
May Newsletter
Industrial Strength Data Science

Hi everyone-
Another month flies by and May is here… and this year in the UK, May is richly blessed with Bank Holidays so ... hopefully plenty of time to catch up on the data science and AI developments of the last month. Don't miss out on more generative AI fun and games in the middle section!
Following is the May edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly click on the “Open Online” link at the top right.
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here
handy new quick links: committee; ethics; research; generative ai; applications; tutorials; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
We are actively planning our activities for the year, and are currently working with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is now accepting applications for the Advanced Data Science Professional certification- more details here.
This year’s RSS International Conference will take place in the lovely North Yorkshire spa town of Harrogate from 4-7 September. As usual Data Science is one of the topic streams on the conference programme, and there is currently an opportunity to submit your work for presentation. There are options available for 5-minute rapid-fire talks and for poster presentations – for full details visit the conference website.
The RSS Policy team is currently researching the role of Data Technicians and the associated Level 3 Apprenticeships with a goal to understand barriers to uptake, how well current standards are delivering for industry needs, and identify any areas for improvement. As part of this research they are keen to hear from people with experience doing a Level 3 Data Technician Apprenticeship, or employed as Data Technicians (or in similar roles like Data support analyst, Junior data analyst, Junior information analyst), or that are involved in training, managing, or employing people in these roles. If you’re interested in sharing your views and experiences sign up here
Martin Goodson (CEO and Chief Scientist at Evolution AI) continues to run the excellent London Machine Learning meetup and is very active with events. The next event is on May 3rd when Shikun Liu, PhD student at Imperial College, will present "Vision-Language Reasoning with Multi-Modal Experts". Videos are posted on the meetup youtube channel - and future events will be posted here.
Martin has also compiled a handy list of mastodon handles as the data science and machine learning community migrates away from twitter...
This Month in Data Science
Lots of exciting data science going on, as always!
Ethics and more ethics...
Bias, ethics and diversity continue to be hot topics in data science...
We are seeing increasing frequency of AI “fakes” causing controversy
A German newspaper published an AI generated “interview” with the Formula 1 former champion Michael Schumacher …. and were swiftly sued by the family.
The music world is awash with new ‘fake hits’ from the likes of Drake and The Weeknd
You can’t go too far online without stumbling upon Harry Potter by Balenciaga

And the winner of the Sony World Photography Award 2023 refuses the award after revealing AI creation

"But as Eldagsen pointed out: "Something about this doesn't feel right, does it?" That something, of course, being the fact that it's not a real photograph at all - but a synthetically-produced image."Meanwhile data protection regulators are attempting to “fight back”
The Italian Data Protection Authority banned ChatGPT for violation or data protection laws although OpenAI are now in conversations to try and resolve this
The European Data Protection Board (EDPB) is creating a ChatGPT Task Force “to foster cooperation and to exchange information on possible enforcement actions conducted by data protection authorities”
And some experts are clear that data protection regulations may have been broken in the assembly of the training data for the underlying models
But it also seems clear that data protection and intellectual property will have to evolve to the new challenges faced with generative AI models. Also research here: “Foundation Models and Fair Use”
And it’s tough to regulate what you don’t really understand…
"There is no simple way to solve the alignment problem. But alignment will be impossible without robust institutions for disclosure and auditing. If we want prosocial outcomes, we need to design and report on the metrics that explicitly aim for those outcomes and measure the extent to which they have been achieved. That is a crucial first step, and we should take it immediately. These systems are still very much under human control. For now, at least, they do what they are told, and when the results don’t match expectations, their training is quickly improved. What we need to know is what they are being told."Meanwhile outside of regulatory affairs, corporate challenges could put a bump in the development road for AI providers through limiting access to key data:
“UMG is concerned with how AI companies might be using music from the label’s roster of artists to train their bots to create music. As a result, UMG has asked streaming services like Spotify and Apple Music to block AI’s access to those platforms“Although OpenAI is keen to reassure everyone that they are taking safety very seriously, there are increasing concerns that the leading players (like Google and Microsoft) are choosing speed over caution
"The surprising success of ChatGPT has led to a willingness at Microsoft and Google to take greater risks with their ethical guidelines set up over the years to ensure their technology does not cause societal problems, according to 15 current and former employees and internal documents from the companies."And this has lead to an open call for a six month pause on Large Language Model research.
"Therefore, we call on all AI labs to immediately pause for at least 6 months the training of AI systems more powerful than GPT-4. This pause should be public and verifiable, and include all key actors. If such a pause cannot be enacted quickly, governments should step in and institute a moratorium.
AI labs and independent experts should use this pause to jointly develop and implement a set of shared safety protocols for advanced AI design and development that are rigorously audited and overseen by independent outside experts. These protocols should ensure that systems adhering to them are safe beyond a reasonable doubt.[4] This does not mean a pause on AI development in general, merely a stepping back from the dangerous race to ever-larger unpredictable black-box models with emergent capabilities."However, support for this approach is mixed:
Although Eliezer Yudkowsky believes this approach does not go far enough
Industry luminaries Yann LeCun, Emad Mostaque and Andrew Ng are all against it

But either way it is great to see more development of methods to evaluate the accuracy of the underlying models, an increasingly complex task: research from Stanford University: “Language Models are Changing AI: The Need for Holistic Evaluation”

Developments in Data Science Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
As with last month, attempting to kick things off with the increasingly rare, non-LLM related research out there!
One of my favourite topics… Double Descent Demystified: Identifying, Interpreting & Ablating the Sources of a Deep Learning Puzzle - “This drop in test error flies against classical learning theory on overfitting and has arguably underpinned the success of large models in machine learning”. As an aside, apparently double decent is also a human phenomenon!
And another favourite… Why do tree-based models still outperform deep learning on typical tabular data?
I was recently struggling with some partial differential equations… so this sounds great! - Machine Learning for Partial Differential Equations
More efficient transfer learning - very useful: Conditional Adapters: Parameter-efficient Transfer Learning with Fast Inference
Novel approach using self supervised learning for computer vision from Facebook/Meta
And hot off the press - a must read - all you ever needed to know about self-supervised learning from Lecun and friends…
It was a popular month for ‘segmenting’ things….
UniverSeg: Universal Medical Image Segmentation - “a method for solving unseen medical segmentation tasks without additional training”
Segment Anything from Facebook…”Working toward the first foundation model for image segmentation”
SegGPT: Segmenting Everything In Context - “generalist model for segmenting everything in context“
And then, upping the ante, Segment Everything Everywhere All at Once
Always fun to hear about robots…
Google leading the charge here with Robotic deep RL at scale: Sorting waste and recyclables with a fleet of robots
Amazon Science has good pedigree in this space as well - and they have recently released the largest dataset for training "pick and place" robots
And of course the holy grail... playing football: DribbleBot: Dynamic Legged Manipulation in the Wild
Of course Large Language Models are never far away these days… “Tool Learning with Foundation Models” … and here’s some handy prompts for ChatGPT to manipulate robots!
"This paradigm, i.e., tool learning with foundation models, combines the strengths of specialized tools and foundation models to achieve enhanced accuracy, efficiency, and automation in problem-solving. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors in this field"And so… back to where the most excitement lies at the moment, LLMs and Generative AI - first off, a useful primer, well worth a quick read: Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond (also some useful timelines and tracking of developments)
Some really interesting research into what could simplistically be called “self-learning”: feeding results back into a prompt to improve outputs. To start with a slightly older paper but good background: Large Language Models Are Human-Level Prompt Engineers (also see here for useful additional resources)
Teaching Large Language Models to Self-Debug: “we propose Self-Debugging, which teaches a large language model to debug its predicted program via few-shot demonstrations”
Training Language Models with Language Feedback at Scale: “In this paper, we introduce Imitation learning from Language Feedback (ILF), a new approach that utilizes more informative language feedback“
Self-Refine: Iterative Refinement with Self-Feedback: this is pretty elegant.. “The main idea is to generate an output using an LLM, then allow the same model to provide multi-aspect feedback for its own output“
Finally Automatic Chain of Thought Prompting in Large Language Models - feels pretty groundbreaking…
"Large Language Models (LLMs) can carry out complex reasoning tasks by generating intermediate reasoning steps. These steps are triggered by what is called chain-of-thought (CoT) prompting, which comes in two flavors: one leverages a simple prompt like "Let’s think step by step" to facilitate step-by-step reasoning before answering a question (Zero-Shot-CoT). The other uses manual demonstrations, each composed of a question and a reasoning chain that leads to an answer (Manual-CoT). Unfortunately, the superior performance of the latter strategy crucially hinges on manually generating task-specific demonstrations. This makes it far less scalable and more dependent on the talent of the CoT engineer. We show that such manual efforts may be eliminated by leveraging LLMs to generate the reasoning chains on its own"This is a great (and accessible) read - From Deep to Long Learning?. A lot of the progress with ChatGPT4 has come from the increased input token length that the model can track over (almost 50 pages of text now). But that comes at a serious computational cost, so exploring less computational expensive ways of expanding the input context makes a lot of sense.
Are we seeing the birth of “InsertYourNameHere”GPT?
BloombergGPT: A Large Language Model for Finance - “a 50 billion parameter language model that is trained on a wide range of financial data“
ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge; additional thoughts in this paper in Nature; and some impressive results from simply using ChatGPT (published in JAMA)
Koala: A Dialogue Model for Academic Research - ChatGPT for academia - check out the demo here
"We fine-tune a LLaMA base model on dialogue data scraped from the web and public datasets, which includes high-quality responses to user queries from other large language models, as well as question answering datasets and human feedback datasets. The resulting model, Koala-13B, shows competitive performance to existing models as suggested by our human evaluation on real-world user prompts
Our results suggest that learning from high-quality datasets can mitigate some of the shortcomings of smaller models, maybe even matching the capabilities of large closed-source models in the future. This might imply, for example, that the community should put more effort into curating high-quality datasets, as this might do more to enable safer, more factual, and more capable models than simply increasing the size of existing systems."Always worth checking out what Yann LeCun is up to… “Do large language models need sensory grounding for meaning and understanding? Spoiler: YES!“
And speaking of OGs… this is very cool from Andrew Ng’s team at Landing.ai - Visual Prompting

More really interesting work looking at interactions between LLMs/agents: “Surprising things happen when you put 25 AI agents together in an RPG town“ (paper here)
Finally… an economics paper! Generative AI at work: (hat tip Tobias…)
"We study the staggered introduction of a generative AI-based conversational assistant using data from 5,179 customer support agents. Access to the tool increases productivity, as measured by issues resolved per hour, by 14 percent on average, with the greatest impact on novice and low-skilled workers, and minimal impact on experienced and highly skilled workers "Generative AI ... oh my!
Still such a hot topic it feels in need of it's own section, for all things DALLE, IMAGEN, Stable Diffusion, ChatGPT...
Another action packed month…
OpenAI, ChatGPT, GPT4 continue to dominate the news, with the new ChatGPT “plugins” apparently a ‘game changer, like Apple’s App Store’
But there’s no getting away from the amazing functionality this brings: like the ChatGPT Retrieval Plugin, and my favourite- ChatGPT Gets Its “Wolfram Superpowers”
And GPT4 continues to impress, this time scoring 83% on Neurosurgery Oral Boards Preparation Question Bank (compared to Google Bard’s 44%)
Google seems to be concerned … merging the Google Brain and DeepMind teams
And Amazon is definitely playing catch-up without a competitive offering of their own at this point
Even the UK Government wants in… although budget might not be quite there: That's cute. UK.gov gathers up £100M for AI super-models
In parallel, lots of progress on the open source side of the equation both in terms of scale and speed…
Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality from UC Berkeley
Cerebras-GPT: A Family of Open, Compute-efficient, Large Language Models
Hugging Face launches open-source version of ChatGPT in bid to challenge dominance of closed-source models; also GPT4All
Can Small Language Models Give High Performance? Meet StableLM
And you can now run these efficient models in the browser (also webGPT)!
Plenty of commercial applications springing up based on the underlying capabilities, from design to storytelling to app development
And we are still learning about the art of prompting - great thread here showing how small changes can make big differences, and this is essential reading: an advanced guide to prompting from Microsoft
Lots of discussion on the positive effects in software development
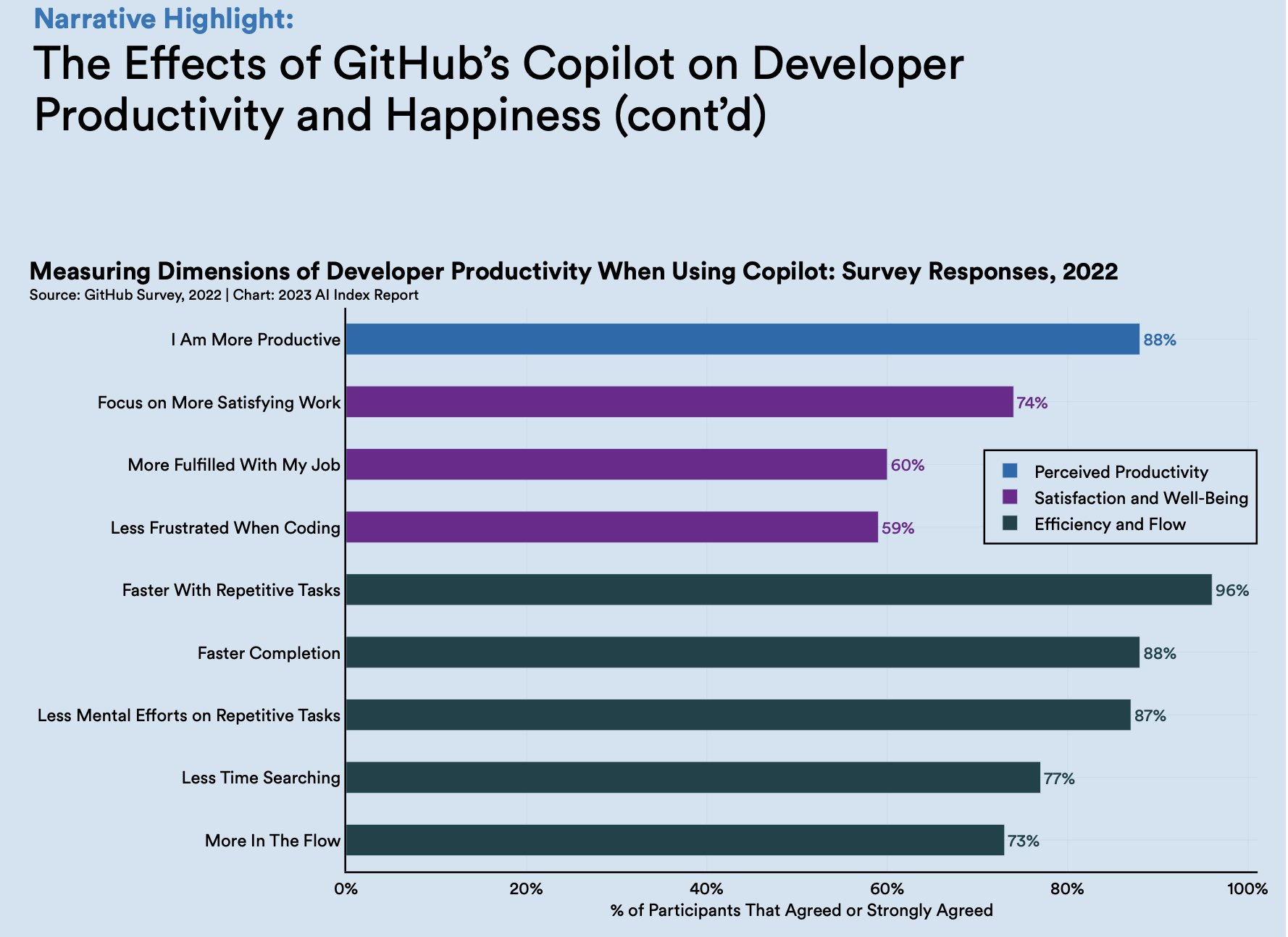
The Effects of GitHub’s Copilot on Developer Productivity and Happiness
Devs love it. We will all love our personal copilots

AI-enhanced development makes me more ambitious with my projects
Will remote software engineering interviews ever be the same again… “Cheetah is an AI-powered macOS app designed to assist users during remote software engineering interviews by providing real-time, discreet coaching and live coding platform integration.”
And a couple of bigger picture thoughts on what this means for programming and for software development as well as Sequoia Capital’s take- Developer Tools 2.0
But the most excitement this month centred on ‘AutoGPT’- the idea (and realisation) of multiple GPT Agents working together on an overall goal…


The prominent implementations so far are AutoGPT and BabyGPT (with Teenage AGI following on)
They are definitely far from perfect right now but even so, there are some startling use cases:
Impressive list of examples here
“Today I used GPT-4 to make "Wolverine" - it gives your python scripts regenerative healing abilities! Run your scripts with it and when they crash, GPT-4 edits them and explains what went wrong. Even if you have many bugs it'll repeatedly rerun until everything is fixed”
“I decided to outsource my entire personal financial life to GPT-4. I gave AutoGPT access to my bank, financial statements, credit report, and email.
Here’s how it’s going so far (+$217.85)“
“Jarvis is now reality. My GPT-4 coding assistant can now build & deploy brand new web apps! It initializes my project, builds my app, creates a GitHub repo, and deploys it to Vercel. All from simply using my voice.”




Real world applications of Data Science
Lots of practical examples making a difference in the real world this month!
Starting off with some useful context- Stanford’s 2023 AI Index report
Machine Learning helping drive pure science … Simulations with a machine learning model predict a new phase of solid hydrogen
Still lots of positive news in the application of AI in healthcare: Speeding up drug discovery with diffusion generative models - really elegant use of a new approach to help solve an incredibly important problem.
In previous deep-learning solutions, molecular docking is treated as a regression problem. In other words, “it assumes that you have a single target that you’re trying to optimize for and there’s a single right answer,” says Gabriele Corso, co-author and second-year MIT PhD student in electrical engineering and computer science who is an affiliate of the MIT Computer Sciences and Artificial Intelligence Laboratory (CSAIL). “With generative modeling, you assume that there is a distribution of possible answers — this is critical in the presence of uncertainty.”In both use cases above, we used an “expert-in-the-loop” approach that incorporates human expertise into the text generation and evaluation process. It combines the efficiency and scalability of algorithmic solutions with the quality and expertise of human experts. The result is a solution that not only delivers high-quality content but also continuously improves with each iteration.
Finally, really interesting 15min video from The Museum of Modern Art in New York - AI Art: How artists are using and confronting machine learning | HOW TO SEE LIKE A MACHINE
How does that work?
Tutorials and deep dives on different approaches and techniques
Kicking off with a few non-LLM related topics!
Time-Series Forecasting: Deep Learning vs Statistics — Who Wins? - clear and comprehensive assessment
PyMC Marketing - new library for bayesian marketing mix modelling - good tutorial
An Introduction to a Powerful Optimization Technique: Simulated Annealing
Always good to have a little bit of stats … equality of odds: as applied to measuring bias in machine learning
It wouldn’t be our “how does that work” section with something on Transformers…
Transformers from Scratch - comprehensive and accessible, well worth a look
Graph classification with Transformers - another excellent guide from Hugging Face
So, you really want to train your own Large Language Model? ok…
This is excellent and well worth a read: talking through step by step what you would need to do and why- How to run your own LLM (GPT)
Useful guide from Weights and Biases : A Recipe for Training Large Models
"When needing an AI model, you should always start by seeing if there is already an existing one that satisfies your needs and aim for the smallest possible model (lower inference cost, more portability, etc). However, in some instances, you will need to train your own model from scratch"Another great tutorial from Hugging Face, this time of RLHL - StackLLaMA: A hands-on guide to train LLaMA with RLHF
And then there is Fine Tuning…
This is great, and very relevant: Building an LLM open source search engine in 100 lines using LangChain and Ray

Some really interesting applications of using LLMs for data science applications both definitely worth checking out
And LangChain continues to be at the forefront- great post on AutoGPT and Agents as well as new functionality

"A question that I’ve been asked a lot recently is how large language models (LLMs) will change machine learning workflows. After working with several companies who are working with LLM applications and personally going down a rabbit hole building my applications, I realized two things:
It’s easy to make something cool with LLMs, but very hard to make something production-ready with them.
LLM limitations are exacerbated by a lack of engineering rigor in prompt engineering, partially due to the ambiguous nature of natural languages, and partially due to the nascent nature of the field."Practical tips
How to drive analytics and ML into production
As is generally the case, lots of commentary about MLOps
Perhaps controversial but worth a read - MLOps is Mostly Data Engineering
Useful explanation for those not familiar - Build Reliable Machine Learning Pipelines with Continuous Integration
Sagemaker has come a long way it looks like - Kubeflow pipelines and SageMaker ML workflow
Interesting idea: make Git your model registry - The open-source tool to simplify your ML model deployments
I’ve always been a fan of MLFlow - useful tutorial
This looks worth checking out for autoML and hyper parameter optimisation- FLAML: A Fast Library for Automated Machine Learning & Tuning, open source from Microsoft
Some useful pointers on using dbt with airflow

Finally some great advice from the excellent Hilary Mason:



Bigger picture ideas
Longer thought provoking reads - lean back and pour a drink! ... Some excellent commentary this month!
Try and find the time to watch this 45min lecture… pretty mindblowing… Sparks of AGI: early experiments with GPT-4
Following on from the ‘AutoGPT’ theme in the genAI section above… Agentized LLMs will change the alignment landscape
"Important parts of alignment and interpretability might be a lot easier than most of us have been thinking. These agents take goals as input, in English. They reason about those goals much as humans do, and this will likely improve with model improvements”“More broadly, integrating human feedback into LLMs means making policy decisions. Whose feedback matters? Who decides who matters? Is RLHF embedding points of view into AI systems? Isn’t human feedback inherently subjective, anyway? How should the outsourced labor force underpinning RLHF today be compensated and supported?”“Lowell’s story shows that there are at least two important components to thinking: reasoning and knowledge. Knowledge without reasoning is inert—you can’t do anything with it. But reasoning without knowledge can turn into compelling, confident fabrication.
Interestingly, this dichotomy isn’t limited to human cognition. It’s also a key thing that people fundamentally miss about AI:
Even though our AI models were trained by reading the whole internet, that training mostly enhances their reasoning abilities not how much they know. And so, the performance of today’s AI models is constrained by their lack of knowledge. "Someone was there making illuminated manuscripts when movable type was invented, and they said - correctly - that it sucks and is much less fun. Of course movable type and the printing press would win out and those laborers were the last of their kind, but if we hopped into a time machine and watched them work, would we make fun of them for not getting with the times? Doesn’t that kind of seem wrong? They weren’t wrong to enjoy their craft and mourn its loss.""As an AI "alignment insider" whose current estimate of doom is around 5%, I wrote this post to explain some of my many objections to Yudkowsky's specific arguments. I've split this post into chronologically ordered segments of the podcast in which Yudkowsky makes one or more claims with which I particularly disagree.""Which is most likely to happen?
It’s hard to predict for certain. Future AI models definitely have scope to be built with even larger amounts/types of data and increased compute. If the utility also continues to increase, we will have a few, expensive general AI models used for an enormous tail of diverse, hard-to-define workflows as illustrated in the diagram above — doing for AI what cloud did for compute.""But the impact of AI goes beyond just writing. I believe it's inevitable that AI will transform classrooms. It obviously takes on some of the role of instructors, acting as a fantastic tutor and explainer of concepts (as one student told me, "Why raise your hand in class when you can ask ChatGPT a question?"). But by doing this, AI also has the potential to benefit teachers, students, and education as a whole. To understand why, it's important to see why traditional teaching methods, like lectures, aren't that effective, and why their alternatives haven't taken off as quickly as some educators would like."Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
Watch an A.I. Learn to Write by Reading Nothing but Jane Austin - great visualisation from the NY Times
We visualized the entire PubMed library, 21 million biomedical and life science papers

Play Prompt Golf with GPTWorld: A puzzle to learn about prompting
Whoa… The Bitcoin Whitepaper Is Hidden in Every Modern Copy of macOS
Love this - Creating timelapse animations from satellite imagery timeseries

Covid Corner
The UK Government is no longer tracking Covid… so I guess it’s time to retire Covid Corner (despite 1 in 40 people still having it as of March 24..)
Updates from Members and Contributors
Shirley Coleman, Technical Director at Newcastle University, is chairing an upcoming session about quality improvement issues in AI, to be held on 22nd May
Sam Young, Practice Manager (Data Science & AI) at Catapult, highlights an interesting new report on applying reinforcement learning in the energy sector
Finally, the Data Science Campus of the ONS is busy as always!
First of all there are more ESSnet Web Intelligence Network (WIN) project seminars coming up: Web data in official statistics: process, challenges, solutions – the case of online real estate offers, 16 May 2023, 14:00 (GMT+2). Book here
The Data Science Graduate Programme is recruiting for the 2023-2024 cohort (deadline 9 May - applications and information here)
All public sector employees with an interest in data science are invited to attend the ONS data campus community events in May: Data Ethics in Government on May 11th and Meet the Data Scientists on May 24th
Jobs!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
“At Muzz, we are hiring Product Data Scientists to join my Data Science team at the largest Muslim dating app and help us connect 2 billion muslims around the world. We are looking for ambitious and product-focused data scientists/analysts/engineers to help us understand our members and all the metrics that matter. Feel free to contact ryan.jessop@muzz.com for more information and set up an intro call.”
This looks exciting - C3.ai are hiring Data Scientists and Senior Data Scientists to start ASAP in the London office- check here for more details
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS