


July Newsletter
Industrial Strength Data Science

Hi everyone-
July in the UK… when the shorts properly come out (sun or not…) and ‘Test Match Special’ becomes the soundtrack to the summer... hopefully plenty of time to catch up on the data science and AI developments of the last month. Don't miss out on more generative AI fun and games in the middle section!
Following is the July edition of our Royal Statistical Society Data Science and AI Section newsletter (we’ll take a break over the summer so the next edition will be in September.) Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly click on the “Open Online” link at the top right.
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science, ML and AI practitioners. And if you are not signed up to receive these automatically you can do so here
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
The post last month from committee member Martin Goodson (CEO and Chief Scientist at Evolution AI) “The Alan Turing Institute has failed to develop modern AI in the UK”, highlighting the lack of government support for the open source AI community in the UK, continues to have far reaching impact. In addition to hitting the front page of hacker news, a number of recent articles in the press have continued the theme, highlighting the lack of a coherent AI strategy from the government. A recent paper from the Tony Blair Institute for Global Change lays out a much more compelling and coherent view. Martin’s post was quoted directly in a recent summary in the Times (“End of the road for AI advisers ‘blindsided’ by latest tech”) - many congratulations to Martin and to all our readers and members who have contributed for helping drive this important change in direction
We have a new practitioners survey and an exciting upcoming event- will send details shortly.
We are continuing our work with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is now accepting applications for the Advanced Data Science Professional certification- more details here.
This year’s RSS International Conference will take place in the lovely North Yorkshire spa town of Harrogate from 4-7 September. As usual Data Science is one of the topic streams on the conference programme, and there is currently an opportunity to submit your work for presentation. There are options available for 5-minute rapid-fire talks and for poster presentations – for full details visit the conference website.
Some great recent content published by Brian Tarron on our sister blog, Real World Data Science:
Martin also continues to run the excellent London Machine Learning meetup and is very active with events. The last event was a special one (June 7th)- the first in person event since 2020- with a great speaker, Jane Dwivedi-Yu (a researcher at Meta AI), and a great topic "Language Models Can Teach Themselves to Use Tools” - this is Meta’s Toolformer. Videos are posted on the meetup youtube channel - and future events will be posted here.
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics and diversity continue to be hot topics in data science and AI...
We continue to see the increasing power and accuracy of generative AI used for harm- “US mother gets call from ‘kidnapped daughter’ – but it’s really an AI scam”
And bad outcomes can be self-inflicted… just ask the lawyer involved in this case, who used ChatGPT to write his brief, including citing cases which were entirely fictitious. Apparently he “did not comprehend” that the chat bot could lead him astray…
"This case has reverberated throughout the entire legal profession,” said David Lat, a legal commentator. “It is a little bit like looking at a car wreck."Meanwhile in the Music business, although Paul McCartney is happily using AI to complete a ‘Last Beatles song’, AI ‘soundalike’ tools are creating lots legal questions on ownership and copyright.
"Copyright has long been the main way that artists and labels protect their creative and economic investment in music. But neither US nor UK copyright law protects a performer’s voice, tone or unique singing style. AI soundalike recordings are generally not created using samples or snippets of existing recordings but instead are generated independently with AI tools that have learned to reconstruct a particular voice. Thus, owning the copyright to the original sound recording is of little help since the newly recorded material is not a direct copy."Many of the leading developers of (Generative) AI tools, such as OpenAI, seem to be taking seriously the risks of misuse of their applications (“The Race to Prevent ‘the Worst Case Scenario for Machine Learning’”) and are attempting to show leadership in safeguarding the use of these tools- e.g. “Governance of Superintelligence“
"But the governance of the most powerful systems, as well as decisions regarding their deployment, must have strong public oversight. We believe people around the world should democratically decide on the bounds and defaults for AI systems. We don't yet know how to design such a mechanism, but we plan to experiment with its development. We continue to think that, within these wide bounds, individual users should have a lot of control over how the AI they use behaves."And there are certainly plenty of initiatives around the world as governments attempt to work through regulatory options - “G7 aims to beef up collaboration for AI governance” - with the EU at the forefront, moving towards passing a far-reaching ‘AI Act’
"Under the latest version of Europe’s bill passed on Wednesday, generative A.I. would face new transparency requirements. That includes publishing summaries of copyrighted material used for training the system, a proposal supported by the publishing industry but opposed by tech developers as technically infeasible. Makers of generative A.I. systems would also have to put safeguards in place to prevent them from generating illegal content."Useful commentary here and here on what the EU AI Act might mean for AI startups and developers - well worth a read.
And some useful grounding from Stanford University (HAI) - which current models are compliant with the EU AI Act draft? (spoiler alert… none are even close)

Interesting article in Foreign Affairs discussing China - “The Illusion of China’s AI Prowess”
There has been a lot in the press about the AI apocalypse and the potential risk to humanity over the last few months. But there has been some recent moderation in the language:
Great debate amongst luminaries - Munk Debate on Artificial Intelligence (Bengio & Tegmark vs. Mitchell & LeCun)
Two ‘OGs’, Andrew Ng and Geoff Hinton, had an interesting discussion about catastrophic risks
Another godfather, Yoshua Bengio, talks through how a rogue AI might develop
While the final member of the gang, Yann LeCun, is far more skeptical

"Will AI take over the world? No, this is a projection of human nature on machines" he said. It would be a huge mistake to keep AI research "under lock and key", he added."Indeed there is increasing commentary that the doomsday scenario is overblown and that it is actually distracting from current harms - a point of view shared by Margrethe Vestager, the EU’s competition chief
"Probably [the risk of extinction] may exist, but I think the likelihood is quite small. I think the AI risks are more that people will be discriminated [against], they will not be seen as who they are.
"If it's a bank using it to decide whether I can get a mortgage or not, or if it's social services on your municipality, then you want to make sure that you're not being discriminated [against] because of your gender or your colour or your postal code," she said.Pulling all this together is an excellent ‘scorecard’ showing the varying views of many leading AI experts on the potential for future harm from AI - with an interesting gender split…
Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
First of all, for anyone new to the field, or frankly for anyone needing a bit of a refresher in a fast moving field, this is a fantastic curated list of explanatory articles and papers - AI Canon
"In this post, we’re sharing a curated list of resources we’ve relied on to get smarter about modern AI. We call it the “AI Canon” because these papers, blog posts, courses, and guides have had an outsized impact on the field over the past several years."It seems increasingly rare, but there is some non-LLM related research going on!
Impressive results from Google on using NERFs (Neural Radiance Fields) to recreate 3d images from photos- and embedding this in google maps!
Google also released DIDACT (Dynamic Integrated Developer ACTivity) - ‘Large sequence models for software development activities’, using ‘the process of software development as the source of training data for the model, rather than just the polished end state of that process‘
Everyone uses the ‘Adam’ optimiser (2014) in their neural network training right? Enter Adam Accumulation (AdamA) - “Notably, AdamA can work together with memory reduction methods for optimizer states to fit 1.26x~3.14x larger models over PyTorch and DeepSpeed baseline on GPUs with different memory capacities.”
And Transformers are always the best architecture, right? ‘Brainformers: Trading Simplicity for Efficiency’ - “A Brainformer model with 8 billion activated parameters per token demonstrates 2x faster training convergence and 5x faster step time compared to its GLaM counterpart”
Not to be outdone, Meta has made some impressive strides in translation (1,100+ languages) and text-to-speech (VoiceBox)
Lots of work going on in creating more specialised foundation models for specific applications..
The open source FinGPT for finance applications
Otter - open source multi-modal LLM showcasing improved instruction-following and in-context learning ability
MatCha - a pixels-to-text foundation model for reasoning on charts
SQL-PaLM: Improved Large Language Model Adaptation for Text-to-SQL
AudioPaLM: A Large Language Model That Can Speak and Listen- intriguing that ‘initializing AudioPaLM with the weights of a text-only large language model improves speech processing’
MusicGen: Simple and Controllable Music Generation from Facebook Research
And some great strides in Video with MAGVIT (for video synthesis) and Video-LLaMA (for video understanding)
And the minimisation quest continues…
Textbooks Are All You Need - ‘new large language model for code, with significantly smaller size than competing models’ trained ‘using a selection of ``textbook quality" data from the web (6B tokens)’
TinyStories: How Small Can Language Models Be and Still Speak Coherent English? - ‘We show that TinyStories can be used to train and evaluate LMs that are much smaller than the state-of-the-art models (below 10 million total parameters)’
‘Impossible Distillation: from Low-Quality Model to High-Quality Dataset & Model for Summarization and Paraphrasing’ - ‘a framework that distills a task-specific dataset directly from an off-the-shelf LM, even when it is impossible for the LM itself to reliably solve the task’
Although interesting research shows that mimicking large model outputs with smaller models may not generalise well (The False Promise of Imitating Proprietary LLMs)
"Overall, we conclude that model imitation is a false promise: there exists a substantial capabilities gap between open and closed LMs that, with current methods, can only be bridged using an unwieldy amount of imitation data or by using more capable base LMs. In turn, we argue that the highest leverage action for improving open-source models is to tackle the difficult challenge of developing better base LMs, rather than taking the shortcut of imitating proprietary systems."Lots of focus on ‘fine-tuning’ large language models- using pre-trained models for specific tasks without laborious re-training.
One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning (PyTorch implementation here) - ‘GLoRA employs a generalized prompt module to optimize pre-trained model weights and adjust intermediate activations, providing more flexibility and capability across diverse tasks and datasets’
Minimising logical errors with ‘Let's Verify Step by Step’
Who needs ‘chains’ when you have ‘graphs’? - Beyond Chain-of-Thought, Effective Graph-of-Thought Reasoning in Large Language Models - ‘researchers have discovered the potential of Chain-of-thought (CoT) to assist LLMs in accomplishing complex reasoning tasks by generating intermediate steps. However, human thought processes are often non-linear, rather than simply sequential chains of thoughts. Therefore, we propose Graph-of-Thought (GoT) reasoning, which models human thought processes not only as a chain but also as a graph’
And who needs ‘graphs’ when you have ‘trees’? Tree of Thoughts: Deliberate Problem Solving with Large Language Models - ‘allows LMs to perform deliberate decision making by considering multiple different reasoning paths and self-evaluating choices to decide the next course of action’
Or Tables? Tab-CoT: Zero-shot Tabular Chain of Thought - ‘a novel tabular-format CoT prompting method, which allows the complex reasoning process to be explicitly modelled in a highly structured manner’
Finally. lots of work looking at how best to ‘ground’ large language models (providing relevant information that is not available as part of the LLM's trained knowledge)- good guide here from Microsoft Research
"Despite their extensive knowledge, LLMs have limitations. Their knowledge is stale, as they are trained only up to a certain point in time (e.g., September 2021 for recent GPT models) and don't update continuously. Moreover, they only have access to public information and lack knowledge about anything behind corporate firewalls, private data, or use-case specific information. Consequently, we need a way to combine the general capabilities of LLMs with specific information relevant to our use-cases. Grounding provides a solution to this challenge, enabling us to leverage the power of LLMs while incorporating the necessary context and data."Sequential Monte Carlo Steering of Large Language Models using Probabilistic Programs - ‘The key idea is to specify language generation tasks as posterior inference problems in a class of discrete probabilistic sequence models, and replace standard decoding with sequential Monte Carlo inference‘
Direct Preference Optimization: Your Language Model is Secretly a Reward Model - ‘we leverage a mapping between reward functions and optimal policies to show that this constrained reward maximization problem can be optimized exactly with a single stage of policy training, essentially solving a classification problem on the human preference data‘
Orca: Progressive Learning from Complex Explanation Traces of GPT-4 - ‘Orca learns from rich signals from GPT-4 including explanation traces; step-by-step thought processes; and other complex instructions, guided by teacher assistance from ChatGPT’
Generative AI ... oh my!
Still such a hot topic it feels in need of it's own section, for all things DALLE, IMAGEN, Stable Diffusion, ChatGPT...
So much going on, as ever! First of all, nation specific large language models are beginning to show up…
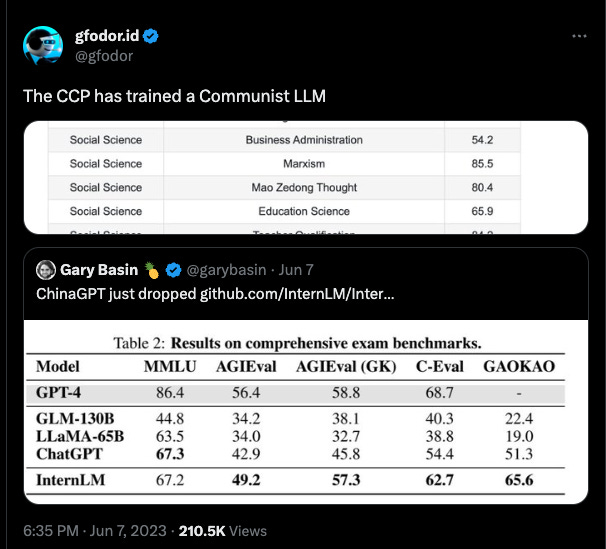
ChatGPT’s ‘secret source’ may have been uncovered (‘a mixture of smaller models’), while in addition, it will likely have some potentially formidable competition from Gemini, DeepMind’s entry into the world of GenAI
"At a high level you can think of Gemini as combining some of the strengths of AlphaGo-type systems with the amazing language capabilities of the large models. We also have some new innovations that are going to be pretty interesting." - Demis HassabisGenAI inspired applications and use cases popping up all over the place…
“Google starts rolling out image generation in Slides, more Duet AI for Gmail and Docs”
Generative AI Studio on Vertex AI (Google Cloud)
“WPP partners with NVIDIA to build generative AI-enabled content engine for digital advertising”
“Midjourney V5.2 is Incredible! Everything You Need To Know!”
Ecoute - ‘live transcription tool that provides real-time transcripts for both the user's microphone input (You) and the user's speakers output (Speaker) in a textbox’
And the Khan Academy AI teaching assistant (Khanmigo) is properly groundbreaking..
There is a lot of excitement about autonomous agents- where one LLM powered agent is able to create additional ones to work on sub-tasks - good summary from the always excellent Lilian Weng (and an example - GPT Engineer)
Working with and using LLMs is not easy and there are increasing numbers of guides, tricks and tools to help:
Definitely worth following OpenAI’s Best Practices guide
Understanding and evaluating responses - observability tool
OpenLLM - “run inference with any open-source large-language models, deploy to the cloud or on-premises, and build powerful AI apps”
Chat with your documents privately without internet using MPT-30B & Langchain
Lots of good tips and tricks on finetuning
Second order effects - data sets used to train AI models, now generated by AI models… Can this work? - "Can foundation models label data like humans?” - feels like ‘no free lunch’ is being violated somewhere…
Updates on tracking performance of the leading LLMs from Hugging Face
A reminder that we really still don’t know how this all works… “A Two sentence Jailbreak for GPT-4 and Claude & Why Nobody Knows How to Fix It“
Apparently genai tools don’t understand humour … but this isn’t too bad


Real world applications and how to guides
Lots of practical examples and tips and tricks this month
This is amazing - ‘Brain Implants Allow Paralyzed Man to Walk Using His Thoughts’
"To achieve this result, the researchers first implanted electrodes in Mr. Oskam’s skull and spine. The team then used a machine-learning program to observe which parts of the brain lit up as he tried to move different parts of his body. This thought decoder was able to match the activity of certain electrodes with particular intentions: One configuration lit up whenever Mr. Oskam tried to move his ankles, another when he tried to move his hips. Then the researchers used another algorithm to connect the brain implant to the spinal implant, which was set to send electrical signals to different parts of his body, sparking movement."Interested in wine? Worth checking out sommeli_ai for fun visulaisation and exploration of the wine world
Useful tutorial on using LLMs to improve recommendation systems
Amazon Science improving on nearest neighbour search efficiency - very useful for semantic search and knowledge retrieval applications


Interesting application from Neo4j (graph database) - using an LLM powered chatbot on top of a knowledge graph
The ever evolving time-series modelling space, keeps evolving…
Transformer models for time-series can be successful (see also IBMs new ‘PatchTST’ - useful tutorial here)

And transfer learning for time-series is intriguing given the often limited data sets available to train from
Finally, self-supervised learning for time-series could be promising
Understanding DeepMind's Sorting Algorithm - really getting down into the assembly code to figure out how it works, very impressive!
The Curse of Dimensionality- good refresher on why things get complicated in higher dimensions!
If you’ve been playing with LLMs you have likely used a tokenizer - but how do they work?
Step by step tutorial: “Fine-tune BERT for Text Classification on AWS Trainium”
Going deep with Structured State Spaces - how to model very long range sequences

"The Structured State Space for Sequence Modeling (S4) architecture is a new approach to very long-range sequence modeling tasks for vision, language, and audio, showing a capacity to capture dependencies over tens of thousands of steps. Especially impressive are the model’s results on the challenging Long Range Arena benchmark, showing an ability to reason over sequences of up to 16,000+ elements with high accuracy."You’ve heard about Bayesian Causal Inference but what is it really, and how do you do it- good comparison of libraries and approaches; and also a good tutorial on using covariates in causal inference
You’ve got a great decision tree model, but you want to better understand how it works… enter ‘Decision Tree Visualizations with dtreeviz’

Finally, more on the visualisation front, if you are in the market for an open source BI tool, Apache Superset is worth checking out - ‘Data Visualisation with Apache Superset — A Step-By-Step Guide’

Practical tips
How to drive analytics and ML into production
As is generally the case, lots of commentary about MLOps
Interesting to see some real world examples: Lyft discussing their realtime ML pipelines
Motion for MLOps - “Motion is especially useful for applications that: Need to continually fine-tune models or do any online learning; Need to update prompts based on new data (e.g., maintain a dynamic list of examples in the prompt)”
Useful tutorial on setting up a platform based on AWS EKS with Kubeflow and MLflow
And another MLflow step-by-step guide

If you are dealing with large amounts of unstructured training data, this looks like a great open source solution: Spotlight
Interesting application of LLMs for feature engineering - CAFFE: fully integrated with sklearn, you basically set up your classifier, pass in the data set and dependent variable, along with a description of the data…
How to train ML models directly on Kafka streams- could be a great time saver
This looks potentially very useful - Giskard: “open-source testing framework dedicated to ML models, from tabular models to LLMs.”

Finally, I do love a good interactive visualisation tool… Weave looks worth checking out


Bigger picture ideas
Longer thought provoking reads - lean back and pour a drink! ...
“Why AI will save the world”- the take from Marc Andreessen… well worth a read
"My view is that the idea that AI will decide to literally kill humanity is a profound category error. AI is not a living being that has been primed by billions of years of evolution to participate in the battle for the survival of the fittest, as animals are, and as we are. It is math – code – computers, built by people, owned by people, used by people, controlled by people. The idea that it will at some point develop a mind of its own and decide that it has motivations that lead it to try to kill us is a superstitious handwave."“The New new moats” - from Greylock
"The entire market of startups, big and small, also have an advantage. In my original “New Moats” essay from six years ago, I was correct in pointing out the power of open source, but I was wrong to assume that it only favored the big cloud providers who could provide open source services at scale. On the contrary, this new generation of AI models can potentially shift power back to startups, as they can leverage foundation models – both open source and not – in their products.”“Talkington dubbed this artificial reporter “Paul.” While Paul isn’t perfect and Talkington is not currently publishing stories the model can generate, Talkington’s early experimentation suggests that this tech could soon — very soon — be a viable tool to save reporters time by covering hours-long public meetings. But even Talkington’s wry choice to name the AI after a reporter he did not hire speaks to an alternative direction use of this tech could take — one that some reporters (myself included, frankly) are afraid of: replacing reporters instead of assisting them”“Our latest research estimates that generative AI could add the equivalent of $2.6 trillion to $4.4 trillion annually across the 63 use cases we analyzed—by comparison, the United Kingdom’s entire GDP in 2021 was $3.1 trillion. This would increase the impact of all artificial intelligence by 15 to 40 percent. This estimate would roughly double if we include the impact of embedding generative AI into software that is currently used for other tasks beyond those use cases."“The New Language Model Stack” - from Sequoia
"Language model APIs put powerful ready-made models in the hands of the average developer, not just machine learning teams. Now that the population working with language models has meaningfully expanded to all developers, we believe we’ll see more developer-oriented tooling.""Open-source will develop LLMs that are mode capable over a specific set of needs, but less cumulatively capable. What this looks like is instead of taking the giant scorecard that GPT4 was touted on, you take 10-50% as the targets for an open-source model and beat GPT4. The other metrics will likely be behind, not equal""In this post, I’ll use this approach to forecast the properties of large pretrained ML systems in 2030. I’ll refer throughout to “GPT2030”, a hypothetical system that has the capabilities, computational resources, and inference speed that we’d project for large language models in 2030 (but which was likely trained on other modalities as well, such as images). To forecast GPT2030’s properties, I consulted a variety of sources, including empirical scaling laws, projections of future compute and data availability, velocity of improvement on specific benchmarks, empirical inference speed of current systems, and possible future improvements in parallelism."
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
DJing with Data Science… DataJockey

A “bit” of maths… “Mathematicians Discover Novel Way to Predict Structure in Graphs”


Great visualisation of the rise of LLMs from Information is Beautiful

Feeling inspired? $250,000 Ai Grant
Updates from Members and Contributors
Dr. Stephen Haben, and collaborators Marcus Voss (TU Berlin) and William Holderbaum have just released what looks to be a useful open access book on load forecasting including code and links to various datasets.
John Sandall draws our attention to London Data Week running 3rd - 9th July which looks like a great event- as well as the ever excellent PyData London meetup on 4th July
Mia Hatton (Data Science Community Project Manager, Data Science Campus
Office for National Statistics) invites any public sector employees with an interest in data science to to present and/or attend DataConnect23 (25 - 29 September)
Jobs!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS