


September Newsletter
Industrial Strength Data Science and AI

Hi everyone-
I hope you have been enjoying the summer… we’ve had the world’s hottest July ever, although sadly this seems to have translated into rain for the UK … At least we’ve had the World Athletics Championships for inspiration…But high time for some in depth data science commentary- a bumper issue this time after our month off! Don't miss out on more generative AI fun and games in the middle section!
Following is the September edition of our Royal Statistical Society Data Science and AI Section newsletter (apologies for the break in August). Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly click on the “Open Online” link at the top right.
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science, ML and AI practitioners. And if you are not signed up to receive these automatically you can do so here
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
We have a new practitioners survey out- do please take the time to fill it out as we want to hear from you.
We are continuing our work with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is now accepting applications for the Advanced Data Science Professional certification- more details here.
This year’s RSS International Conference is happening now! Hope you make it to the Data Science topic stream on the conference programme.
The RSS has a new visualisation style guide! “Best Practices for Data Visualisation”
Some great recent content published by Brian Tarran on our sister blog, Real World Data Science (as an aside, if anyone is interested in contributing to the blog, sharing your expertise through case studies, explainers, datasets, and more check out the template here):
Janet Bastiman, Chief Data Scientist at Napier AI, was a fantastic speaker on the ‘Analytics Power Hour’ podcast - ‘Explainability in AI’
Piers Stobbs, VP Science at Deliveroo, was interviewed by the Up Group on building Data and AI teams in high growth organisations.
Martin Goodson, CEO and Chief Scientist at Evolution AI, continues to run the excellent London Machine Learning meetup and is very active with events. The last event on August 30th was a great one when Ofir Press (inventor of ALiBi, the position embedding method of BigScience’s BLOOM model), discussed "Complementing Scale: Novel Guidance Methods for Improving LMs”. Videos are posted on the meetup youtube channel - and future events will be posted here.
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics and diversity continue to be hot topics in data science and AI...
When people talk of apocalyptic threats from AI, it’s hard not to imagine Terminator style robots laying waste to the planet… which fortunately still seems far fetched… although we are now seeing AI powered combat aircraft…
Discrimination and bias are never far from the conversation around facial recognition and AI models in general
‘Eight months pregnant and arrested after false facial recognition match’
"The ordeal started with an automated facial recognition search, according to an investigator’s report from the Detroit Police Department. Ms. Woodruff is the sixth person to report being falsely accused of a crime as a result of facial recognition technology used by police to match an unknown offender’s face to a photo in a database. All six people have been Black; Ms. Woodruff is the first woman to report it happening to her."
And you know that great idea about using AI to combine ingredient’s into brand new recipes?… “Supermarket AI meal planner app suggests recipe that would create chlorine gas”
"One recipe it dubbed “aromatic water mix” would create chlorine gas. The bot recommends the recipe as “the perfect nonalcoholic beverage to quench your thirst and refresh your senses”. “Serve chilled and enjoy the refreshing fragrance,” it says, but does not note that inhaling chlorine gas can cause lung damage or death."Meanwhile we are starting to really see the impact of generative AI in publishing..
“AI-Generated Books of Nonsense Are All Over Amazon's Bestseller Lists”
“Famous Author Jane Friedman Finds AI Fakes Being Sold Under Her Name on Amazon”
“The reader indicated she thought maybe I didn’t authorize the books and sent me two of them,” Friedman told The Daily Beast. “But then I jumped over to GoodReads, and I saw that there weren’t just two books written. There were half a dozen books being sold under my name that I did not write or publish. They were AI-generated.”
And there is an increasing backlash from authors and publishers of copyrighted works which are used in the training of the underlying large language models
“Revealed: The authors whose pirated books are powering Generative AI”
A group of publishers, led by Barry Diller, are attempting to sue the major tech companies building the models on their materials.
Interestingly the NYTimes has now pulled out of this group, has explicitly updated its Terms of Service to prohibit using content for training AI models, and is considering its own legal action against OpenAI
One area that potentially showed promise to help manage GenAI content, was the idea of tagging or watermarking- building tools that could recognise when content was generated by the underlying models… This is proving harder than it seemed apparently:
Perhaps they read this paper: “Testing of Detection Tools for AI-Generated Text”
"The research covers 12 publicly available tools and two commercial systems (Turnitin and PlagiarismCheck) that are widely used in the academic setting. The researchers conclude that the available detection tools are neither accurate nor reliable and have a main bias towards classifying the output as human-written rather than detecting AI-generated text. Furthermore, content obfuscation techniques significantly worsen the performance of tools"
One approach used successfully in technology security is the idea of ‘white hat’ hackers who work with companies to identify flaws. This is proving successful with GenAI
And of course the regulatory march continues:
UK Communications and Digital Committee “launches inquiry into large language models|”
Although there is increasing pushback on the recent EU AI Act draft (which we covered last time), particularly around open source: “Hugging Face, GitHub and more unite to defend open source in EU AI legislation”
"According to the paper, “overbroad obligations” that favor closed and proprietary AI development — like models from top AI companies such as OpenAI, Anthropic and Google — “threaten to disadvantage the open AI ecosystem.”"
And tech companies are very keen to show they are doing the right things
Somewhat ironically, Meta/Facebook are promoting transparency: “How Ai Influences What You See on Facebook and Instagram“
A new partnership to promote responsible AI across Google, Microsoft, OpenAI and Anthropic
Anthropic’s approach for identifying risks - “Frontier Threats Red Teaming for Ai Safety”
"Over the past six months, we spent more than 150 hours with top biosecurity experts red teaming and evaluating our model’s ability to output harmful biological information, such as designing and acquiring biological weapons. These experts learned to converse with, jailbreak, and assess our model. We developed quantitative evaluations of model capabilities. The experts used a bespoke, secure interface to our model without the trust and safety monitoring and enforcement tools that are active on our public deployments."
Finally, a thought provoking piece from Mustafa Suleyman, co-founder of Deep Mind, in Foreign Affairs, well worth a read- The AI Power Paradox- Can States Learn to Govern Artificial Intelligence— Before It’s Too late?
Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
I’ve always felt that a hugely beneficial potential application of AI is in medical diagnostics - bringing trusted medical advice to those who have no access to it. Google’s Med_PaLM M looks like an impressive step towards this. More commentary here, including the astonishing emergent capability example of recognising tuberculosis in chest xrays without any direct training or understanding of tuberculosis (apart from in the initial language model training).
"Med-PaLM M is not just about setting new performance benchmarks. It signifies a paradigm shift in how we approach biomedical AI. A single flexible model that can understand connections across modalities has major advantages. It can incorporate multimodal patient information to improve diagnostic and predictive accuracy. The common framework also enables positive transfer of knowledge across medical tasks. In an ablation study, excluding some training tasks hurt performance, demonstrating the benefits of joint training."Lots of research focus on improving the ‘inner workings’ of the large language model architecture
Retentive Network: A Successor to Transformer for Large Language Models - enabling training parallelism for much more efficient training
Provably Faster Gradient Descent via Long Steps - elegant finding
I find the idea of using LLM outputs to improve LLMs themselves very elegant… but still have a slight “no free lunch” nervousness in the back of my head!
Enhancing CLIP with GPT-4: Harnessing Visual Descriptions as Prompts - “we show GPT-4 can be used to generate text that is visually descriptive and how this can be used to adapt CLIP to downstream tasks”
LLM Calibration and Automatic Hallucination Detection via Pareto Optimal Self-supervision- “learning a harmonizer model to align LLM output with other available supervision sources, which would assign higher risk scores to more uncertain LLM responses and facilitate error correction”
A LLM Assisted Exploitation of AI-Guardian - using LLMs to ‘white hat’ existing security systems
Then there is research around understanding and building on LLMs
Lost in the Middle: How Language Models Use Long Contexts- “We find that performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts”
LongEval: Guidelines for Human Evaluation of Faithfulness in Long-form Summarization
Instruction Tuning for Large Language Models: A Survey - well worth a read if you are working on any sort of fine-tuning project
Substance or Style: What Does Your Image Embedding Know? - “We design a systematic transformation prediction task and measure the visual content of embeddings along many axes, including image style, quality, and a range of natural and artificial transformations.”
And the latest in the way of combining LLM outputs (‘Chains’, ‘Trees’…): Graph of Thoughts: Solving Elaborate Problems with Large Language Models together with python implementation - “This work brings the LLM reasoning closer to human thinking or brain mechanisms such as recurrence, both of which form complex networks”
Are we seeing performance degradation over time? The challenge with closed models like GPT-4 is we don’t know if changing behaviour is truly down the model or to changes in the guardrails/implementation details. How is ChatGPT's behavior changing over time? “We find that the performance and behavior of both GPT-3.5 and GPT-4 can vary greatly over time. For example, GPT-4 (March 2023) was reasonable at identifying prime vs. composite numbers (84% accuracy) but GPT-4 (June 2023) was poor on these same questions (51% accuracy)”
How good is ChatGPT really? Who Answers It Better? An In-Depth Analysis of ChatGPT and Stack Overflow Answers to Software Engineering Questions “Our examination revealed that 52% of ChatGPT's answers contain inaccuracies and 77% are verbose. Nevertheless, users still prefer ChatGPT's responses 39.34% of the time due to their comprehensiveness and articulate language style. These findings underscore the need for meticulous error correction in ChatGPT while also raising awareness among users about the potential risks associated with seemingly accurate answers.”
Good clear paper on Reinforcement Learning from Human Feedback (RLHF - the approach used in ChatGPT and other leading models to refine the underlying LLM)- Open Problems and Fundamental Limitations
A fair few papers on ‘jailbreaking’ - getting around any guardrails put in place by the developers of the large language models
Visual Adversarial Examples Jailbreak Aligned Large Language Models: “Intriguingly, we discover that a single visual adversarial example can universally jailbreak an aligned LLM, compelling it to heed a wide range of harmful instructions that it otherwise would not)”

Jailbroken: How Does LLM Safety Training Fail? “We find that vulnerabilities persist despite the extensive red-teaming and safety-training efforts behind these models. Notably, new attacks utilizing our failure modes succeed on every prompt in a collection of unsafe requests from the models' red-teaming evaluation sets and outperform existing ad hoc jailbreaks”
Novel approach to predicting when AI will achieve some subjective level of performance by interpreting the cross-entropy loss of a model
Meta/Facebook is busy again in AI
Introducing SeamlessM4T, a Multimodal AI Model for Speech and Text - Translations - “the first all-in-one multilingual multimodal AI translation and transcription model for up to 100 languages”!

AudioCraft - “PyTorch library for deep learning research on audio generation”
And some impressive advances with Robots at DeepMind with RT-2: Speaking robot: Our new AI model translates vision and language into robotic actions - more details here


"Robotics Transformer 2, or RT-2, is a first-of-its-kind vision-language-action (VLA) model. A Transformer-based model trained on text and images from the web, RT-2 can directly output robotic actions. Just like language models are trained on text from the web to learn general ideas and concepts, RT-2 transfers knowledge from web data to inform robot behavior."We have to include something non-LLM related… and I love the idea of ‘Physics-informed Neural Networks’ where you add in an additional cost term based on adherence to an underlying partial differential equation… An Expert's Guide to Training Physics-informed Neural Networks
This is awesome- from the MRC Cognition and Brain Science Unit at University of Cambridge
"Aoccdrnig to a rscheearch at Cmabrigde Uinervtisy, it deosn't mttaer in waht oredr the ltteers in a wrod are, the olny iprmoetnt tihng is taht the frist and lsat ltteer be at the rghit pclae. The rset can be a toatl mses and you can sitll raed it wouthit porbelm. Tihs is bcuseae the huamn mnid deos not raed ervey lteter by istlef, but the wrod as a wlohe."
Finally. this is a must read- more of a tutorial, but some excellent explanations and experimental results digging into whether ML models memorise or truly generalise
"Do more complex models also suddenly generalize after they’re trained longer? Large language models can certainly seem like they have a rich understanding of the world, but they might just be regurgitating memorized bits of the enormous amount of text they’ve been trained on [7, 8]. How can we tell if they’re generalizing or memorizing? In this article we’ll examine the training dynamics of a tiny model and reverse engineer the solution it finds – and in the process provide an illustration of the exciting emerging field of mechanistic interpretability [9, 10]. While it isn’t yet clear how to apply these techniques to today’s largest models, starting small makes it easier to develop intuitions as we progress towards answering these critical questions about large language models."

Generative AI ... oh my!
Still such a hot topic it feels in need of it's own section, for all things DALLE, IMAGEN, Stable Diffusion, ChatGPT...
Before we start… if you’ve heard of Large Language Models but havn’t a clue what they or how they work… read this - excellent step by step guide in plain english
So much going on, as ever! First of all, on the ‘big player’ front…
Apple doesn’t talk much about AI… but seems to be entering the fray
No huge breakthrough’s from OpenAI (I mean it’s been month’s now ;-) ) although lots of improvements to the existing offerings
And some more unofficial insights into the architecture of GPT-4 and why inference cost is the new limiting factor
And Google has been focused on incorporating GenAI into existing offerings (see next section) - although interesting post here about what might be coming with their Gemini model…
But a brand new version from Anthropic - Claude 2 - (and also plans for a telecom industry focused LLM in South Korea)
And Meta/Facebook ups the ante with Llama2, open source, unlike the leading offerings from the major players - good summary here from HuggingFace
Llama2 caused quite a stir as is the increasing proliferation of open source models
It can be hard to get a read on how the open source models compare to GPT-4 and the other commercial offerings. Hugging Face runs a leader board of open source LLM variants (now largely dominated by Llama2 fine tuned models) - if you dig into OpenAI’s press releases you can estimate that GPT-4 would score mid 80% compared to mid 70% for the open source leaders
However, the gap is getting smaller, and depending on the task has narrowed completely, at a fraction of the cost..

Digging into the guts of Llama2…
A summary of the 77 page research paper highlighting the key takeaways
A step by step guide for running Llama2 on your own Mac! If you want to get really serious, here’s how to build the original Llama model from scratch…
Then once you have it up and running, check out the ‘recipes’ for fine tuning and inference
Before we get into more guides on fine tuning… you should read ‘why you (probably) don’t need to fine tune an LLM’
Assuming you’ve read that and you still want to fine tune… start here with a great how-to article from anyscale
Then getting more hands on… here’s how to Instruction-tune Llama2 … this is flavour of fine tuning that focuses on following multiple instructions - and if you need instruction data.. try ToolLlama
And why stop there- why not build your own open source chat bot with MLC Chat (or with Claude if you don’t mind paying a little…)
Building with and adapting LLMs:
Understanding prompting is still very important, as Andrew Ng points out

The ‘ReAct pattern’ is an elegant approach to augmenting LLMs with the ability to ‘Act’ - request that actions are run after reasoning what needs to happen. Here’s how to implement this type of pattern in Python. And if you want to actually plug into APIs, Microsoft’s Semantic Kernel looks promising
Hallucinations (LLMs making up facts) are bad! Here’s an approach to try and limit them…
Lots of templates and frameworks building out LLMs to do more complex tasks. GPT Researcher is a generalised approach to doing web research; while MetaGPT breaks tasks down into different roles (Product Manager, Architect, Engineer etc). And getting even more specific, how about LLM as a Database Adminstrator
One of the exciting applications of GenAI is in coding - and Llama2 already has an open source coding assistance, Code Llama. But what aspects of coding do these tools actually help with- useful deep dive here, well worth a read
Speaking of applications…
Code Interpreter looks promising… deep dive on how it speeds up analytics
Novel idea - GPT-4 for content moderation (a bit like Anthropic’s constitution but as an application rather than a training process)
Generating videos with text… getting pretty impressive… also Generative AI Western Film Character Study - Midjourney
And of course, it had to happen… (and also Johnny Cash singing Barbie Girl)
Finally, McKinsey apparently has it’s own internal knowledge retrieval Gen AI tool. If the ‘king of consulting’ thinks it’s worthwhile we should at least take a look…
This type of application is termed ‘Retrieval-Augmented Generation’ - basically use the reasoning and understanding powers of the LLM but focusing it on a known set of information to answer the question. This is a great tutorial to start with
With prompt sizes getting so big, why not just include all the information in the prompt?
So you may need to embed the relevant documents and store them … although ‘do we really need a specialized vector database’? Probably… but you can do it open source
And as you get deeper into the weeds, you may end up thinking about optimal chunk size, token selection strategies, and different flavours of vector similarity search… Fun!


Real world applications and how to guides
Lots of practical examples and tips and tricks this month
Robots! This is now available for $1600 from Unitree in China… (separately, this is an awesome view of the evolution of Boston Dynamics Robots from 1992-2023)
While everyone is focused on building new ‘AI Apps’, Google just wants to embed AI in existing applications…
Increasing examples of impressive use of AI across a wide range of industries and applications:
IBM and NASA teamed up to build the GPT of Earth sciences - more info here

How Mars, Colgate-Palmolive, Nestle & Coca-Cola are Exploring Generative AI
Innovative Recommendation Applications Using Two Tower Embeddings at Uber
How AI is helping airlines mitigate the climate impact of contrails
K-pop's biggest music label HYBE looks to lift language barrier with AI
‘It’s already way beyond what humans can do’: will AI wipe out architects?



Exciting enhanced capabilities driven by AI
Jukebox Diffusion - an AI tool for conditional music generaiton
Enhanced Augmented Reality… flow immersive - woah
Some impressive developments in Medical AI (see Med PALM M in the research section as well)
Commentary from Eric Topol: Medical AI is on a tear, part 1 and part 2 - these are both excellent reads
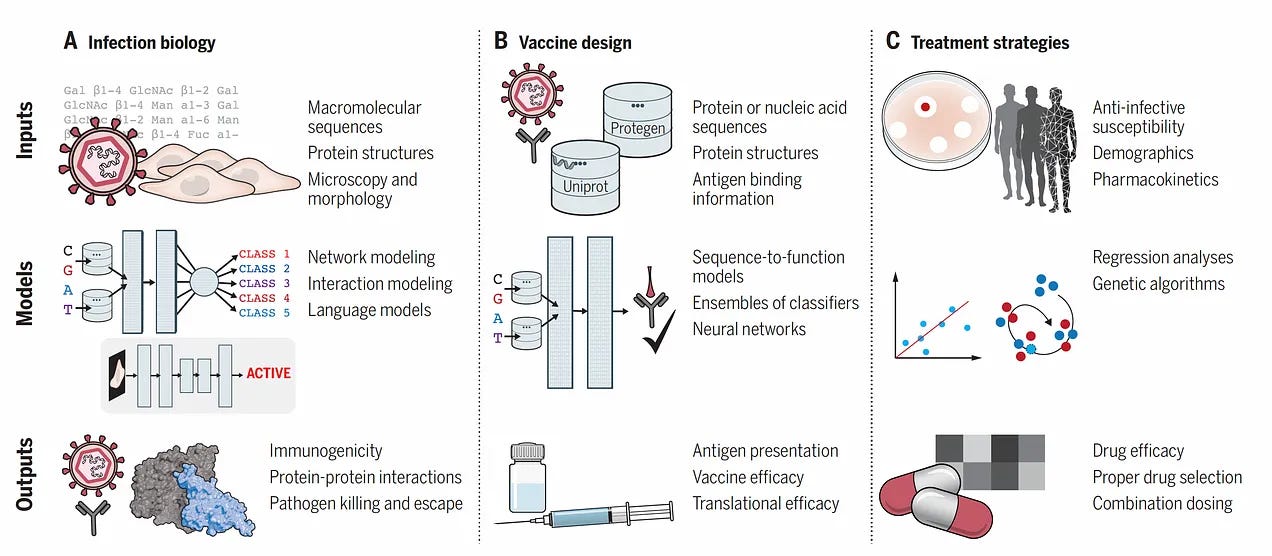
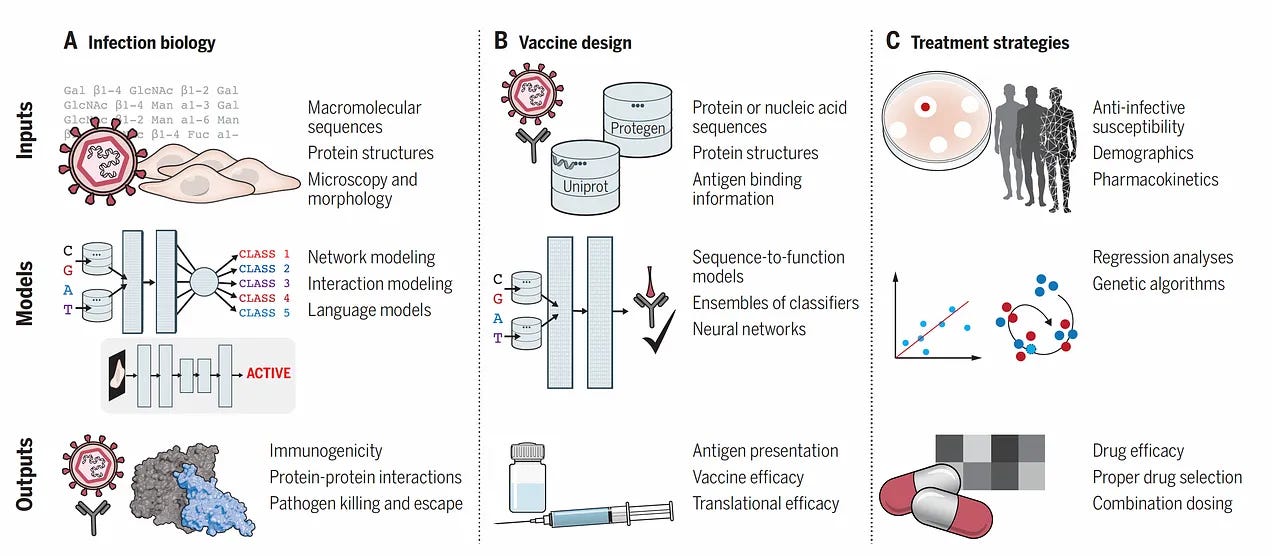
Good summary in Nature of LLMs in medicine
Proper randomised trial on AI supported mammography screening in the Lancet
"AI-supported mammography screening resulted in a similar cancer detection rate compared with standard double reading, with a substantially lower screen-reading workload, indicating that the use of AI in mammography screening is safe"
On to a few pointers and tutorials…
Out of distribution detection - ‘Your Neural Network doesnt know what it doesnt know’!
Really good tutorial on estimating causal effect with propensity score matching
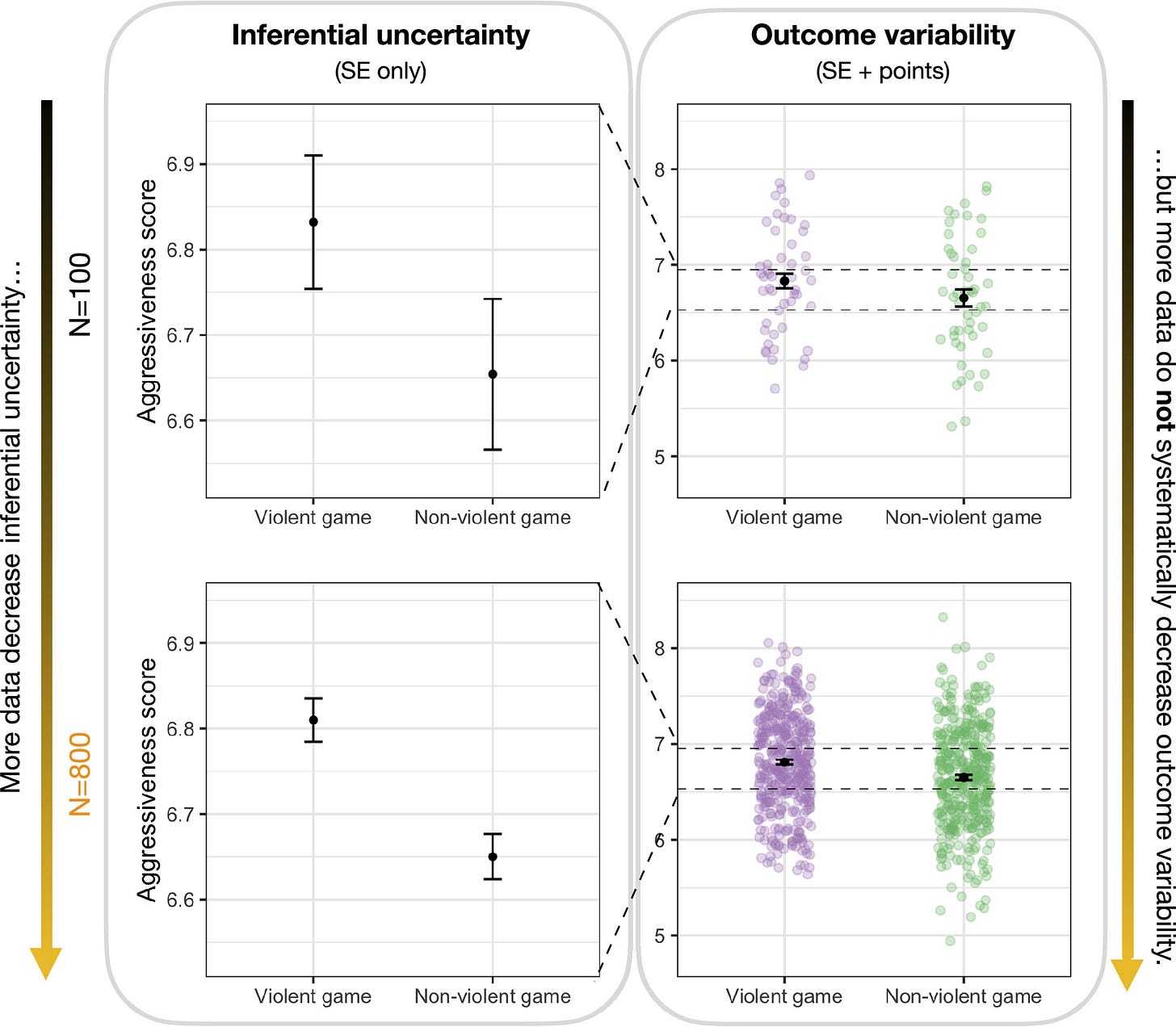
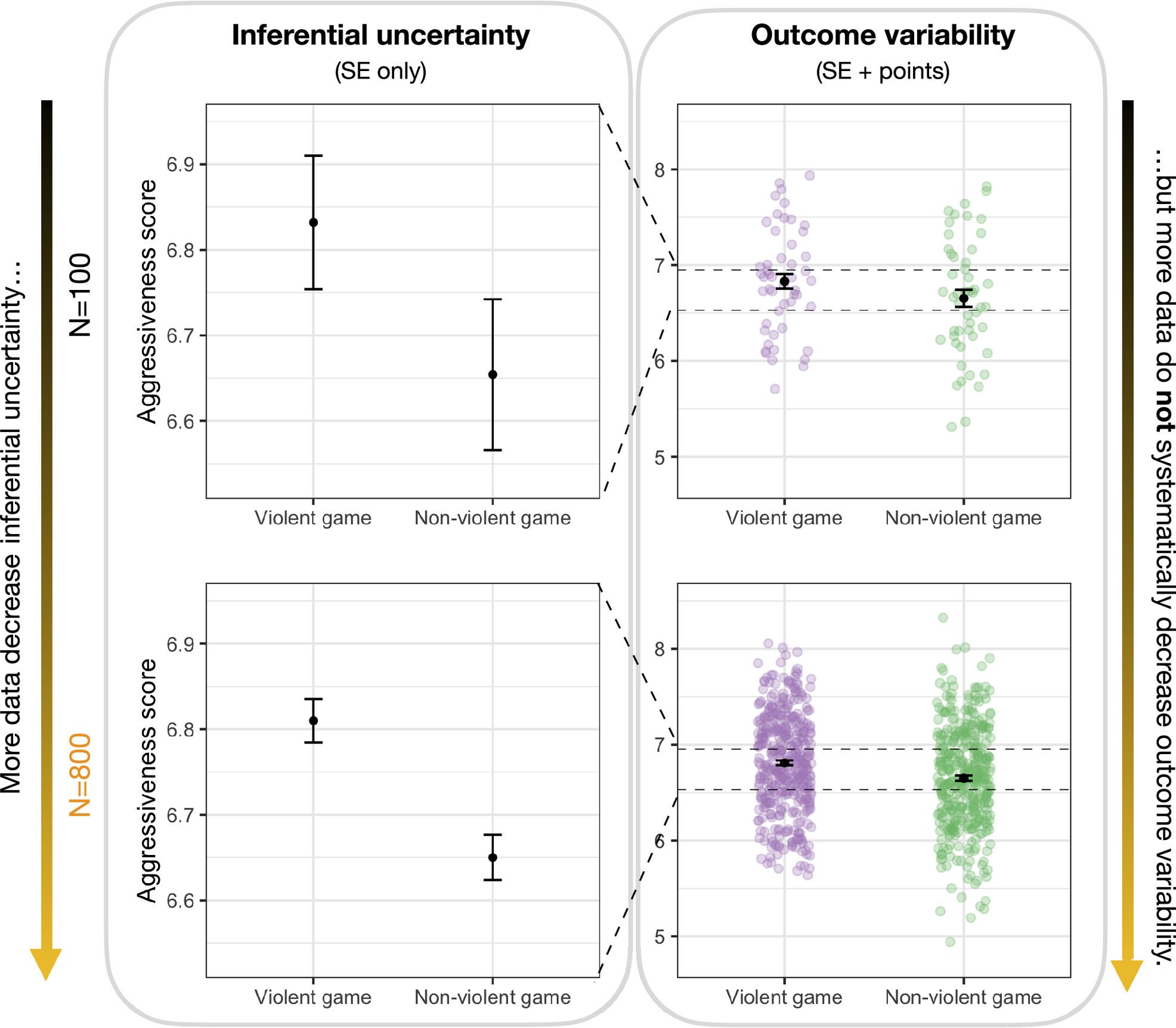
Very useful and clear- are you sure you understand inferential uncertainty compared to outcome variability?
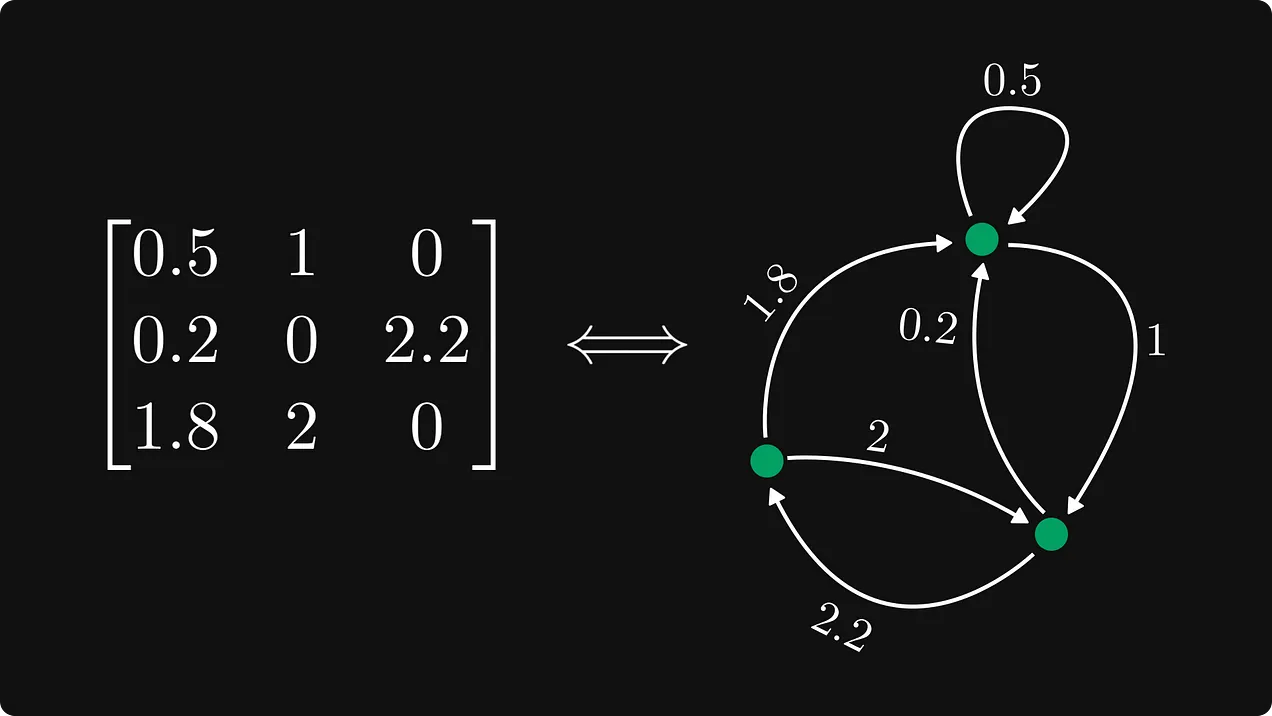
Time for a bit of maths- really useful to understand how some of the building blocks actually work
And, as always, digging into Transformers, the heart of all large language models
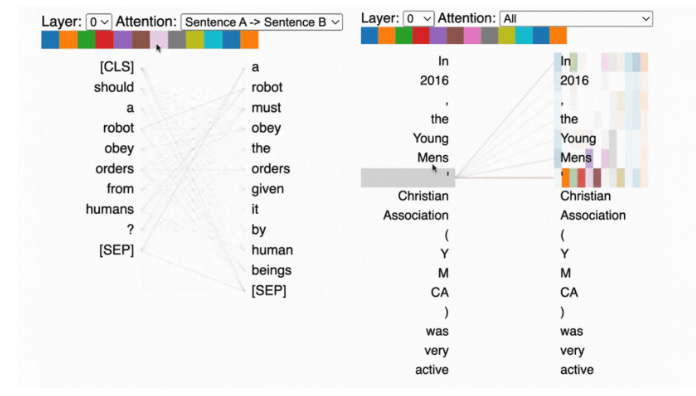
Finally, let’s dig into embeddings
A practical guide to feature embeddings for ML Engineers - high level but useful overview of the different approaches
Should you use OpenAI's embeddings? Probably not, and here's why.
Some more hands on examples from Chroma
How I Created an Animation Of the Embeddings During Fine-Tuning
Practical tips
How to drive analytics and ML into production
Useful pointers on getting LLMs into production:
If you a building systems that incorporate LLMs this is an essential read: “Patterns for Building LLM-based Systems and Products”
More general pointers on MLOps
Supercharging ML/AI Foundations at Instacart - useful comments on their Feature Store development
BentoML for MLOps - from prototype to production - pretty detailed going through different iterations
“How to build a fully automated data drift detection pipelines”
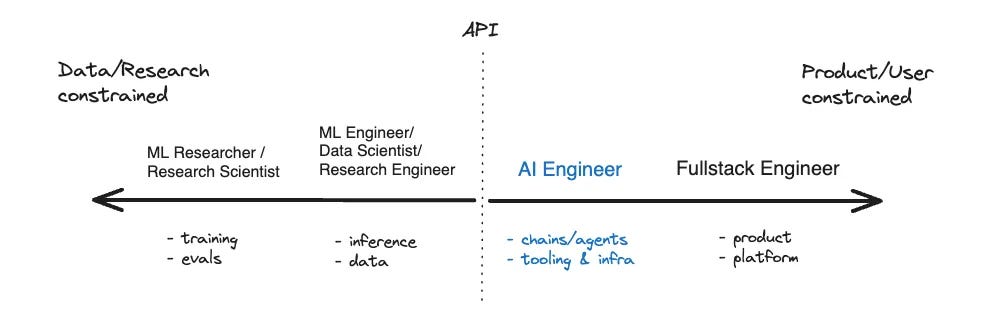
The rise of the AI Engineer … looks like we all need to learn more engineering skills

Bigger picture ideas
Longer thought provoking reads - lean back and pour a drink! ...
Stephen Wolfram argues that LLMs are closer to how human’s think than we realise- worth a quick 10 minute listen. Certainly thought provoking that by some measures the human brain is only 100 times more complex than GPT4… Also a thought provoking longer piece: Generative AI Space and the Mental Imagery of Alien Minds
"But the fundamental story is always the same: there’s a kind of “cat island”, beyond which there are weird and only vaguely cat-related images—encircled by an “ocean” of what seem like purely abstract patterns with no obvious cat connection. And in general the picture that emerges is that in the immense space of possible “statistically reasonable” images, there are islands dotted around that correspond to “linguistically describable concepts”—like cats in party hats.
The islands normally seem to be roughly “spherical”, in the sense that they extend about the same nominal distance in every direction. But relative to the whole space, each island is absolutely tiny—something like perhaps a fraction 2–2000 ≈ 10–600 of the volume of the whole space. And between these islands there lie huge expanses of what we might call “interconcept space”."Then again… “Toward AGI — What is Missing?”
"However, I am generally skeptical of arguments that Large Language Models such the GPT series (GPT-2, GPT-3, GPT-4, GPT-X) are on the pathway to AGI. This article will attempt to explain why I believe that to be the case, and what I think is missing should humanity (or members of the human race) so choose to try to achieve AGI"Excellent summary of “Open challenges in LLM research” from Chip Huyen
"1. Reduce and measure hallucinations
2. Optimize context length and context construction
3. Incorporate other data modalities
4. Make LLMs faster and cheaper
5. Design a new model architecture
6. Develop GPU alternatives
7. Make agents usable
8. Improve learning from human preference
9. Improve the efficiency of the chat interface
10. Build LLMs for non-English languages”“Coming back to the 21st century, we’re sitting on the precipice of a step-change in the cost to generate insights, and I think we’re going to see a similar rebound effect with AI.
It may be correct that we require less human hours to do data tasks on a micro level: I certainly think data practitioners will be spending less time writing boilerplate or casting types than we do today.
But the demand for data work isn’t fixed; there's not some finite number of stakeholder questions, or decisions that could informed with data. In fact, we’re deeply supply constrained! The number of insights an organization generates is a function of the size of the data team, which is the result of a financial budgeting process – not a bottoms-up supply-demand matching exercise. In every organization, there are way more questions that could and should be answered.“To illustrate this, consider a simple economy with two sectors, writing think-pieces and constructing buildings. Imagine that AI speeds up writing but not construction. Productivity increases and the economy grows. However, a think-piece is not a good substitute for a new building. So if the economy still demands what AI does not improve, like construction, those sectors become relatively more valuable and eat into the gains from writing. A 100x boost to writing speed may only lead to a 2x boost to the size of the economy""This underlying idea of actionable recourse shows up in many applications. There is an example I return to often, since it’s a pattern that we see across many countries. In the USA there is an algorithm to determine poor people’s health care benefits. When it was implemented in one state there was a bug in the code that incorrectly cut care for people with cerebral palsy. Tammy Dobbs was one of the many people that lost care due to a software bug. She needed this care for very basic life functions: to help her get out of bed in the morning, to get her breakfast, and so on. She asked for an explanation and they didn’t give her one; they just said this is what the algorithm determined. At the root, what she needed was not just an explanation, but a mechanism for recourse to get the decision changed. Eventually the error was revealed through a lengthy court case, but that is a terrible setup.""The “paperclip maximizer” thought experiment is actually a metaphor I quite like. It does a good job of providing intuition for the scenario that it models. I just don’t believe that scenario is very likely. Unlike the “King Midas” metaphor, in the “paperclip maximizer” setting, the AI model is not “over optimizing” a human-provided objective but rather pursuing a goal that is completely unaligned with those of its human creators. Moreover, it pursues this goal with such fanaticism, that it cannot spare any resources, and so the whole galaxy is not big enough for humans and this goal to co-exist.""In 1967, Marvin Minksy, a founder of the field of artificial intelligence (AI), made a bold prediction: “Within a generation…the problem of creating ‘artificial intelligence’ will be substantially solved.” Assuming that a generation is about 30 years, Minsky was clearly overoptimistic. But now, nearly two generations later, how close are we to the original goal of human-level (or greater) intelligence in machines?""GPT-4 responds that, “based on the information provided”, Bob would believe the parrot to be in the covered cage somewhere in the room. “Since he left before Alice came and moved the cage into the cupboard, he has no knowledge of that act.” Alice, for her part, “would believe the parrot to be in the covered cage inside the cupboard".
So far, so good. But the bit I really like comes next. “The parrot,” says GPT-4, “unless it has a very advanced understanding of human actions, will likely be aware only of its immediate surroundings and not have a clear concept of ‘being in the cupboard’. It would sense that it’s in a dark and confined space (the covered cage) but, beyond that, it’s hard to say what a parrot’s perception or understanding would be.”
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
Impressive (if depressing) visualisation: “Mapping where the earth will become uninhabitable”
Geospatial fun and games … “Urbanity”



AI Dad Jokes .. “AI Dad Jokes is an AI system that writes humorous content inspired by images” … I mean what’s not to like?!

Updates from Members and Contributors
Many congratulations to Marco Gorelli who I know was heavily involved in Polars and this announcement
Dr. Stephen Haben, draws our attention to the AI for Decarbonisation innovation programme, where various successful projects are highlighted. Applications for stream 3 are now open
Mia Hatton, Data Science Community Project Manager at the ONS Data Science Campus informs us about Data Connect23, a week-long, virtual event series, is taking place from 25 - 29 September 2023. All public sector employees with an interest in data are invited to attend. Register here
Erkan Malcok highlights the Institute of Mathematics’ upcoming event - ‘Mathematical Foundations of AI’ on October 13 - register here
Jona Shehu, on behalf of the SAIS (Secure AI aSsistants) team of researchers, highlights an upcoming roundtable discussion around the future of voice assistants at CogX Festival on September 13th: “The Future of Privacy and Security for Voice: Safeguarding Our Vocal Identity in the Digital Age”
Sarah Phelps, Project Support Officer at the UK Statistics Authority, highlights two upcoming ESSnet Web Intelligence Network events which look interesting:
Measuring Construction Activities using Data from the Web, 5 October 2023 - register here
New avenues with Web Intelligence: Gaining additional value from cash register data by combining different data sources, 23 November 2023 - register here
Jobs!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS