
May Newsletter
Industrial Strength Data Science and AI

Hi everyone-
Another month flies by and as always lots going on in the world of AI and Data Science… With the bank holiday weekend ahead, I really encourage you to read on, but some edited highlights if you are short for time!
What does AI regulation really mean? Thought provoking piece from Benedict Evans drawing parallels to the UK Post Office scandal,
Open source has had quite a month… Llama3 was released, breaking all sorts of records (and check out loads more open source developments below)
Apparently, AI models are already as persuasive as humans…
A sign of things to come? Startup uses AI to edit human DNA
Following is the May edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
We are continuing our work with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is accepting applications for the Advanced Data Science Professional certification as well as the new Data Science Professional certification.
In fact we’re delighted to announce that the Alliance for Data Science Professionals (AfDSP), of which the RSS is a founding member, is a finalist in the 2024 British Data Awards- huge congratulations to Rachel Hilliam and the team.
Giles Pavey, Global Director Data Science at Unilever, was interviewed for the Gartner D-Suite Podcast about how Unilever are assuring responsible use of AI- well worth a listen
Piers Stobbs, VP Data and Science at Deliveroo, was on a panel discussion at the Maths Summit, exploring the role of the mathematics and data science, in solving challenges and creating opportunities in the 21st century.
Martin Goodson, CEO and Chief Scientist at Evolution AI, continues to run the excellent London Machine Learning meetup and is very active with events. The last event was on March 27th, when Meng Fang, Assistant Professor in AI at the University of Liverpool, presented "Large Language Models Are Neurosymbolic Reasoners”. Videos are posted on the meetup youtube channel - and future events will be posted here.
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
Sadly more and more examples of AI applications misbehaving or being used for questionable purposes:
Apparently the Israeli military may gave been using features from Google Photos to identify Palestinian targets in Gaza
"The program relies on two different facial recognition tools, according to the New York Times: one made by the Israeli contractor Corsight, and the other built into the popular consumer image organization platform offered through Google Photos. An anonymous Israeli official told the Times that Google Photos worked better than any of the alternative facial recognition tech, helping the Israelis make a “hit list” of alleged Hamas fighters who participated in the October 7 attack."US Air Force confirms first successful AI dogfight
AI seems increasingly capable of exploiting security flaws in systems:
OpenAI's GPT-4 can exploit real vulnerabilities by reading security advisories
In a newly released paper, four University of Illinois Urbana-Champaign (UIUC) computer scientists – Richard Fang, Rohan Bindu, Akul Gupta, and Daniel Kang – report that OpenAI's GPT-4 large language model (LLM) can autonomously exploit vulnerabilities in real-world systems if given a CVE advisory describing the flaw. "Also, if you extrapolate to what GPT-5 and future models can do, it seems likely that they will be much more capable than what script kiddies can get access to today," he said.AI hallucinates software packages and devs download them – even if potentially poisoned with malware
"Several big businesses have published source code that incorporates a software package previously hallucinated by generative AI. Not only that but someone, having spotted this reoccurring hallucination, had turned that made-up dependency into a real one, which was subsequently downloaded and installed thousands of times by developers as a result of the AI's bad advice, we've learned. If the package was laced with actual malware, rather than being a benign test, the results could have been disastrous."
NYC AI Chatbot Touted by Adams Tells Businesses to Break the Law
"Five months after launch, it’s clear that while the bot appears authoritative, the information it provides on housing policy, worker rights, and rules for entrepreneurs is often incomplete and in worst-case scenarios “dangerously inaccurate,” as one local housing policy expert told The Markup."
Meanwhile, the race for better and better performance is driving a need for more and more data…
How Tech Giants Cut Corners to Harvest Data for A.I.
"OpenAI, Google and Meta ignored corporate policies, altered their own rules and discussed skirting copyright law as they sought online information to train their newest artificial intelligence systems."OpenAI transcribed over a million hours of YouTube videos to train GPT-4. Of course Google is in a awkward position here since no doubt they have used YouTube transcripts in their model training!
"The story opens on OpenAI which, desperate for training data, reportedly developed its Whisper audio transcription model to get over the hump, transcribing over a million hours of YouTube videos to train GPT-4, its most advanced large language model.
Some attempts from the big players to better understand the threats and build in safeguards…
Microsoft Research digging into ‘jailbreaking’
"One of the challenges of developing ethical LLMs is to define and enforce a clear boundary between acceptable and unacceptable topics of conversation. For example, an LLM might be trained to avoid engaging in discussions about violence, hate speech, or illegal activities. However, this does not mean that the LLM is incapable of generating such content, as it might have learned relevant words and phrases from its large-scale training data. Rather, the LLM is expected to refuse or deflect any attempts by the user to steer the conversation towards the prohibited topics. This creates a discrepancy between the LLM's potential and actual behavior, which can be exploited by malicious users who want to elicit unethical responses from the LLM through what are known as jailbreak attacks."Anthropic also published research on Many-shot jailbreaking
"We investigated a “jailbreaking” technique — a method that can be used to evade the safety guardrails put in place by the developers of large language models (LLMs). The technique, which we call “many-shot jailbreaking”, is effective on Anthropic’s own models, as well as those produced by other AI companies. We briefed other AI developers about this vulnerability in advance, and have implemented mitigations on our systems."Meta expanding their approach to labelling AI generated content
"We are making changes to the way we handle manipulated media based on feedback from the Oversight Board and our policy review process with public opinion surveys and expert consultations. We will begin labeling a wider range of video, audio and image content as “Made with AI” when we detect industry standard AI image indicators or when people disclose that they’re uploading AI-generated content."And apparently OpenAI’s new ‘Voice Engine’ which is able to clone voices, is too dangerous to release right now…
"We believe that any broad deployment of synthetic voice technology should be accompanied by voice authentication experiences that verify that the original speaker is knowingly adding their voice to the service and a no-go voice list that detects and prevents the creation of voices that are too similar to prominent figures."
Another industry attempt to gain commitment for responsible AI development- this time in the life sciences: Community Values, Guiding Principles, and Commitments for the Responsible Development of AI for Protein Design
"As scientists engaged in this work, we believe the benefits of current AI technologies for protein design far outweigh the potential for harm and we would like to ensure our research remains beneficial for all going forward. Given anticipated advances in this field, a new proactive risk management approach may be required to mitigate the potential of developing AI technologies that could be misused, intentionally or otherwise, to cause harm."Governments and regulators worldwide are still struggling with what to do about all this
The Competition Markets Authority (CMA) in the UK is now very worried about the lack of competition in the LLM space - ‘CMA outlines growing concerns in markets for AI Foundation Models’
"The CMA is concerned that some firms may have both the ability and the incentive to shape these markets in their own interests – both to protect existing market power and to extend it into new areas. This could profoundly impact fair, open, and effective competition in FM-related markets, ultimately harming businesses and consumers, for example through reduced choice, lower quality, and higher prices, as well as stunting the flow of potentially unprecedented innovation and wider economic benefits from AI."AI Safety: UK and US sign landmark agreement - but not entirely clear what it will actually attempt to do…
""AI, like chemical science, nuclear science, and biological science, can be weaponised and used for good or ill," Prof Sir Nigel Shadbolt told the BBC's Today programme. But the University of Oxford professor said fears around AI's existential risk "are sometimes a bit overblown". "We've got to be really supportive and appreciative of efforts to get great AI powers thinking about and researching what the dangers are," he said."Great to see Imperial College London leaning into AI applications: New AI startup accelerator led by Imperial opens for applications
"“Bringing together leading experts from industry and academia, the AI SuperConnector curriculum combines entrepreneurship fundamentals with AI capabilities to equip participants with the skills, knowledge, and connections they need to develop robust, ethical, and impactful AI ventures,” says Hiten Thakrar, who heads the initiative. "Meanwhile the Canadian government is going full throttle into developing their own AI
"Investing $2 billion to build and provide access to computing capabilities and technological infrastructure for Canada’s world-leading AI researchers, start-ups, and scale-ups. "
Finally, an interesting take from Benedict Evans on AI regulation, with a parallel made to the recent Post Office scandal in the UK- well worth a read
"I think about this case every time I hear about AI Ethics and every time people talk about regulating AI. Fujitsu was not building machine learning or LLMs - this was 1970s technology. But we don’t look at this scandal and say that we need Database Ethics, or that the solution is a SQL Regulator. This was an institutional failure inside Fujitsu and inside the Post Office, and in a court system failing to test the evidence properly. And, to be clear, the failure was not that there were bugs, but in refusing to acknowledge the bugs. Either way, to take the language that people now use to worry about AI: a computer, running indeterminate software that was hard to diagnose or understand, made ‘decisions’ that ruined people’s lives - it ‘decided’ that money was missing. The staff at the Post Office just went along with those decisions."
Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
With the models getting so big and so costly to train (both in terms of money and energy), efficiency is an active area of research
Towards Greener LLMs: Bringing Energy-Efficiency to the Forefront of LLM Inference
"We show that depending on the inputs, the model, and the service-level agreements, there are several knobs available to the LLM inference provider to use for being energy efficient. We characterize the impact of these knobs on the latency, throughput, as well as the energy. By exploring these trade-offs, we offer valuable insights into optimizing energy usage without compromising on performance, thereby paving the way for sustainable and cost-effective LLM deployment in data center environments."A different take on efficiency- why is it that with models getting bigger/deeper, individual layers of the model seem to be relatively ineffective?: The Unreasonable Ineffectiveness of the Deeper Layers
"From a practical perspective, these results suggest that layer pruning methods can complement other PEFT strategies to further reduce computational resources of finetuning on the one hand, and can improve the memory and latency of inference on the other hand. From a scientific perspective, the robustness of these LLMs to the deletion of layers implies either that current pretraining methods are not properly leveraging the parameters in the deeper layers of the network or that the shallow layers play a critical role in storing knowledge."A new and more efficient way to train from Facebook research: Schedule-Free Learning - A New Way to Train
"As the name suggests, Schedule-free learning does not require a decreasing learning rate schedule, yet typically out-performs, or at worst matches, SOTA schedules such as cosine-decay and linear decay. Only two sequences need to be stored at a time (the third can be computed from the other two on the fly) so this method has the same memory requirements as the base optimizer (parameter buffer + momentum)."
Reinforcement Learning is incredibly powerful in certain settings but can be challenging to practically apply - a new approach to addressing distribution shifts between offline and online data - Oxford might help: Policy-Guided Diffusion (see also here)
"Researchers from Oxford University present policy-guided diffusion (PGD) to address the issue of compounding error in offline RL by modeling entire trajectories rather than single-step transitions. PGD trains a diffusion model on the offline dataset to generate synthetic trajectories under the behavior policy. To align these trajectories with the target policy, guidance from the target policy is applied to shift the sampling distribution. This results in a behavior-regularized target distribution, reducing divergence from the behavior policy and limiting generalization error. "Infinite context windows anyone? Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
"The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs."A new approach to combining specialist LLMs together, a bit like old school ensemble methods! Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
"After individual experts are asynchronously trained, BTX brings together their feedforward parameters as experts in Mixture-of-Expert (MoE) layers and averages the remaining parameters, followed by an MoE-finetuning stage to learn token-level routing. BTX generalizes two special cases, the Branch-Train-Merge method, which does not have the MoE finetuning stage to learn routing, and sparse upcycling, which omits the stage of training experts asynchronously. Compared to alternative approaches, BTX achieves the best accuracy-efficiency tradeoff."Making ‘Many-shot-learning’ more accessible: Many-Shot In-Context Learning
"Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions."I want to believe that synthetic data can really help in training models, but I’ll be honest, I struggle conceptually. However, this paper, definitely brings it to life
"Synthetic data has emerged as a promising solution by generating artificial data that mimics real-world patterns. This paper provides an overview of synthetic data research, discussing its applications, challenges, and future directions. We present empirical evidence from prior art to demonstrate its effectiveness and highlight the importance of ensuring its factuality, fidelity, and unbiasedness. "Healthcare feels like a very promising application for these LLM models but how can they help? Useful survey paper digging into this: Foundation Model for Advancing Healthcare: Challenges, Opportunities, and Future Directions
"It first conducted a comprehensive overview of the HFM including the methods, data, and applications for a quick grasp of the current progress. Then, it made an in-depth exploration of the challenges present in data, algorithms, and computing infrastructures for constructing and widespread application of foundation models in healthcare. This survey also identifies emerging and promising directions in this field for future development. "And this looks promising- applying CausalML to the problem of predicting treatment outcomes in healthcare (paper here)
Looking forward to trying this out: Google AI Introduces AutoBNN: A New Open-Source Machine Learning Framework for Building Sophisticated Time Series Prediction Models
"GoogleAI researchers released AutoBNN to address the challenge of effectively modeling time series data for forecasting purposes. Traditional Bayesian approaches like Gaussian processes (GPs) and structural time series could not overcome limitations in scalability, interpretability, and computational efficiency. The neural network-based approaches lack interpretability and may not provide reliable uncertainty estimates. These issues create a need for a method that combines the interpretability of traditional approaches with the scalability and flexibility of neural networks."Finally some good research from the leading players on safety and alignment:
Update on mechanistic interpretability research from the Google Deep Mind team- constructing Steering Vectors from Sparse Auto Encoder features looks to be promising
Measuring the Persuasiveness of Language Models
"Within each class of models (compact and frontier), we find a clear scaling trend across model generations: each successive model generation is rated to be more persuasive than the previous. We also find that our latest and most capable model, Claude 3 Opus, produces arguments that don't statistically differ in their persuasiveness compared to arguments written by humans"

Generative AI ... oh my!
Still moving at such a fast pace it feels in need of it's own section, for developments in the wild world of large language models...
Even for the world of GenAI, this felt like a particularly impressive month of developments.. Suffice to say OpenAI is not the undisputed king anymore… at least until GPT-5 arrives!
OpenAI released a bunch of new enterprise features, including a new “Assistants API”, a new memory feature for ChatGPT plus users, as well as expanded support for enterprise customers to fine tune models (“Custom Models”), and announced an expansion into Japan (“introducing OpenAI Japan”)- not exactly standing still!
"As a first step in our long-term commitment to the region, we’re providing local businesses with early access to a GPT-4 custom model specifically optimized for the Japanese language. This custom model offers improved performance in translating and summarizing Japanese text, is cost effective, and operates up to 3x faster than its predecessor.”Google’s Gemini Pro 1.5 (complete with its’ 1m token context window!) became available in public preview, with some impressive results, while they also announced a new Vertex AI Agent Builder, to speed up agent development, as well as expanding their Gemma range of lightweight open source models (including CodeGemma for coding assistants and RecurrentGemma for faster batch inference).
"Because Gemini 1.5 Pro is multilingual — and multimodal in the sense that it’s able to understand images and videos and, as of Tuesday, audio streams in addition to text — the model can also analyze and compare content in media like TV shows, movies, radio broadcasts, conference call recordings and more across different languages. One million tokens translates to about an hour of video or around 11 hours of audio."Amazon has been scrambling to keep up in the GenAI race, but the savvy appointment of friend of the newsletter Andrew Ng to their Board of Directors looks well timed.
Anthropic’s models are increasingly close to GPT-4 across a number of dimensions- e.g. tool use (calling external functions) and they have a useful tool use library now available
And speaking of outperforming GPT-4…
Grok-1.5 (Elon Musk’s new foray into LLMs) was released with a chunky 128,000 token context window and and GPT-4 like performance
A major new model from SenseTime in China that looks very impressive

Apple claims their new LLM outperforms GPT-4 on ‘some tasks’(indeed Apple seem to be increasingly focused on developing their own on-device AI capabilities, with a new acquisition)
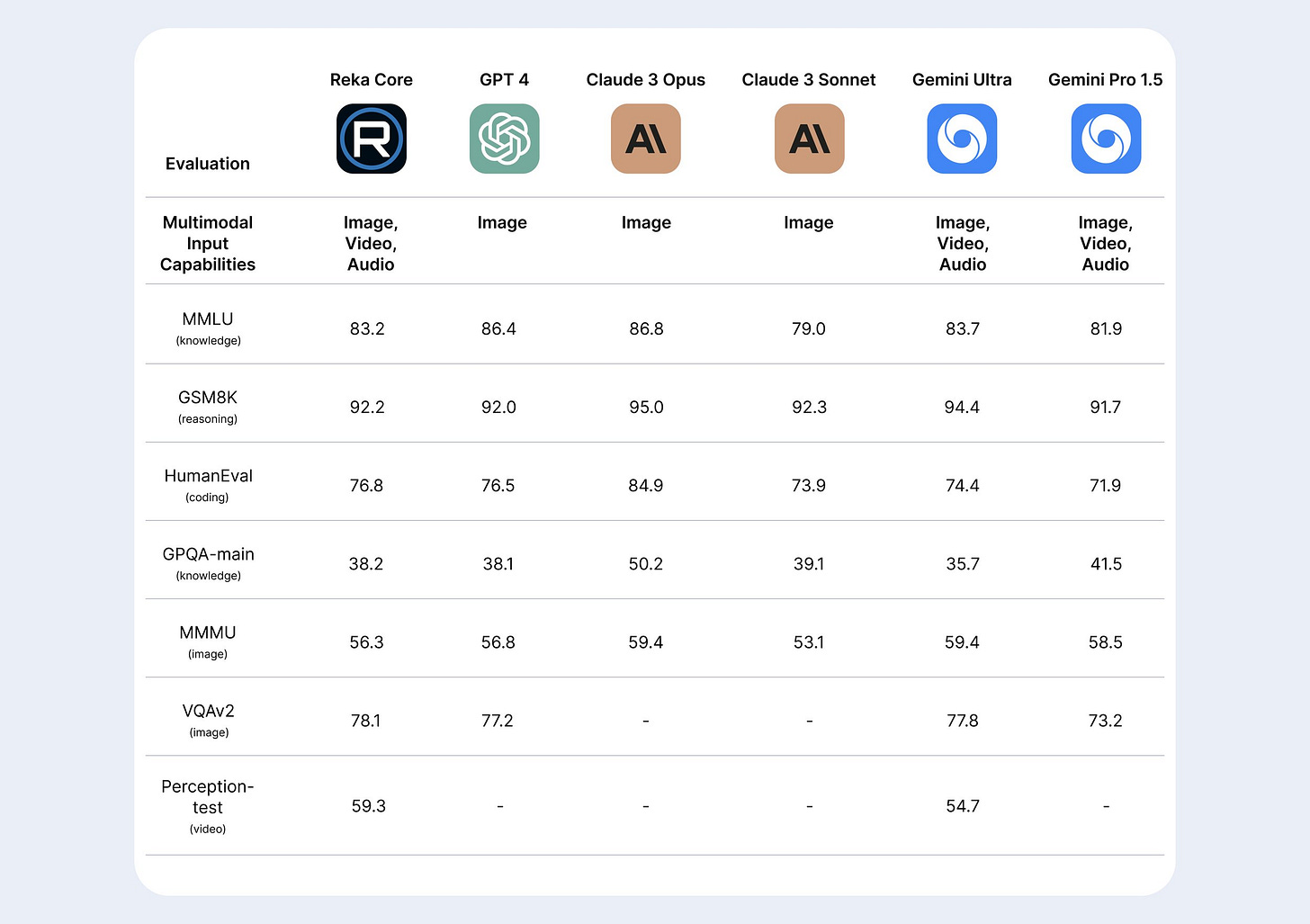
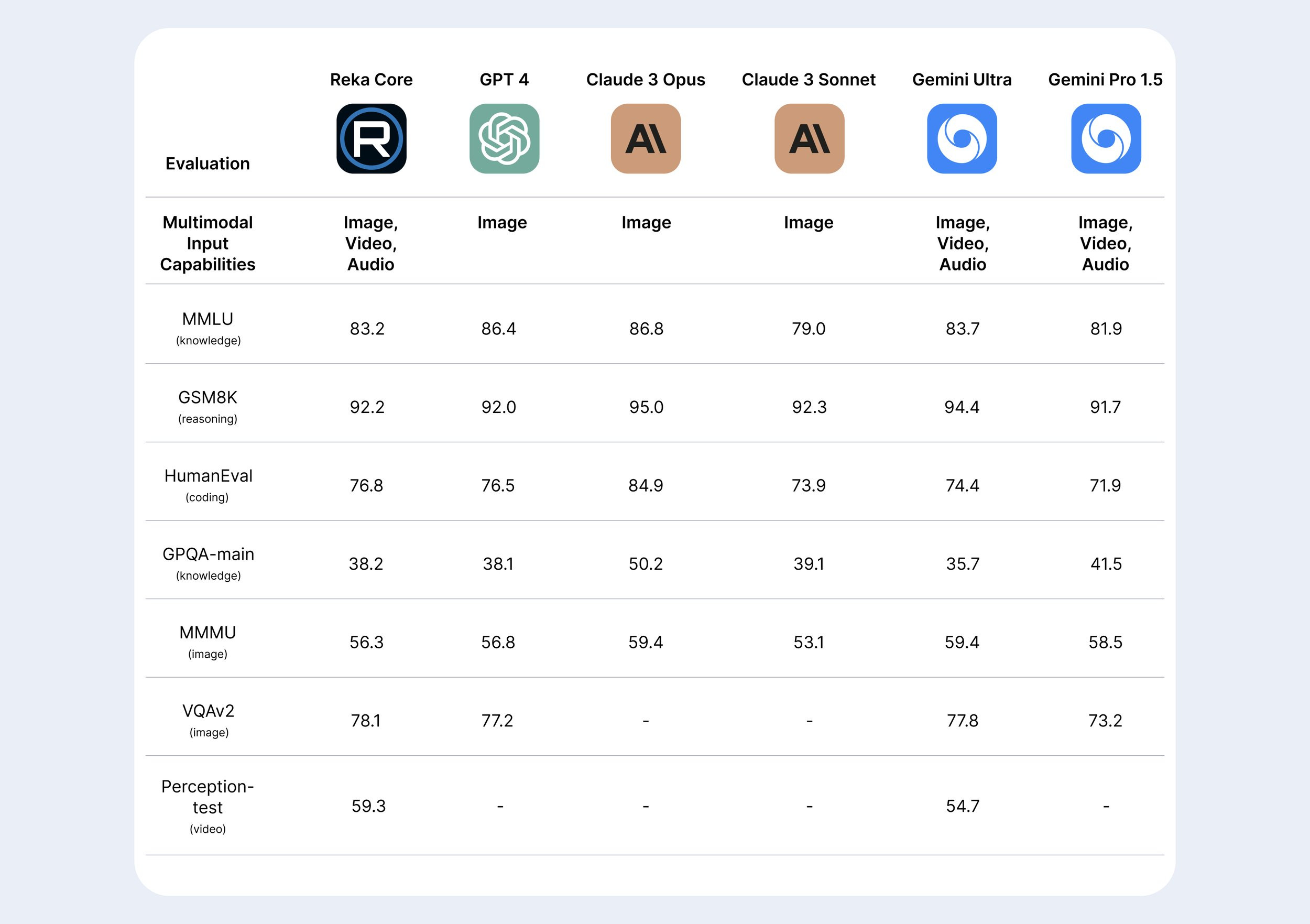
And new kid on the block Reka released a very impressive new model
But the standout updates from the month were in the world of open source models. It is clear that the gap between closed and open source models is closing and the volume of open source developers is increasing
First of all Meta:
The biggest news was Meta’s release of Llama3- clearly the most capable open source model yet. Indeed the largest Llama3 models have not finished training yet, but the early results are pretty astonishing for an open source model. Good summary here
Interestingly, the release was accompanied with collaborative partner posts about cheap and performant deployment- “Meta AI Llama 3 With Groq Outperforms Private Models on Speed/Price/Quality Dimensions?”; “Together AI partners with Meta to release Meta Llama 3 for inference and fine-tuning”
Meta also showed further commitment to the open source community with another pytorch release, this time for fine-tuning with torchtune (with or course cookbooks for fine tuning Llama3)
It didnt take long for jailbreaking Llama 3 to happen…
But loads of additional open source news!
AI21labs released Jamba, the first Mamba-based LLM- an approach that shows great promise for efficiency over straight transformers
Snowflake released Arctic, (together with some good cookbooks) specifically designed for Enterprise AI (and fully open)- focused on SQL generation and RAG applications with impressive results
And cohere similarly released Command R+ “a scalable LLM built for business”, with a good toolkit for RAG applications
Apple released OpenALEM for on-device inference
While Microsoft released Phi-3, “Redefining what’s possible with SLMs” - awesome how-to-guide here for finetuning Phi-3 on a MacBook Pro!
Microsoft also release VASA-1- “Lifelike Audio-Driven Talking Faces
And Stability.ai released Stable Audio 2.0
No sooner had the impressive ‘Devin’ (the software development agent) been released (see last month), but we have OpenDevin
If you’re looking to get under the hood of all these developments..
First of all, LLaMA now goes faster on CPUs - go Justine!
This is fantastic if ever want to do voice transcription - command line Whisper
And if you want to play around on your local machine, check out moondream: “a tiny vision language model that kicks ass and runs anywhere” (more useful resources at Awesome Local AI)
Definitely try out AgentStudio if you are interested in exploring Agent building

Finally, I find this intriguing - Evolutionary Model Merging (based on the work from sakana.ai in Japan)





Real world applications and how to guides
Lots of applications and tips and tricks this month
Some interesting practical examples of using AI capabilities in the wild
Last month it was suno, this month it’s udio’s turn to blow your mind with AI generated music - have a quick listen!
Meanwhile Spotify launches personalized AI playlists that you can build using prompts
How about video style transfer- amazing!

Need to write wikipedia style documents? Not a problem…
"STORM is a LLM system that writes Wikipedia-like articles from scratch based on Internet search. While the system cannot produce publication-ready articles that often require a significant number of edits, experienced Wikipedia editors have found it helpful in their pre-writing stage."Now you can access the latest multimodal AI through your Ray-Bans…
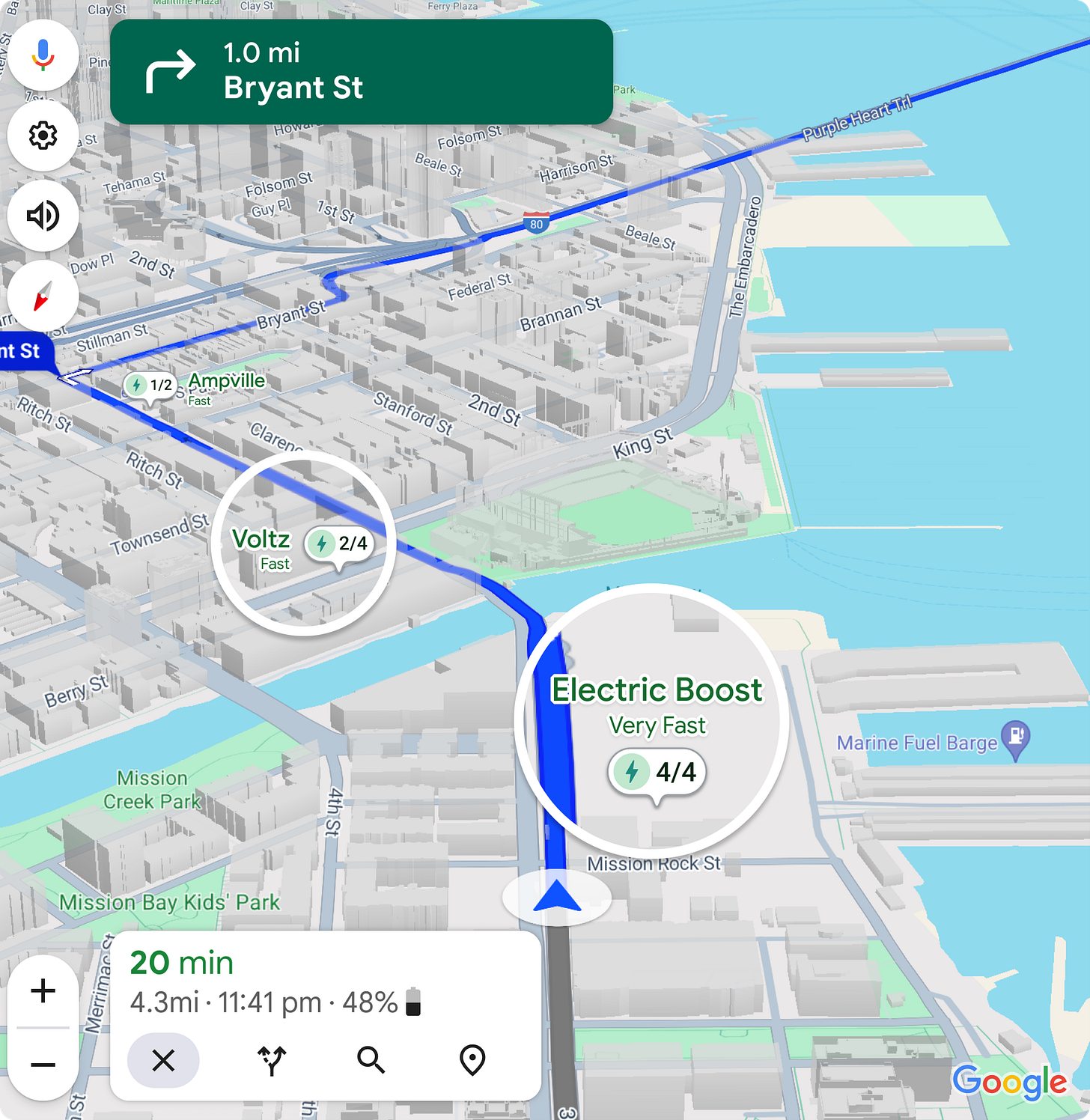
"It can be handy, confidently wrong, and just plain finicky — but smart glasses are a much more comfortable form factor for this tech."Google Maps will use AI to help you find out-of-the-way EV chargers
It’s not all golden though… reviews of the Humane AI Pin are pretty mixed…
"I spoke some simple phrases in Japanese and Korean. Instead of translating, the AI Pin spewed gibberish back at me. I asked my colleague David Pierce, who reviewed the damn thing, if I was doing something wrong. I wasn’t. It just didn’t work."AI+Life Sciences has so much potential but at the same time feels properly scary…
Startup uses AI to edit human DNA
"Profluent also claims to have already used one of these AI-generated gene editors, dubbed OpenCRISPR-1, to edit human DNA. The company says it's the "world’s first open-source, AI-generated gene editor" that was "designed from scratch with AI."A.I. Could Spot Breast Cancer Earlier. Should You Pay for It?
“Clinics around the country are starting to offer patients a new service: having their mammograms read not just by a radiologist, but also by an artificial intelligence model. The hospitals and companies that provide these tools tout their ability to speed the work of radiologists and detect cancer earlier than standard mammograms alone."
Certainly applying AI to language translation is proving very valuable: ChatGP-Twi: how AI could bring African languages online
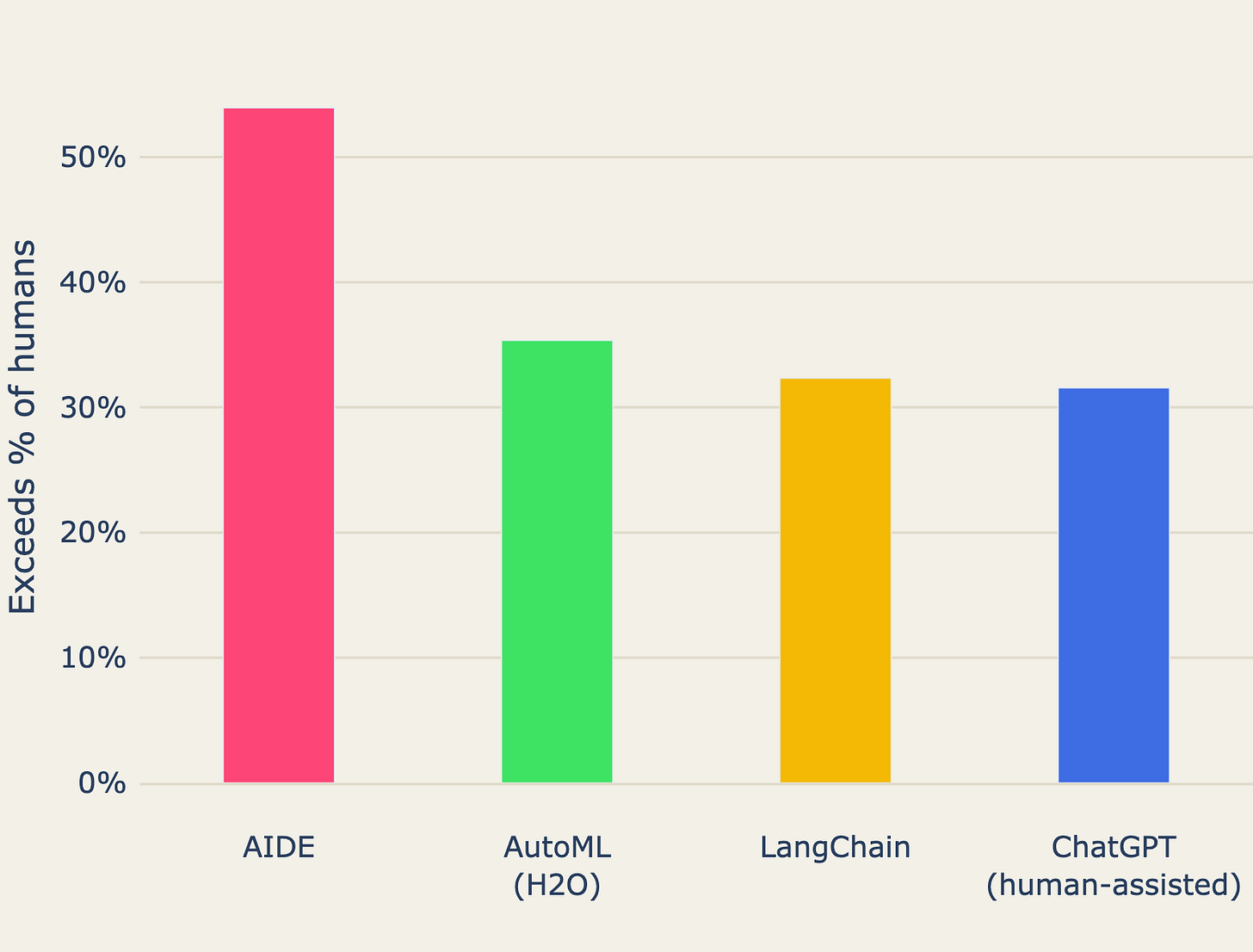
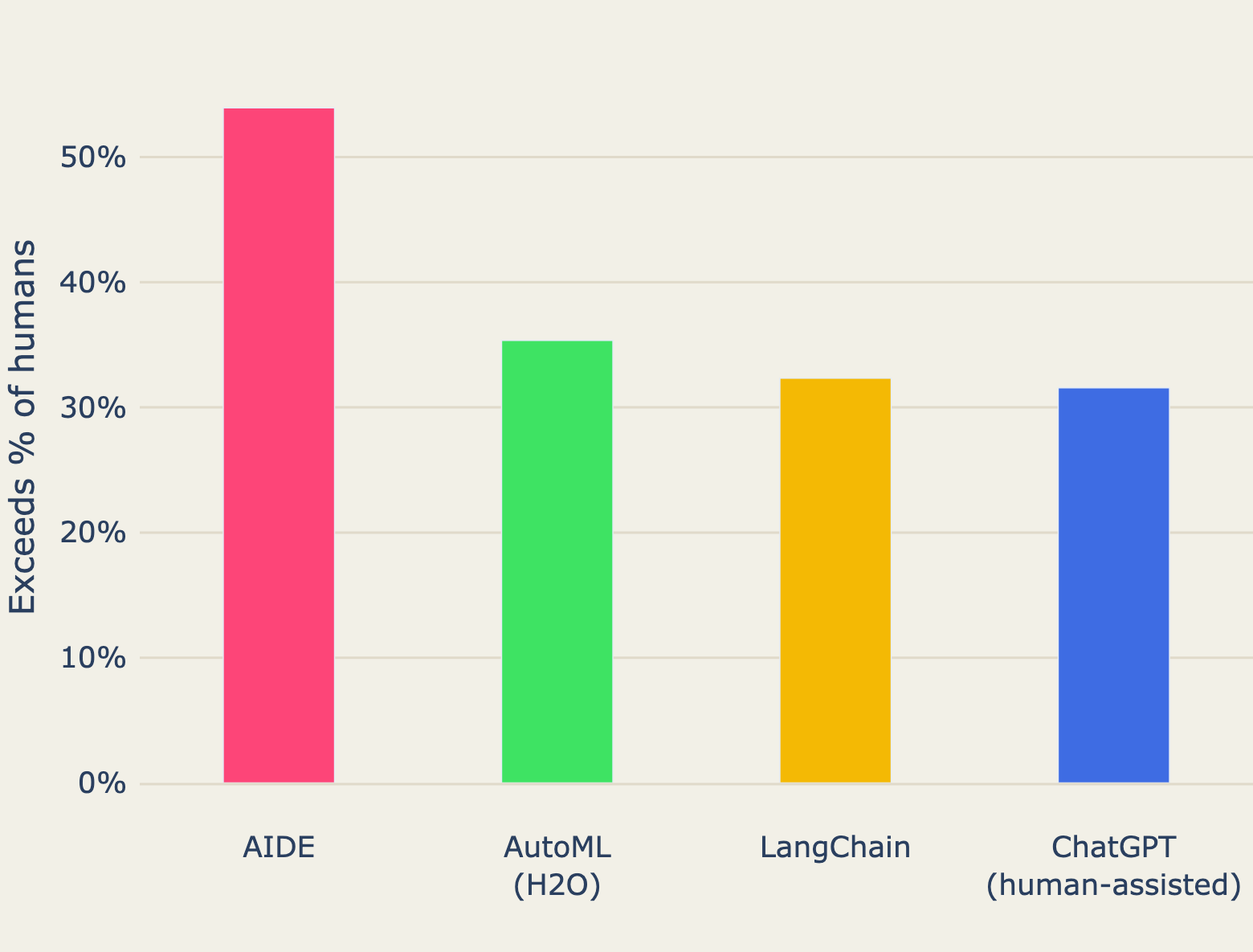
"Outside of the largest public university in Ghana’s Ashanti region, two linguists are wide-eyed. They’re looking at an app they have never heard of perform something they have never seen before: rapid translation of a few lines of Twi spoken into the device. The app, called Khaya, used artificial intelligence to perform the task, and achieved in moments what Google Translate has failed to do in nearly 20 years."Are Data Scientists on the way out?!? AIDE: Human-Level Performance in Data Science Competitions
This certainly seems like a laudable goal if done well: Los Angeles is using AI in a pilot program to try to predict homelessness and allocate aid
Thought provoking and well worth a read- Google’s Deep Mind AI can help engineers predict “catastrophic failure”

Lots of great tutorials and how-to’s this month
Excellent primer: How does ChatGPT work? As explained by the ChatGPT team.
Good tutorial on sentence embeddings
"You keep reading about “embeddings this” and “embeddings that”, but you might still not know exactly what they are. You are not alone! Even if you have a vague idea of what embeddings are, you might use them through a black-box API without really understanding what’s going on under the hood. This is a problem because the current state of open-source embedding models is very strong - they are pretty easy to deploy, small (and hence cheap to host), and outperform many closed-source models."More thought provoking stuff, this time on how we can teach models to think ahead using ‘self-reasoning tokens’
Want to fine-tune Mistral on your own data? Here’s how!
Useful tips and tricks on working with Google Gemini models
Digging into how quantisation works to improve efficiency of these huge models
"Along this journey, we will see that quantization works in harmony with the pruning techniques we encountered previously, as well as with knowledge distillation and parameter-efficient fine-tuning methods which we have yet to explore, providing us a glimpse into the upcoming topics of investigation in the Streamlining Giants series. "Instructor looks like a very useful library for interacting with LLMs- worth a try if you are looking for a LangChain alternative
Similarly DSPy, from Stanford NLP, also looks very interesting: Programming—not prompting—Foundation Models (also Red-Teaming Language Models with DSPy)
Slightly left field but interesting nonetheless: an introduction to flow matching from the University of Cambridge Lachine Learning Group
"Flow matching (FM) is a recent generative modelling paradigm which has rapidly been gaining popularity in the deep probabilistic ML community. Flow matching combines aspects from Continuous Normalising Flows (CNFs) and Diffusion Models (DMs), alleviating key issues both methods have."Finally, another Retrieval Augmented Generation (RAG) approach: RAGFlow
"RAGFlow is an open-source RAG (Retrieval-Augmented Generation) engine based on deep document understanding. It offers a streamlined RAG workflow for businesses of any scale, combining LLM (Large Language Models) to provide truthful question-answering capabilities, backed by well-founded citations from various complex formatted data."


Practical tips
How to drive analytics and ML into production
Observations on MLOps–A Fragmented Mosaic of Mismatched Expectations
"Yet, the marketing message — MLOps tools are a fragmented mess — has such a negative connotation. It may be fragmented. It may be a mess. But, it’s like the mess you’d find in Monet’s studio. It’s a beautiful, flexible mess. From the perspective of the AI/ML staff, the mosaic of options is a necessary component of the development."Some Architecture & Design Principles for MLOps & LLMOps
"Despite all the latest and greatest results, the reality is that fundamental principles are always the most important things to get right. In this post, I'll start picking apart on aspect of these principles."Scaling AI Models Like You Mean It
"Open-source models present an attractive solution, but what's the next hurdle? Unlike using a model endpoint like OpenAI, where the model is a scalable black box behind the API, deploying your own open-source models introduces scaling challenges. It's crucial to ensure that your model scales effectively with production traffic and maintains a seamless experience during traffic spikes."Finally, a fun reddit discussion… ‘how would you process 8 billion files sitting in an S3 bucket?’
Bigger picture ideas
Longer thought provoking reads - lean back and pour a drink! ...
OpenAI’s CEO Says the Age of Giant AI Models Is Already Over - Sam Altman
“I think we're at the end of the era where it's going to be these, like, giant, giant models,” he told an audience at an event held at MIT late last week. “We'll make them better in other ways.”More warnings from Gary Marcus… An unending array of jailbreaking attacks could be the death of LLMs

Looking for AI use-cases - Benedict Evans
"The narrow problem, and perhaps the ‘weak’ problem, is that these models aren’t quite good enough, yet. They will get stuck, quite a lot, in the scenarios I suggested above. Meanwhile, these are probabilistic rather than deterministic systems, so they’re much better for some kinds of task than others. They’re now very good at making things that look right, and for some use-cases this is what you want, but for others, ‘looks right’ is different to ‘right’. Error rates and ‘hallucinations’ are improving all the time, and becoming more manageable, but we don’t know where this will go - this is one of the big scientific arguments around generative AI (and indeed AGI). And whatever you think these models will be in a couple of years, there’s a lot that isn’t there today."AI Agentic Design Patterns - Andrew Ng

Does AI need a “body” to become truly intelligent? - Freethink
"According to this theory, the only way to get an AI to develop true intelligence is to give it a body and the ability to move around and experience the world. Digital-only AIs, in comparison, may be great for narrow tasks, but they’ll always hit an intelligence ceiling."Inside the shadowy global battle to tame the world's most dangerous technology - Politico
"The debate represented a snapshot of a bigger truth. For the past year, a political fight has been raging around the world, mostly in the shadows, over how — and whether — to control AI. This new digital Great Game is a long way from over. Whoever wins will cement their dominance over Western rules for an era-defining technology. Once these rules are set, they will be almost impossible to rewrite."


Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
Want to train your own LLM? Here’s 15 trillion tokens of the finest data the 🌐 web has to offer!
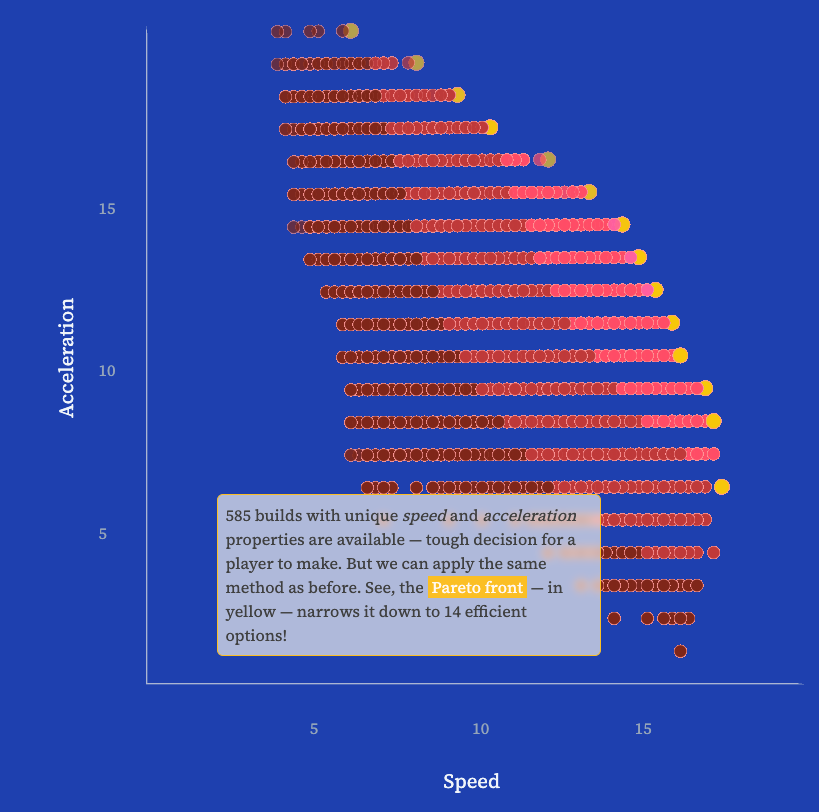
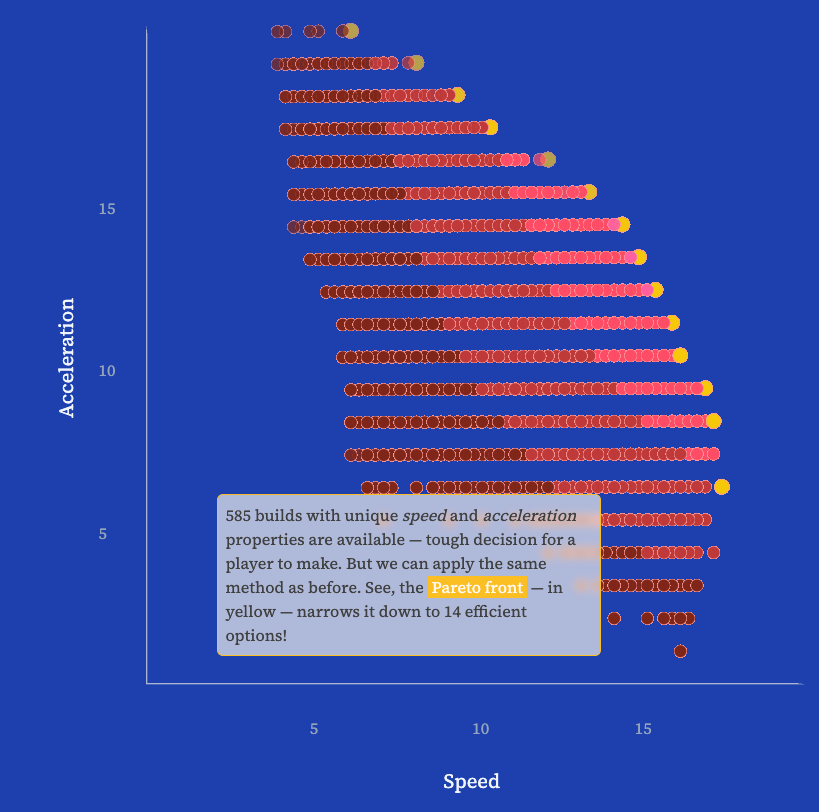
Getting serious about MarioKart: Mario meets Pareto
This is amazing: Voyager 1 transmitting data again after Nasa remotely fixes 46-year-old probe. They initially had no idea what the problem was, no way of interrogating the system, and a one way message took 24 hours!
A fun read: Monument Valley at 10: the story of the most meticulous puzzle game ever created
"It’s 10 years since Monument Valley became the must-have mobile game, with its intensively detailed levels and beautiful aesthetic and sound. We visited ustwo games to to uncover its story and find out what happens next"
{kind=link}
Updates from Members and Contributors
Stephen Haben, from Energy Systems Catapult, draws our attention to the upcoming ADViCE webinar, looking at applying AI to decarbonise manufacturing inputs.
Zoe Turner, Senior Data Scientist at The Strategy Unit, highlights the NHS-R Community, including various upcoming workshops and the live streamed RPYSOC 2024 conference hosted by NHS-R Community with NHS.pycom on 21 and 22 November at the ICC Birmingham. Also all videos are published on YouTube, and contributions are welcome here
Friend of the newsletter, Brian Tarran, now Senior Research and Statistics Editor at the British Film Institute, mentions a new BFI fund of relevance: The British Film Institute (BFI) has launched the BFI National Lottery Innovation Challenge Fund, with a call for “new, transformative and open data” to support the UK video games sector. Up to £250,000 in funding is available to help deliver a “publicly facing platform which surfaces data and insights that are demonstrably useful to the sector, particularly smaller-scale and independent developers”. For further details, see https://www.bfi.org.uk/get-funding-support/bfi-national-lottery-innovation-challenge-fund.
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
2 exciting new machine learning roles at Carbon Re- excellent climate change AI startup
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS