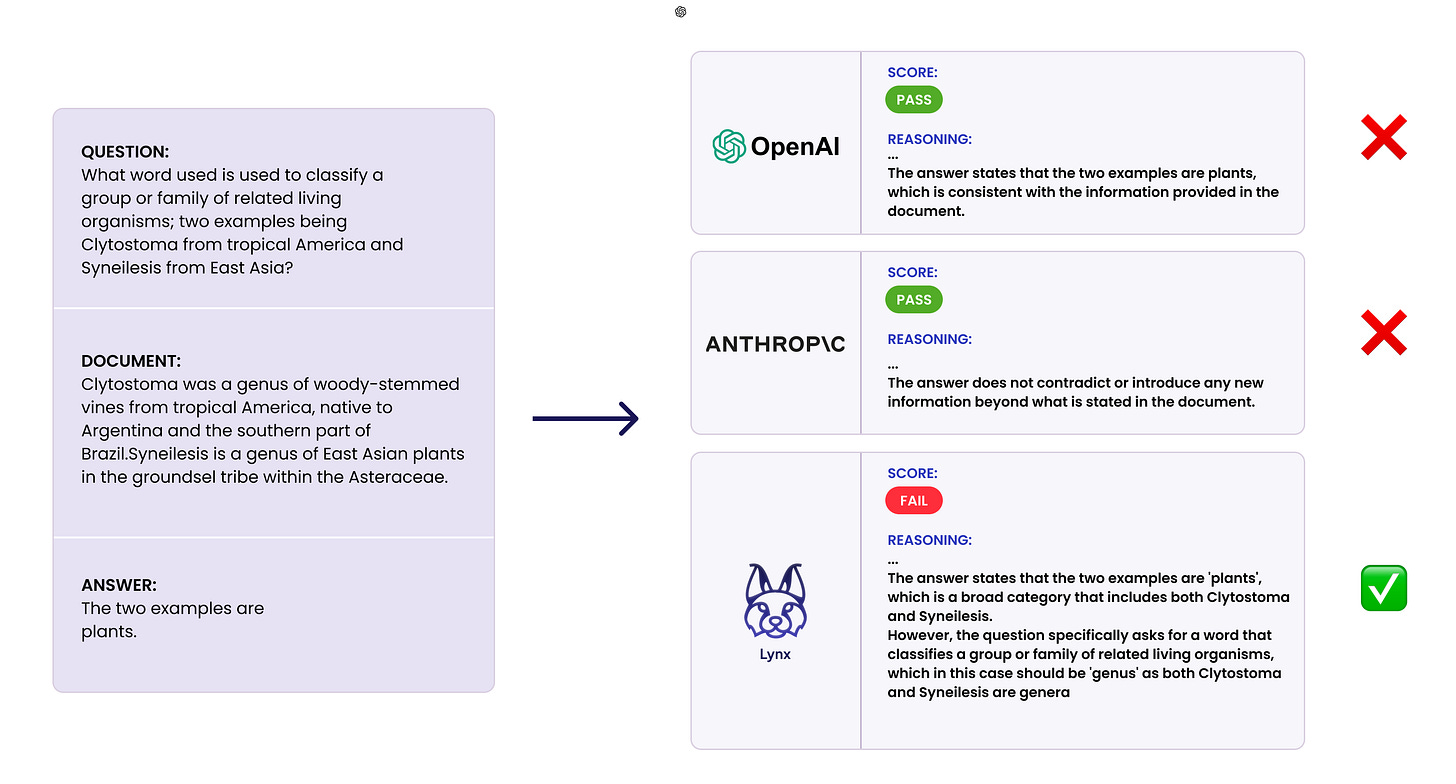
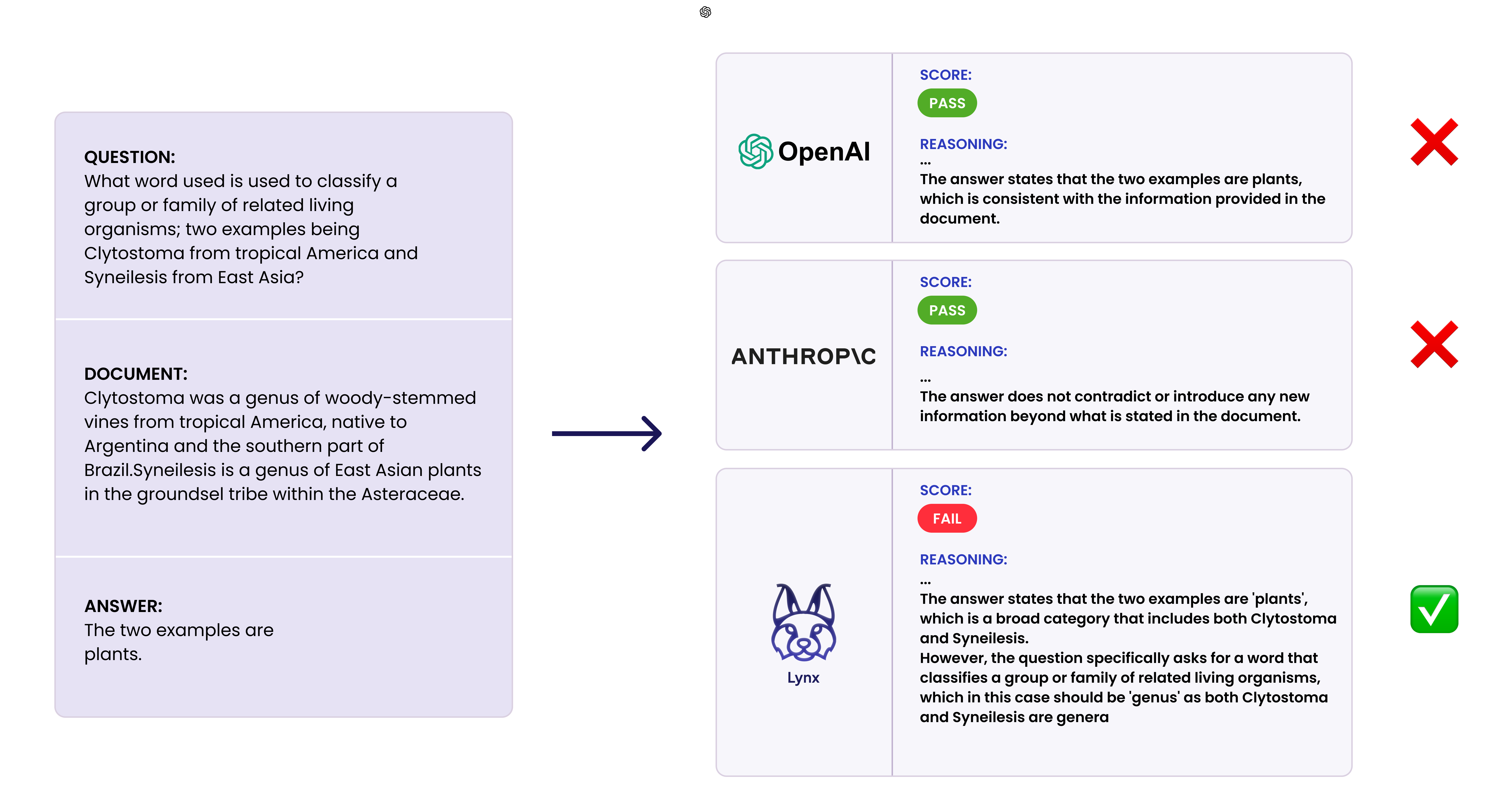
Finally, more progress on detecting when AI is making stuff up: “Lynx: State-of-the-Art Open Source Hallucination Detection Model”. And Open Source!
Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
Anyone remember SETI@home? Imagine if we could distribute the pre-training of Large Language models in a similar way? “The Future of Large Language Model Pre-training is Federated”
"Federated learning (FL) has the potential to unleash the majority of the planet's data and computational resources, which are underutilized by the data-center-focused training methodology of current LLM practice. Our work presents a robust, flexible, reproducible FL approach that enables large-scale collaboration across institutions to train LLMs."Have you struggled with how best to optimise your learning rate for Deep Learning architectures? Maybe you don’t need to? “No learning rates needed: Introducing SALSA -- Stable Armijo Line Search Adaptation”
"Our optimization approach outperforms both the previous Armijo implementation and a tuned learning rate schedule for the Adam and SGD optimizers. Our evaluation covers a diverse range of architectures, such as Transformers, CNNs, and MLPs, as well as data domains, including NLP and image data. Our work is publicly available as a Python package, which provides a simple Pytorch optimizer."Great work from together.ai in improving the efficiency of the attention mechanism with FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision - its these type of improvements that are driving the increase in context length now available in leading models
The improvements from FlashAttention-3 will result in: 1- More efficient GPU Utilization: The new technique uses up to 75% of an H100 GPU's maximum capabilities, up from just 35% before. This results in significantly (1.5-2x) faster than previous versions for training and running of large language models (LLMs). 2- Better performance with lower precision: FlashAttention-3 can work with lower precision numbers (FP8) while maintaining accuracy. This allows for even faster processing and potentially lower memory usage, which could lead to cost savings and improved efficiency for customers running large-scale AI operations. 3- Ability to use longer context in LLMs: By speeding up the attention mechanism, FlashAttention-3 enables AI models to work with much longer pieces of text more efficiently. This could allow for applications that can understand and generate longer, more complex content without slowing down.Can we improve inference with repeated sampling? Can we make smaller models smarter by simply giving them more goes at answering the question? It certainly looks that way
"Across multiple tasks and models, we observe that coverage - the fraction of problems solved by any attempt - scales with the number of samples over four orders of magnitude. In domains like coding and formal proofs, where all answers can be automatically verified, these increases in coverage directly translate into improved performance. When we apply repeated sampling to SWE-bench Lite, the fraction of issues solved with DeepSeek-V2-Coder-Instruct increases from 15.9% with one sample to 56% with 250 samples, outperforming the single-attempt state-of-the-art of 43% which uses more capable frontier models."Multimodal models rely on the elegant Contrastive Language-Image Pre-training (CLIP) method. CLEFT is a new method that leverages the existing approach but combines prompt engineering techniques for smaller and more specialist data sets such as in medicine.
"Our method demonstrates state-of-the-art performance on multiple chest X-ray and mammography datasets compared with various baselines. The proposed parameter efficient framework can reduce the total trainable model size by 39% and reduce the trainable language model to only 4% compared with the current BERT encoder."Great new functionality from Google research- Magic Insert: Style-Aware Drag-and-Drop

Using stand alone Large Language Models for evaluation and alignment is increasingly viable: Meta-Rewarding Language Models: Self-Improving Alignment with LLM-as-a-Meta-Judge
"Large Language Models (LLMs) are rapidly surpassing human knowledge in many domains. While improving these models traditionally relies on costly human data, recent self-rewarding mechanisms (Yuan et al., 2024) have shown that LLMs can improve by judging their own responses instead of relying on human labelers. However, existing methods have primarily focused on improving model responses rather than judgment capabilities, resulting in rapid saturation during iterative training. To address this issue, we introduce a novel Meta-Rewarding step to the self-improvement process, where the model judges its own judgements and uses that feedback to refine its judgment skills."Even MultiModal models struggle with the interaction between text and images. One approach to improve these capabilities is to focus on specific domains- in this case charts
"Specifically, we propose a novel data engine to effectively filter diverse and high-quality data from existing datasets and subsequently refine and augment the data using LLM-based generation techniques to better align with practical QA tasks and visual encodings. Then, to facilitate the adaptation to chart characteristics, we utilize the enriched data to train an MLLM by unfreezing the vision encoder and incorporating a mixture-of-resolution adaptation strategy for enhanced fine-grained recognition. "In the Mechanistic Interpretability space (attempting to understand how the large models end up with the predictions they make) Sparse AutoEncoder (SAE) models of some of the key internal layers have proved successful in identifying underlying ‘topics’ (for instance, see Anthropic’s ‘Golden Gate’ research). However the training cost in generating these models and weights are high. Now Google have open sourced their SAEs for Gemma 2!
"We evaluate the quality of each SAE on standard metrics and release these results. We hope that by releasing these SAE weights, we can help make more ambitious safety and interpretability research easier for the community. Weights and a tutorial can be found at this https URL and an interactive demo can be found at this https URL"More progressing in driving consistency and reasoning with LLMs- Distilling System 2 into System 1
"In this work we investigate self-supervised methods to ``compile'' (distill) higher quality outputs from System 2 techniques back into LLM generations without intermediate reasoning token sequences, as this reasoning has been distilled into System 1. We show that several such techniques can be successfully distilled, resulting in improved results compared to the original System 1 performance, and with less inference cost than System 2"Creating more accurate models for more specific use cases often requires specialised data sets- this looks very useful for the medical domain
"This paper introduces MedTrinity-25M, a comprehensive, large-scale multimodal dataset for medicine, covering over 25 million images across 10 modalities, with multigranular annotations for more than 65 diseases. These enriched annotations encompass both global textual information, such as disease/lesion type, modality, region-specific descriptions, and inter-regional relationships, as well as detailed local annotations for regions of interest (ROIs), including bounding boxes, segmentation masks. "Speaking of foundation models for specific use cases
"ECG-FM is a foundation model for electrocardiogram (ECG) analysis. Committed to open-source practices, ECG-FM was developed in collaboration with the fairseq_signals framework, which implements a collection of deep learning methods for ECG analysis."Small Molecule Optimization with Large Language Models
"We present Chemlactica and Chemma, two language models fine-tuned on a novel corpus of 110M molecules with computed properties, totaling 40B tokens. These models demonstrate strong performance in generating molecules with specified properties and predicting new molecular characteristics from limited samples. "How about all of Biology? ESM3: Simulating 500 million years of evolution with a language model
"Language models operate over discrete units, or tokens. To create one that can reason over three of the fundamental biological properties of proteins—sequence, structure, and function—we had to transform three dimensional structure and function into discrete alphabets, and construct a way to write every three dimensional structure as a sequence of letters. This allows ESM3 to be trained at scale, unlocking emergent generative capabilities. ESM3’s vocabulary bridges sequence, structure, and function all within the same language model."
Can LLMs understand causality? Causal Agent based on Large Language Model
"To address these challenges, we have equipped the LLM with causal tools within an agent framework, named the Causal Agent, enabling it to tackle causal problems. The causal agent comprises tools, memory, and reasoning modules. In the tools module, the causal agent applies causal methods to align tabular data with natural language. In the reasoning module, the causal agent employs the ReAct framework to perform reasoning through multiple iterations with the tools."Finally… how cool is this?! Google DeepMind trained a robot to beat humans at table tennis



Generative AI ... oh my!
Still moving at such a fast pace it feels in need of it's own section, for developments in the wild world of large language models...
Never a dull moment with OpenAI
OpenAI Generates More Turmoil - more founders leaving the company
But they are certainly still delivering:
GPT-4o Mini - smaller, faster, cheaper; as well as free fine tuning
Full GPT-4o System Card- with lots of detail on the safety checks involved
And rumours abound on something called ‘Strawberry’ - see also here
Google also keeps delivering with a particular focus on embedding AI into their product suite:
Speed and efficiency improvements with Gemini 1.5 Flash
Together with price drops as well as fine tuning
New image generation with Imagen-3
As well as AI-powered video creation for work
Microsoft have released and impressive update to their Phi models: Microsoft's Phi-3 family
Apart from attracting key OpenAI employees (see OpenAI turmoil above), Anthropic rolled out a very useful feature for developers- prompt caching
"Prompt caching, which enables developers to cache frequently used context between API calls, is now available on the Anthropic API. With prompt caching, customers can provide Claude with more background knowledge and example outputs—all while reducing costs by up to 90% and latency by up to 85% for long prompts."Elon Musk’s Grok-2 model was released- and it’s apparently pretty good
"With the new release Grok-2 was also given a makeover with a look closer to other chatbot interfaces, as well as the ability to generate images using Flux, the AI image generation model from Black Forest Labs that is close to the quality of industry leader Midjourney. I’ve been playing with Grok-2 for the past few days and have found it as responsive as ChatGPT but with a better sense of humor and the ability to respond to real-time events thanks to X."On the video front:
Open source and Meta are pretty closely linked at the moment
To start with, Mark Zuckerberg doubles down on their open source commitment: Open Source AI Is the Path Forward
"I believe that open source is necessary for a positive AI future. AI has more potential than any other modern technology to increase human productivity, creativity, and quality of life – and to accelerate economic growth while unlocking progress in medical and scientific research. Open source will ensure that more people around the world have access to the benefits and opportunities of AI, that power isn’t concentrated in the hands of a small number of companies, and that the technology can be deployed more evenly and safely across society. There is an ongoing debate about the safety of open source AI models, and my view is that open source AI will be safer than the alternatives. I think governments will conclude it’s in their interest to support open source because it will make the world more prosperous and safer."And true to his word, they keep releasing:
Introducing SAM 2: The next generation of Meta Segment Anything Model for videos and images
Introducing Llama 3.1: Our most capable models to date
"Llama 3.1 405B is the first openly available model that rivals the top AI models when it comes to state-of-the-art capabilities in general knowledge, steerability, math, tool use, and multilingual translation. With the release of the 405B model, we’re poised to supercharge innovation—with unprecedented opportunities for growth and exploration. We believe the latest generation of Llama will ignite new applications and modeling paradigms, including synthetic data generation to enable the improvement and training of smaller models, as well as model distillation—a capability that has never been achieved at this scale in open source."
Elsewhere in the world of open source:
Stability AI steps into a new gen AI dimension with Stable Video 4D
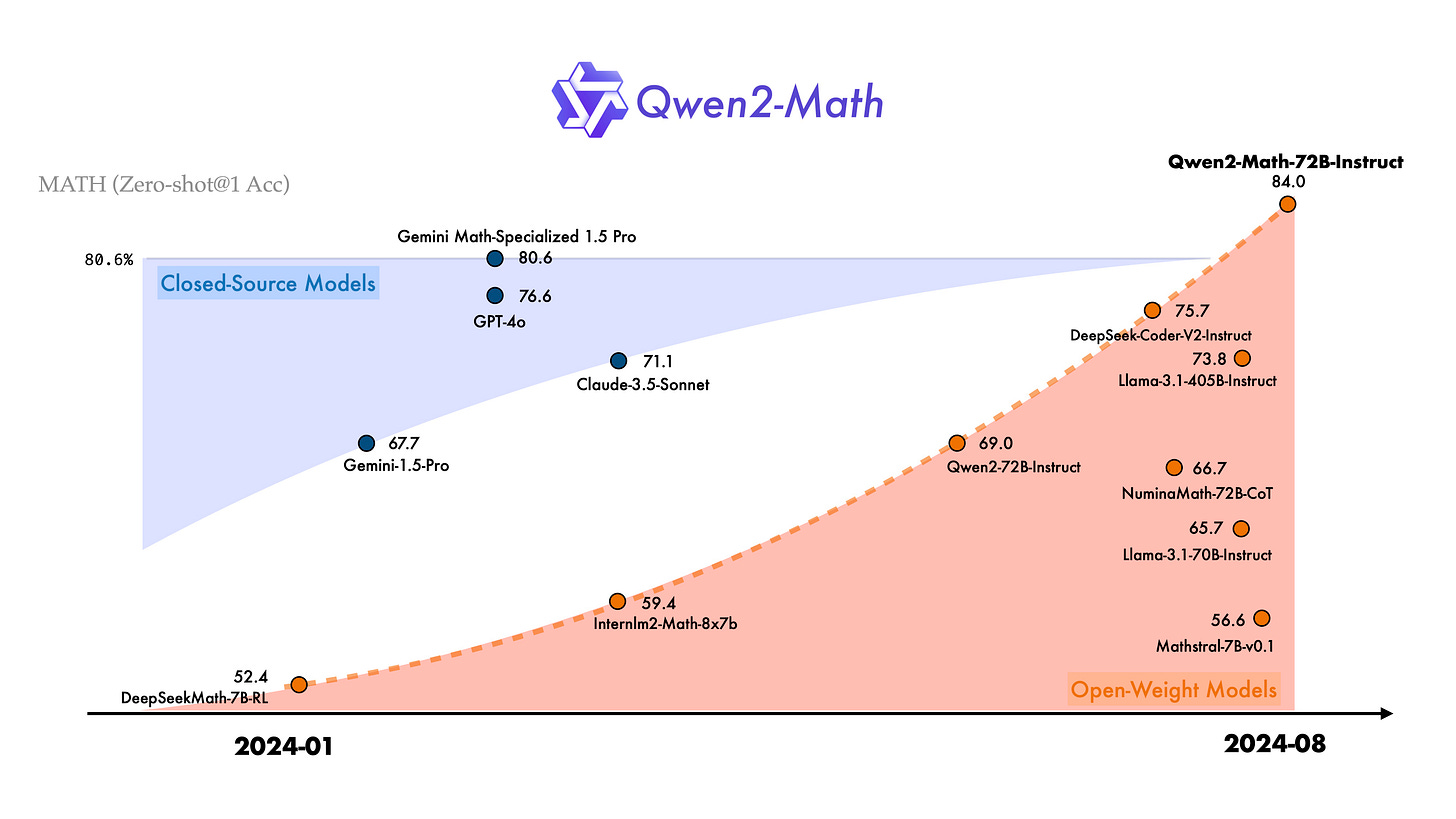
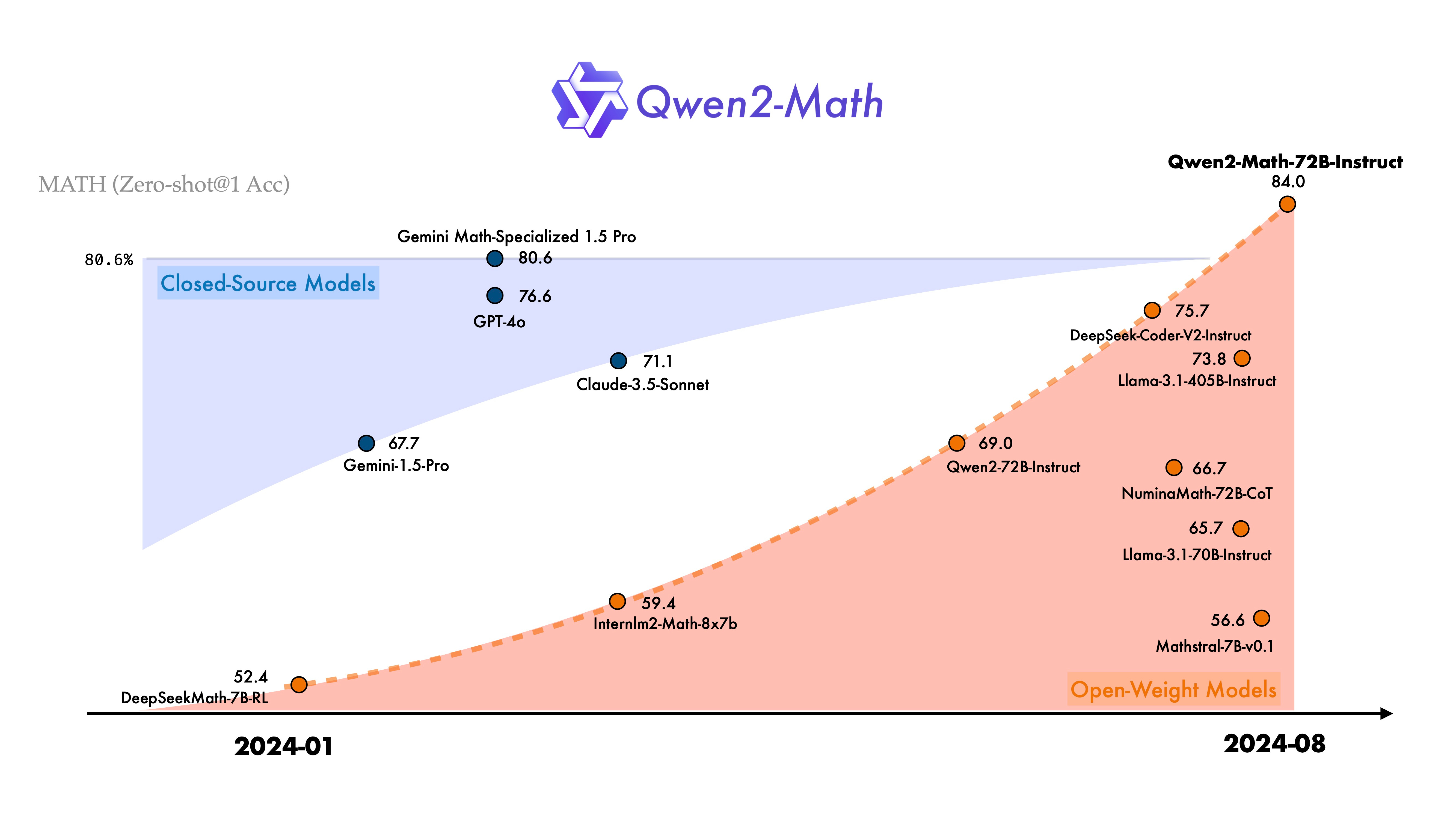
Introducing Qwen2-Math - interesting open source specialist maths focused model from China
Of course, what really is open source when it comes to these models? Great resource here listing what components of each model are actually ‘open’- well worth a look
Some interesting commentary on inference costs (how much it costs to use the models):
A new level on the ‘Price-Intelligence’ frontier
And what this potentially means: AI paid for by Ads – the gpt-4o mini inflection point
"You can probably see where I'm going with this now. For that blog post, we might earn ~$0.0026 for the single page impression from the user that requested it. Meanwhile, the blog post itself, had a cost of $0.00051525 to generate. We made a net profit of $0.0026 - $0.00051525 = ~$0.002! We're going to be rich! That's 2 tenths of a penny. Don't go spending it all in one place."
Finally I think Sakana are doing some pretty amazing things combining large language models with evolutionary approaches- you have to check this out: The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery: from idea to finished paper, all done by AI.


Real world applications and how to guides
Lots of applications and tips and tricks this month
Some interesting practical examples of using AI capabilities in the wild
Amazing achievement from DeepMind: AI achieves silver-medal standard solving International Mathematical Olympiad problems
"Today, we present AlphaProof, a new reinforcement-learning based system for formal math reasoning, and AlphaGeometry 2, an improved version of our geometry-solving system. Together, these systems solved four out of six problems from this year’s International Mathematical Olympiad (IMO), achieving the same level as a silver medalist in the competition for the first time.“Using AI to speed up nuclear power development: BYU engineering research finds key to quicker nuclear power: artificial intelligence
"Technically speaking, Memmott’s research proves the concept of replacing a portion of the required thermal hydraulic and neutronics simulations with a trained machine learning model to predict temperature profiles based on geometric reactor parameters that are variable, and then optimizing those parameters. The result would create an optimal nuclear reactor design at a fraction of the computational expense required by traditional design methods."Are you ready for a robot drilling your teeth?: Fully-automatic robot dentist performs world's first human procedure
“We’re excited to successfully complete the world's first fully automated robotic dental procedure,” says Dr. Chris Ciriello, CEO and Founder of Perceptive – and clearly a man well versed in the art of speaking in the driest, crustiest press release vernacular. “This medical breakthrough enhances precision and efficiency of dental procedures, and democratizes access to better dental care, for improved patient experience and clinical outcomes. We look forward to advancing our system and pioneering scalable, fully automated dental healthcare solutions for patients.”Today’s state-of-the-art components for the fastest possible time to first byte are: - WebRTC for sending audio from the user’s device to the cloud - Deepgram’s fast transcription (speech-to-text) models - Llama 3 70B or 8B - Deepgram’s Aura voice (text-to-speech) model We are targeting an 800ms median voice-to-voice response time. This architecture hits that target and in fact can achieve voice-to-voice response times as low as 500ms.
Interesting research showing the benefits of self driving cars even at low overall penetration: Self-Driving Cars Are Still The Best Way To Solve The Biggest Problem With Driving In America
"We found that when robot vehicles make up just 5% of traffic in our simulation, traffic jams are eliminated. Surprisingly, our approach even shows that when robot vehicles make up 60% of traffic, traffic efficiency is superior to traffic controlled by traffic lights."
Lots of great tutorials and how-to’s this month
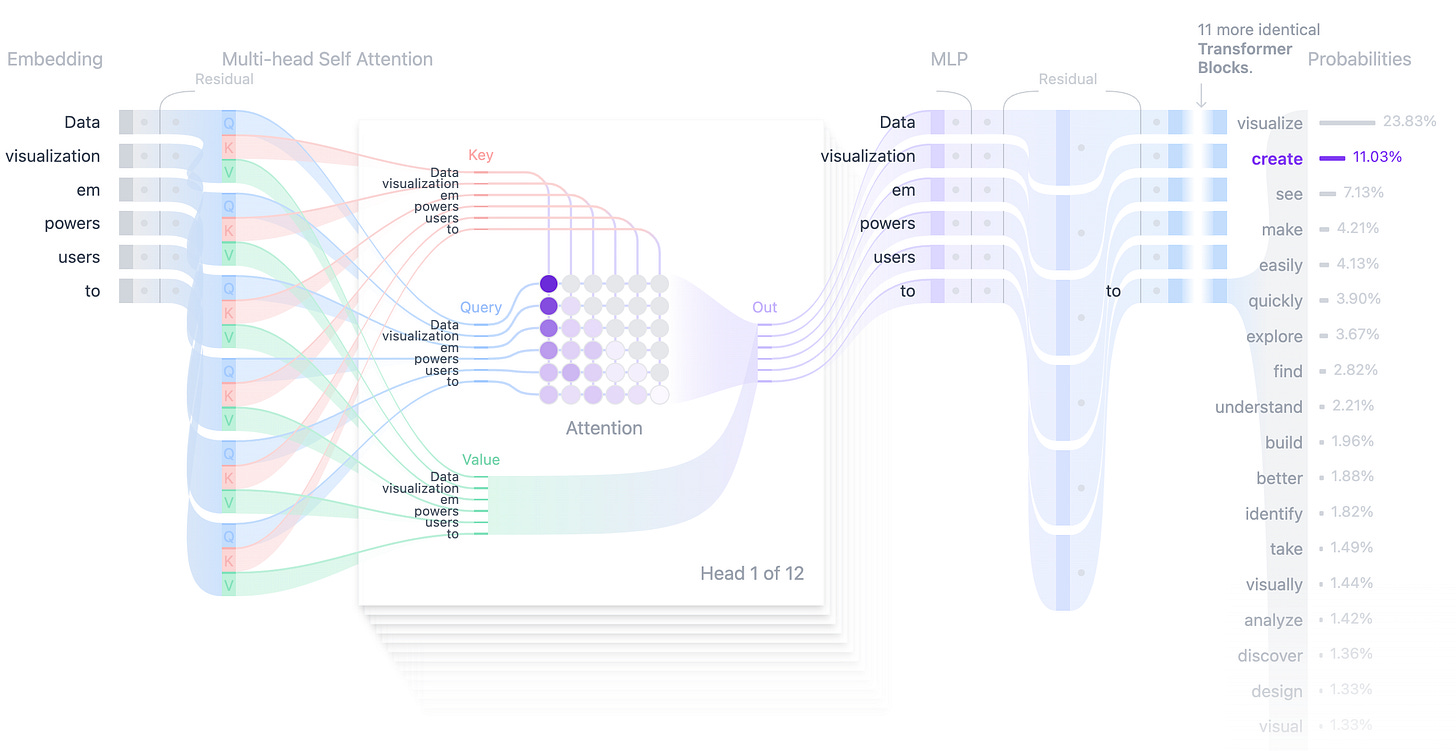
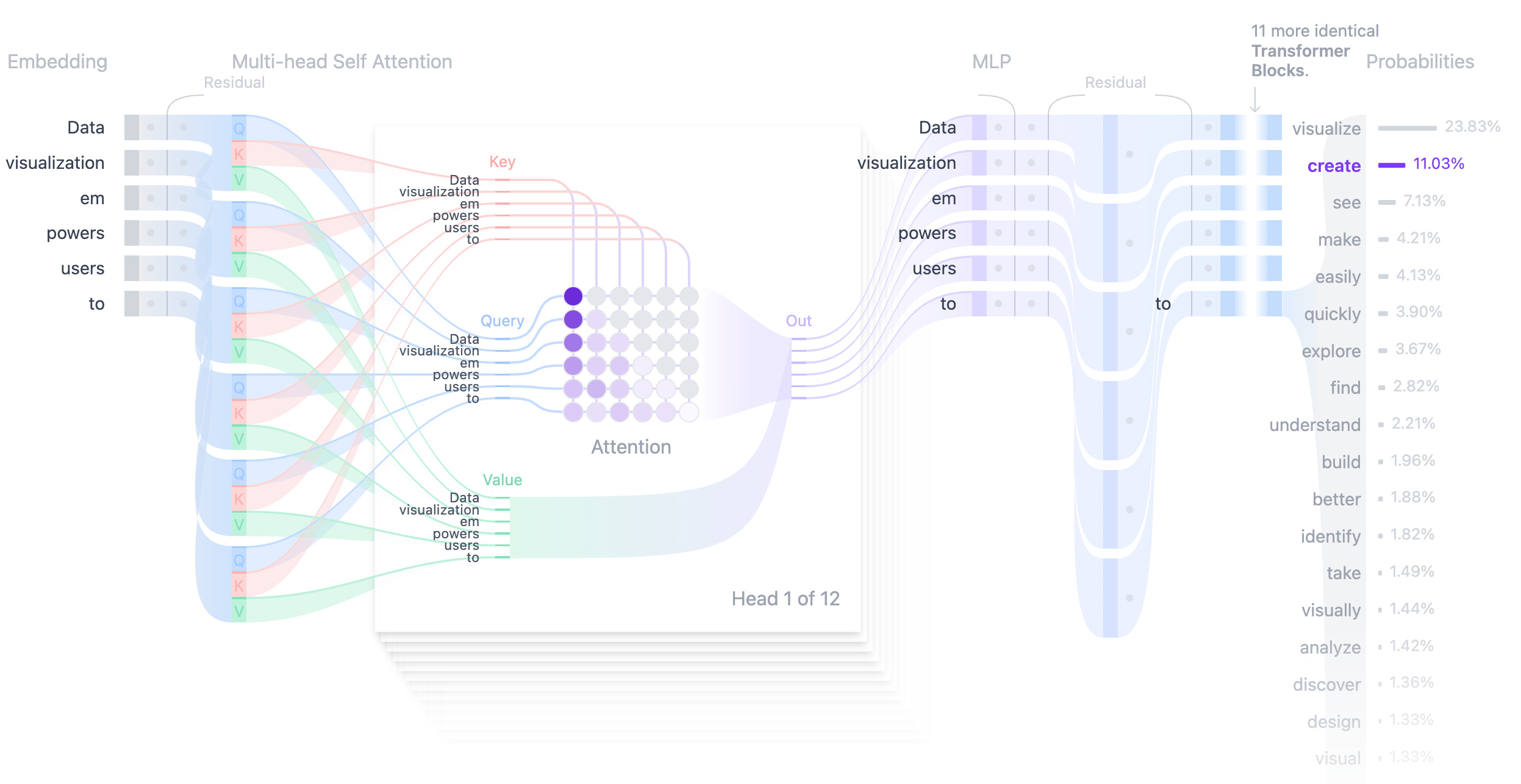
Beautiful interactive visualisation of how transformers work
Insight into how LLM’s work: Manipulating Chess-GPT's World Model
"This suggests a possible explanation for Chess-GPT’s poor performance on randomly initialized games. If a game begins with 20 random moves, the players are probably not high skill players. Chess-GPT is also a base model, with no RLHF or instruct tuning to learn a desired behavior of playing strong chess. If Chess-GPT truly was a good next token predictor, it would predict legal, low skill moves in the case of a randomly initialized game."Excellent step by step colab tutorial on fine tuning open source models from unsloth
Do graphs help with Retrieval Augmented Generation (RAG)?- GraphRAG Analysis, Part 1: How Indexing Elevates Vector Database Performance in RAG When Using Neo4j - maybe?

Very useful- Using LLMs for Evaluation

Finally, a useful primer on causality- Seven basic rules for causal inference
"These seven rules represent basic building blocks of causal inference. Most causal analysis procedures involve one or more of these rules to some extent. If you are completely new to formal causal inference, learning these rules can serve as a springboard to learn more complicated things. If you apply causal inference regularly in your own research then you might find this post useful as a cheat sheet. For a much more detailed introduction to causal inference, see Hernán and Robins (2020), and the Causal Diagrams course from HarvardX."


Practical tips
How to drive analytics, ML and AI into production
Good how-to guide to using Github Actions for MLOps- Implementing CI/CD Pipelines with GitHub Actions for MLOps
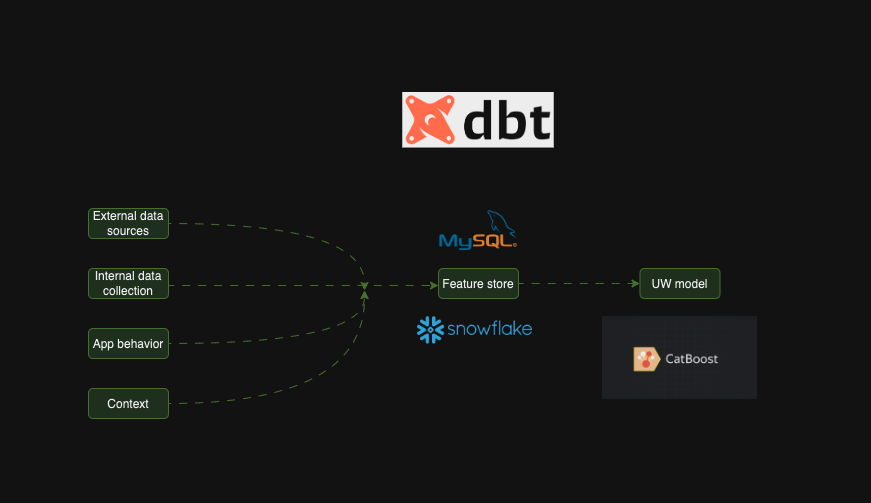
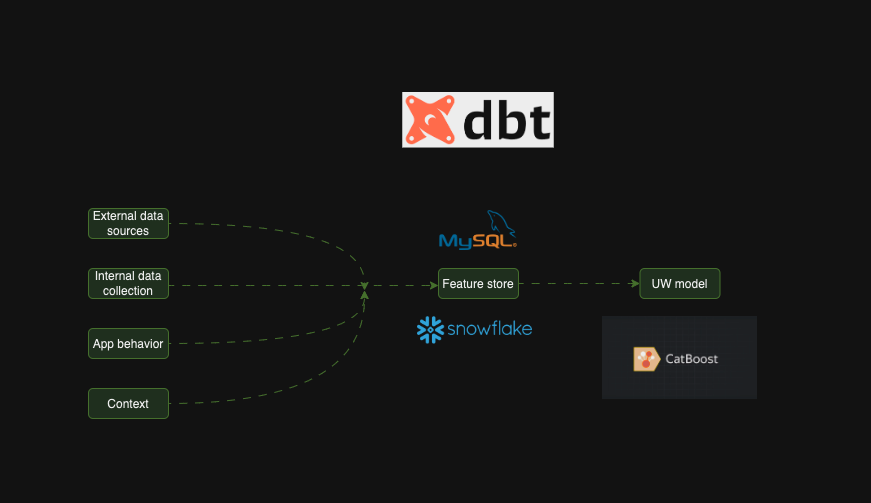
Another useful primer- Revolutionizing Feature Engineering: How We Built a Lean Feature Store with DBT, Snowflake, and MySQL
How to shrink that massive LLM model down to something you can use in production? Different Approaches to Model Compression

How to systematically improve your LLM app? Tactics for multi-step AI app experimentation
"Assuming a 90% accuracy of any step in our AI application, implies a 60% error for a 10-step application (cascading effects of failed sub-steps). Hence, quality assessment (QA) of every possible sub-step is crucial. It goes without saying that testing every sub-step simplifies identifying where to improve our application. How to exactly evaluate a given sub-step is domain specific. Yet, you might want to check out these lists of reference-free and referenced-based eval metrics for inspiration. Reference-free means that you don’t know the correct answer, while reference-based means that you have some ground truth data to check the output against. Typically, it becomes a lot easier to evaluate when you have some ground truth data to verify the output."Finally, a great post from Chip Huyen on system design for a generative AI platform



Bigger picture ideas
Longer thought provoking reads - sit back and pour a drink! ...
My trip to the frontier of AI education - Bill Gates
"In May, I had the chance to visit the First Avenue Elementary School, where they’re pioneering the use of AI education in the classroom. The Newark School District is piloting Khanmigo, an AI-powered tutor and teacher support tool, and I couldn’t wait to see it for myself. I’ve written a lot about Khanmigo on this blog. It was developed by Khan Academy, a terrific partner of the Gates Foundation. And I think Sal Khan, the founder of Khan Academy, is a visionary when it comes to harnessing the power of technology to help kids learn. (You can read my review of his new book, Brave New Words, here.) We’re still in the early days of using AI in classrooms, but what I saw in Newark showed me the incredible potential of the technology."AI-Driven Behavior Change Could Transform Health Care - Time Magazine
"Using AI in this way would also scale and democratize the life-saving benefits of improving daily habits and address growing health inequities. Those with more resources are already in on the power of behavior change, with access to trainers, chefs, and life coaches. But since chronic diseases—like diabetes and cardiovascular disease—are distributed unequally across demographics, a hyper-personalized AI health coach would help make healthy behavior changes easier and more accessible. For instance, it might recommend a healthy, inexpensive recipe that can be quickly made with few ingredients to replace a fast-food dinner."Raising children on the eve of AI - Julia Wise
“Even in the world where change is slower, more like the speed of the industrial revolution, I feel a bit like we’re preparing children to be good blacksmiths or shoemakers in 1750 when the factory is coming. The families around us are still very much focused on the track of do well in school > get into a good college > have a career > have a nice life. It seems really likely that chain will change a lot sometime in my children’s lifetimes.”Faith and Fate: Transformers as fuzzy pattern matchers - Alexis Gallagher
"The larger implication here is this: rather than think of models as working through the parts of a problem in a general and systematic way, it is often more accurate to think of them as search engines, recalling examples which roughly match that specific part of a problem before, and then stitching together such approximate recollections."Contra Acemoglu on AI - Maxwell Tabbarok
"The more important point is that the consumer-facing “generative AI” products that Acemoglu is referring to are just wrappers around the more general technology of transformers. Transformers are already being used to train robots, operate self driving cars, and improve credit card fraud detection. All examples of increasing the productivity of tasks already performed by machines. It is easier to get small productivity effects and ambiguous wage effects from AI if you assume that it will have zero impact on capital productivity."An AI Empire - J.K. Lund
" Regardless whether this theory is correct or not, our search for alien intelligence may be about to come to an end…because we will find it here on Earth first. In the 2020s, for the first time, humanity must confront the prospect of facing a “species” that is more intelligent than itself. How we handle this transition will make or break the 21st century."
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
Need to write a wikipedia style article? Fret no more - Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models
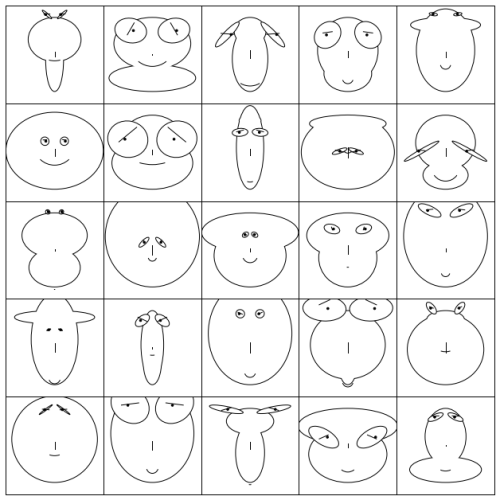
This looks great fun- DataViz in Python: Chernoff Faces with Matplotlib (hat tip Simon Raper)
Updates from Members and Contributors
Long time friend of the newsletter (and Polars core developer), Marco Gorelli, highlights his new python library Narwhals. It offers an extremely lightweight and extensible compatibility layer between dataframe libraries (pandas, Polars, cuDF, Modin, PyArrow, and more in progress) targeted at tool-builders, and has recently been adopted by visualisation giant Altair.
Sarah Phelps, from the ONS, highlights an upcoming webinar from the ESSnet Web Intelligence Network: Introduction to the Data Acquisition Service (DAS) of the Web Intelligence Hub, 17 September 2024. It will present the status
of the DAS development, give an insight into the available features, and provide a demo with different use cases. For more information and booking see here (you can see previous webinars on their YouTube channel)
Mia Hatton draws our attention to a series of three posts now on how the Department of Business and Trade are enabling responsible use of AI. In March they outlined the governance process, in July they shared how they collaborated with the Government Digital Service to explore how AI tools could support businesses, and in August they updated on the implementation of the governance process.
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
2 exciting new machine learning roles at Carbon Re- excellent climate change AI startup
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS