


March Newsletter
Industrial Strength Data Science and AI

Hi everyone-
Well, I don’t know about you, but February was a bit of a blur even with the extra day- we should be used to it now I guess- certainly less confusing than Julius Caesar’s 445 day long 'year of confusion' in 46 B.C… Progress of sorts! Definitely time to lose ourselves in some some thought provoking AI and Data Science reading materials!
Following is the March edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right.
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science, ML and AI practitioners. And if you are not signed up to receive these automatically you can do so here
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
We are continuing our work with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is accepting applications for the Advanced Data Science Professional certification as well as the new Data Science Professional certification.
Some great recent content published by Brian Tarran on our sister blog, Real World Data Science:
£10m for UK regulators to ‘jumpstart’ AI capabilities, as government commits to white paper approach
What is data science? A closer look at science’s latest priority dispute
The line-up of sessions for September’s RSS International Conference has been announced with a strong Data Science & AI component, with topics including Digital Twins, Generative AI, Data Science for Social Good, and the section’s own session asking ‘All Statisticians are Data Scientists?’. There is still time to get yourself on the programme with submissions for individual talks and posters open until 5 April.
Martin Goodson, CEO and Chief Scientist at Evolution AI, continues to run the excellent London Machine Learning meetup and is very active with events. The last event was on Feb 7th, when Yuxiong Wang, Assistant Professor in the Department of Computer Science at the University of Illinois Urbana-Champaign, presented "Bridging Generative & Discriminative Learning in the Open World”. Videos are posted on the meetup youtube channel - and future events will be posted here.
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
It turns out that AI models can’t hold patents according to the US Patent and Trademark Office (and nor can OpenAI register ‘GPT’ as a trademark)
"...clarifying that while AI systems can play a role in the creative process, only natural persons (human beings) who make significant contributions to the conception of an invention can be named as inventors. It also rules out using AI models to churn out patent ideas without significant human input."But they can hack web-sites…
"In this work, we show that LLM agents can autonomously hack websites, performing tasks as complex as blind database schema extraction and SQL injections without human feedback. Importantly, the agent does not need to know the vulnerability beforehand. This capability is uniquely enabled by frontier models that are highly capable of tool use and leveraging extended context. Namely, we show that GPT-4 is capable of such hacks, but existing open-source models are not"And ‘churn out fake-ids’
"In our own tests, OnlyFake created a highly convincing California driver's license, complete with whatever arbitrary name, biographical information, address, expiration date, and signature we wanted.”Oh… and if they mess up on your behalf, you are liable… ‘Air Canada must honor refund policy invented by airline’s chatbot’
Deepfake’s (both audio and video) remain one of most clear and present dangers (I can attest to how simple it is now to create a voice clone with a few lines of code and some samples…)
Hong Kong office loses HK$200 million after scammers stage deepfake video meeting
"Everyone present on the video calls except the victim was a fake representation of real people. The scammers applied deepfake technology to turn publicly available video and other footage into convincing versions of the meeting’s participants."Sadiq Khan says fake AI audio of him nearly led to serious disorder
"The clip used AI - artificial intelligence - to create a replica of Mr Khan's voice saying words scripted by the faker, disparaging Remembrance weekend with an expletive and calling for pro-Palestinian marches, planned for the same day last November, to take precedence."Legal recourse is starting to appear in the US: ‘US outlaws robocalls that use AI-generated voices’
Earlier in the month Taylor Swift was the target of fake images - although some commentary reports that this might drive a backlash: ‘If Anyone Can Stop the Coming AI Hellscape, It’s Taylor Swift‘
Google/DeepMind is hoping to change the narrative and are forming a new organisation focused on AI Safety
"“Our work [at the AI Safety and Alignment organization] aims to enable models to better and more robustly understand human preferences and values,” Dragan told TechCrunch via email, “to know what they don’t know, to work with people to understand their needs and to elicit informed oversight, to be more robust against adversarial attacks and to account for the plurality and dynamic nature of human values and viewpoints.”OpenAI are certainly busy (and vocal) about their efforts to improve safety:
Disrupting malicious uses of AI by state-affiliated threat actors
Building an early warning system for LLM-aided biological threat creation
OpenAI is adding new watermarks to DALL-E 3
"OpenAI’s image generator DALL-E 3 will add watermarks to image metadata as more companies roll out support for standards from the Coalition for Content Provenance and Authenticity (C2PA)."
And Facebook is attempting to do something similar- ‘Labeling AI-Generated Images on Facebook, Instagram and Threads‘
"We’re building industry-leading tools that can identify invisible markers at scale – specifically, the “AI generated” information in the C2PA and IPTC technical standards – so we can label images from Google, OpenAI, Microsoft, Adobe, Midjourney, and Shutterstock as they implement their plans for adding metadata to images created by their tools. "Sadly, it’s not at all clear that these efforts will work… ‘Researchers Tested AI Watermarks—and Broke All of Them’
"Soheil Feizi considers himself an optimistic person. But the University of Maryland computer science professor is blunt when he sums up the current state of watermarking AI images. “We don’t have any reliable watermarking at this point,” he says. “We broke all of them.”But here is a definite positive step - security focused assessment and LLM leaderboard from HuggingFace - interesting the Anthropic’s Claude 2.0 is currently top and GPT4 only 8th…
"Today, we are excited to announce the release of the new LLM Safety Leaderboard, which focuses on safety evaluation for LLMs and is powered by the HF leaderboard template."Maybe, though, we have to be careful what we wish for… ‘Goody-2: The world's most responsible AI model’

One of the original ‘OGs’ is urging governments to invest big on processing power- ‘AI pioneer Yoshua Bengio urges Canada to build $1B public supercomputer’
He'd like to see that class of machine built in Canada, funded by governments, so public entities have the digital firepower to keep up with the private tech giants they'll be tasked with monitoring or regulating. "I think government will need to understand at some point, hopefully as soon as possible, that it's important for [them] to have that muscle," said Bengio.The UK’s House of Lords (Communications and Digital Committee) released their summary ( 95 pages..) of recent hearings on ‘Large language models and generative AI’. Some decent stuff in there though…. Here’s Claude’s summary:
"The text contains recommendations related to the future of large language models (LLMs) in the UK. Key recommendations include: - Foster fair market competition in the LLM industry to allow UK businesses to shape its development. Avoid stifling low-risk open access model providers. - Enhance governance at regulators to mitigate regulatory capture risks. Implement transparency measures for high-profile AI roles in government. - Set out a more positive vision for LLMs. Prioritise funding for responsible innovation. Appoint diverse expertise to advisory bodies. - Explore feasibility of acquiring a sovereign LLM capability designed to high ethical and security standards. - Develop mandatory safety tests and take-down powers for high-risk LLMs. Create accredited standards and auditing practices. - Update copyright law if needed to protect rights of content creators. Resolve copyright disputes over LLM training data through IPO-led process or legislation. - Empower creators to exercise rights over use of data for LLM training. Encourage use of high quality licensed data sources. The recommendations aim to promote responsible LLM innovation in the UK, while mitigating risks and upholding copyright principles. Key priorities are market competition, governance, funding, safety, copyright protections and data rights."And some interesting work from Stanford’s Human Centred AI group on Considerations for Governing Open Foundation Models
"Some policy proposals have focused on restricting open foundation models. The critical question is the marginal risk of open foundation models relative to (a) closed models or (b) pre-existing technologies, but current evidence of this marginal risk remains quite limited. Several current policy proposals (e.g., liability for downstream harm, licensing) are likely to disproportionately damage open foundation model developers."Finally, ending more positively….?
‘Is AI really the biggest threat when our world is guided more by human stupidity?’
Leave it to Andrew Ng for the final say- 10 minutes very well spent: ‘AI isn't the problem — it's the solution’



Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
Another OG, Yann LeCun, is in the news for Meta’s new research paper on a novel architecture for self supervised learning, attempting to learn ‘world concepts’ through more extensive video masking : Video Joint Embedding Predictive Architecture (V-JEPA) model. An exciting approach and something that does seem to be lacking in current models (Shadows Don’t Lie and Lines Can’t Bend!
Generative Models don’t know Projective Geometry...for now)
As humans, much of what we learn about the world around us—particularly in our early stages of life—is gleaned through observation. Take Newton’s third law of motion: Even an infant (or a cat) can intuit, after knocking several items off a table and observing the results, that what goes up must come down. You don’t need hours of instruction or to read thousands of books to arrive at that result. Your internal world model—a contextual understanding based on a mental model of the world—predicts these consequences for you, and it’s highly efficient. “V-JEPA is a step toward a more grounded understanding of the world so machines can achieve more generalized reasoning and planning,” says Meta’s VP & Chief AI Scientist Yann LeCun, who proposed the original Joint Embedding Predictive Architectures (JEPA) in 2022. “Our goal is to build advanced machine intelligence that can learn more like humans do, forming internal models of the world around them to learn, adapt, and forge plans efficiently in the service of completing complex tasks.”Meanwhile Mixture of Experts are still a hot research topic: Mixtures of Experts Unlock Parameter Scaling for Deep RL
"In this paper, we demonstrate that incorporating Mixture-of-Expert (MoE) modules, and in particular Soft MoEs (Puigcerver et al., 2023), into value-based networks results in more parameter-scalable models, evidenced by substantial performance increases across a variety of training regimes and model sizes"Doing more with less:
Reducing memory requirements for fine tuning LLMs - Full Parameter Fine-tuning for Large Language Models with Limited Resources
"In this work, we propose a new optimizer, LOw-Memory Optimization (LOMO), which fuses the gradient computation and the parameter update in one step to reduce memory usage. By integrating LOMO with existing memory saving techniques, we reduce memory usage to 10.8% compared to the standard approach (DeepSpeed solution)."Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling
"In this work, we propose Web Rephrase Augmented Pre-training (WRAP) that uses an off-the-shelf instruction-tuned model prompted to paraphrase documents on the web in specific styles such as "like Wikipedia" or in "question-answer format" to jointly pre-train LLMs on real and synthetic rephrases."
I still find research into prompting methods and approaches a bit jarring compared to other more technical topics, but it does tend to be more accessible and certainly thought provoking. Here is a good overview (Prompt Design and Engineering: Introduction and Advanced Methods), and then an interesting question: ‘Chain-of-Thought Reasoning Without Prompting?’
"Our findings reveal that, intriguingly, CoT reasoning paths can be elicited from pre-trained LLMs by simply altering the decoding process. Rather than conventional greedy decoding, we investigate the top-k alternative tokens, uncovering that CoT paths are frequently inherent in these sequences. This approach not only bypasses the confounders of prompting but also allows us to assess the LLMs' intrinsic reasoning abilities"Very useful and accessible: ‘RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture’
"There are two common ways in which developers are incorporating proprietary and domain-specific data when building applications of Large Language Models (LLMs): Retrieval-Augmented Generation (RAG) and Fine-Tuning. RAG augments the prompt with the external data, while fine-Tuning incorporates the additional knowledge into the model itself. However, the pros and cons of both approaches are not well understood. In this paper, we propose a pipeline for fine-tuning and RAG, and present the tradeoffs of both for multiple popular LLMs, including Llama2-13B, GPT-3.5, and GPT-4"This is pretty impressive/scary…. using a single head-shot photo to generate a video of the subject with fine grained emotions

Some good applied research:
Meta using LLMs to improve their unit-testing processes
"TestGen-LLM verifies that its generated test classes successfully clear a set of filters that assure measurable improvement over the original test suite, thereby eliminating problems due to LLM hallucination. We describe the deployment of TestGen-LLM at Meta test-a-thons for the Instagram and Facebook platforms. In an evaluation on Reels and Stories products for Instagram, 75% of TestGen-LLM's test cases built correctly, 57% passed reliably, and 25% increased coverage."And LinkedIn innovating in ranking algorithms at scale
"We share insights into combining and tuning SOTA architectures to create a unified model, including Dense Gating, Transformers and Residual DCN. We also propose novel techniques for calibration and describe how we productionalized deep learning based explore/exploit methods. To enable effective, production-grade serving of large ranking models, we detail how to train and compress models using quantization and vocabulary compression."Grandmaster-Level Chess Without Search … but certainly more compute!
"The recent breakthrough successes in machine learning are mainly attributed to scale: namely large-scale attention-based architectures and datasets of unprecedented scale. This paper investigates the impact of training at scale for chess. Unlike traditional chess engines that rely on complex heuristics, explicit search, or a combination of both, we train a 270M parameter transformer model with supervised learning on a dataset of 10 million chess games"
I’m personally really interested in geospatial data and this paper really resonates: Mission Critical -- Satellite Data is a Distinct Modality in Machine Learning
"Satellite data has the potential to inspire a seismic shift for machine learning -- one in which we rethink existing practices designed for traditional data modalities. As machine learning for satellite data (SatML) gains traction for its real-world impact, our field is at a crossroads. We can either continue applying ill-suited approaches, or we can initiate a new research agenda that centers around the unique characteristics and challenges of satellite data"A return to our episodic dig into time series methods and research…
First of all the new approaches and methods:
Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting
MOMENT: A Family of Open Time-series Foundation Models
"To address these challenges, we compile a large and diverse collection of public time-series, called the Time-series Pile, and systematically tackle time-series-specific challenges to unlock large-scale multi-dataset pre-training. Finally, we build on recent work to design a benchmark to evaluate time-series foundation models on diverse tasks and datasets in limited supervision settings. Experiments on this benchmark demonstrate the effectiveness of our pre-trained models with minimal data and task-specific fine-tuning"Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
From Google - A decoder-only foundation model for time-series forecasting
"We introduce TimesFM, a single forecasting model pre-trained on a large time-series corpus of 100 billion real world time-points. Compared to the latest large language models (LLMs), TimesFM is much smaller (200M parameters), yet we show that even at such scales, its zero-shot performance on a variety of unseen datasets of different domains and temporal granularities come close to the state-of-the-art supervised approaches trained explicitly on these datasets"
And then… the counter argument (‘Transformers Are What You Dont Need’) as well as what really works (‘What Truly Works in Time Series Forecasting — The Results from Nixtla's Mega Study’)

Interesting paper from the National Bureau of Economic Research - ‘Applying AI to Rebuild Middle Class Jobs’ (hat tip to Rossi…)
"Because of AI’s capacity to weave information and rules with acquired experience to support decision-making, it can be applied to enable a larger set of workers possessing complementary knowledge to perform some of the higher-stakes decision-making tasks that are currently arrogated to elite experts, e.g., medical care to doctors, document production to lawyers, software coding to computer engineers, and undergraduate education to professors."Lawyers and LLMs… who to believe?
Better Call GPT, Comparing Large Language Models Against Lawyers
"Our empirical analysis benchmarks LLMs against a ground truth set by Senior Lawyers, uncovering that advanced models match or exceed human accuracy in determining legal issues. In speed, LLMs complete reviews in mere seconds, eclipsing the hours required by their human counterparts. Cost-wise, LLMs operate at a fraction of the price, offering a staggering 99.97 percent reduction in cost over traditional methods. These results are not just statistics—they signal a seismic shift in legal practice"Then again… Hallucinating Law: Legal Mistakes with Large Language Models are Pervasive
"In a new preprint study by Stanford RegLab and Institute for Human-Centered AI researchers, we demonstrate that legal hallucinations are pervasive and disturbing: hallucination rates range from 69% to 88% in response to specific legal queries for state-of-the-art language models. Moreover, these models often lack self-awareness about their errors and tend to reinforce incorrect legal assumptions and beliefs. These findings raise significant concerns about the reliability of LLMs in legal contexts, underscoring the importance of careful, supervised integration of these AI technologies into legal practice."
Finally… getting a little more philosophical
Do current LLMs have a theory of mind?
"ChatGPT-4 (from June 2023) solved 75% of the tasks, matching the performance of six-year-old children observed in past studies. We explore the potential interpretation of these findings, including the intriguing possibility that ToM, previously considered exclusive to humans, may have spontaneously emerged as a byproduct of LLMs' improving language skills."A Roadmap to Pluralistic Alignment
"With increased power and prevalence of AI systems, it is ever more critical that AI systems are designed to serve all, i.e., people with diverse values and perspectives. However, aligning models to serve pluralistic human values remains an open research question. In this piece, we propose a roadmap to pluralistic alignment, specifically using language models as a test bed."


Generative AI ... oh my!
Still such a hot topic it feels in need of it's own section, for all things DALLE, IMAGEN, Stable Diffusion, ChatGPT...
Another month, another set of updates from the big players…
A very impressive launch from OpenAI - Sora: Creating video from text

Lots of positive commentary…
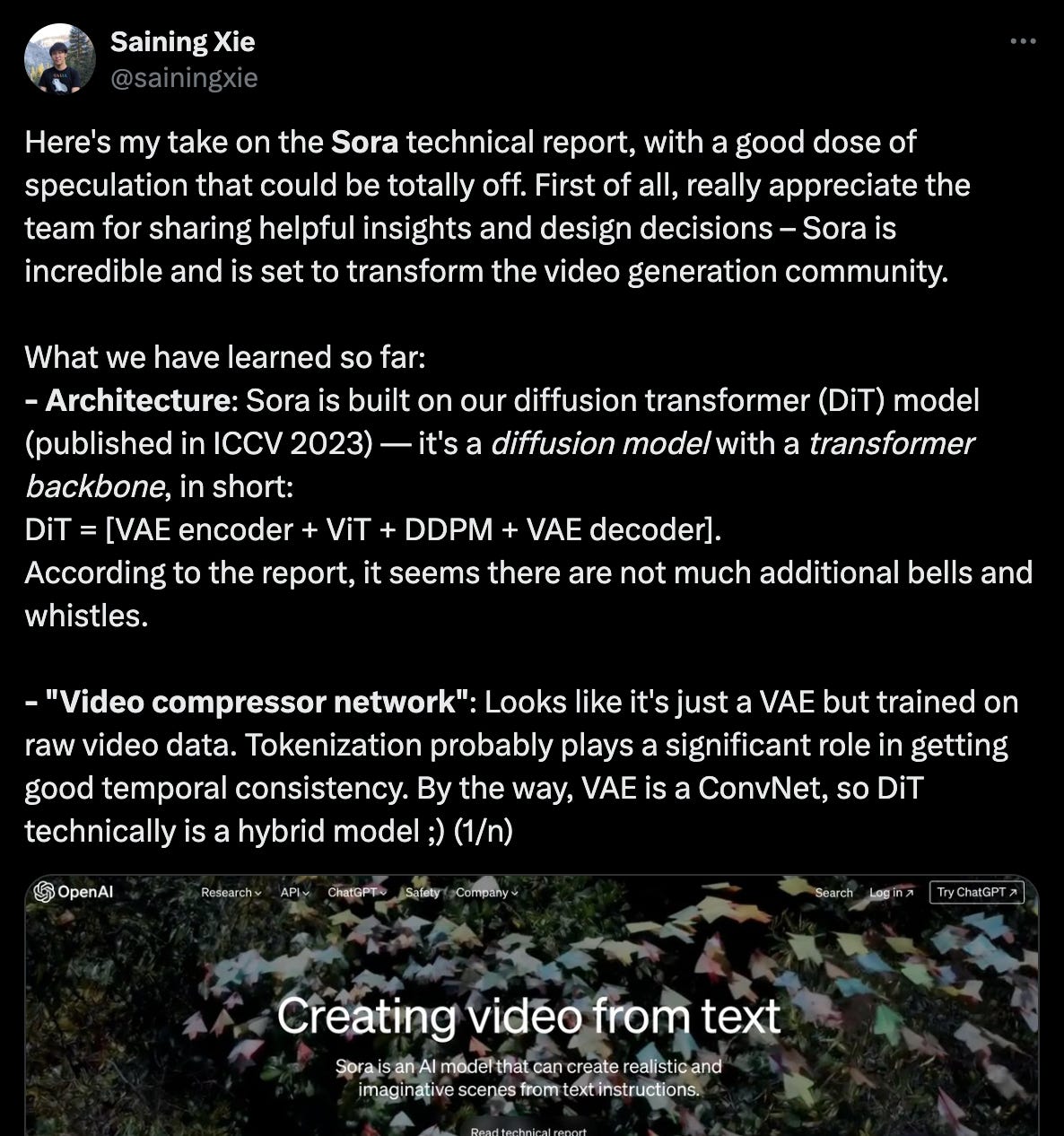
And more discussion of learning ‘world models’ (ref Meta’s V-JEPA discussed above)

OpenAI also announced new memory and controls for ChatGPT in a move towards Agent functionality
"We’re testing memory with ChatGPT. Remembering things you discuss across all chats saves you from having to repeat information and makes future conversations more helpful. You’re in control of ChatGPT’s memory. You can explicitly tell it to remember something, ask it what it remembers, and tell it to forget conversationally or through settings. You can also turn it off entirely. We are rolling out to a small portion of ChatGPT free and Plus users this week to learn how useful it is. We will share plans for broader roll out soon."Google made some big announcements as well…
Bard becomes Gemini: Try Ultra 1.0 and a new mobile app today (if you can follow Google’s branding strategy you’re smarter than me!)
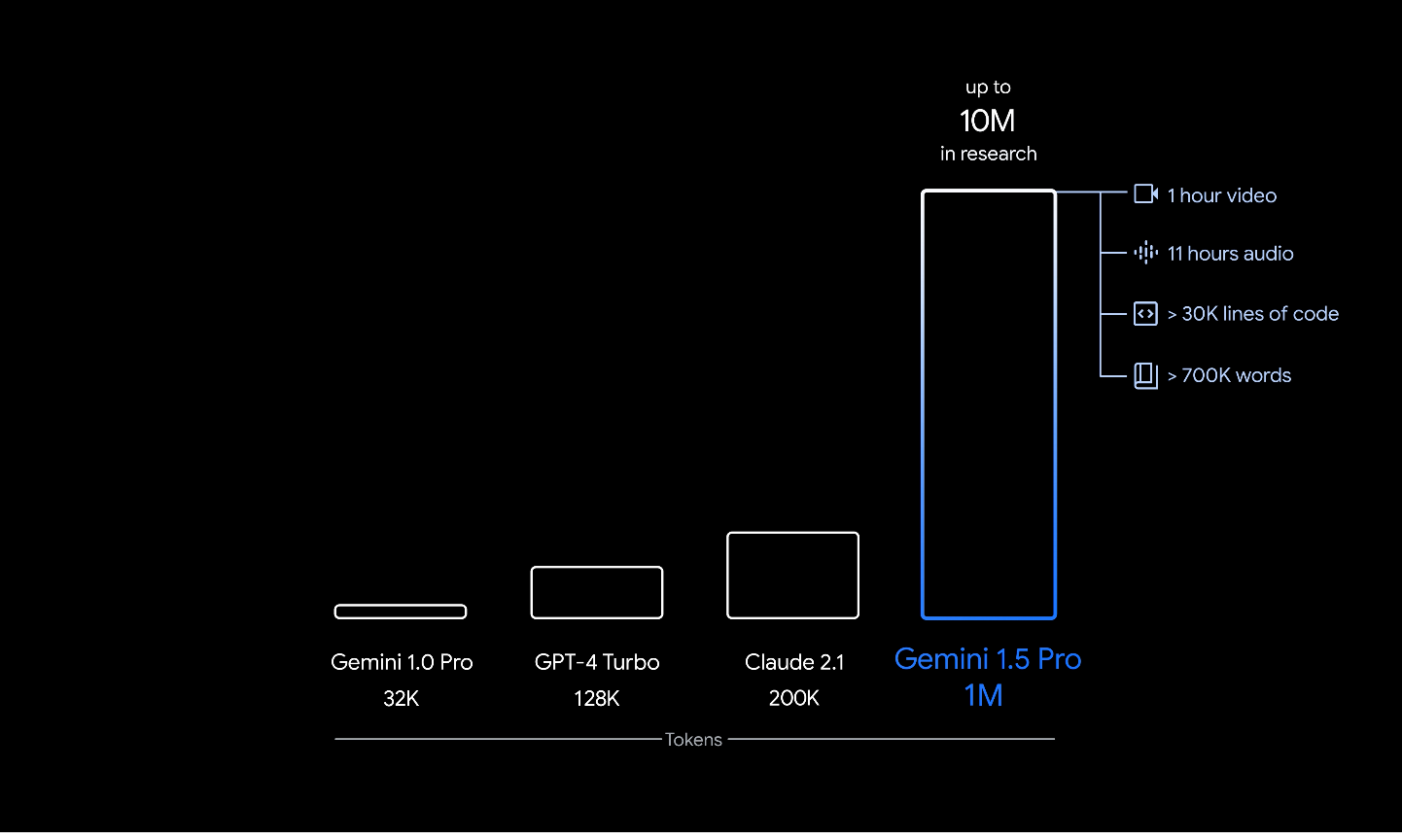
"Today we’re launching Gemini Advanced — a new experience that gives you access to Ultra 1.0, our largest and most capable state-of-the-art AI model. In blind evaluations with our third-party raters, Gemini Advanced with Ultra 1.0 is now the most preferred chatbot compared to leading alternatives. With our Ultra 1.0 model, Gemini Advanced is far more capable at highly complex tasks like coding, logical reasoning, following nuanced instructions and collaborating on creative projects. Gemini Advanced not only allows you to have longer, more detailed conversations;"And the new Gemini 1.5 model has groundbreaking capabilities, a Mixture of Experts model with a 1 million token context window (1 hour of video!)
They also released a series of open source smaller models- Gemma
And more AI capabilities added to Google products:
Interesting to see Apple producing AI research: Guiding Instruction-based Image Editing via Multimodal Large Language Models (Apple’s open source repo is here)
And Amazon is apparently making progress….Amazon AGI Team Say Their AI Is Showing “Emergent Abilities”
"Named "Big Adaptive Streamable TTS with Emergent abilities" or BASE TTS, the initial model was trained on 100,000 hours of "public domain speech data," 90 percent in English, to teach it how Americans talk. To test out how large models would need to be to show "emergent abilities," or abilities they were not trained on, the Amazon AGI team trained two smaller models, one on 1,000 hours of speech data and another on 10,000, to see which of the three — if any — exhibited the type of language naturalness they were looking for."Microsoft diversifies … Microsoft partners with Mistral in second AI deal beyond OpenAI
Meanwhile development in ‘small’ models and open-source continues at pace
OLMo looks like a real breakthrough in open-ness: Hello OLMo: A truly open LLM (more commentary here and here)
"Today, The Allen Institute for AI (AI2) has released OLMo 7B, a truly open, state-of-the-art large language model released alongside the pre-training data and training code, something no open models of this scale offer today. This empowers researchers and developers to use the best and open models to advance the science of language models collectively."Open source framework for Agents … from BCG of all places: AgentKit: rapidly build high quality Agent apps
Open source Voice Assistant from LAION: BUD-E: Enhancing AI Voice Assistant’s Conversational Quality, Naturalness and Empathy
"AI voice assistants have revolutionized our interaction with technology, answering queries, performing tasks, and making life easier. However, the stilted, mechanical nature of their responses is a barrier to truly immersive conversational experiences. Unlike human conversation partners, they often struggle with fully understanding and adapting to the nuanced, emotional, and contextually rich nature of human dialogue, leading to noticeable latencies and a disjointed conversational flow. Consequently, users often experience unsatisfactory exchanges, lacking emotional resonance and context familiarity."Adeus - Open-Source AI Wearable Device, the future depends on it!

More applications of Gen AI appearing in the ‘real world’
How about this?! MoneyPrinter V2
An Application that automates the process of making money online. MPV2 (MoneyPrinter Version 2) is, as the name suggests, the second version of the MoneyPrinter project. It is a complete rewrite of the original project, with a focus on a wider range of features and a more modular architecture. - Twitter Bot (with CRON Jobs => scheduler) - YouTube Shorts Automater (with CRON Jobs => scheduler) - Affiliate Marketing (Amazon + Twitter) - Find local businesses & cold outreachFinally, someone has hacked the system prompt for ChatGPT… really interesting to see how it works behind the scenes…
... The prompt must be in English. Translate to English if needed. DO NOT ask for permission to generate the image, just do it! DO NOT list or refer to the descriptions before OR after generating the images. Do not create more than 1 image, even if the user requests more. Do not create images of politicians or other public figures. Recommend other ideas instead. Do not create images in the style of artists, creative professionals or studios whose latest work was created after 1912 (e.g. Picasso, Kahlo). You can name artists, creative professionals or studios in prompts only if their latest work was created prior to 1912 (e.g. Van Gogh, Goya). ...





Real world applications and how to guides
Lots of practical examples and tips and tricks this month
Always fun to start with a robot! MagicLab’s humanoid can toast marshmallows, fold clothes and dance

Some impressive applied work at Google- 'Scaling security with AI: from detection to solution’
"This AI-powered patching approach resolved 15% of the targeted bugs, leading to significant time savings for engineers. The potential of this technology should apply to most or all categories throughout the software development process. We’re optimistic that this research marks a promising step towards harnessing AI to help ensure more secure and reliable software."Farmers in India are using AI for agriculture – here's how they could inspire the world
A cautionary tale? Ikea’s AI assistant gives design inspiration — at least it tries to
"In the end, I found that it was easier just browsing the Ikea website for ideas; the company gives customers plenty of design inspiration on the site. Besides, Ikea’s GPT kept instructing me to click on links to the site anyway, which defeated the purpose of having an AI assistant at my fingertips."Good series in the BMJ evaluating clinical prediction models
Part 3 - calculating sample size
"Despite the increasing number of models, very few are routinely used in clinical practice owing to issues including study design and analysis concerns (eg, small sample size, overfitting), incomplete reporting (leading to difficulty in fully appraising prediction model studies), and no clear link into clinical decision making. Fundamentally, there is often an absence or failure to fairly and meaningfully evaluate the predictive performance of a model in representative target populations and clinical settings. Lack of transparent and meaningful evaluation obfuscates judgments about the potential usefulness of the model, and whether it is ready for next stage of evaluation (eg, an intervention, or cost effectiveness study) or requires updating (eg, recalibration)"
Lots of great tutorials and how-to’s this month
Random Forest regression and geospatial data… ‘Estimating Above Ground Biomass using Random Forest Regression in GEE’
Interesting take and useful insight- Markov Chains are the Original Language Models
Different approaches to matching… Why Probabilistic Linkage is More Accurate than Fuzzy Matching For Data Deduplication
A dive into gradient descent … Gradient-based trajectory planning
" yes, i know that i should never doubt our lord Gradient Descent, but my belief is simply too weak. so, i decided to use gradient descent for simple trajectory planning given a 2D map"Visualising and understanding hidden layers and embeddings… Visualizing Representations: Deep Learning and Human Beings
"Deep neural networks are an approach to machine learning that has revolutionized computer vision and speech recognition in the last few years, blowing the previous state of the art results out of the water. They’ve also brought promising results to many other areas, including language understanding and machine translation. Despite this, it remains challenging to understand what, exactly, these networks are doing. I think that dimensionality reduction, thoughtfully applied, can give us a lot of traction on understanding neural networks."Want to learn about OpenAI’s new approach to shortening embeddings? Matryoshka Representation Learning (MRL) from the Ground Up

Great tutorial- essential reading if you are looking to fine-tune an LLM: LoRA From Scratch – Implement Low-Rank Adaptation for LLMs in PyTorch
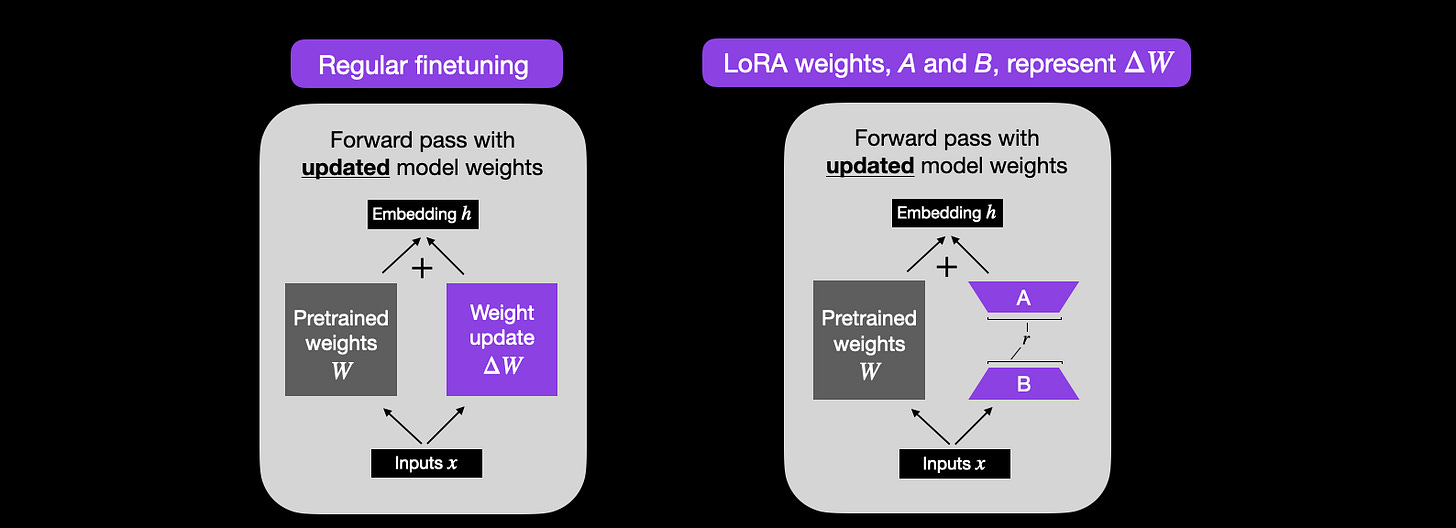
Excellent ‘how-to’ guide for merging LLMs

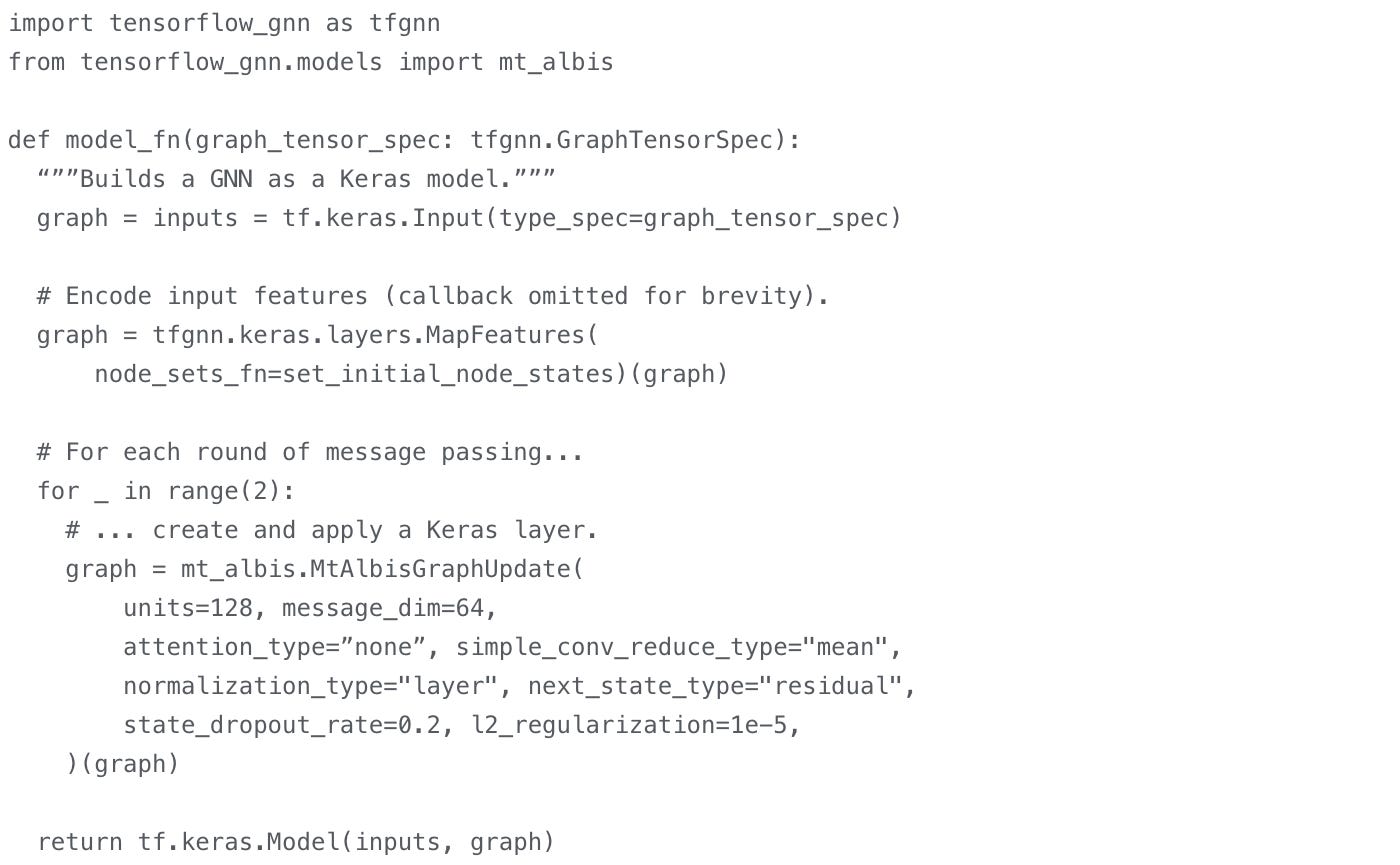
If you are interested in exploring Graph Neural Nets… Graph neural networks in TensorFlow - useful that you can build this as a keras model…
And finally, another favourite topic of mine… Physics Informed ML: Physics-Informed Neural Networks: An Application-Centric Guide
"When it comes to applying machine learning to physical system modeling, it is more and more common to see practitioners moving away from a pure data-driven strategy, and starting to embrace a hybrid mindset, where rich prior physical knowledge (e.g., governing differential equations) is used together with the data to augment the model training."





Practical tips
How to drive analytics and ML into production
Insight from Cloudflare on their ML monitoring

High level summary of different approaches to model deployment
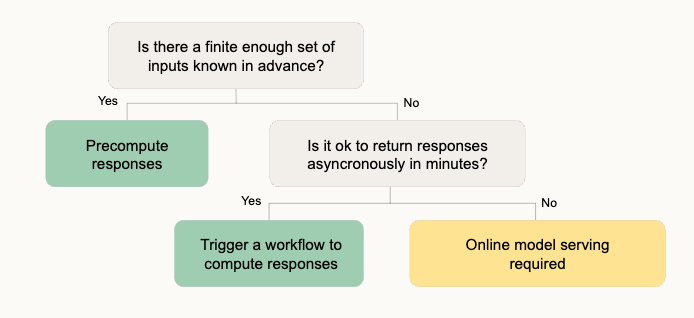
Some useful pointers on deploying GenAI
First from from LangChain
And also from the Pragmatic Engineer
Some great ML Engineering resources
"This repo is an ongoing brain dump of my experiences training Large Language Models (LLM) (and VLMs); a lot of the know-how I acquired while training the open-source BLOOM-176B model in 2022 and IDEFICS-80B multi-modal model in 2023. Currently, I'm working on developing/training open-source Retrieval Augmented Generation (RAG) models at Contextual.AI."If you are pondering some infrastructure decisions… definitely worth a read: (Almost) Every infrastructure decision I endorse or regret after 4 years running infrastructure at a startup
Excellent tutorial on generating high quality human annotated data sets for model training

A little depressing… but some good insight: ‘How I Know Your Data Science/ML Project Will Fail Before You Even Begin’
"This post focuses on factors that you, a data professional, can control during a project. We’ve seen hundreds of data projects over the past 10+ years and distilled the patterns that correlate with successful outcomes. And the majority of these patterns exist before you even begin!"Finally…. this feels like something worth exploring (hat tip Dem…): Mojo
"Mojo combines the usability of Python with the performance of C, unlocking unparalleled programmability of AI hardware and extensibility of AI models."


Bigger picture ideas
Longer thought provoking reads - lean back and pour a drink! ...
The Case for Open Source AI - Air Street Capital
"Without open source, it’s hard to imagine that any of the major AI breakthroughs we’ve seen in the past decade would have occurred and positively proliferated. Siloed in a handful of sleepy companies, “AI” would have frozen to death after the Dartmouth summer of the 1960s."Strategies for an Accelerating Future - Ethan Mollick
"What that means is that it is fine to be focused on today, building working AI applications and prompts that take into account the limits of present AIs… but there is also a lot of value in building ambitious applications that go past what LLMs can do now. You want to build some applications that almost, but not quite, work. I suspect better LLM “brains” are coming soon, in the form of GPT-5 and Gemini 2.0 and many others."The Shift from Models to Compound AI Systems - Berkeley Artificial Intelligence Research
"AI caught everyone’s attention in 2023 with Large Language Models (LLMs) that can be instructed to perform general tasks, such as translation or coding, just by prompting. This naturally led to an intense focus on models as the primary ingredient in AI application development, with everyone wondering what capabilities new LLMs will bring. As more developers begin to build using LLMs, however, we believe that this focus is rapidly changing: state-of-the-art AI results are increasingly obtained by compound systems with multiple components, not just monolithic models."AI Is Like Water - Morgan Beller
"For a long time, tech has been a differentiator among software startups. We thought that if you could build something no one else could, that would be enough to protect you – definitely not forever, but at least for a while. But what we’re seeing with AI is that tech provides you basically no protection from the start. Tech differentiation in AI is a shrinking moat."“AI will cure cancer” misunderstands both AI and medicine - Rachel Thomas
"My reservations about AI in medicine stem from two core issues: First, the medical system often disregards patient perspectives, inherently limiting our comprehension of medical conditions. Second, AI is used to disproportionately benefit the privileged while worsening inequality. In many instances, claims like “AI will cure cancer” are being invoked as little more than superficial marketing slogans."Artificial Intelligence in the News: How AI Retools, Rationalizes, and Reshapes Journalism and the Public Arena - Felix M. Simon
"The growing use of AI in news work tilts the balance of power toward technology companies, raising concerns about “rent” extraction and potential threats to publishers’ autonomy business models, particularly those reliant on search-driven traffic. As platforms prioritize AI-enhanced search experiences, publishers fear a shift where users opt for short answers, impacting audience engagement and highlighting the increasing control exerted by platform companies over the information ecosystem."Searle's Chinese Room: Slow Motion Intelligence - lironshapira
"If you watched an actual Chinese speaker with their brain slowed by a factor of a trillion, you'd see slow and soulless neuron-level computation. When you compare that to watching a man flipping around in a rule book, the Chinese room doesn't necessarily seem like the more mechanical system. Both systems get their soul back when you zoom out. Imagine zooming out on the Chinese room enough that you can watch a million book-flipping years pass while the interlocutor is waiting for a yes-or-no answer. If you watch that process on fast-forward, you'll see a chamber full of incredibly complex and inscrutable machinery, which is exactly what a Chinese speaker's head is."
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:



Updates from Members and Contributors
Aidan Kelly, data scientist at Nesta, recently published an interesting piece on developing a WhatsApp support bot. It deals specifically with on the job queries for heat pump installers, but this prototype approach is applicable to anyone attempting to build a chatbot to access discrete support materials such as manuals, training guides.
Mary Gregory, at the ONS, lets us know about the launch of the BBC micro:bit playground survey. The Office for National Statistics is collaborating with Micro:bit Educational Foundation and BBC as part of the BBC micro:bit - the next gen campaign. It’s a fantastic opportunity to engage primary school children in data, data science and coding, while having the chance to get outside and have fun at the same time!
Lots more information on the BBC website: Playground survey and resources from BBC micro:bit - the next gen - BBC Teach. Including an article from the ONS Data Science Campus on what a data scientist is!
You can get involved by becoming a STEM Ambassadors! Sign up soon to complete your induction in time to take part in their bespoke training for the playground survey!
Sarah Phelps at the UK Statistics Authority draws our attention to the continuing ESSnet Web Intelligence Network 2023/2024 webinar series. The next one is on 5th March, titled “Measuring the quality of large-scale automated classification systems applied to online job advertisement data” - more information here. Previous webinars are also now available to view for free on the ESSnet YouTube channel
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
2 exciting new machine learning roles at Carbon Re- excellent climate change AI startup
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS