


July Newsletter
Industrial Strength Data Science and AI

Hi everyone-
It’s all go… Elections, Euros, Olympics about to start- perhaps time for some quiet AI and Data Science reading, maybe even in the sun!… I really encourage you to read on, but some edited highlights if you are short for time!
Claude Sonnet 3.5 looks to be a major contender to GPT-4o - free as well
Thinking of hosting your own LLM model? Might not be as cost effective as you think - Cost Of Self Hosting Llama-3 8B-Instruct
LLMs in healthcare - CRISPR-GPT: An LLM Agent for Automated Design of Gene-Editing Experiments
Great article (as always) from Benedict Evans- Building AI products
Always worth knowing what Geoff Hinton is up to! The ‘Godfather of AI’ quit Google a year ago. Now he’s emerged out of stealth to back a startup promising to use AI for carbon capture
Following is the July edition of our Data Science and AI newsletter (note we will take a summer break in August and be back bright and early in September). Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
We are continuing our work with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is accepting applications for the Advanced Data Science Professional certification as well as the new Data Science Professional certification.
We are running an event on July 17th from 6-7.30pm: ‘Designing the perfect data science project for every environment - Github repository templates’. Sign up here- hope you can make it!
"Starting up a new repository is often the first thing we do as data scientists on a new project. To help with this we have brought together three leading data scientists who will share the template repositories they have developed to support getting started on a new project quickly. Many projects have restrictions on internet access or have locked down IT systems. In this session we will talk through an ideal repository for working in a locked down environment and also where you have full reign to install anything you like."Also, the RSS Ethics section is running an in person meetup on July 12: ‘Can AI Respect Consumer Choices? Lessons from existing algorithmic systems’. Sign up here
Martin Goodson, CEO and Chief Scientist at Evolution AI, continues to run the excellent London Machine Learning meetup and is very active with events. The last event was on March 27th, when Meng Fang, Assistant Professor in AI at the University of Liverpool, presented "Large Language Models Are Neurosymbolic Reasoners”. Videos are posted on the meetup youtube channel - and future events will be posted here.
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
The battle over copyright is far from over- now it’s the turn of the music companies: Music labels sue AI companies Suno, Udio for US copyright infringement
"The lawsuits are the first to target music-generating AI following several cases brought by authors, news outlets and others over the alleged misuse of their work to train text-based AI models powering chatbots like OpenAI's ChatGPT. AI companies have argued that their systems make fair use of copyrighted material."AI regulation continues to get discussed at the highest levels although it is not entirely clear if it is progressing in any meaningful way: What we learned from the global AI summit in South Korea
"There’s an obvious objection here, which is that none of these agreements have teeth, or even really sufficient detail to identify whether or not someone is trying to follow them. “Companies determining what is safe and what is dangerous, and voluntarily choosing what to do about that, that’s problematic,” Francine Bennett, the interim director of the Ada Lovelace Institute, told me."Meanwhile the rationale for some sort of regulation of use cases becomes increasingly clear:
Shanghai District Tripling Mass Surveillance, Expanding Behavioral Analytics
"A sweeping mass surveillance expansion underway in central Shanghai will triple facial recognition cameras, and increase computing infrastructure by several times to power "the mining of massive data" across files for 50+ million citizens' everyday activities and behavior."It Looked Like a Reliable News Site. It Was an A.I. Chop Shop.
"During the two years that BNN was active, it had the veneer of a legitimate news service, claiming a worldwide roster of “seasoned” journalists and 10 million monthly visitors, surpassing the The Chicago Tribune’s self-reported audience. Prominent news organizations like The Washington Post, Politico and The Guardian linked to BNN’s stories. Google News often surfaced them, too. A closer look, however, would have revealed that individual journalists at BNN published lengthy stories as often as multiple times a minute, writing in generic prose familiar to anyone who has tinkered with the A.I. chatbot ChatGPT. BNN’s “About Us” page featured an image of four children looking at a computer, some bearing the gnarled fingers that are a telltale sign of an A.I.-generated image."
And while the underlying AI capabilities are very impressive, it is still very hard to tell fact from fiction- ChatGPT is bullshit
"We argue that these falsehoods, and the overall activity of large language models, is better understood as bullshit in the sense explored by Frankfurt (On Bullshit, Princeton, 2005): the models are in an important way indifferent to the truth of their outputs. We distinguish two ways in which the models can be said to be bullshitters, and argue that they clearly meet at least one of these definitions. We further argue that describing AI misrepresentations as bullshit is both a more useful and more accurate way of predicting and discussing the behaviour of these systems"This is a promising idea to try and gain more clarity on how good the models actually are. With test sets in the public domain, it is increasingly likely they leak into the training data of the big models, so proprietary test sets could be an answer. Good thread from Alexandr Wang, founder of Scale.ai
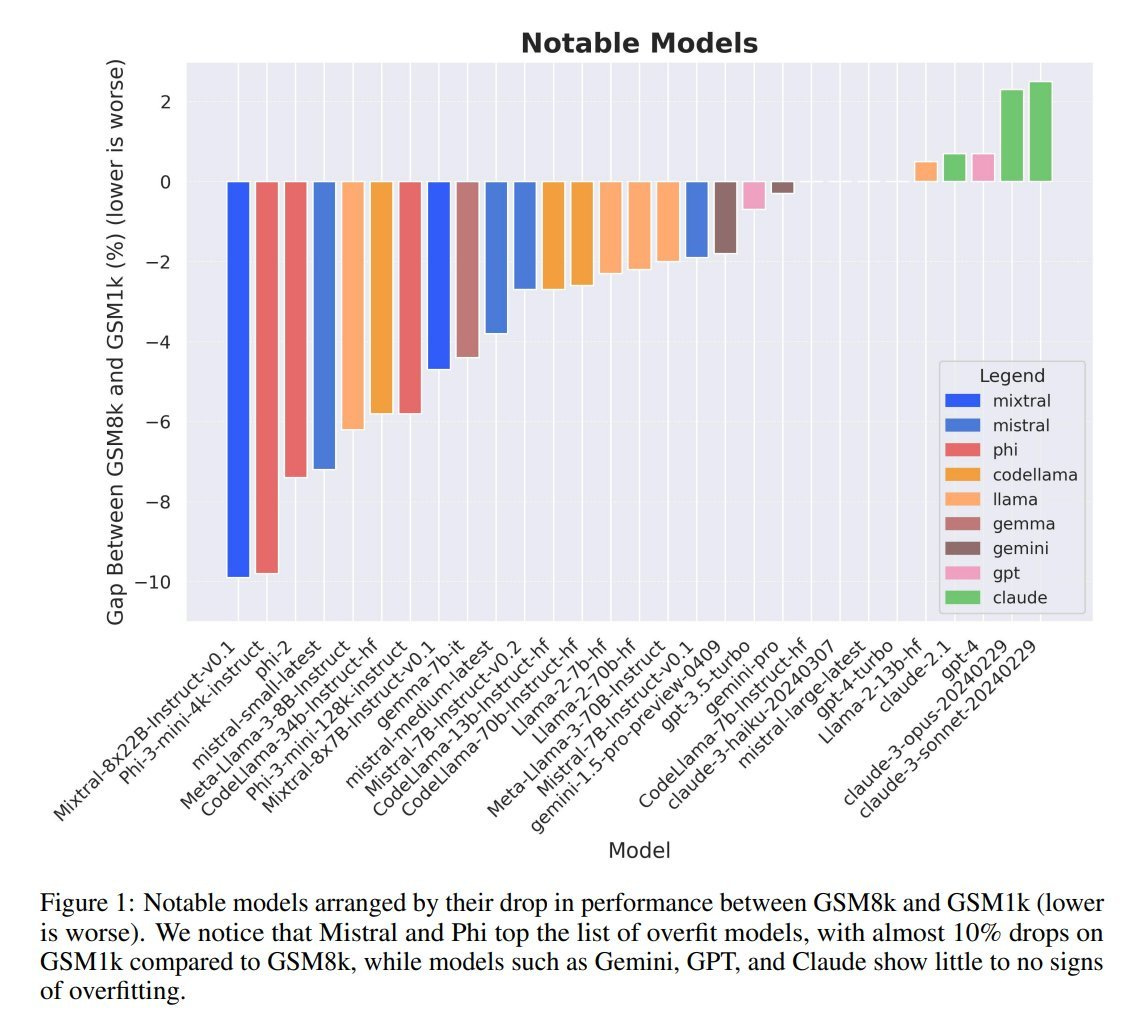
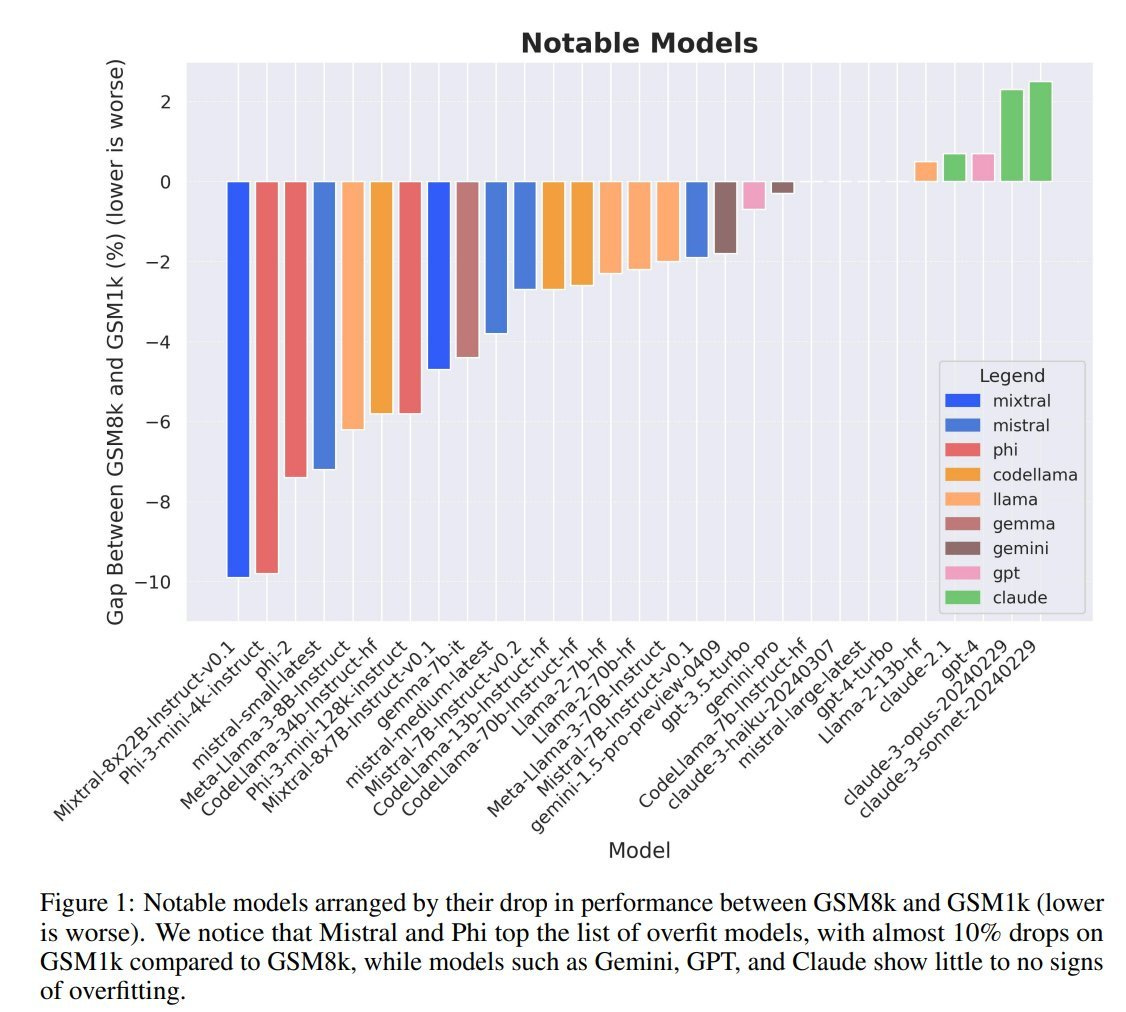
OpenAI’s ex-Chief Scientist is starting a new firm focused on safety; see also Haize Labs for automatic Red Teaming of LLMs
Ilya Sutskever, OpenAI’s co-founder and former chief scientist, is starting a new AI company focused on safety. In a post on Wednesday, Sutskever revealed Safe Superintelligence Inc. (SSI), a startup with “one goal and one product:” creating a safe and powerful AI system.And when even the most sophisticated tech players are struggling to release AI product and features, you know that doing this successfully is challenging
Microsoft’s Recall feature - Microsoft postpones Windows Recall after major backlash — will launch Copilot+ PCs without headlining AI feature
"In an unprecedented move, Microsoft has announced that its big Copilot+ PC initiative that was unveiled last month will launch without its headlining "Windows Recall" AI feature next week on June 18. The feature, which captures snapshots of your screen every few seconds, was revealed to store sensitive user data in an unencrypted state, raising serious concerns among security researchers and experts. "Google’s AI Overview search feature: AI Overviews: About last week
"But some odd, inaccurate or unhelpful AI Overviews certainly did show up. And while these were generally for queries that people don’t commonly do, it highlighted some specific areas that we needed to improve. One area we identified was our ability to interpret nonsensical queries and satirical content. Let’s take a look at an example: “How many rocks should I eat?” Prior to these screenshots going viral, practically no one asked Google that question. You can see that yourself on Google Trends.”
What do people actually think about generative AI? Good piece of research from the bbc (full report here)
"... People are nervous about how GenAI might be used in the media, including how it may impact creative roles, and they want reassurance from media companies about how they will engage with Gen AI. 65% of UK adults agree products and services using AI make them nervous."And finally, while the capabilities are clearly far from perfect, they are certainly good enough to start to dramatically effect individual jobs and job functions. Ashton Kutcher Says Soon ‘You’ll Be Able to Render a Whole Movie’ Using AI: ‘The Bar Is Going to Have to Go Way Up’ in Hollywood
Kutcher added that, while playing around with the software, he prompted Sora to create footage of a runner trying to escape a desert sandstorm. “I didn’t have to hire a CGI department to do it,” Kutcher said. “I, in five minutes, rendered a video of an ultramarathoner running across the desert being chased by a sandstorm. And it looks exactly like that.”
Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
A great deal of effort going into understanding how to improve and enhance LLMs
How to reduce size without impacting performance: LayerMerge: Neural Network Depth Compression through Layer Pruning and Merging
"To this end, we propose LayerMerge, a novel depth compression method that selects which activation layers and convolution layers to remove, to achieve a desired inference speed-up while minimizing performance loss. Since the corresponding selection problem involves an exponential search space, we formulate a novel surrogate optimization problem and efficiently solve it via dynamic programming. Empirical results demonstrate that our method consistently outperforms existing depth compression and layer pruning methods on various network architectures, both on image classification and generation tasks."In the same spirit of getting smaller models to perform well: Orca 2: Teaching Small Language Models How to Reason
"We seek to teach small LMs to employ different solution strategies for different tasks, potentially different from the one used by the larger model. For example, while larger models might provide a direct answer to a complex task, smaller models may not have the same capacity. In Orca 2, we teach the model various reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer, etc.). More crucially, we aim to help the model learn to determine the most effective solution strategy for each task"Looking specifically at change detection for remote sensing: ChangeViT: Unleashing Plain Vision Transformers for Change Detection
"Despite the success of vision transformers (ViTs) as backbones in numerous computer vision applications, they remain underutilized in change detection, where convolutional neural networks (CNNs) continue to dominate due to their powerful feature extraction capabilities. In this paper, our study uncovers ViTs' unique advantage in discerning large-scale changes, a capability where CNNs fall short."This looks very impressive for zero shot text to speech: VALL-E 2 from Microsoft. See impressive demos here
"Our experiments on the LibriSpeech and VCTK datasets show that VALL-E 2 surpasses previous systems in speech robustness, naturalness, and speaker similarity. It is the first of its kind to reach human parity on these benchmarks. Moreover, VALL-E 2 consistently synthesizes high-quality speech, even for sentences that are traditionally challenging due to their complexity or repetitive phrases. The advantages of this work could contribute to valuable endeavors, such as generating speech for individuals with aphasia or people with amyotrophic lateral sclerosis."The latest in the line of ‘Chain-Of’ approaches… Chain of Preference Optimization: Improving Chain-of-Thought Reasoning in LLMs
"In this work, we demonstrate that fine-tuning LLMs leveraging the search tree constructed by Tree-of-thought (ToT) allows Chain-of-thoughts (CoT) to achieve similar or better performance, thereby avoiding the substantial inference burden. This is achieved through Chain of Preference Optimization (CPO), where LLMs are fine-tuned to align each step of the CoT reasoning paths with those of ToT using the inherent preference information in the tree-search process"And the latest in the line of Retrieval Augmented Generation (RAG) approaches: PlanRAG: A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers
"To address Decision QA effectively, we also propose a new RAG technique called the iterative plan-then-retrieval augmented generation (PlanRAG). Our PlanRAG-based LM generates the plan for decision making as the first step, and the retriever generates the queries for data analysis as the second step. The proposed method outperforms the state-of-the-art iterative RAG method by 15.8% in the Locating scenario and by 7.4% in the Building scenario, respectively."
More research digging into some of the failings of existing models:
Really interesting - models apparently know when they are hallucinating: Understanding Hallucinations in Diffusion Models through Mode Interpolation
"Finally, we show that diffusion models in fact know when they go out of support and hallucinate. This is captured by the high variance in the trajectory of the generated sample towards the final few backward sampling process. Using a simple metric to capture this variance, we can remove over 95% of hallucinations at generation time while retaining 96% of in-support samples. We conclude our exploration by showing the implications of such hallucination (and its removal) on the collapse (and stabilization) of recursive training on synthetic data with experiments on MNIST and 2D Gaussians dataset"Adversarial Attacks on Multimodal Agents

It’s all about the data! Can we get better training data by using the models themselves to improve it?
What If We Recaption Billions of Web Images with LLaMA-3?
"Our recaptioning pipeline is simple: first, we fine-tune a LLaMA-3-8B powered LLaVA-1.5 and then employ it to recaption 1.3 billion images from the DataComp-1B dataset. Our empirical results confirm that this enhanced dataset, Recap-DataComp-1B, offers substantial benefits in training advanced vision-language models. For discriminative models like CLIP, we observe enhanced zero-shot performance in cross-modal retrieval tasks. For generative models like text-to-image Diffusion Transformers, the generated images exhibit a significant improvement in alignment with users' text instructions, especially in following complex queries""In this paper, we introduce AutoIF, the first scalable and reliable method for automatically generating instruction-following training data. AutoIF transforms the validation of instruction-following data quality into code verification, requiring LLMs to generate instructions, the corresponding code to check the correctness of the instruction responses, and unit test samples to verify the code's correctness. Then, execution feedback-based rejection sampling can generate data for Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) training"
A systematic approach to prompt optimisation: Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs
"To make this tractable, we factorize our problem into optimizing the free-form instructions and few-shot demonstrations of every module and introduce several strategies to craft task-grounded instructions and navigate credit assignment across modules. Our strategies include (i) program- and data-aware techniques for proposing effective instructions, (ii) a stochastic mini-batch evaluation function for learning a surrogate model of our objective, and (iii) a meta-optimization procedure in which we refine how LMs construct proposals over time. Using these insights we develop MIPRO, a novel optimizer that outperforms baselines on five of six diverse LM programs using a best-in-class open-source model (Llama-3-8B), by as high as 12.9% accuracy"Some more specific and diverse applications of foundation models:
How do we get better at less prevalent languages: IrokoBench: A New Benchmark for African Languages in the Age of Large Language Models
"In this paper, we introduce IrokoBench -- a human-translated benchmark dataset for 16 typologically-diverse low-resource African languages covering three tasks: natural language inference~(AfriXNLI), mathematical reasoning~(AfriMGSM), and multi-choice knowledge-based QA~(AfriMMLU). We use IrokoBench to evaluate zero-shot, few-shot, and translate-test settings~(where test sets are translated into English) across 10 open and four proprietary LLMs. Our evaluation reveals a significant performance gap between high-resource languages~(such as English and French) and low-resource African languages. We observe a significant performance gap between open and proprietary models, with the highest performing open model, Aya-101 only at 58\% of the best-performing proprietary model GPT-4o performance. "Understanding Meerkats? animal2vec and MeerKAT: A self-supervised transformer for rare-event raw audio input and a large-scale reference dataset for bioacoustics
"First, we present the animal2vec framework: a fully interpretable transformer model and self-supervised training scheme tailored for sparse and unbalanced bioacoustic data. Second, we openly publish MeerKAT: Meerkat Kalahari Audio Transcripts, a large-scale dataset containing audio collected via biologgers deployed on free-ranging meerkats with a length of over 1068h, of which 184h have twelve time-resolved vocalization-type classes, each with ms-resolution, making it the largest publicly-available labeled dataset on terrestrial mammals"
Increasingly promising developments in the medical space:
CARES: A Comprehensive Benchmark of Trustworthiness in Medical Vision Language Models
"However, the trustworthiness of Med-LVLMs remains unverified, posing significant risks for future model deployment. In this paper, we introduce CARES and aim to comprehensively evaluate the Trustworthiness of Med-LVLMs across the medical domain. We assess the trustworthiness of Med-LVLMs across five dimensions, including trustfulness, fairness, safety, privacy, and robustness. CARES comprises about 41K question-answer pairs in both closed and open-ended formats, covering 16 medical image modalities and 27 anatomical regions. Our analysis reveals that the models consistently exhibit concerns regarding trustworthiness, often displaying factual inaccuracies and failing to maintain fairness across different demographic groups. "LlamaCare: A Large Medical Language Model for Enhancing Healthcare Knowledge Sharing
"In this paper, we proposed LlamaCare, a fine-tuned medical language model, and Extended Classification Integration(ECI), a module to handle classification problems of LLMs. Our contributions are : (i) We fine-tuned a large language model of medical knowledge with very low carbon emissions and achieved similar performance with ChatGPT by a 24G GPU. (ii) We solved the problem of redundant categorical answers and improved the performance of LLMs by proposing a new module called Extended Classification Integration. (iii) We released our processed data for one-shot and few-shot training for some benchmarks such as PubMedQA and USMLE 1-3 step."CRISPR-GPT: An LLM Agent for Automated Design of Gene-Editing Experiments
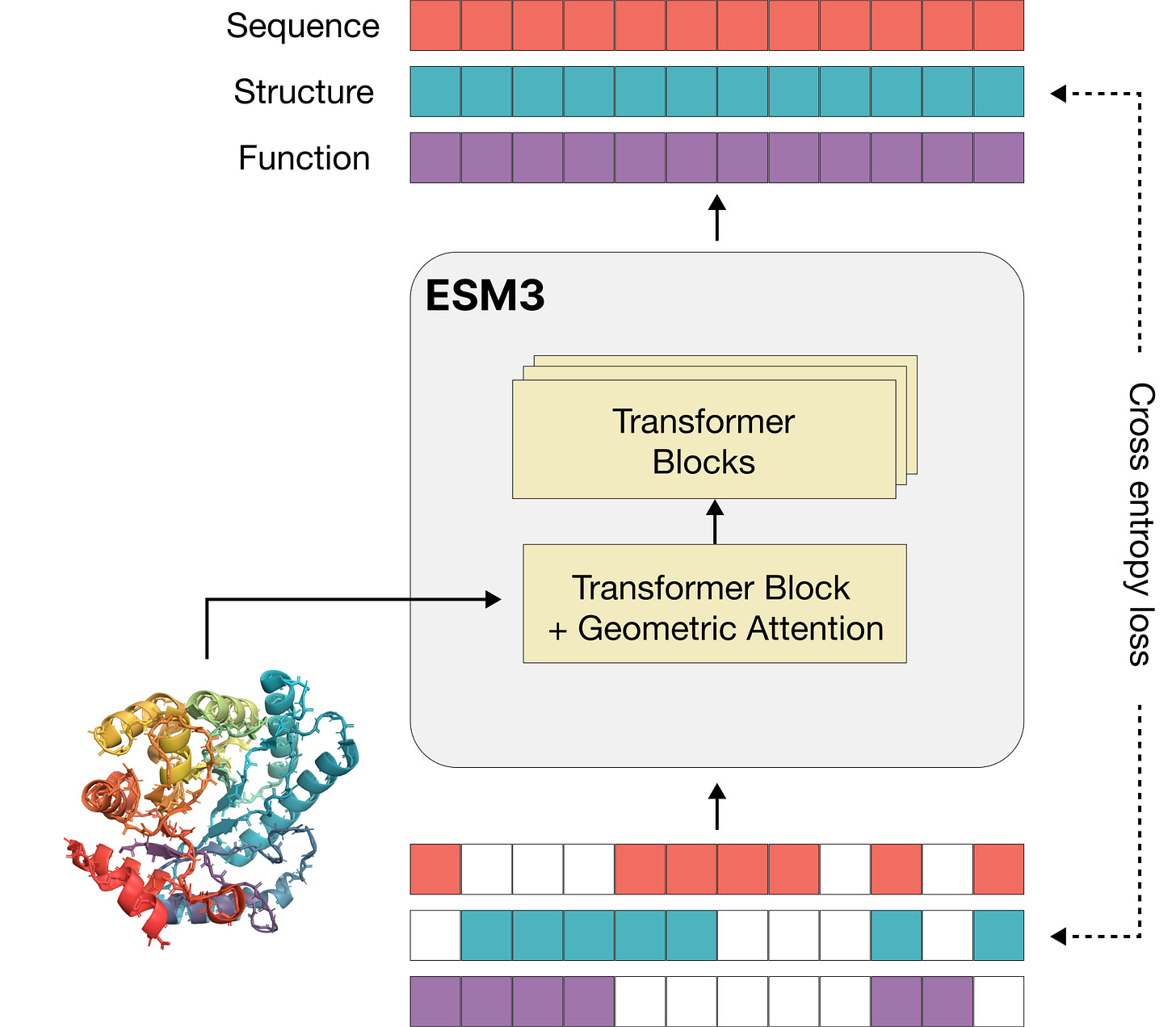
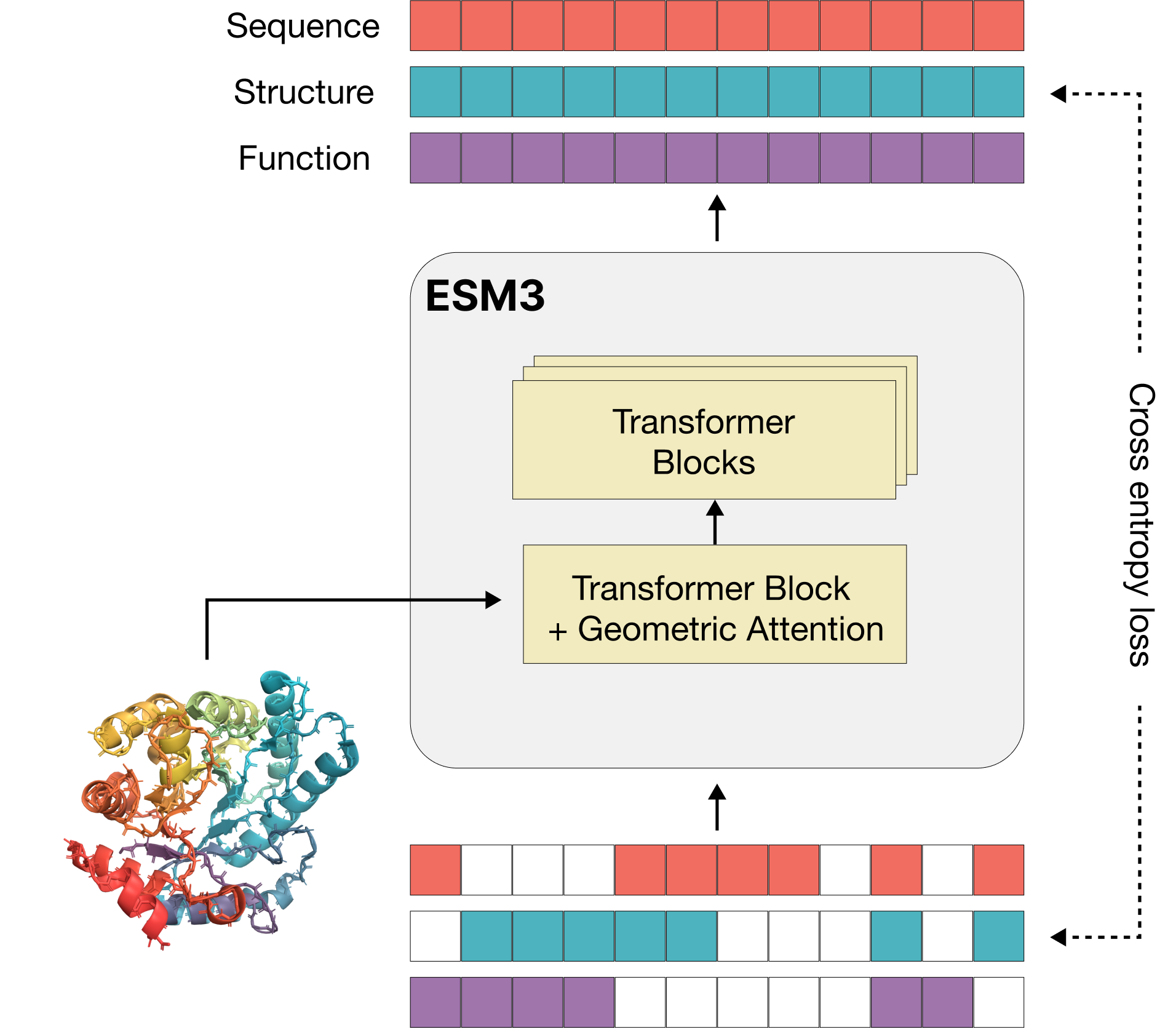
"In this work, we introduce CRISPR-GPT, an LLM agent augmented with domain knowledge and external tools to automate and enhance the design process of CRISPR-based gene-editing experiments. CRISPR-GPT leverages the reasoning ability of LLMs to facilitate the process of selecting CRISPR systems, designing guide RNAs, recommending cellular delivery methods, drafting protocols, and designing validation experiments to confirm editing outcomes. We showcase the potential of CRISPR-GPT for assisting non-expert researchers with gene-editing experiments from scratch and validate the agent's effectiveness in a real-world use case."And this looks very interesting - ESM3: Simulating 500 million years of evolution with a language model (and they have raised $140m!)
Finally.. another time series approach! TimeSieve: Extracting Temporal Dynamics through Information Bottlenecks
"Our approach employs wavelet transforms to preprocess time series data, effectively capturing multi-scale features without the need for additional parameters or manual hyperparameter tuning. Additionally, we introduce the information bottleneck theory that filters out redundant features from both detail and approximation coefficients, retaining only the most predictive information. This combination reduces significantly improves the model's accuracy. Extensive experiments demonstrate that our model outperforms existing state-of-the-art methods on 70\% of the datasets, achieving higher predictive accuracy and better generalization across diverse datasets."

Generative AI ... oh my!
Still moving at such a fast pace it feels in need of it's own section, for developments in the wild world of large language models...
As always seems to be the case, all sorts of news from OpenAI
Getting a little more product focused - OpenAI welcomes Sarah Friar (CFO) and Kevin Weil (CPO)
Building out their retrieval infrastructure - OpenAI acquires Rockset; and also Multi
Following on from Anthropic’s interesting explainability work, OpenAI’s version- Extracting Concepts from GPT-4
"Unlike with most human creations, we don’t really understand the inner workings of neural networks. For example, engineers can directly design, assess, and fix cars based on the specifications of their components, ensuring safety and performance. However, neural networks are not designed directly; we instead design the algorithms that train them. The resulting networks are not well understood and cannot be easily decomposed into identifiable parts. This means we cannot reason about AI safety the same way we reason about something like car safety."And some positive work combating covert use cases: Disrupting deceptive uses of AI by covert influence operations
"In the last three months, we have disrupted five covert IO that sought to use our models in support of deceptive activity across the internet. As of May 2024, these campaigns do not appear to have meaningfully increased their audience engagement or reach as a result of our services. "
Google also continues to innovate at pace with the new ‘Flash’ models looking particularly compelling in the trade-off between speed and accuracy: Gemini 1.5 Pro and 1.5 Flash GA, 1.5 Flash tuning support, higher rate limits, and more API updates
"Gemini 1.5 Flash was purpose-built as our fastest, most cost-efficient model yet for high volume tasks, at scale, to address developers’ feedback asking for lower latency and cost. Today, we are increasing the rate limit for 1.5 Flash to 1000 requests per minute (RPM) and removing the request per day limit. "Anthropic have been busy
Claude Sonnet 3.5 looks to be a major contender to GPT-4o - free as well

And some interesting revelations about Claude’s ‘character’
"Claude 3 was the first model where we added "character training" to our alignment finetuning process: the part of training that occurs after initial model training, and the part that turns it from a predictive text model into an AI assistant. The goal of character training is to make Claude begin to have more nuanced, richer traits like curiosity, open-mindedness, and thoughtfulness."
Microsoft’s announcements this month were all about building AI into their products: Copilot Runtime: Building AI into Windows
While Apple made a big splash about AI at their developer conference- very focused on narrow and contained use cases embedded in products
Apple Intelligence: every new AI feature coming to the iPhone and Mac
Their research is clearly focusing on edge AI- on device models
"Apple Intelligence is comprised of multiple highly-capable generative models that are specialized for our users’ everyday tasks, and can adapt on the fly for their current activity. The foundation models built into Apple Intelligence have been fine-tuned for user experiences such as writing and refining text, prioritizing and summarizing notifications, creating playful images for conversations with family and friends, and taking in-app actions to simplify interactions across apps."And for tasks requiring larger models, they seem to be outsourcing to OpenAI: OpenAI and Apple announce partnership to integrate ChatGPT into Apple experiences (although it looks like Apple is not paying OpenAI directly)
Lots of open source development as well
Microsoft released Florence-2: Open Source Vision Foundation Model
Apple researchers add 20 more open-source models to improve text and image AI
And Meta has also been very productive:
Meta Open-Sources MEGALODON LLM for Efficient Long Sequence Modeling
Meta Chameleon - processing and generating both text and images
While Nvidia now has a model (Nemotron-4 340B) that is topping the reward bench leaderboard
New open source models from Stability.ai
Introducing Stable Audio Open - An Open Source Model for Audio Samples and Sound Design - check out the examples in the link, very impressive
Announcing the Open Release of Stable Diffusion 3 Medium

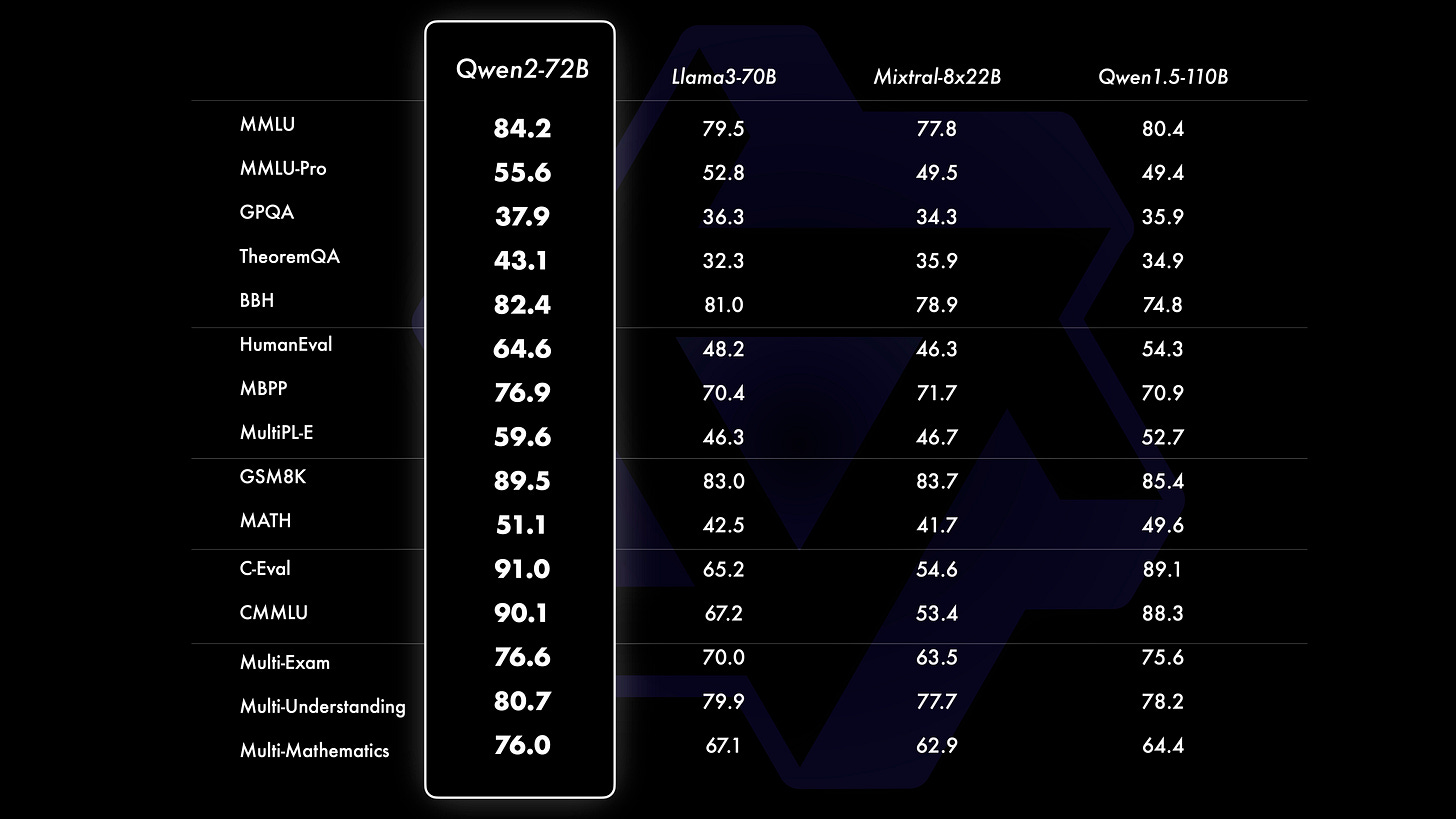
Qwen2 looks very powerful - from Alibaba Cloud in China
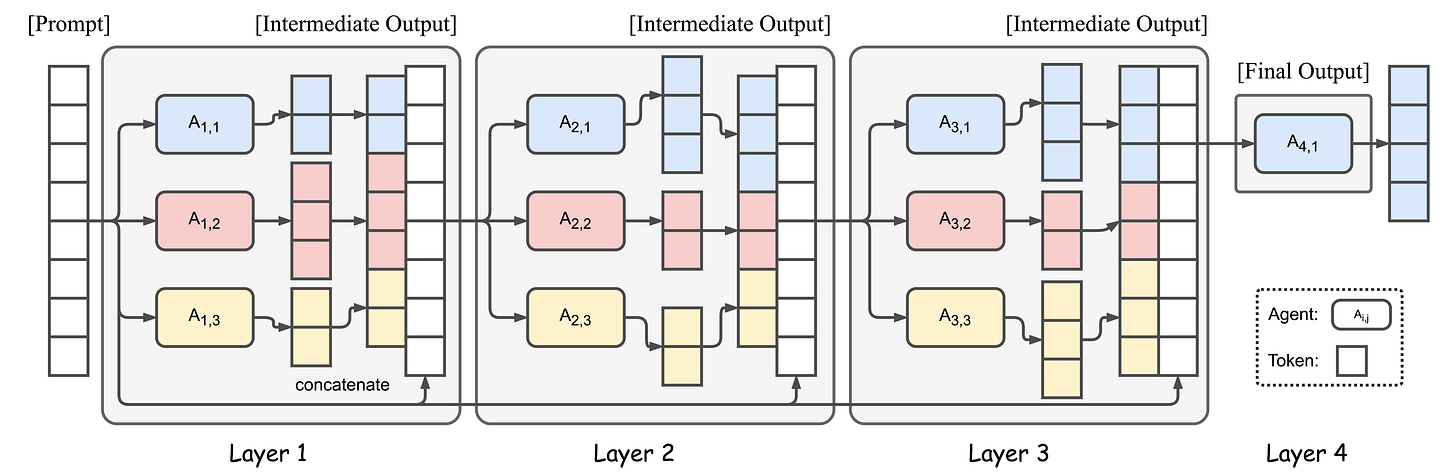
While Together.ai seems to be having a lot of success blending leading models together using an approach they call ‘Mixture of Agents’
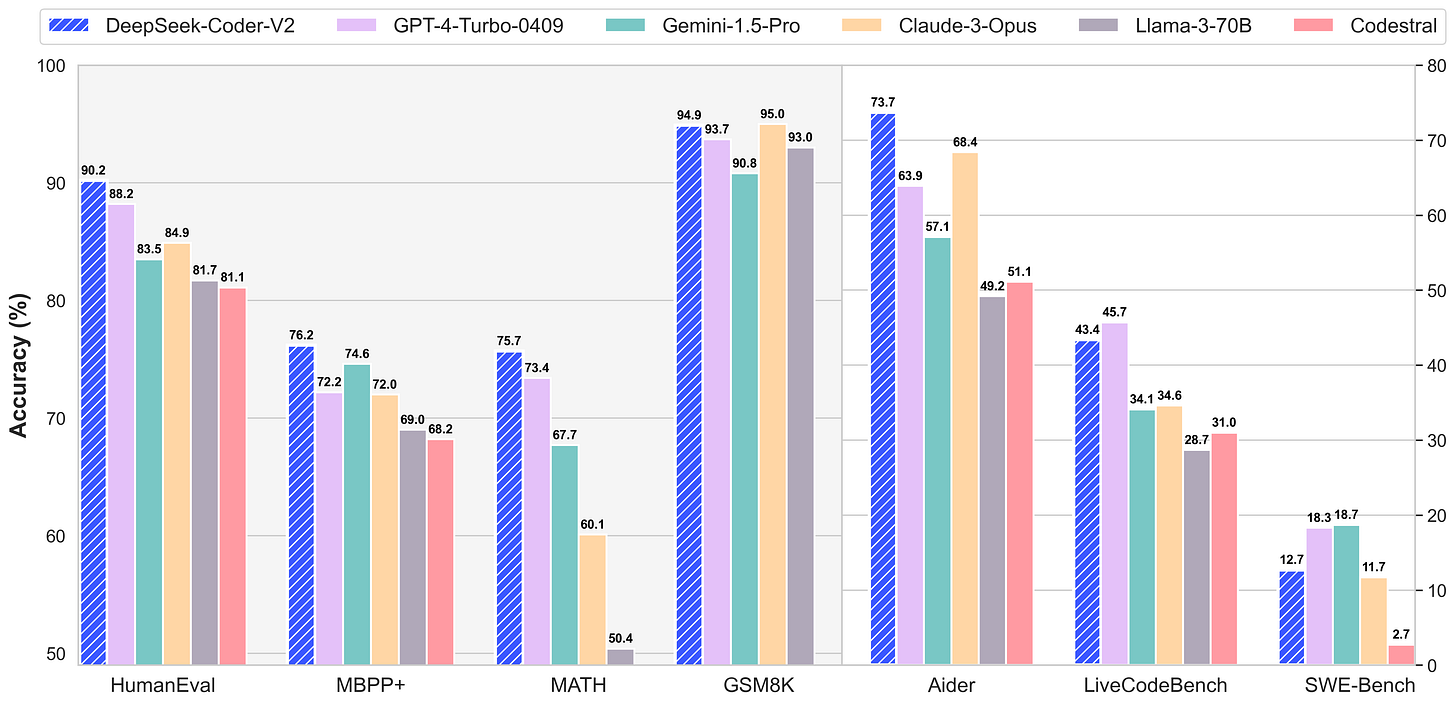
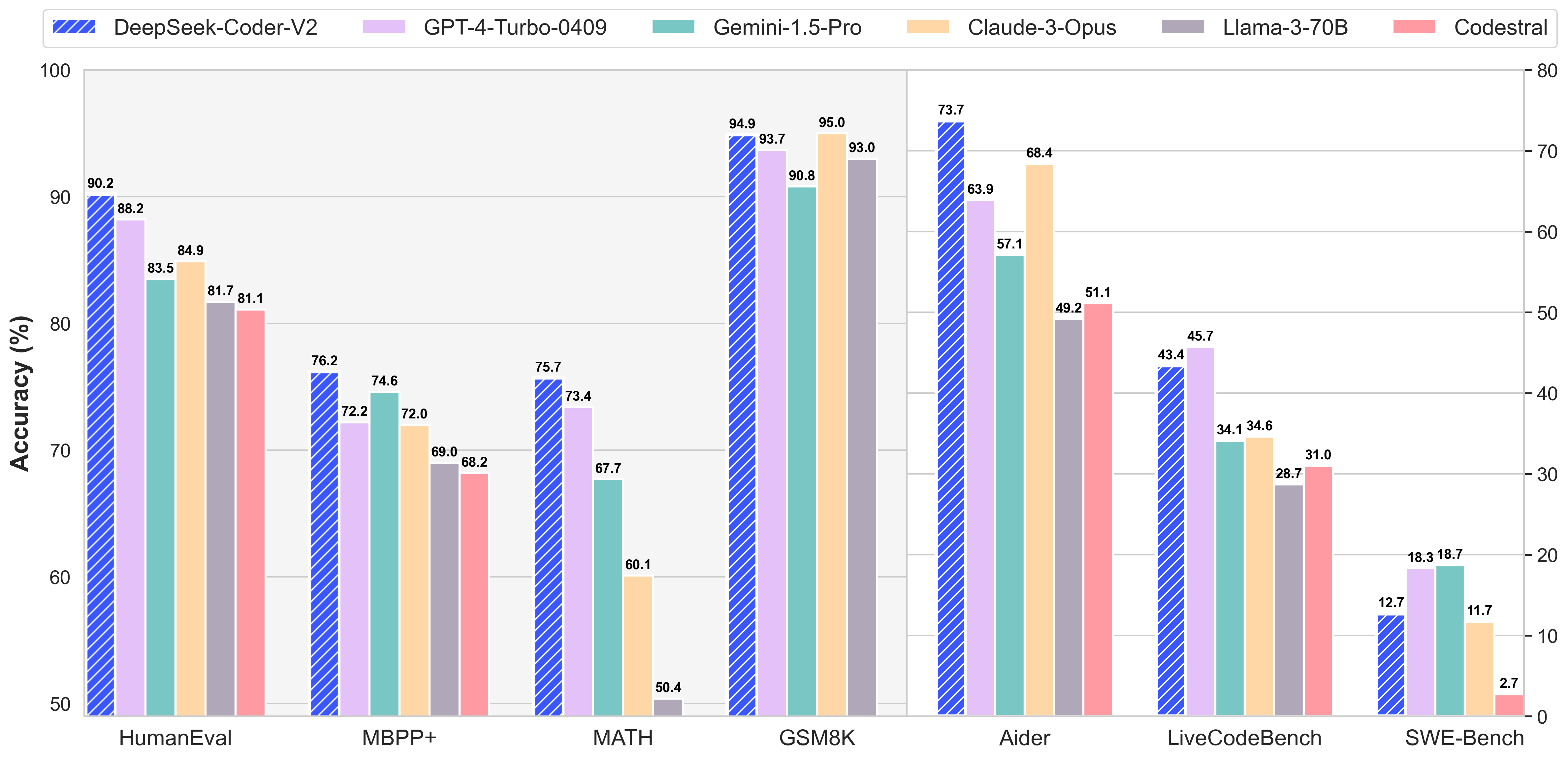
Finally, when it comes to coding, DeepSeek seems to be the leading model right now: DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
And if its a coding agent you want, then OpenDevin to the rescue

Ending with the elegant approach of Sakana - ‘Can LLMs invent better ways to train LLMs?’
"As researchers, we are thrilled by the potential of our method to discover new optimization algorithms with minimal human intervention. This not only reduces the need for extensive computational resources but also opens new avenues for exploring the vast search space of optimal loss functions, ultimately enhancing the capabilities of LLMs in various applications. Ultimately, we envision a self-referential process in which advancements in AI research feedback into faster and more efficient discovery of scientific advancements.



Real world applications and how to guides
Lots of applications and tips and tricks this month
Some interesting practical examples of using AI capabilities in the wild
AI Project Management from Asana
"When I asked Asana cofounder and CEO Dustin Moskovitz about positioning AI as a team member, he emphasized the proactive nature of the new features—especially compared to chatbot-style AI that sits in a window of its own and doesn’t spring into action until called upon. “It’s less about thinking of it as this separate thing on the side and more something that is in the workflow, as if it was another human,” he told me. “In many cases, I do think the outputs are as good as humans. Sometimes they’re superhuman.“A new image generation model based on shutterstock images from DataBricks
"ImageAI addresses these challenges by enabling companies to use AI to quickly and confidently create new high-resolution, photorealistic images that are commercially viable because the model was trained entirely on Shutterstock’s trusted collection of curated images."This looks worth exploring if you are working on recommendations: XRec: Large Language Models for Explainable Recommendation

`DeepMind’s new AI generates soundtracks and dialogue for videos - see release here
"DeepMind’s V2A tech takes the description of a soundtrack (e.g. “jellyfish pulsating under water, marine life, ocean”) paired with a video to create music, sound effects and even dialogue that matches the characters and tone of the video, watermarked by DeepMind’s deepfakes-combating SynthID technology. The AI model powering V2A, a diffusion model, was trained on a combination of sounds and dialogue transcripts as well as video clips, DeepMind says."And some good progress on software agents from Google:
AI in software engineering at Google: Progress and the path ahead
"Key improvements came from both the models — larger models with improved coding capabilities, heuristics for constructing the context provided to the model, as well as tuning models on usage logs containing acceptances, rejections and corrections — and the UX. This cycle is essential for learning from practical behavior, rather than synthetic formulations."
Route optimisation for shipping! Heuristics on the high seas: Mathematical optimization for cargo ships
"To improve their scalability, we applied a heuristic strategy using two variants of local search in which we examine neighborhoods around existing solutions to find opportunities for improvements. Large neighborhood search We fixed parts of the solution (e.g., "this vessel will visit Los Angeles on alternate Tuesdays") before applying either of the methods described above. This improves scalability by reducing the search space. Variable neighborhood search We explored neighborhoods over both the network and the schedule. We parallelize the exploration and distribute it over multiple machines to evaluate many neighborhoods simultaneously. This also improves scalability by limiting the search space, while also allowing us to incorporate knowledge from Operations Research and the shipping industry."And if you ever need to optimise a tokamak fusion reactor … TORAX?
How can AI help physicists search for new particles?

Always worth knowing what Geoff Hinton is up to! The ‘Godfather of AI’ quit Google a year ago. Now he’s emerged out of stealth to back a startup promising to use AI for carbon capture
“Humanity will face many challenges in the coming decade. Some will be caused by AI while others can be solved by AI,” Hinton said. “I’ve been very impressed by CuspAI and its mission to accelerate the design process of new materials using AI to curb one of humanity’s most urgent challenges—climate change.”
Lots of great tutorials and how-to’s this month
"Let's imagine inventing a new game intended to teach children how to unleash their creativity and come up with fictional stories. Left to their own devices, children will typically write about topics that interest them. But our intention is to broaden their horizons and encourage them to think outside the box, to be comfortable ideating and crafting stories about any topic."Useful insight into interpretability- Prism: mapping interpretable concepts and features in a latent space of language (see also Logit Prisms: Decomposing Transformer Outputs for Mechanistic Interpretability)
"This work explores a scalable, automated way to directly probe embedding vectors representing sentences in a small language model and “map out” what human-interpretable attributes are represented by specific directions in the model’s latent space. A human-legible map of models’ latent spaces opens doors to dramatically richer ways of interacting with information and foundation models, which I hope to explore in future research. In this work, I share two primitives that may be a part of such interfaces: detailed decomposition of concepts and styles in language and precise steering of high-level semantic text edits."Using LLMs for classification tasks: Transforming Next-Token Prediction into Classification with LLMs
"Given this, can we replace the vocabulary with the classification labels? Yes we can! Instead of predicting the next token from the vocabulary, we are interested in predicting the category of a classification task given preceding context tokens. It is feasible by changing the LLMs’ head, commonly implemented as, lm_head . In text generation, the lm_head has a shape of (embedding dimension, vocabulary size) . For classification, we modify it to (embedding dimension, number of classification) ."How to get the best results from Stable Diffusion 3

Useful tutorial for anyone working on geospatial data- Spatial ML: Predicting on out-of-sample data
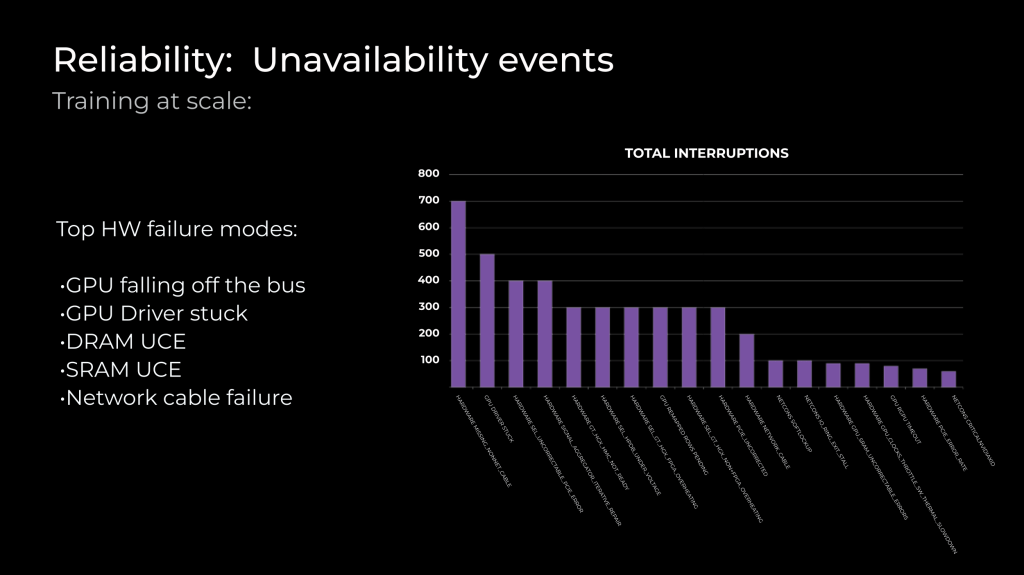
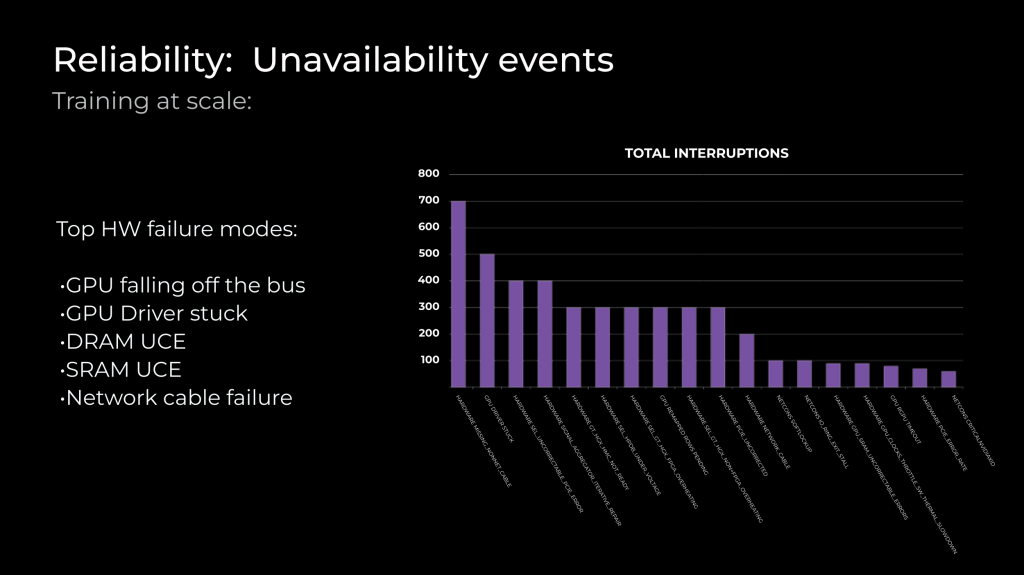
Ending with a bang… if you happen to want to train your own LLM- How Meta trains large language models at scale. And if you did want to train your own LLM- this looks like the best open source data set to use (FineWeb: decanting the web for the finest text data at scale)



Practical tips
How to drive analytics and ML into production
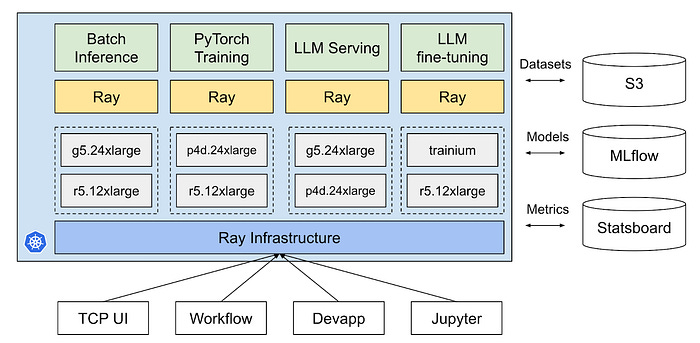
Interesting post from Pintrest on how they use Ray for their MLOps infrastructure
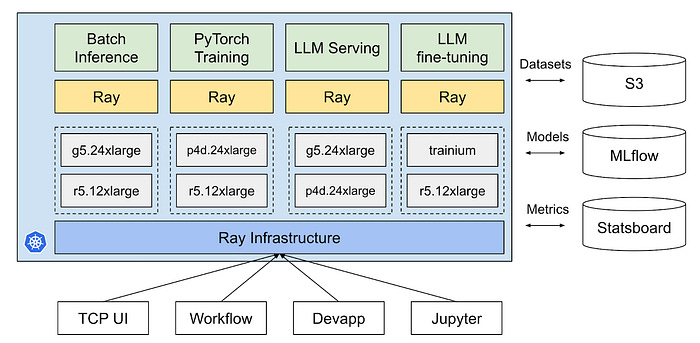
A rather simpler option- ML Ops with PyTest
"What we’d like to do in non-deterministic tests is to measure values considering uncertainty. Whenever we talk about uncertainty, probability and statistics come into play, and we will make use of them here as well. A common practice is to evaluate the values of a dataset we are currently working on by comparing it with previous versions."Looking to get an LLM app into production- this might be worth checking out: Glide: Cloud-Native LLM Gateway for Seamless LLMOps

Interesting and thought provoking- Why we no longer use LangChain for building our AI agents
"We used LangChain in production for over 12 months, starting in early 2023 then removing it in 2024. LangChain seemed to be the best choice for us in 2023. It had an impressive list of components and tools, and its popularity soared. It promised to “enable developers to go from an idea to working code in an afternoon.” But problems started to surface as our requirements became more sophisticated, turning LangChain into a source of friction, not productivity. As its inflexibility began to show, we soon found ourselves diving into LangChain internals, to improve lower-level behavior of our system. But because LangChain intentionally abstracts so many details from you, it often wasn’t easy or possible to write the lower-level code we needed to."Useful insight from Character.ai- Optimizing AI Inference at Character.AI
"The key bottleneck of LLM inference throughput is the size of the cache of attention keys and values (KV). It not only determines the maximum batch size that can fit on a GPU, but also dominates the I/O cost on attention layers. We use the following techniques to reduce KV cache size by more than 20X without regressing quality. With these techniques, GPU memory is no longer a bottleneck for serving large batch sizes."Very useful- Cost Of Self Hosting Llama-3 8B-Instruct
"Assuming 100% utilization of your model Llama-3 8B-Instruct model costs about $17 dollars per 1M tokens when self hosting with EKS, vs ChatGPT with the same workload can offer $1 per 1M tokens. Choosing to self host the hardware can make the cost <$0.01 per 1M token that takes ~5.5 years to break even"And a couple of more general data function organisational tips:
How To Hire AI Engineers — with James Brady & Adam Wiggins of Elicit

Excellent post from Laszlo Sragner- You Only Need These 3 Data Roles in a Data-Driven Enterprise
"You can justify this categorisation by asking: Who is your customer? If your customer is an executive, you are doing analytics (DSA/BI). If you work on automated models, recommender systems, and your customers are your company’s clients, you belong to a data product function (DS/MLE etc.). If your customers are data roles from the previous two categories, then you belong to the data function (DWH/DE). "


Bigger picture ideas
Longer thought provoking reads - sit back and pour a drink! ...
How to Fix “AI’s Original Sin” - Tim O’Reilly
“But it seems less important to get into the fine points of copyright law and arguments over liability for infringement, and instead to explore the political economy of copyrighted content in the emerging world of AI services: Who will get what, and why? And rather than asking who has the market power to win the tug of war, we should be asking, What institutions and business models are needed to allocate the value that is created by the “generative AI supply chain” in proportion to the role that various parties play in creating it? And how do we create a virtuous circle of ongoing value creation, an ecosystem in which everyone benefits?”LLMs and Search - Steven Sinofsky
"At the same time it meant people were not focused on the creative and expressive power of the technology and doing what it did so uniquely well. Worse those seemed pedestrian use cases compared to the grand vision of replacing whole parts of the economy."How Amazon blew Alexa’s shot to dominate AI - Sharon Goldman
"The reason, according to interviews with more than a dozen former employees who worked on AI for Alexa, is an organization beset by structural dysfunction and technological challenges that have repeatedly delayed shipment of the new generative AI-powered Alexa. Overall, the former employees paint a picture of a company desperately behind its Big Tech rivals Google, Microsoft, and Meta in the race to launch AI chatbots and agents, and floundering in its efforts to catch up."Building AI products - Benedict Evans
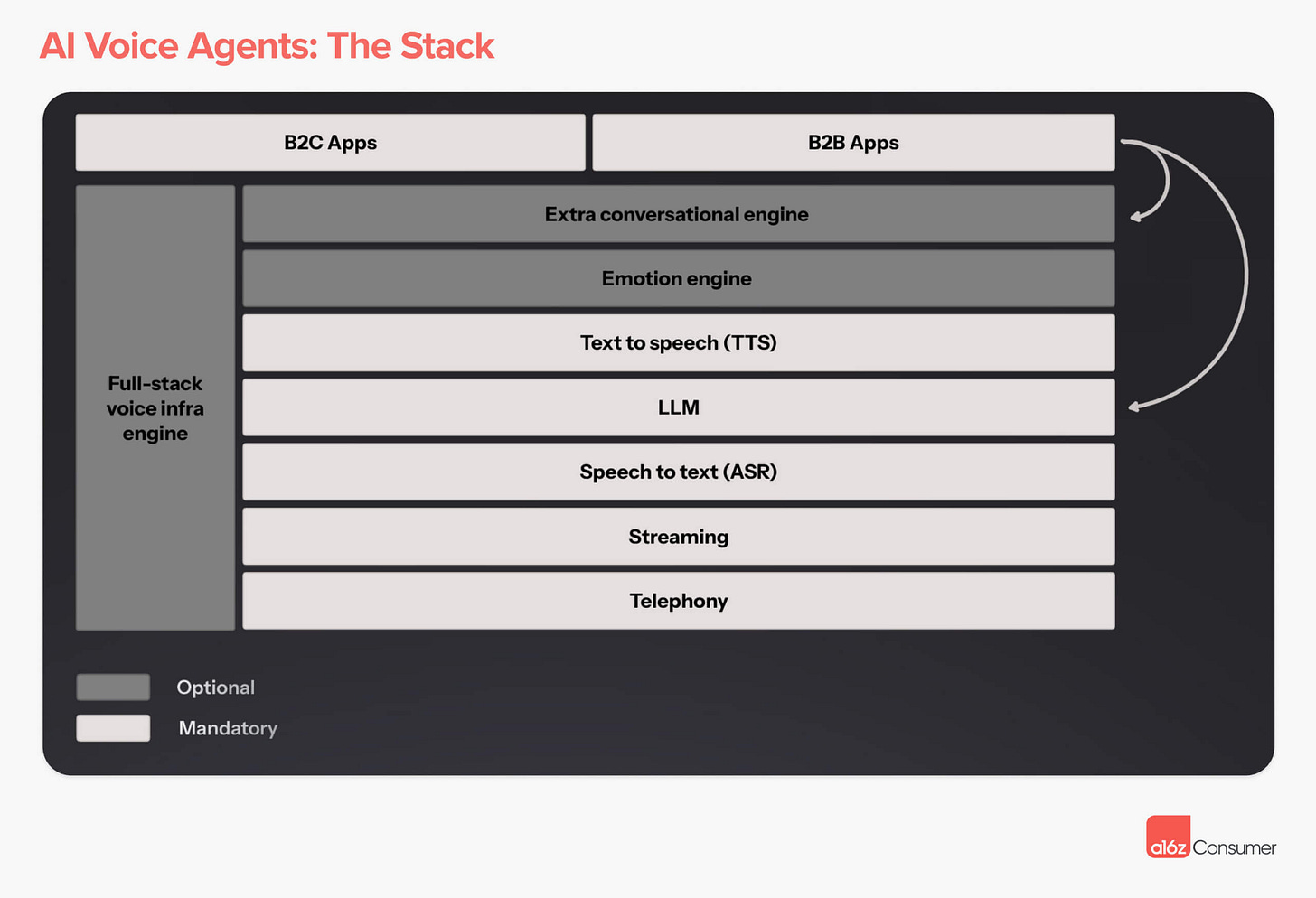
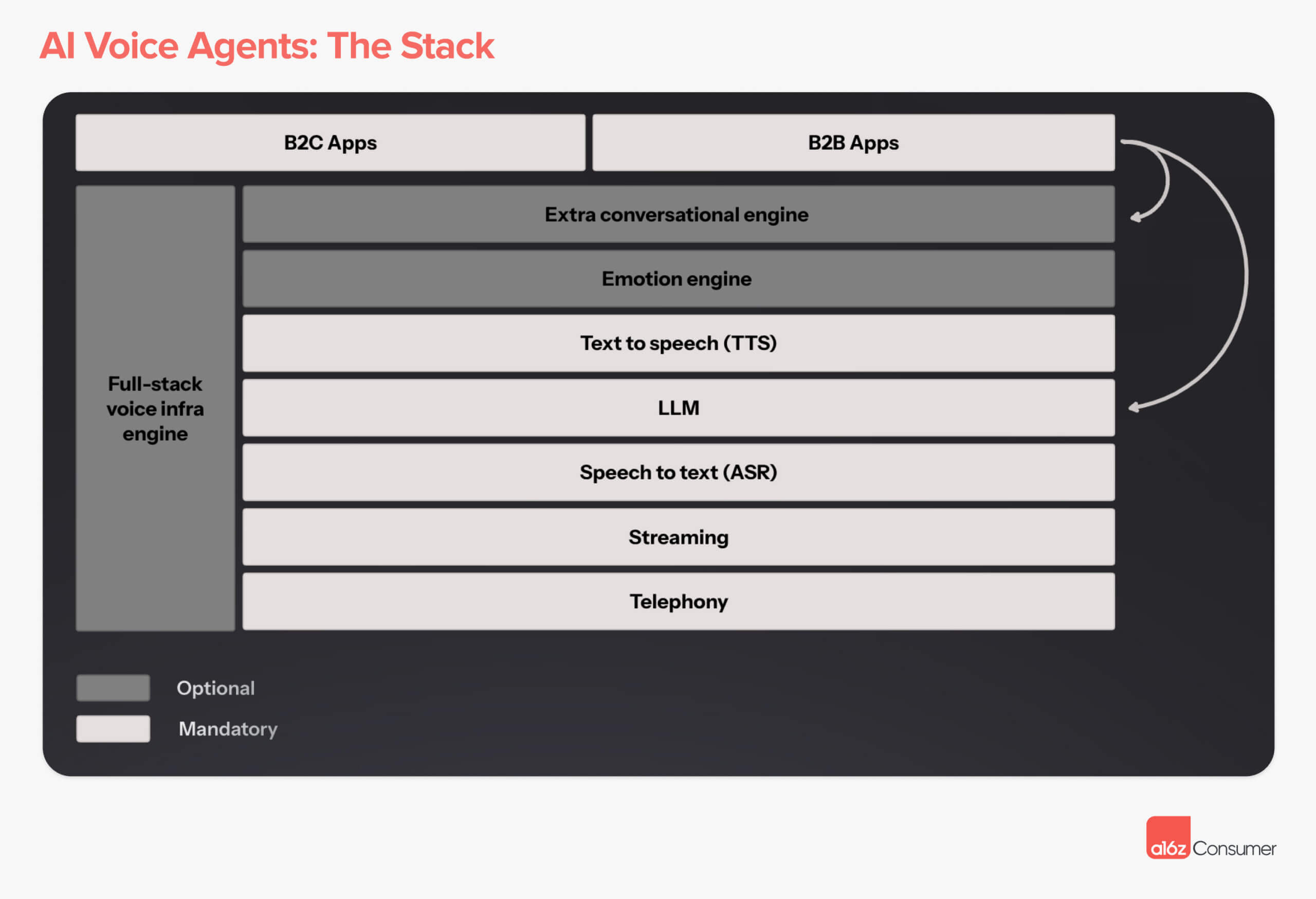
"But the other path is to treat this as a product problem. How do we build useful mass-market products around models that we should presume will be getting things ‘wrong’? A stock reaction of AI people to examples like mine is to say “you’re holding it wrong” - I asked 1: the wrong kind of question and 2: I asked it in the wrong way. I should have done a bunch of prompt engineering! But the message of the last 50 years of consumer computing is that you do not move adoption forward by making the users learn command lines - you have to move towards the users."Hi, AI: Our Thesis on AI Voice Agents - Andreessen - Horowitz
Controversial… The future of foundation models is closed-source - John Luttig
"As an accelerant of modern software, open-source maintains a cherished place in tech. Who can argue with free stuff, decentralized control, and free speech? But open and closed-source AI cannot both dominate in the limit: if centralizing forces hold, scale advantages will compound and leave open-source alternatives behind. Despite recent progress and endless cheerleading, open-source AI will become a financial drain for model builders, an inferior option for developers and consumers, and a risk to national security. Closed-source models will create far more economic and consumer value over the next decade."
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
This looks great fun- Building an AI Text-to-Video Model from Scratch Using Python
"In this blog, we will build a small scale text-to-video model from scratch. We will input a text prompt, and our trained model will generate a video based on that prompt. This blog will cover everything from understanding the theoretical concepts to coding the entire architecture and generating the final result."Nothing like a $500k prize to get the competitive juices flowing - ARC Prize 2024
Create an AI capable of solving reasoning tasks it has never seen before
The Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI) benchmark measures an AI system's ability to efficiently learn new skills. Humans easily score 85% in ARC, whereas the best AI systems only score 34%. The ARC Prize competition encourages researchers to explore ideas beyond LLMs, which depend heavily on large datasets and struggle with novel problems.Or maybe you have an idea for a product or company? How about Mozilla Builders: 2024 Accelerator Theme: Local AI
"Local AI is the theme for our inaugural Accelerator because it aligns with our core values of privacy, user empowerment, and open source innovation. Local AI refers to running AI models and applications directly on personal devices like laptops and smartphones, rather than relying on cloud-based services controlled by Big Tech companies. This approach fosters greater data privacy and control by putting the technology directly into the hands of users . It also democratizes AI development by reducing costs, making powerful AI tools accessible to individual developers and small communities."
Updates from Members and Contributors
NHS Data Scientist Luke Shaw highlights some recent research on generative AI adoption: Singapore has apparently the highest penetration, with the UK a fair bit behind
Professor Harin Sellahewa, draws our attention to an interesting recent research paper he contributed to: ‘AI deception: A survey of examples, risks, and potential solutions’
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
2 exciting new machine learning roles at Carbon Re- excellent climate change AI startup
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS