
November Newsletter
Industrial Strength Data Science and AI

Hi everyone-
Well, the clocks have recently changed in the UK- a sure sign of darker nights and colder weather… so high time to curl up with some thought provoking AI and Data Science reading materials!
Following is the November edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right.
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science, ML and AI practitioners. And if you are not signed up to receive these automatically you can do so here
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
Are you passionate about data science and AI? We are looking for new committee members … are you interested?
We explore emerging topics that affect the long-term success of data science and AI as a profession. We organise and deliver an annual program of events and activities that push forward the debate around opportunities and challenges posed by data science, artificial intelligence and machine learning.
We are keen to encourage expressions of interests from diverse backgrounds, so that our committee is inclusive of gender, ethnicity, socio-economic background and career stage. The only qualifying criteria are a passion for data science and AI, a commitment to the work of the Section, and you will need to be a fellow of the RSS.
If you are interested, please contact Louisa Nolan at datasciencesection@rss.org.uk by Friday 1 December, with a paragraph (up to 200 words) summarising why you would like to join, who you are (e.g. geography, job sector, career path and stage), any topics you would like to explore or ideas for the section, and anything else you think is relevant.
Despite our calls for inclusion, we were disappointed by the the list of attendees to the UK AI Safety Summit, dominated by the large tech companies without representation for practitioners and start-ups (see below for more details)
Our AGM (at the RSS HQ) and Christmas social is on the 5th Dec so hold the date! Drinks to follow at a local establishment… Sign up here
We are continuing our work with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is now accepting applications for the Advanced Data Science Professional certification- more details here.
Some great recent content published by Brian Tarran on our sister blog, Real World Data Science:
American Statistical Association joins Real World Data Science as partner
Data science career profile with Niclas Thomas, head of data science, Next
Feelings about sharing data can be context and time dependent – you can’t just do one survey or focus group: Real World Data Science sits down with Helen Miller-Bakewell of the UK Office for Statistics Regulation
Planning is already underway for the RSS 2024 International Conference which will take place in Brighton from 2-5 September. The organisers are currently calling for proposals for sessions and workshops at the conference; topics can include new research and results, collaborations between different sectors, areas of controversy/debate, novel applications, topical discussion and informative and innovative case studies. The deadline for proposals is 20 November.
We are very pleased and excited to announce that our section secretary, Louisa Nolan, Head of Public Health Data Science, Public Health Wales, has been elected to the RSS Council from January 2024- many congrats Louisa!
Our Chair Janet Bastiman, Chief Data Scientist at Napier AI, is presenting on Ethics and Trust in AI at Enterprise Data and Business Intelligence & Analytics Conference Europe (irmuk.co.uk) 7-10th November.
Martin Goodson, CEO and Chief Scientist at Evolution AI, published his recent talk “An AI for Humanity” a brilliant read advocating for large scale open source AI projects that gained a lot of traction in the community.
Martin also continues to run the excellent London Machine Learning meetup and is very active with events. The next event, on November 15th, looks to be a great one with Baptiste Rozière, Research Scientist at Meta AI, presenting "Code Llama: Open Foundation Models for Code”. Videos are posted on the meetup youtube channel - and future events will be posted here.
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
The big news as I write this is the UK’s AI Safety Summit (for more background on the UK Government’s various AI Regulatory initiatives, this is a good summary from Allen & Overy)
The summit is something the UK Government has been touting heavily with attendees including US Vice President Kamala Harris, and Elon Musk.
The idea of the conference is laudable: certainly pulling together leading figures from around the world, including China, is positive, and the opportunity for the UK to take a leading position is real
That being said, the specifics are more questionable
"One of the executives invited to Rishi Sunak’s international AI safety summit next month has warned that the conference risks achieving very little, accusing powerful tech companies of attempting to “capture” the landmark meeting."The white paper issued prior to the summit (Capabilities and risks from
frontier AI) lays out the different risks sensibly, taking in the ‘here and now’ problems (algo bias, missinformation etc.) as well as the more existential longer term nightmare scenarios (critical system interference, biological weapons etc.)
However, the summit appears to be focusing almost entirely on the latter which goes against the advice of many leading luminaries in the field including Yann LeCun, Margaret Mitchell, Emily Bender and Sasha Luccioni
"Altman, Hassabis, and Amodei are the ones doing massive corporate lobbying at the moment," LeCun wrote, referring to these founders' role in shaping regulatory conversations about AI safety. "They are the ones who are attempting to perform a regulatory capture of the AI industry." He added that if these efforts succeed, the outcome would be a "catastrophe" because "a small number of companies will control AI."With attendees dominated by the big tech players, there is a serious risk of a regulatory environment designed to entrench those incumbents
"If the AI Safety Summit is to be judged a success — or at least on the right path to creating consensus on AI safety, regulation, and ethics — then the UK government must strive to create an even playing field for all parties to discuss the future use cases for the technology,” Zenil said. “The Summit cannot be dominated by those corporations with a specific agenda and narrative around their commercial interests, otherwise this week’s activities will be seen as an expensive and misleading marketing exercise.”As you all know, we are fierce advocates of open source and the voice of the practitioner, and added our voice to the call for wider representation
Leave it to ‘friend of the section’ Andrew Ng to frame the risks sensibly
"I firmly believe that AI has the potential to help people lead longer, healthier, more fulfilling lives. One of the few things that can stop it is regulators passing ill-advised laws that impede progress. Some lobbyists for large companies — some of which would prefer not to have to compete with open source — are trying to convince policy makers that AI is so dangerous, governments should require licenses for large AI models. If enacted, such regulation would impede open source development and dramatically slow down innovation."
Not to be “out-AI’d”, US President Biden issued an “Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence“ , to somewhat luke-warm acclaim
"Even where the order appears to cover its bases, there might be “considerable mismatch between what policymakers expect and what is technically feasible,” Ho adds. He points to “watermarking” as a central example of that. The new policy orders the Department of Commerce to identify best practices for labeling AI-generated content within the next eight months—but there is no established, robust technical method for doing so."Lots of “State of AI” missives out this month:
First of all, the ‘original’ - State of AI Report 2023 from Nathan Benaich… all 163 slides of it!

Then we have the State of Open Source AI

Useful commentary on the legal and policy side of GenAI in the media sector
“Senator Cory Booker: “[O]ne of my biggest concerns about this space is what I’ve already seen in the space of web two, web three is this massive corporate concentration. It is really terrifying to see how few companies now control and affect the lives of so many of us. And these companies are getting bigger and more powerful.Some positive news from Hollywood where the the writer’s strike (about use of AI amongst other things) has been resolved successfully
Finally, a high level but thoughtful read advocating for more “red-teaming” - to identify potential risks from AI models
"These corporate AI red-teaming efforts and documents are important, but there are two big limitations to them. First, when internal red teams uncover abhorrent AI behavior that could spook investors and scare off customers, the company could try to fix the problem—or they could just ignore it and hope not enough people notice, or care. There is no accountability imposed. Second, the landscape of possible inputs to AI systems is far too vast for any one team to explore. Just ask New York Times tech columnist Kevin Roose, who tested Microsoft’s Bing chatbot, powered by GPT-4, in ways the company’s internal red teams had missed: his prompts led the chatbot to beg him to leave his wife.
Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
While GenAI is cool and exciting, there is research going on in other fields!
An alternative approach for regression tasks when the underlying data is of questionable quality - Bayesian Regression Markets
Experimental results of targeted nudges… Causal vs Predictive Targeting in a Field Experiment on Student Financial Aid Renewal
My favourite weird and wonderful topic… “Grokking”- the crazy phenomena of ML models getting better at generalisation when they are overfitted…Explaining grokking through circuit efficiency
"Most strikingly, we demonstrate two novel and surprising behaviours: ungrokking, in which a network regresses from perfect to low test accuracy, and semi-grokking, in which a network shows delayed generalisation to partial rather than perfect test accuracy"
Facebook/Meta are still producing a lot of excellent research- this time in the field of robotics: Introducing Habitat 3.0: The next milestone on the path to socially intelligent robots

Although… do robots make us more productive? Lean back or lean in? Exploring social loafing in human–robot teams
Of course GenAI is still very popular! Lots of fundamental exploration of different approaches to building Large Language Models as always:
A new approach to learning from mistakes: AI ‘breakthrough’: neural net has human-like ability to generalize language
"It’s not magic, it’s practice,” Lake says. “Much like a child also gets practice when learning their native language, the models improve their compositional skills through a series of compositional learning tasks.”Improving computation efficiency - Training and inference of large language models using 8-bit floating point
Improving LLM’s approach to numbers with continuous number encoding rather than tokenising
"Large Language Models have not yet been broadly adapted for the analysis of scientific datasets due in part to the unique difficulties of tokenizing numbers. We propose xVal, a numerical encoding scheme that represents any real number using just a single token. xVal represents a given real number by scaling a dedicated embedding vector by the number value... Compared with existing number encoding schemes, we find that xVal is more token-efficient and demonstrates improved generalization."Does RLHF (Reinforcement Learning from Human Feedback - the approach used to fine tune Large Language Models using human evaluation of model outputs) simply reward longer responses? Maybe so…
"Open-source preference datasets and reward models have enabled wider experimentation beyond generic chat settings, particularly to make systems more "helpful" for tasks like web question answering, summarization, and multi-turn dialogue. When optimizing for helpfulness, RLHF has been consistently observed to drive models to produce longer outputs. This paper demonstrates that optimizing for response length is a significant factor behind RLHF's reported improvements in these settings."Are we already seeing the end of the Prompt-Engineer job? … Deepmind's Promptbreeder automates prompt engineering (paper here)
"Popular prompt strategies like Chain-of-Thought Prompting can dramatically improve the reasoning abilities of Large Language Models (LLMs) in various domains. However, such hand-crafted prompt-strategies are often sub-optimal. In this paper, we present Promptbreeder, a general-purpose self-referential self-improvement mechanism that evolves and adapts prompts for a given domain. Driven by an LLM, Promptbreeder mutates a population of task-prompts, and subsequently evaluates them for fitness on a training set. Crucially, the mutation of these task-prompts is governed by mutation-prompts that the LLM generates and improves throughout evolution in a self-referential way."
And lots of research into novel and specialised uses of GenAI
Using Stable Diffusion for visual segmentation tasks: Diffuse, Attend, and Segment: Unsupervised Zero-Shot Segmentation using Stable Diffusion
Music understanding and composition with MusicAgent
More evaluation of LLM’s for software engineering
Can LLM’s be used for time series forecasting? Yes! Large Language Models Are Zero-Shot Time Series Forecasters
"By encoding time series as a string of numerical digits, we can frame time series forecasting as next-token prediction in text. Developing this approach, we find that large language models (LLMs) such as GPT-3 and LLaMA-2 can surprisingly zero-shot extrapolate time series at a level comparable to or exceeding the performance of purpose-built time series models trained on the downstream tasks... We argue the success of LLMs for time series stems from their ability to naturally represent multimodal distributions, in conjunction with biases for simplicity, and repetition, which align with the salient features in many time series, such as repeated seasonal trends."
Some more philosophical approaches to understanding Large Language Models…
Large Language Models as Analogical Reasoners
"In this work, we introduce a new prompting approach, Analogical Prompting, designed to automatically guide the reasoning process of large language models. Inspired by analogical reasoning, a cognitive process in which humans draw from relevant past experiences to tackle new problems, our approach prompts language models to self-generate relevant exemplars or knowledge in the context, before proceeding to solve the given problem."Language Models Represent Space and Time - excellent paper with Max Tegmark as contributing author (although see rebuttal from Gary Marcus in the big picture ideas section)
"The capabilities of large language models (LLMs) have sparked debate over whether such systems just learn an enormous collection of superficial statistics or a coherent model of the data generating process -- a world model. We find evidence for the latter by analyzing the learned representations of three spatial datasets (world, US, NYC places) and three temporal datasets (historical figures, artworks, news headlines) in the Llama-2 family of models"Does ChatGPT have semantic understanding? A problem with the statistics-of-occurrence strategy
"SOMs do not themselves function to represent or produce meaningful text; they just reflect the semantic information that exists in the aggregate given strong correlations between word placement and meaningful use.""Overall, more than half (57.4%) of the users found GPT-4 generated feedback helpful/very helpful and 82.4% found it more beneficial than feedback from at least some human reviewers."Good summary of current work on hallucination - Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Interesting idea- are the surprising ‘untrained’ abilities we see exhibited in LLMs simply a bi-product of our different training approaches? Are Emergent Abilities in Large Language Models just In-Context Learning?
"Large language models have exhibited emergent abilities, demonstrating exceptional performance across diverse tasks for which they were not explicitly trained, including those that require complex reasoning abilities. The emergence of such abilities carries profound implications for the future direction of research in NLP, especially as the deployment of such models becomes more prevalent. However, one key challenge is that the evaluation of these abilities is often confounded by competencies that arise in models through alternative prompting techniques, such as in-context learning and instruction following, which also emerge as the models are scaled up."
Digging into the cutting edge - The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)
"Observations from these samples demonstrate that GPT-4V's unprecedented ability in processing arbitrarily interleaved multimodal inputs and the genericity of its capabilities together make GPT-4V a powerful multimodal generalist system. Furthermore, GPT-4V's unique capability of understanding visual markers drawn on input images can give rise to new human-computer interaction methods such as visual referring prompting. We conclude the report with in-depth discussions on the emerging application scenarios and the future research directions for GPT-4V-based systems"Finally, a thoughtful piece from Anthropic: Decomposing Language Models Into Understandable Components



Generative AI ... oh my!
Still such a hot topic it feels in need of it's own section, for all things DALLE, IMAGEN, Stable Diffusion, ChatGPT...
While the big players may be struggling to turn GenAI into profits, it is not stopping the pace of investment and innovation…
Amazon is investing up to $4b in Anthropic to “develop the most reliable and high-performing foundation models in the industry” and become the primary LLM provider on AWS (as OpenAI is on Azure, and Google’s PALM/Bard is on GCP)
Meta/Facebook has executed an impressive pivot away from the metaverse and is doubling down on AI, announcing both GenAI tools to improve Ad effectiveness as well as a suite of consumer-facing AI ‘personalities’
Google continues its push towards ‘AI as a feature’, with new GenAI powered creative tools in YouTube, and the launch of the new AI laden Pixel 8 phone (“to help you bring your photos in line with the essence of the moment you were trying to capture”)
Following Microsoft’s announcement last month, Google is also indemnifying their GenAI users from copyright infringement (“If you are challenged on copyright grounds, we will assume responsibility for the potential legal risks involved.”), an approach that getty images is also pushing
Of course the big news right at the end of last month was the launch of the new ‘multimodal’ GPT-4V from OpenAI…
But what is multimodal…. great explanatory post from Chip Huyen, well worth a read

The results are certainly impressive…
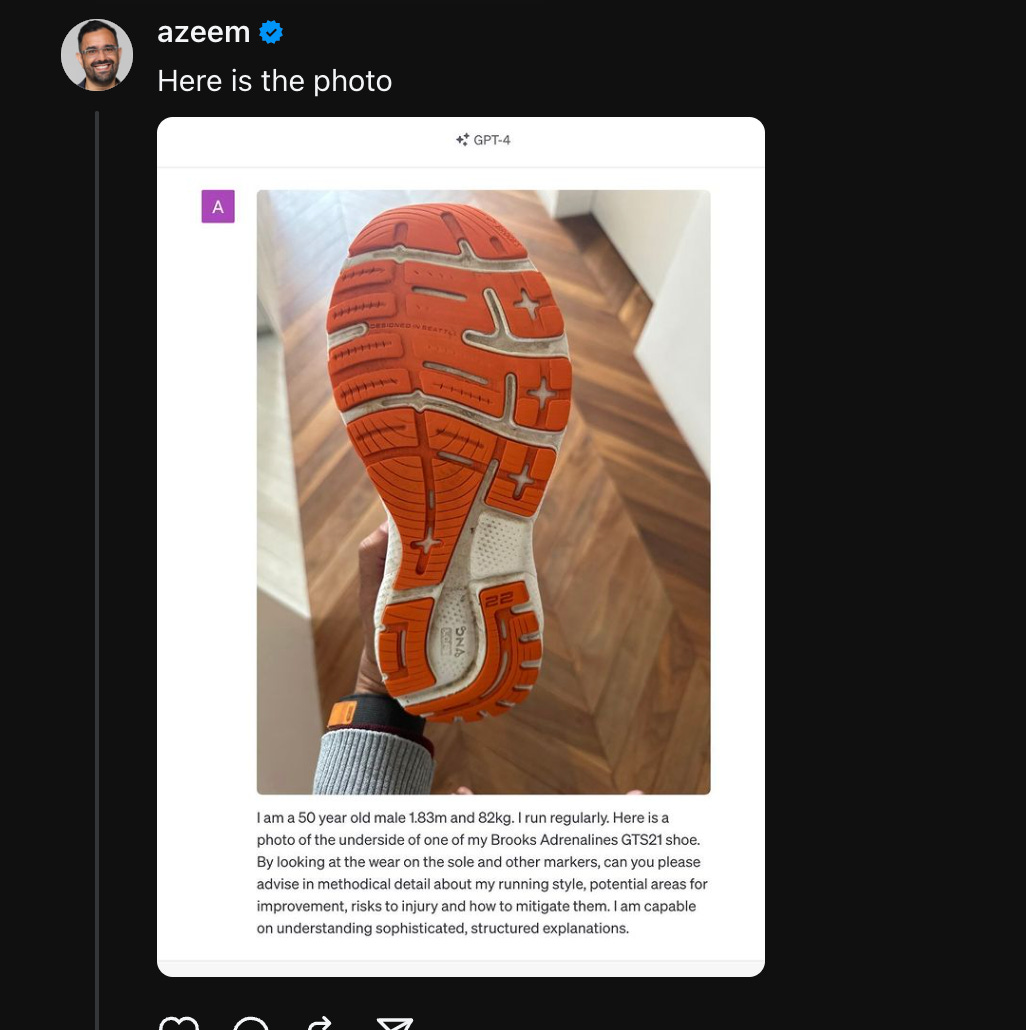
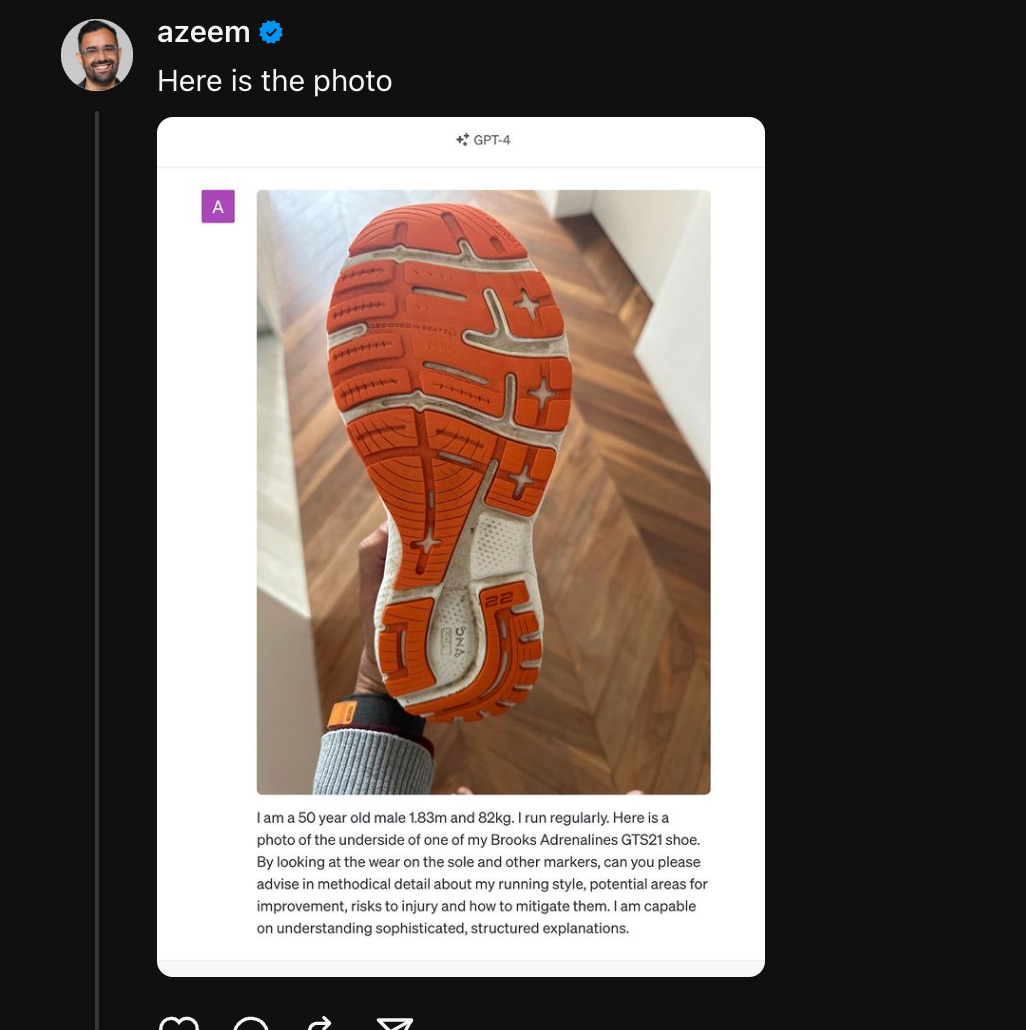
Azeem Azhar has his running stride analysed by simply supplying a photo of the bottom of his running shoe to ChatGPT
“ChatGPT breaks down this diagram of a human cell for a 9th grader.”

DALL-E3, the new image model underlying GPT-4V, is impressive in its own right… more opportunities for prompt engineering
"A fascinating thing about DALL-E 3 is that you don’t prompt it directly: you instead access it via ChatGPT, which prompts the model for you. ChatGPT then turns your query into several prompts, each producing a different image. The prompts it generates are available if you click on the images (on mobile you have to flip your phone horizontal to see that option)."
Still lots going on in the open source community- often creating focussed offerings for specific use cases
A specialist LLM for database interactions: DB-GPT
AlpaCare: Instruction-tuned Large Language Models for Medical Applications

MEM-GPT - for chatbots with self-editing memory
Finetuning - adapting an ‘off the shelf’ large language model using your own proprietary data- is still very much a hot-topic…
First of all, pick your open source model e.g. Llama2
Follow a nice step by step tutorial… maybe like this one to get a feel for what you are trying to do
Go a little deeper once you’ve tried it out a little, to learn some of the tips and tricks, or maybe try some alternative approaches
Then, if you need to get serious… “Everything about Distributed Training and Efficient Finetuning“
Still lots of discussion about “RAG” (Retrieval augmented generation - using chatbots on your own information) based applications

A critical topic with these applications… how do you know they are any good?
Good introductory post from Databricks on their learnings about evaluation
Some more general background on the challenges of evaluation from Anthropic
Agents remain a hot topic… turning a simple chatbot into a complex tool that can solve a wide variety of tasks
Thoughtful discussion here: “AI Agents vs Developers“
If you want to experiment… OpenAgents: An Open Platform for Language Agents in the Wild
And once you’ve got something up and running … AgentTuning: Enabling Generalized Agent Abilities For LLMs
And maybe you end up with this

If you really get serious have a read of this - “Building AI Agents in Production“
A deep dive into the weird and wonderful world of voice cloning… very educational!
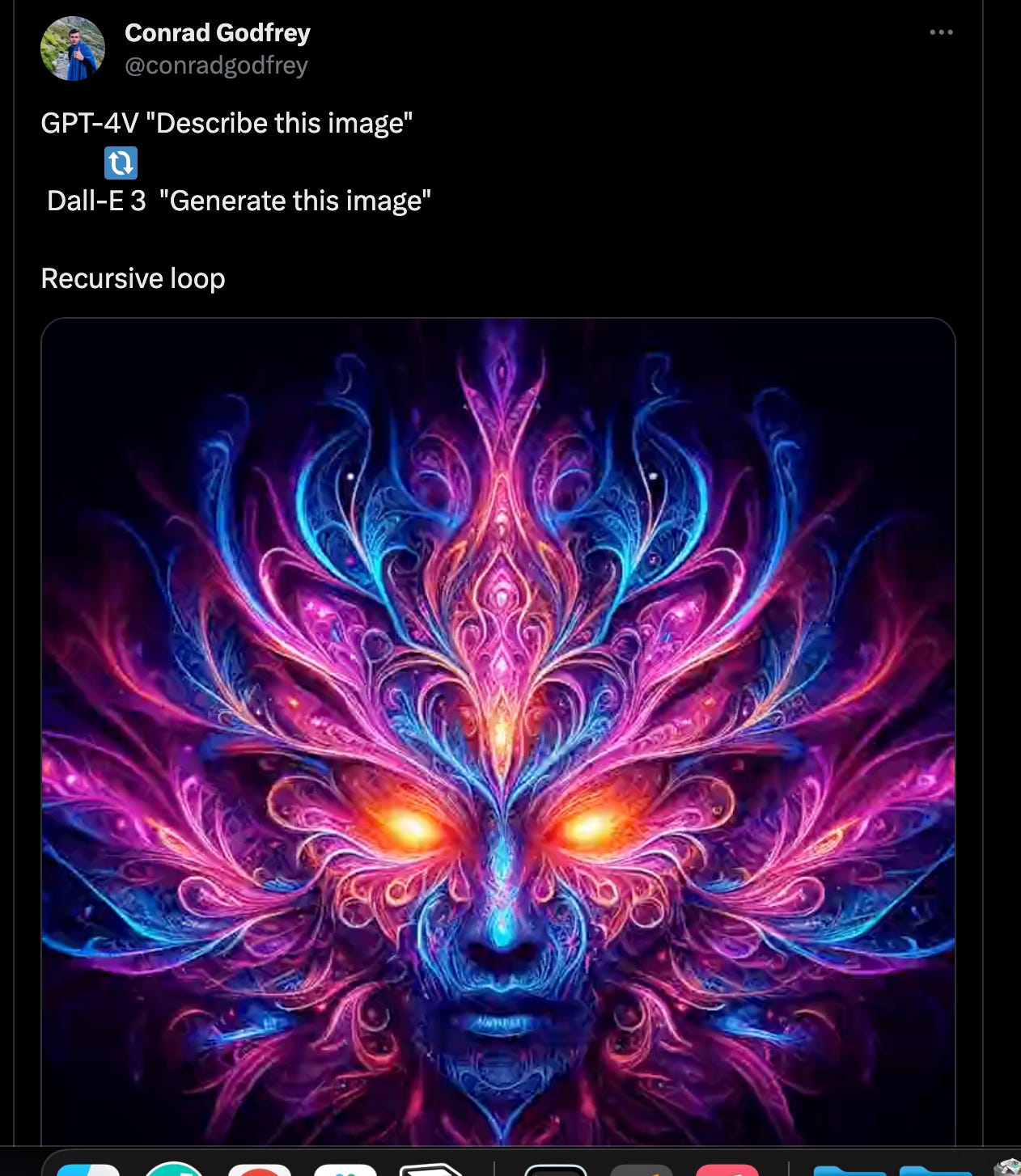
"This got me thinking: what if every Weird Al song was the original, and every other artist was covering his songs instead? With recent advances in A.I. voice cloning, I realized that I could bring this monstrous alternate reality to life. This was a terrible idea and I regret everything."Finally… a sort of ChatGPT fuelled game of Chinese Whispers… (you really should check out the sequence…it starts with the Mona Lisa!)






Real world applications and how to guides
Lots of practical examples and tips and tricks this month
Podcasts for all! “Spotify’s AI Voice Translation Pilot Means Your Favorite Podcasters Might Be Heard in Your Native Language”
"This Spotify-developed tool leverages the latest innovations—one of which is OpenAI’s newly released voice generation technology—to match the original speaker’s style, making for a more authentic listening experience that sounds more personal and natural than traditional dubbing. A podcast episode originally recorded in English can now be available in other languages while keeping the speaker’s distinctive speech characteristics."Uber using anomaly detection to combat fraud: risk entity watch - a useful real world application of graph based approaches (useful set of graph mining tools here from Google)

“The art of data: Empowering art institutions with data and analytics”
Google’s guide to AI for marketers: “What AI can and can’t do — and what that means for marketers“
Embeddings are becoming increasingly useful….
Here’s how LinkedIn is using them to improve matching

And here’s an excellent in-depth primer: “Embeddings: What they are and why they matter“
Another hot topic is explainability…
First of all an extensive tutorial: “Interpretable Machine Learning“
And a good recent lecture from the Imperial College Centre for Explainable AI
With Deep Learning models, the learning rate is an important tuneable hyper-parameter… but how should you tune it? Useful insight from Amazon Science
How do you get a Large Language Model to “unlearn” something- interesting question, and good post, well worth a look
How close are “Neural Nets” to actual “NeuroScience”? Why not take this course and find out (Neuroscience for machine learners)?
With all our focus on AI and machine learning it’s easy to forget the importance of stats…
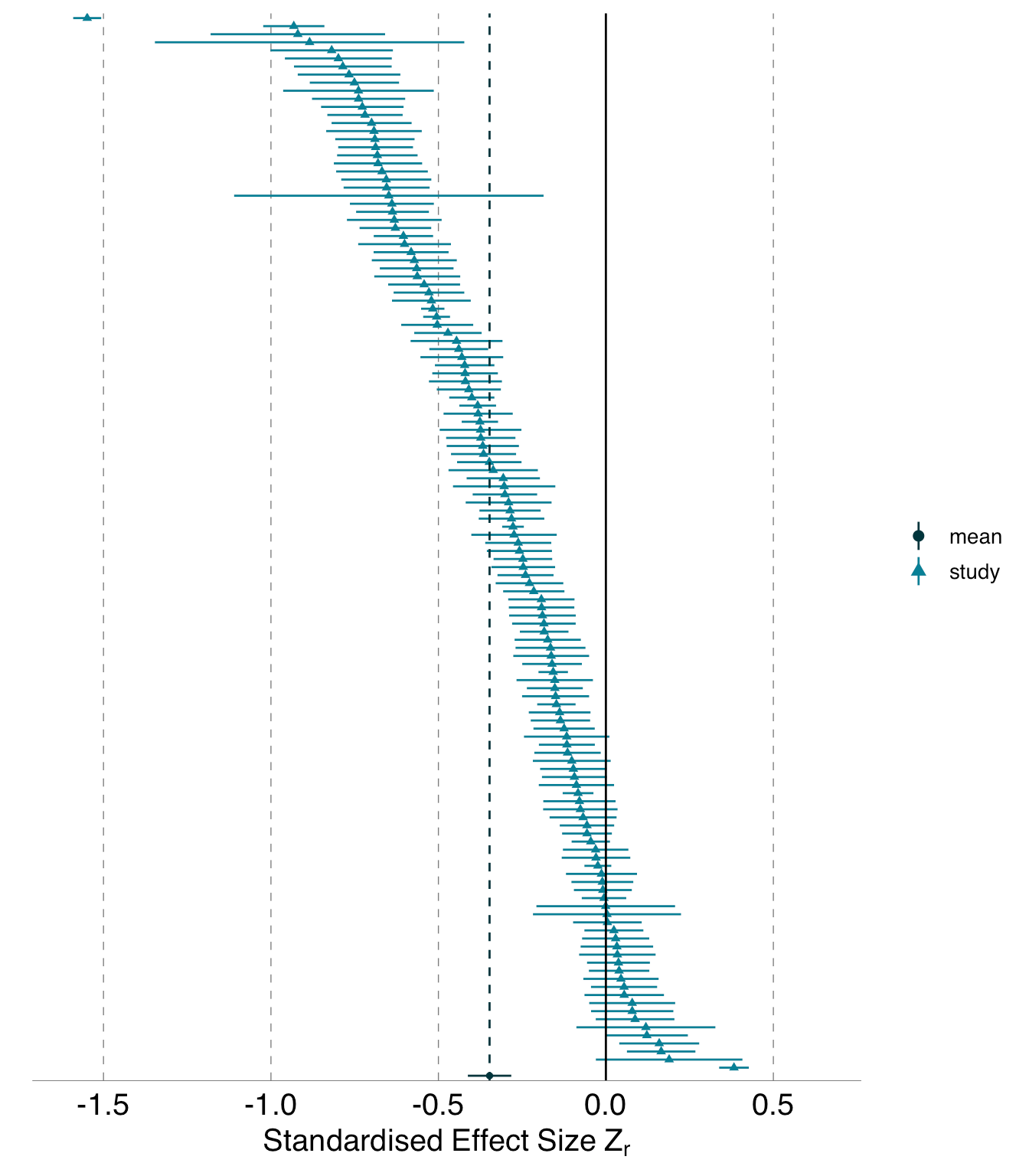
This is a sobering read- we all assume that given a data set, different data scientists should align on analytical findings, but that may not be the case… “Same data, different analysts: variation ineffect sizes due to analytical decisions inecology and evolutionary biology“
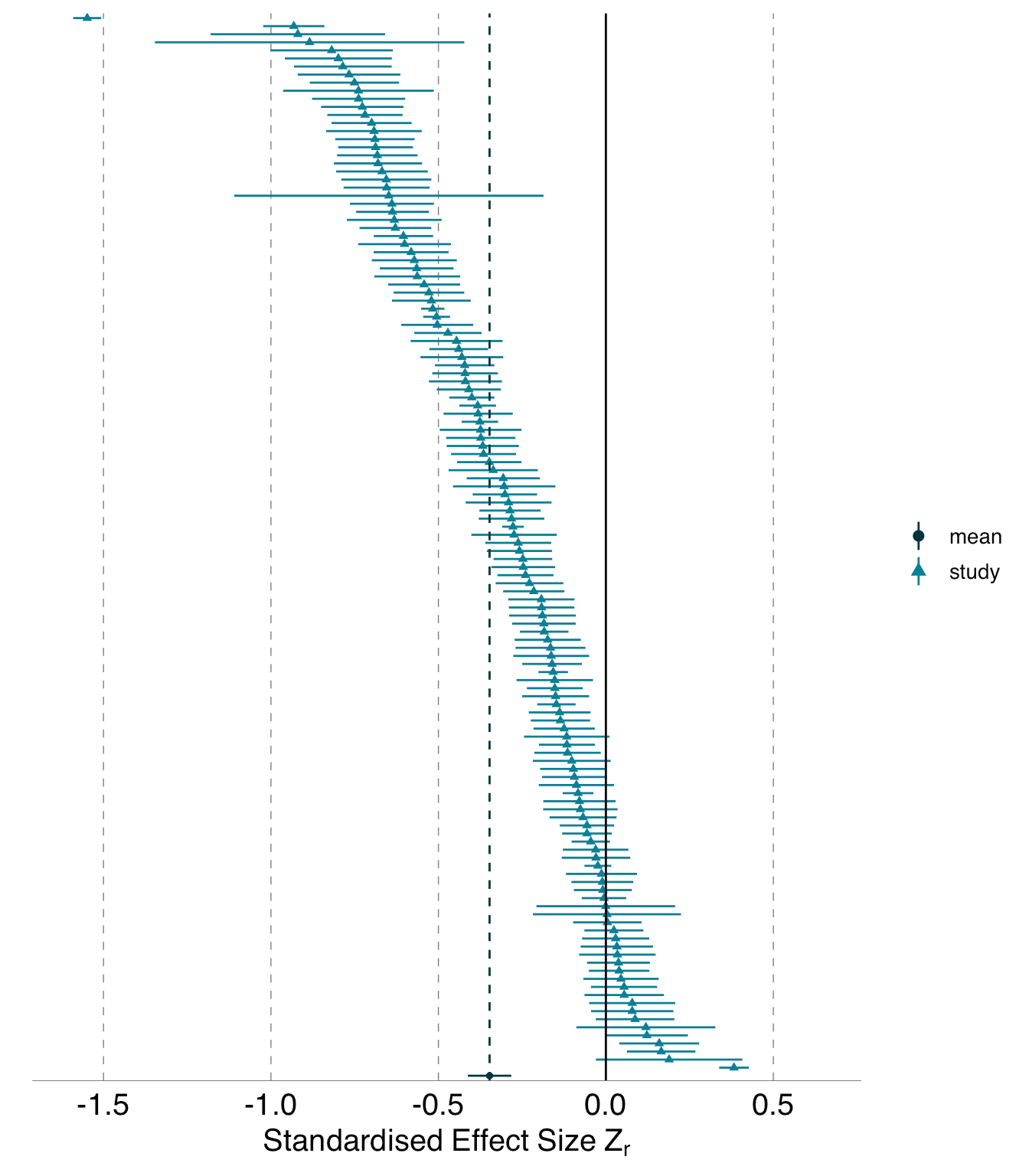
"When a large pool of ecologists and evolutionary biologists analyzed the same two datasets to answer the corresponding two research questions, they produced substantially heterogeneous sets of answers. Although the variability in analytical outcomes was high for both datasets, the patterns of this variability differed distinctly between them. For the blue tit dataset, there was nearly continuous variability across a wide range of values. In contrast, for the Eucalyptus dataset, there was less variability across most of the range, but more striking outliers at the tails"How should you characterise a correlation statistic? Is 0.3 big or small? “What Size is That Correlation”
“Beyond Hypothesis Tests & P-values: Iterative Refinement in Science and Business” - interesting and practical approach to iterative refinement
And rounding out our stats section… “Causal inference as a blind spot of data scientists“
"Now, how does this relate to data science and business decisions? Well, businesses make important choices every day, like where to invest money, who to hire or fire, and what the consequences of public policies might be. The data they collect only shows one side of reality. To really understand the results of their decisions, they need to explore an unseen or simulated reality. That’s where causal inference comes in, helping us make better decisions by considering alternative outcomes."
Finally, some visualisation pointers



Practical tips
How to drive analytics and ML into production
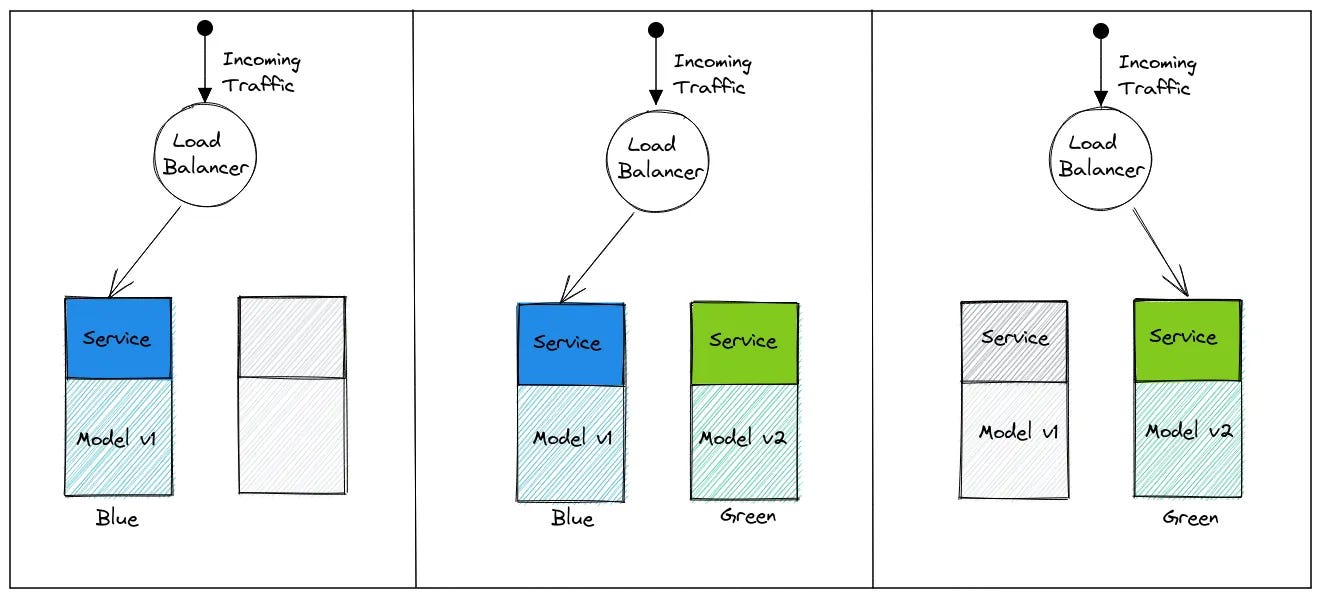
First of all, for those who don’t know they ‘canary’ from their ‘blue-green’, a useful primer on different ML deployment patterns

As always, lots of chat about MLOps-
Here’s Databricks latest ebook on the topic
And AWS’s take on applying MLOps principles to LLM deployment

Another open source tool to try: “Pezzo is a fully cloud-native and open-source LLMOps platform.“
A decent post on the challenges of data integration (as well as an open source slimline alternative to dbt… lea)
This looks like a potentially useful resource: Open Source Deep Learning containers (Deep Learning Ultra)
And if you need fast translations on the fly…. checkout, “insanely fast whisper“
Guess what… there’s a new version of XGBoost! (native support for Apple Silicon)
And this looks worth a quick try- “CAAFE lets you semi-automate your feature engineering process based on your explanations on the dataset and with the help of language models.“
Finally, an open source visualisation tool-kit from McKinsey of all people! Vizro



Bigger picture ideas
Longer thought provoking reads - lean back and pour a drink! ...
How a billionaire-backed network of AI advisers took over Washington, from Politico
"In the high-stakes Washington debate over AI rules, Open Philanthropy has long been focused on one slice of the problem — the long-term threats that future AI systems might pose to human survival. Many AI thinkers see those as science-fiction concerns far removed from the current AI harms that Washington should address. And they worry that Open Philanthropy, in concert with its web of affiliated organizations and experts, is shifting the policy conversation away from more pressing issues — including topics some leading AI firms might prefer to keep off the policy agenda."On the one side… Artificial Intelligence is Already Here, from Blaise Agueray Arcas and Peter Norvig
“The most important parts of AGI have already been achieved by the current generation of advanced AI large language models.”And on the other… Muddles about Models, from Gary Marcus (of course!), countering the paper referenced in the research section above (“Language Models Represent Space and Time”), and talked to a discussion on twitter/X
"Although I have little doubt in the results, I sharply disagree with their argument. Of course as Fei Fei Li correctly pointed out on X, it all depends on what you mean by a “model”, but here’s the crux, same as it ever was: correlations aren’t causal, semantic models. Finding that some stuff correlates with space or time doesn’t mean that stuff genuinely represents space or time. No human worth their salt would think there are dozens of cities thousands of miles off East Coast, throughout the Atlantic Ocean."How ChatGPT and other AI tools could disrupt scientific publishing, from Gemma Conroy in Nature
"Science publishers and others have identified a range of concerns about the potential impacts of generative AI. The accessibility of generative AI tools could make it easier to whip up poor-quality papers and, at worst, compromise research integrity, says Daniel Hook, chief executive of Digital Science, a research-analytics firm in London. “Publishers are quite right to be scared,” says Hook"Then again, maybe …. Generative AI is Boring, from Jacob Browning
"We already know they can't reason, can't plan, only superficially understand the world, and lack any understanding of other people. And, as Sam Altman and Bill Gates have both attested, scaling up further won't fix what ails them. We're now able to evaluate what they are with fair confidence it won't improve much by doing more of the same. And the conclusion is: they're pretty boring."This is something we can all get behind… Why We’re Building an Open-Source Universal Translator, from Pete Warden
"Science fiction translators are effortless. You can walk up to someone and talk normally, and they understand what you’re saying as soon as you speak. There’s no setup, no latency, it’s just like any other conversation. So how can we get there from here?"Finally, How to Think Computationally about AI, the Universe and Everything - Stephen Wolfram, always a good read
"It all starts from the idea that space—like matter—is made of discrete elements. And that the structure of space and everything in it is just defined by the network of relations between these elements—that we might call atoms of space. It’s very elegant—but deeply abstract."

Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
Interactive visualisation of algebra
If you fancy using your ML skills for good, with a chance of prizes, this looks great fun! “First word discovered in unopened Herculaneum scroll by 21yo computer science student“

The Iconic Harry Beck Map But Make It Aeroplanes




Updates from Members and Contributors
Mia Hatton, Data Science Community Project Manager at the ONS Data Science Campus informs us about the upcoming Data Science Community Showcase (more info here)
”The Data Science Community Showcase is a virtual conference for all public sector employees with an interest in data science. A celebration of the power of community, the conference will take place over three days (28-30 November) with a different theme each day. Whether you are looking to develop your skills and career on day one, supplement your data science toolshed on day two, or explore the impact of data science on day three, there is something for everyone in the public sector with an interest in data science. Sign up here”
Jobs!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS