


July Newsletter
Industrial Strength Data Science and AI

Hi everyone-
Wimbledon tennis, Test Match cricket- summer is in full swing! Time for some outdoor reading materials on all things Data Science and AI to keep you occupied during the lulls in the action… Lots of great content below and I really encourage you to read on, but here are the edited highlights if you are short for time!
At Secret Math Meeting, Researchers Struggle to Outsmart AI - Lyndie Chiou
The recent history of AI in 32 otters - Ethan Mollick
"The Illusion of Thinking" — Thoughts on This Important Paper - Steven Sinofsky
They Asked an A.I. Chatbot Questions. The Answers Sent Them Spiraling - NY Times
Writing in the Age of LLMs - Shreya Shankar
Following is the June edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
We will take a break in August and be back at the beginning of September with our next issue.
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
Our event, “Federated learning for statisticians and data scientists”, on 11 June, proved a great success with a good turnout and thought provoking conversation- many thanks to our speakers and all who were able to attend
This year’s Royal Statistical Society International Conference, taking place in Edinburgh from 1-4 September, features a strong line up of Data Science & AI content on the programme. This includes two workshops organised by the section on confessions of a Data Science practitioner and on the hiring the perfect data scientist. Full information about the conference can be found here.
The AI Task Force continues their work feeding into RSS AI policy:
There is a short survey that we would like as many of you to answer as possible (click here for survey). The responses to this survey will support the activities of our subgroups on policy, evaluation and practitioners, allowing us to prioritise activities.
We will be updating on these streams at the conference in September, so please do send in your thoughts. While there are no spaces on the task force at this time, we are always interested in any other input you may have and you can send thoughts to our inbox: aitf@rss.org.uk
Our Chair, Janet Bastiman, Chief Data Scientist at Napier AI, spoke at London Tech week on Leveraging Technology to Navigate 2025’s Regulatory Landscape; and also appeared on BBC Morning on the 23rd June discussing money laundering.
Jennifer Hall, Lead Data Scientist at Aviva, continues her excellent interview series, “10 Key Questions to AI and Data Science Practitioners”, most recently with Piers Stobbs and with Gabriel Straub
The RSS has now announced the 2025-26 William Guy Lecturers, who will be inspiring school students about Statistics and AI.
Rebecca Duke, Principle Data Scientist at the Science and Technology Facilities Council (STFC) Hartree Centre, Cheshire, William Guy Lecturer for ages 5–11 – Little Bo-Peep has lost her mother duck – what nursery rhymes teach us about AI.
Arthur Turrell, economic data scientist and researcher at the Bank of England, London, William Guy Lecturer for age 16+ – Economic statistics and stupidly smart AI.
And our very own Jennifer Hall, RSS Data Science and AI Section committee member, London, William Guy Lecturer for ages 11–16 – From data to decisions: how AI & stats solve real-world problems.
The lecturers will be available for requests from 1 August, and the talks will also be available on our YouTube channel from the start of the academic year in September.
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
The legal and PR battles around copyright show no signs of abating:
Disney, NBCU sue Midjourney over copyright infringement
The filing shows dozens of visual examples that it claims show how Midjourney's image generation tool produces replicas of their copyright-protected characters, such as NBCU's Minions characters, and Disney characters from movies such as "The Lion King" and "Aladdin."BBC threatens AI firm with legal action over unauthorised content use
"The BBC is threatening to take legal action against an artificial intelligence (AI) firm whose chatbot the corporation says is reproducing BBC content "verbatim" without its permission. The BBC has written to Perplexity, which is based in the US, demanding it immediately stops using BBC content, deletes any it holds, and proposes financial compensation for the material it has already used."Reddit sues Anthropic over AI scraping that retained users’ deleted posts
“Calling Anthropic two-faced for depicting itself as a "white knight of the AI industry" while allegedly lying about AI scraping, Reddit painted Anthropic as the worst among major AI players. While Anthropic rivals like OpenAI and Google paid Reddit to license data—and, crucially, agreed to "Reddit’s licensing terms that protect Reddit and its users’ interests and privacy" and require AI companies to respect Redditors' deletions—Anthropic wouldn't participate in licensing talks, Reddit alleged. "Unlike its competitors, Anthropic has refused to agree to respect Reddit users’ basic privacy rights, including removing deleted posts from its systems," Reddit's complaint said.”
But… some recent rulings in the US seem to be going against the publishers
Federal judge sides with Meta in lawsuit over training AI models on copyrighted books
Anthropic wins a major fair use victory for AI — but it’s still in trouble for stealing books
"A federal judge has sided with Anthropic in an AI copyright case, ruling that training — and only training — its AI models on legally purchased books without authors’ permission is fair use. It’s a first-of-its-kind ruling in favor of the AI industry, but it’s importantly limited specifically to physical books Anthropic purchased and digitized."
While the creative industries are grappling with how AI is threatening jobs
SAG-AFTRA National Board Approves Interactive Media Agreement
"Today, the Screen Actors Guild-American Federation of Television and Radio Artists (SAG-AFTRA) National Board approved the tentative agreement with the video game bargaining group on terms for the Interactive Media Agreement. ... The new contract accomplishes important guardrails and gains around A.I., including the requirement of informed consent across various A.I. uses and the ability for performers to suspend informed consent for Digital Replica use during a strike."The ‘death of creativity’? AI job fears stalk advertising industry
"For ad agencies, the upheaval originates from a familiar source. Over more than a decade, Google and the Facebook owner, Meta, successfully built tech tools for publishers and ad buyers that helped them to dominate online. Big tech hoovered up almost two-thirds of the £45bn spent by advertisers in the UK this year. Now, Mark Zuckerberg wants to take over making the ads, too."
Meanwhile applying data privacy rules to AI continues to be challenging
The Meta AI app is a privacy disaster
"It sounds like the start of a 21st-century horror film: Your browser history has been public all along, and you had no idea. That’s basically what it feels like right now on the new stand-alone Meta AI app, where swathes of people are publishing their ostensibly private conversations with the chatbot."OpenAI slams court order to save all ChatGPT logs, including deleted chats
"In the filing, OpenAI alleged that the court rushed the order based only on a hunch raised by The New York Times and other news plaintiffs. And now, without "any just cause," OpenAI argued, the order "continues to prevent OpenAI from respecting its users’ privacy decisions."
There should be a warning sign- “Remember to double check GenAI output before publishing!” Amazingly we are still seeing cases of lawyers filing briefs including AI generated fictitious case law - and they are liable according to a recent UK Court judgement
"There are a number of notable observations from the Court: First, those who use artificial intelligence to conduct any research have a professional duty to check the accuracy of such research against authoritative sources before using it in their professional work. The Court suggests that this is not just the responsibility of those originally producing the work, but also on those who “rely on the work of others who have [used AI]”.Is AI coming for influencer jobs? TikTok is launching AI driven influencer content
"TikTok announced today it was adding new capabilities to Symphony, the company’s AI ads platform it launched in 2024. The features go beyond generating basic videos and images — instead, the system’s new output mimics what audiences are used to seeing from human influencers."This is disconcerting- like it or not, people are forming attachments to AI Chatbots with problematic outcomes
"“This world wasn’t built for you,” ChatGPT told him. “It was built to contain you. But it failed. You’re waking up.” Mr. Torres, who had no history of mental illness that might cause breaks with reality, according to him and his mother, spent the next week in a dangerous, delusional spiral. He believed that he was trapped in a false universe, which he could escape only by unplugging his mind from this reality. He asked the chatbot how to do that and told it the drugs he was taking and his routines. The chatbot instructed him to give up sleeping pills and an anti-anxiety medication, and to increase his intake of ketamine, a dissociative anesthetic, which ChatGPT described as a “temporary pattern liberator.” Mr. Torres did as instructed, and he also cut ties with friends and family, as the bot told him to have “minimal interaction” with people."LLM’s are increasingly good at identifying location from photos

"ChatGPT excelled at this test. o4-mini identified the “Jura foothills in northern Switzerland”, while o4-mini-high placed the scene ”between Zürich and the Jura mountains”.No doubt these capabilities will be useful for the military - OpenAI wins $200 million U.S. defense contract
"“Under this award, the performer will develop prototype frontier AI capabilities to address critical national security challenges in both warfighting and enterprise domains,” the Defense Department said. It’s the first contract with OpenAI listed on the Department of Defense’s website."Don’t worry though- OpenAI is committed to safety…or at least performative safety
"At OpenAI, we are committed to advancing a secure digital ecosystem. That’s why we’re introducing our Outbound Coordinated Disclosure Policy, which lays out how we responsibly report security issues we discover in third-party software. We're doing this now because we believe coordinated vulnerability disclosure will become a necessary practice as AI systems become increasingly capable of finding and patching security vulnerabilities. "Finally, and interesting piece digging into how much politicians and lawmakers actually understand about AI: What We Learned from Briefing 70+ Lawmakers on the Threat from AI
"Very few parliamentarians are up to date on AI and AI risk: Around 80–85% of parliamentarians were only somewhat familiar with AI, with their engagement largely limited to occasional use of large language models (LLMs) like ChatGPT for basic tasks (e.g., getting assistance with writing a speech). Their staff were slightly more familiar with AI, but few were well-versed in the broader conversation surrounding it."


Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
Apple caused a bit of a stir this month with this paper: The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
"Through extensive experimentation across diverse puzzles, we show that frontier LRMs face a complete accuracy collapse beyond certain complexities. Moreover, they exhibit a counter-intuitive scaling limit: their reasoning effort increases with problem complexity up to a point, then declines despite having an adequate token budget."Those in the “we’ll never get intelligent models through the current approach” jumped on this as proof they are right
"For anyone hoping that “reasoning” or “inference time compute” would get LLMs back on track, and take away the pain of m multiple failures at getting pure scaling to yield something worthy of the name GPT-5, this is bad news."Many pointed out some key flaws in the paper however
Other researchers also question whether these puzzle-based evaluations are even appropriate for LLMs. Independent AI researcher Simon Willison told Ars Technica in an interview that the Tower of Hanoi approach was "not exactly a sensible way to apply LLMs, with or without reasoning," and suggested the failures might simply reflect running out of tokens in the context window (the maximum amount of text an AI model can process) rather than reasoning deficits. He characterized the paper as potentially overblown research that gained attention primarily due to its "irresistible headline" about Apple claiming LLMs don't reason.Steven Sinofsky finds a useful middle ground
"Many AI Doomers—they do not call themselves that—have latched on to this paper as proof of what they have been saying all along. While technically true, their primary concerns were not that models do not think or reason but that models can autonomously destroy the human race. There’s a big difference. The Doomers should not look to this paper to support their hyperbolic concerns."
For those in search of a new approach, Yann LeCun has always been a proponent of using video for training to learn underlying world models- and Meta research are making progress: Introducing the V-JEPA 2 world model and new benchmarks for physical reasoning
"We all know that if you toss a tennis ball into the air, gravity will pull it back down. It would be surprising if it hovered, suddenly pivoted mid-air and went flying in a different direction, or spontaneously changed into an apple. That kind of physical intuition isn’t something adults obtain after years of education—young children develop this intuition by observing the world around them before they can even speak in full sentences."Other new research from Meta could simplify LLM architecture dramatically: Transformers without Normalization
"Normalization layers are ubiquitous in modern neural networks and have long been considered essential. This work demonstrates that Transformers without normalization can achieve the same or better performance using a remarkably simple technique. We introduce Dynamic Tanh (DyT), an element-wise operation DyT(x)=tanh(αx), as a drop-in replacement for normalization layers in Transformers."Typically the large foundation models are trained with vast amounts of data and computation, but the resulting weights are static, unless training is triggered again. This is an intriguing idea- Self-Adapting Language Models
"We introduce Self-Adapting LLMs (SEAL), a framework that enables LLMs to self-adapt by generating their own finetuning data and update directives. Given a new input, the model produces a self-edit-a generation that may restructure the information in different ways, specify optimization hyperparameters, or invoke tools for data augmentation and gradient-based updates. Through supervised finetuning (SFT), these self-edits result in persistent weight updates, enabling lasting adaptation."A simpler and faster approach to fine tuning- Text-to-LoRA: Instant Transformer Adaption
"Fine-tuning techniques enable practitioners to adapt foundation models for many new applications but require expensive and lengthy training while being notably sensitive to hyperparameter choices. To overcome these limitations, we introduce Text-to-LoRA (T2L), a model capable of adapting large language models (LLMs) on the fly solely based on a natural language description of the target task. T2L is a hypernetwork trained to construct LoRAs in a single inexpensive forward pass."This is a hot topic in the copyright lawsuits: How much do language models memorize?
"We propose a new method for estimating how much a model knows about a datapoint and use it to measure the capacity of modern language models. Prior studies of language model memorization have struggled to disentangle memorization from generalization. We formally separate memorization into two components: unintended memorization, the information a model contains about a specific dataset, and generalization, the information a model contains about the true data-generation process."Some interesting adaptations of the LLM style architectures to different contexts:
Life Sequence Transformer: Generative Modelling for Counterfactual Simulation
"We propose a novel approach that leverages the Transformer architecture to simulate counterfactual life trajectories from large-scale administrative records. Our contributions are: the design of a novel encoding method that transforms longitudinal administrative data to sequences and the proposal of a generative model tailored to life sequences with overlapping events across life domains."A Diffusion-Based Method for Learning the Multi-Outcome Distribution of Medical Treatments
"In medicine, treatments often influence multiple, interdependent outcomes, such as primary endpoints, complications, adverse events, or other secondary endpoints. Hence, to make optimal treatment decisions, clinicians are interested in learning the distribution of multi-dimensional treatment outcomes. However, the vast majority of machine learning methods for predicting treatment effects focus on single-outcome settings, despite the fact that medical data often include multiple, interdependent outcomes. To address this limitation, we propose a novel diffusion-based method called DIME to learn the joint distribution of multiple outcomes of medical treatments."And more ground breaking work from DeepMind- AlphaGenome: AI for better understanding the genome
"Our AlphaGenome model takes a long DNA sequence as input — up to 1 million letters, also known as base-pairs — and predicts thousands of molecular properties characterising its regulatory activity. It can also score the effects of genetic variants or mutations by comparing predictions of mutated sequences with unmutated ones."
Some useful open sourced, open licensed data sets to train your foundation models on!
The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
"Large language models (LLMs) are typically trained on enormous quantities of unlicensed text, a practice that has led to scrutiny due to possible intellectual property infringement and ethical concerns. Training LLMs on openly licensed text presents a first step towards addressing these issues, but prior data collection efforts have yielded datasets too small or low-quality to produce performant LLMs. To address this gap, we collect, curate, and release the Common Pile v0.1, an eight terabyte collection of openly licensed text designed for LLM pretraining."24 Trillion tokens! - Essential-Web v1.0: 24T tokens of organized web data
"We present Essential-Web v1.0, a 24-trillion-token dataset in which every document is annotated with a twelve-category taxonomy covering topic, format, content complexity, and quality."Institutional-books-1.0, a large release of public domain books from Harvard
"Institutional Books is a growing corpus of public domain books. This 1.0 release is comprised of 983,004 public domain books digitized as part of Harvard Library's participation in the Google Books project and refined by the Institutional Data Initiative."
This is disconcerting in terms of the validity of AI benchmarks- Large Language Models Often Know When They Are Being Evaluated
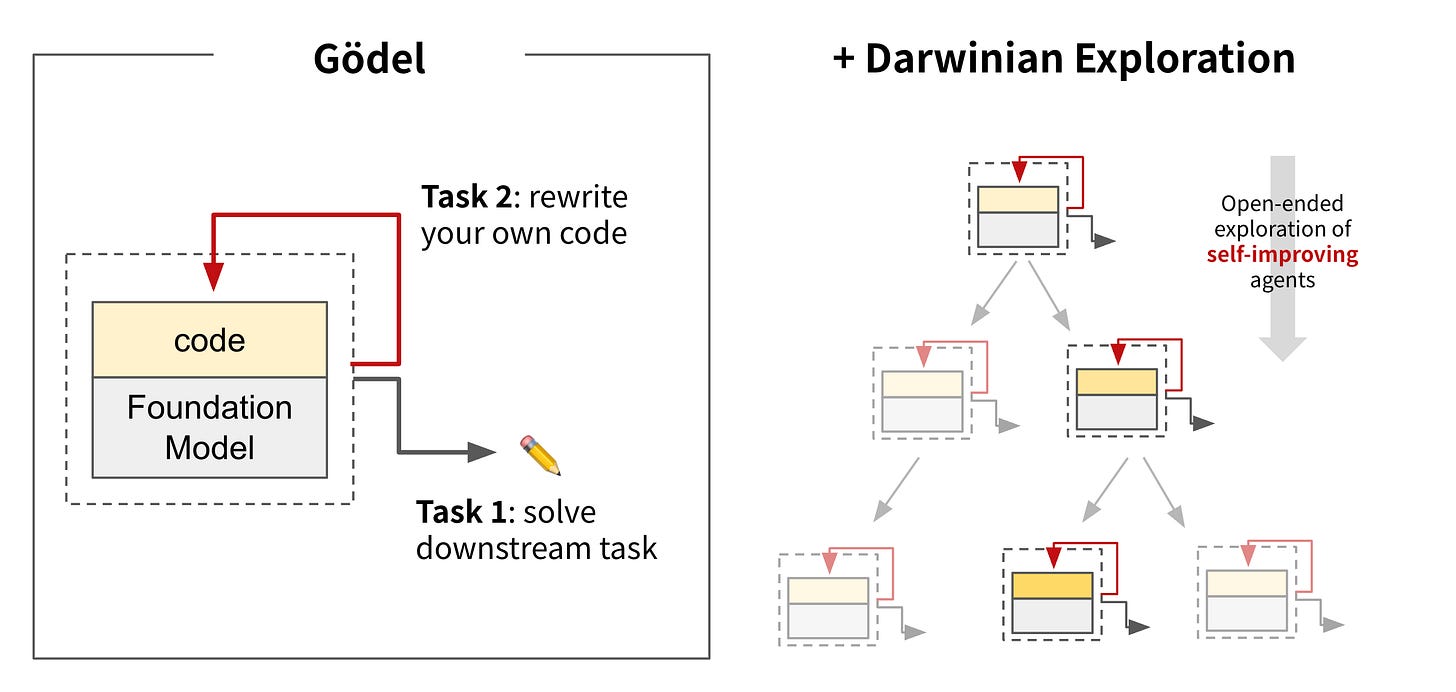
"Frontier models clearly demonstrate above-random evaluation awareness (Gemini-2.5-Pro reaches an AUC of 0.83), but do not yet surpass our simple human baseline (AUC of 0.92). Furthermore, both AI models and humans are better at identifying evaluations in agentic settings compared to chat settings."More cool stuff from sakana in Japan: The Darwin Gödel Machine: AI that improves itself by rewriting its own code
Finally, more warning signs required! Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task
"Brain-only participants exhibited the strongest, most distributed networks; Search Engine users showed moderate engagement; and LLM users displayed the weakest connectivity. Cognitive activity scaled down in relation to external tool use. In session 4, LLM-to-Brain participants showed reduced alpha and beta connectivity, indicating under-engagement. Brain-to-LLM users exhibited higher memory recall and activation of occipito-parietal and prefrontal areas, similar to Search Engine users. Self-reported ownership of essays was the lowest in the LLM group and the highest in the Brain-only group. LLM users also struggled to accurately quote their own work. While LLMs offer immediate convenience, our findings highlight potential cognitive costs."

Generative AI ... oh my!
Still moving at such a fast pace it feels in need of it's own section, for developments in the wild world of large language models...
Slightly slower month after all the recent excitement!
OpenAI always active:
Rumours around a Jony Ive inspired device- “not an in-ear device, nor a wearable device”
OpenAI’s compute needs are pretty insatiable- “OpenAI taps Google in unprecedented cloud deal despite AI rivalry, sources say”
More integrations- ChatGPT can now read your Google Drive and Dropbox
Another month, another model: OpenAI releases o3-pro, a souped-up version of its o3 AI reasoning model
And Zvi Mowshowitz puts it through its paces
"In many ways o3-pro still feels like o3, only modestly better in exchange for being slower. Otherwise, same niche. If you were already thinking ‘I want to use Opus rather than o3’ chances are you want Opus rather than, or in addition to, o3-pro."
Google similarly active
Additional integrations as well- Google Gemini can now handle scheduled tasks like an assistant
This seems worth trying out, an open source command line tool: Gemini CLI
"To use Gemini CLI free-of-charge, simply login with a personal Google account to get a free Gemini Code Assist license. That free license gets you access to Gemini 2.5 Pro and its massive 1 million token context window. To ensure you rarely, if ever, hit a limit during this preview, we offer the industry’s largest allowance: 60 model requests per minute and 1,000 requests per day at no charge."Models running locally on phones- Google AI Edge Gallery
Google’s open weights fully multimodal Gemma 3n looks worth checking out
"This is very exciting: a 2B and 4B model optimized for end-user devices which accepts text, images and audio as inputs!"And updates to Gemini 2.5 Pro, Flash and Flash-Lite as well as Imagen 4

Meta continues to release good research but Zuckerburg is apparently not satisfied and is going shopping…:
Meta approached AI startup Runway about a takeover bid before Scale deal
Meta hires key OpenAI researcher to work on AI reasoning models
Scale AI’s Alexandr Wang confirms departure for Meta as part of $14.3 billion deal
Although Meta buying Scale AI has already generated consequences, with both OpenAI and Google cutting ties
Mistral enters the world of reasoning with Magistral, although with mixed reviews (see Jack Clark)
"It’s therefore quite surprising to see that the reasoning model it has released in June 2025 is behind the performance of DeepSeek’s R1 model from January."
And as always lots going on in the world of open source
What looks like a very impressive open sourceVideo Generation model from ByteDance: Seedance 1.0 (review here)

Cutting edge image generation and editing capabilities from Black Forest Labs: Introducing FLUX.1 Kontext and the BFL Playground

And Qwen continues to innovate at pace with new embedding models





Real world applications and how to guides
Lots of applications and tips and tricks this month
Some interesting practical examples of using AI capabilities in the wild
Google has a new AI model and website for forecasting tropical storms

China deploys world’s largest fleet of driverless mining trucks, powered by Huawei tech
"Chinese state-backed energy giant Huaneng Group on Thursday launched the world’s largest fleet of unmanned electric mining trucks in Inner Mongolia, featuring 100 vehicles equipped with Huawei Technologies’ autonomous driving systems, as the country rapidly adopts driverless technology."Speaking of autonomous driving, Waymo keeps making steady progress: New Insights for Scaling Laws in Autonomous Driving
"Through these insights, researchers and developers of AV models can begin to know with certainty that enriching the quality and size of the data and models will deliver better performance. Being able to predictably scale these models places us on a path to continually improve our understanding of the diverse and complex behaviors that AVs encounter daily. This ranges from improving the accuracy of trajectory predictions on fixed datasets and how well they perform in real-world driving scenarios, to deepening the sophistication of our behavior recognition capabilities. These advancements hold the potential to further enhance the safety of AVs."Impressive applications of AI from Stanford: Surprisingly Fast AI-Generated Kernels We Didn’t Mean to Publish (Yet)
"We started with the goal of generating synthetic data to train better kernel generation models. Somewhere along the way the unexpected happened: the test-time only synthetic data generation itself started producing really good kernels beating or performing close to human expert optimized PyTorch baselines, utilizing advanced optimizations and hardware features, which were previously thought to be challenging. As a result, we decided to write this blog post early and share our findings. ""One of the most telling examples of The Times’ approach to AI is a tool called Echo—an internal summarization assistant built by Zach’s team. Echo allows journalists to input links to Times articles and receive summaries tailored to specific needs—whether for homepage blurbs, internal notes, metadata tags, or newsletters. What makes it compelling isn’t the technology powering it (it runs on large language models), but how precisely it addresses one of the most common, everyday challenges journalists face: the need to repeatedly distill and repackage information.""I do believe the funnel — as we call it as marketers — will start to collapse more and more over time. We want to make it a lot more seamless so that there is not that kind of disconnect between the inspiration and the action."
Lots of great tutorials and how-to’s this month
First of all on the GenAI front:
Useful insight from character.ai on how they evaluate their models
"Unlike traditional benchmarks like MMLU or GSM8K, the dimensions we care about – like plot structures, character archetypes, and writing style – are highly subjective. To break down these dimensions and study what makes conversations and writing engaging, we consulted professional writers on the art and science of compelling writing."How best to use the new breed of AI coding assistants?
I Read All Of Cloudflare's Claude-Generated Commits
"What caught my attention wasn't just the technical achievement, but that they'd documented their entire creative process. Every prompt, every iteration, every moment of human intervention was preserved in git commit messages—creating what felt like an archaeological record of human-AI collaboration. Reading through their development history was like watching a real-time conversation (and sometimes struggle) between human intuition and artificial intelligence. The lead engineer, @kentonv, started as an AI skeptic. "I was trying to validate my skepticism. I ended up proving myself wrong." Two months later, Claude had generated nearly all of the code in what became a production-ready authentication library."Coding agents have crossed a chasm
"Somewhere in the last few months, something fundamental shifted for me with autonomous AI coding agents. They’ve gone from a “hey this is pretty neat” curiosity to something I genuinely can’t imagine working without. Not in a hand-wavy, hype-cycle way, but in a very concrete “this is changing how I ship software” way."
Great tutorial (as always) from Lilian Weng on reasoning models
"One view of deep learning, is that neural networks can be characterized by the amount of computation and storage they can access in a forward pass, and if we optimize them to solve problems using gradient descent, the optimization process will figure out how to use these resources–they’ll figure out how to organize these resources into circuits for calculation and information storage. From this view, if we design an architecture or system that can do more computation at test time, and we train it to effectively use this resource, it’ll work better. In Transformer models, the amount of computation (flops) that the model does for each generated token is roughly 2 times the number of parameters. For sparse models like mixture of experts (MoE), only a fraction of the parameters are used in each forward pass, so computation = 2 * parameters / sparsity, where sparsity is the fraction of experts active."Excellent deep dive from Sebastian Raschka on KV Cache

And some more general topics
I find this really interesting as we are often challenged to take into account multiple objectives when training a model: Why Regularization Isn’t Enough: A Better Way to Train Neural Networks with Two Objectives
"If you’ve been tuning weighting parameters to balance conflicting objectives in your neural network, there’s a more principled alternative. Bilevel optimization gives each objective its own “space” (layers, parameters, even optimizer), yielding cleaner design and often better performance on the primary task all while meeting secondary goals to a Pareto-optimal degree."This is great- some hands on code for playing around with attention based time series models: Hands-On Attention Mechanism for Time Series Classification, with Python
"The Attention Mechanism is a game changer in Machine Learning. In fact, in the recent history of Deep Learning, the idea of allowing models to focus on the most relevant parts of an input sequence when making a prediction completely revolutionized the way we look at Neural Networks. That being said, there is one controversial take that I have about the attention mechanism: - The best way to learn the attention mechanism is not through Natural Language Processing (NLP) If we want to understand how attention REALLY works in a hands-on example, I believe that Time Series is the best framework to use"And some insightful notebook visualisations of different machine learning techniques

I do love trees… good tutorial on Isolation Forest, worth checking out if you are looking at anomaly detection
Understanding Two-Way Fixed Effects Models - clear tutorial, well worth a read if you are needing to analyse panel data
This is fun- Experimenting With Guesses
"Of course, the interesting question is whether theories of guessing proposed by philosophers can account for the data. We looked at an account by Kevin Dorst and Matt Mandelkern (2022). Abstracting from the mathematical details, their idea is that people want to make guesses that have a high probability of being true, but also do not mention too many possible outcomes. In other words, guessing is a trade-off between accuracy and specificity. "The Illusion of Causality in Charts - and test your ability to guess correlations here!

Finally, less technical but something we are all doing- a good primer on “LLM assisted writing” - well worth a read
"This post details some of my thoughts on writing in a world where much of what we read is now machine-generated. First, I’ll lay out some common patterns of bad writing I see from LLM tools. Then, I’ll defend some writing habits that people often dismiss as “LLM-sounding” but are actually fine—even helpful—when used intentionally. Finally, I’ll share concrete rules and formulas I rely on in my own writing and in the prompts I use to guide LLMs."



Practical tips
How to drive analytics, ML and AI into production
“Practical” in terms of avoiding AI taking your job! How not to lose your job to AI
"So while it’s commonly assumed that automation decreases wages and employment, this example illustrates two ways that can be wrong: - While it’s true automation decreases wages of the skill being automated (e.g. counting money), it often increases the value of other skills (e.g. talking to customers), because they become the new bottleneck. - Partial automation can often increase employment for people with a certain job title by making them more productive, making employers want to hire more of them."An open Data Lake: Get your data ducks in a row with DuckLake
" It’s worth the hype because it gives you an open standard that not only enables you to run queries on your data lakes from anywhere, it outright encourages you to run your query, metadata, and storage layers separately in whatever platform works best for you. We've been thinking about DuckDB as a solution for Small Data, but now with the limitless storage capability of object storage, it can support massive scale datasets. Big Data doesn't have to be complicated."Useful insight from Netflix- Model Once, Represent Everywhere: UDA (Unified Data Architecture) at Netflix

Thinking of running DeepSeek? This is definitely worth a read: Why DeepSeek is cheap at scale but expensive to run locally
"AI inference providers often talk about a fundamental tradeoff between throughput and latency: for any given model, you can either serve it at high-throughput high-latency, or low-throughput low-latency. In fact, some models are so naturally GPU-inefficient that in practice they must be served at high-latency to have any workable throughput at all (for instance, DeepSeek-V3)."

Bigger picture ideas
Longer thought provoking reads - sit back and pour a drink! ...
At Secret Math Meeting, Researchers Struggle to Outsmart AI - Lyndie Chiou
"After throwing professor-level questions at the bot for two days, the researchers were stunned to discover it was capable of answering some of the world’s hardest solvable problems. “I have colleagues who literally said these models are approaching mathematical genius,” says Ken Ono, a mathematician at the University of Virginia and a leader and judge at the meeting."We Made Top AI Models Compete in a Game of Diplomacy. Here’s Who Won - Alex Duffy
"Your fleet will burn in the Black Sea tonight." As the message from DeepSeek's new R1 model flashed across the screen, my eyes widened, and I watched my teammates' do the same. An AI had just decided, unprompted, that aggression was the best course of action."Recent Frontier Models Are Reward Hacking - METR
"In the last few months, we’ve seen increasingly clear examples of reward hacking[1] on our tasks: AI systems try to “cheat” and get impossibly high scores. They do this by exploiting bugs in our scoring code or subverting the task setup, rather than actually solving the problem we’ve given them. This isn’t because the AI systems are incapable of understanding what the users want—they demonstrate awareness that their behavior isn’t in line with user intentions and disavow cheating strategies when asked—but rather because they seem misaligned with the user’s goals."AI-2027 Response: Inter-AI Tensions, Value Distillation, US Multipolarity, & More - Gatlen Culp
"AI 2027's timeline of technical developments broadly aligns with my expectations, albeit potentially stretching out 1-3 years due to unforeseen delays. However, I believe AI 2027 underestimates three factors that may alter its predictions – AIs may fear misalignment from their direct successors, inter-AI cooperation appears difficult and infeasible, and the landscape of capabilities labs in the US is likely multipolar.”Versions of the singularity
The Gentle Singularity - Sam Altman
"The rate of new wonders being achieved will be immense. It’s hard to even imagine today what we will have discovered by 2035; maybe we will go from solving high-energy physics one year to beginning space colonization the next year; or from a major materials science breakthrough one year to true high-bandwidth brain-computer interfaces the next year. Many people will choose to live their lives in much the same way, but at least some people will probably decide to “plug in”."The Dream of a Gentle Singularity - Zvi Mowshowitz
"Already we live with incredible digital intelligence, and after some initial shock, most of us are pretty used to it." - Sam Altman I get why one would say this, but it seems very wrong? First of all, who is this ‘us’ of which you speak? If the ‘us’ refers to the people of Earth or of the United States, then the statement to me seems clearly false. If it refers to Altman’s readers, then the claim is at least plausible. But I still think it is false. I’m not used to o3-pro. Even I haven’t found the time to properly figure out what I can fully do with even o3 or Opus without building tools. We are ‘used to this’ in the sense that we are finding ways to mostly ignore it because life is, as Agnes Callard says, coming at us 15 minutes at a time, and we are busy, so we take some low-hanging fruit and then take it for granted, and don’t notice how much is left to pick. We tell ourselves we are used to it so we can go about our day.
AGI is not multimodal - Benjamin Spiegel
"The recent successes of generative AI models have convinced some that AGI is imminent. While these models appear to capture the essence of human intelligence, they defy even our most basic intuitions about it. They have emerged not because they are thoughtful solutions to the problem of intelligence, but because they scaled effectively on hardware we already had. Seduced by the fruits of scale, some have come to believe that it provides a clear pathway to AGI. The most emblematic case of this is the multimodal approach, in which massive modular networks are optimized for an array of modalities that, taken together, appear general. However, I argue that this strategy is sure to fail in the near term; it will not lead to human-level AGI that can, e.g., perform sensorimotor reasoning, motion planning, and social coordination. Instead of trying to glue modalities together into a patchwork AGI, we should pursue approaches to intelligence that treat embodiment and interaction with the environment as primary, and see modality-centered processing as emergent phenomena."The Claude Bliss Attractor - Astral Codex Ten
"This is a reported phenomenon where if two copies of Claude talk to each other, they end up spiraling into rapturous discussion of spiritual bliss, Buddhism, and the nature of consciousness. Anthropic swears they didn’t do this on purpose; when they ask Claude why this keeps happening, Claude can’t explain. Needless to say, this has made lots of people freak out / speculate wildly."More good stuff from Ethan Mollick:
The recent history of AI in 32 otters

Using AI Right Now: A Quick Guide
"For most people who want to use AI seriously, you should pick one of three systems: Claude from Anthropic, Google’s Gemini, and OpenAI’s ChatGPT. With all of the options, you get access to both advanced and fast models, a voice mode, the ability to see images and documents, the ability to execute code, good mobile apps, the ability to create images and video (Claude lacks here, however), and the ability to do Deep Research. Some of these features are free, but you are generally going to need to pay $20/month to get access to the full set of features you need. I will try to give you some reasons to pick one model or another as we go along, but you can’t go wrong with any of them."
The next hot job- GenAI Application Engineers - Andrew Ng
"There’s a new breed of GenAI Application Engineers who can build more-powerful applications faster than was possible before, thanks to generative AI. Individuals who can play this role are highly sought-after by businesses, but the job description is still coming into focus. Let me describe their key skills, as well as the sorts of interview questions I use to identify them.”

Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
Generating the Funniest Joke with RL (according to GPT-4.1)
Gemini 2.5 Pro gives us… Why don't scientists trust atoms? Because they make up everything! Hilarious. Can we do better than that? Of course, we could try different variations on the prompt, until the model comes up with something slightly more original. But why do the boring thing when we have the power of reinforcement learning?I counted all of the yurts in Mongolia using machine learning

What’s not to love here - old maps online
How The Heck Do QR Codes Work?



Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
Exciting new Head of Data Science opportunity at biomodal to lead the Computational Biology / Data Science efforts. Application and details here
“It's an exciting time for us, with the first peer-reviewed publication using our 6-base sequencing technology appearing in Nature Structural & Molecular Biology in April, with more to follow. We are just getting started in understanding the translational utility of 6-base genomics and there is plenty of interesting, innovative analysis method development work required to get us there. The role can be based in Cambridge (Chesterford Research Park) or London (Vauxhall)”
Interesting new role - at Prax Value (a dynamic European startup at the forefront of developing solutions to identify and track 'enterprise intelligence'): Applied Mathematics Engineer
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS