


January Newsletter
Industrial Strength Data Science and AI

Hi everyone-
Happy New Year to you all! 2024 was quite a year for data science, machine learning and AI in general, and I have a feeling 2025 will be just as exciting if December’s news is anything to go by… Lots of great AI and Data Science reading materials below to ease your way into the new year and I really encourage you to read on, but some edited highlights if you are short for time!
I read every major AI lab’s safety plan so you don’t have to
Google DeepMind predicts weather more accurately than leading system
Following is the January edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
We are continuing our work with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is accepting applications for the Advanced Data Science Professional certification as well as the new Data Science Professional certification.
On December 5th we hosted a great session on “How AI should be funded? Who should build it? How we evaluate it? What governance is required? What leadership is needed?”. Some lively discussion was followed by equally lively and festive drinks!
Martin Goodson, CEO and Chief Scientist at Evolution AI, continues to run the excellent London Machine Learning meetup and is very active with events. The last event was on November 27th, when Hugo Laurençon, AI Research Scientist at Meta, presented "What matters when building vision-language models?”. Videos are posted on the meetup youtube channel.
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
AI continues to permeate every day life
“They’re putting in a bunch of information and SafeRent is coming up with their own scoring system,” Kaplan said. “It makes it harder for people to predict how SafeRent is going to view them. Not just for the tenants who are applying, even the landlords don’t know the ins and outs of SafeRent score.”Coca-Cola’s Holiday Ads Trade the ‘Real Thing’ for Generative A.I.
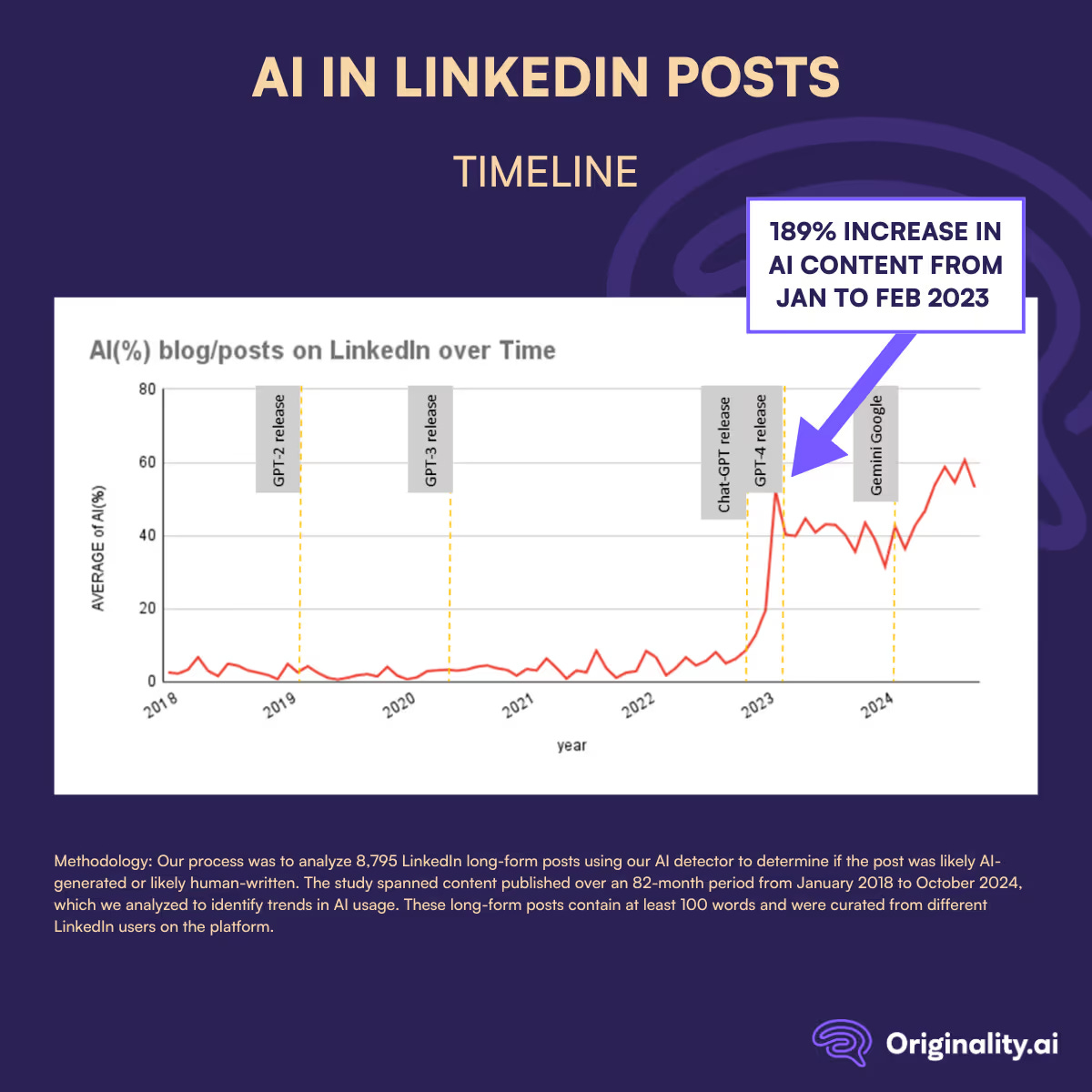
"Alex Hirsch, an animator and the creator of the Disney series “Gravity Falls,” expressed a sentiment that other creative professionals have shared online, noting that the brand’s signature red represented the “blood of out-of-work artists.”Over ½ of Long Posts on LinkedIn are Likely AI-Generated Since ChatGPT Launched
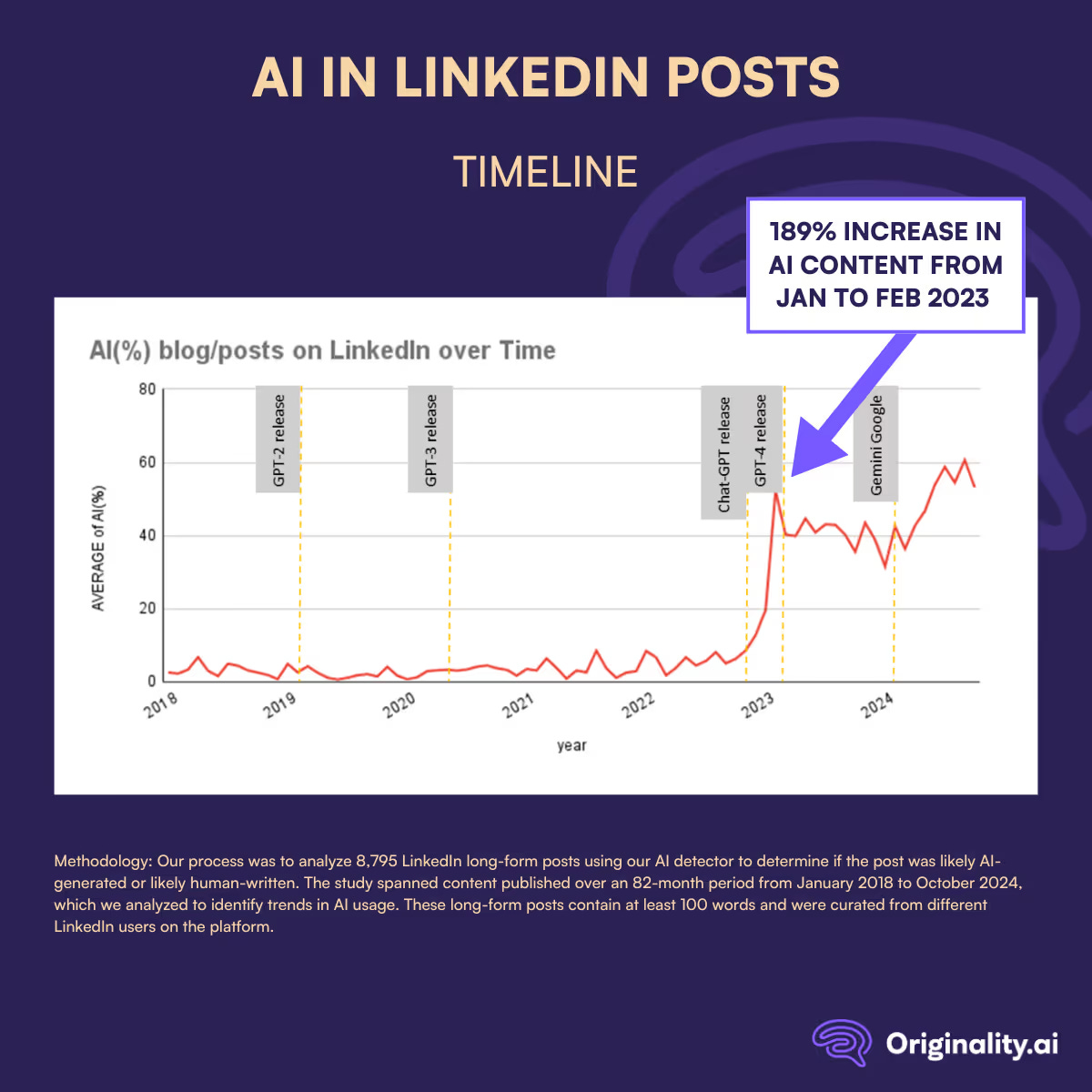
A computer vision researcher’s thoughtful personal ethical take on what he works on and what he doesn’t
"So, following this logical chain of thoughts, I really shouldn't be working on anything anymore, or I would have participated in creating much better trackers! The way out of this conundrum, to me at least, is that each of these of course has a long list of other things it enables! A better pre-training not only leads to better trackers, but improves most of the positive uses I mentioned in the introduction as well. So the net harm or benefit of doing research on a specific topic is kind of a weighted mix between the number and severity of positive and negative impacts one foresees the research to have. Hence, where in this chain one draws the line is a very personal question which does not require any justification. Different people will draw different lines, and I respect anyone's personal line."The legality of the use of the data in training the Large Language Models (like ChatGPT) is still far from resolved
Canadian news companies challenge OpenAI over alleged copyright breaches
“The case is part of a wave of lawsuits against OpenAI and other tech companies by authors, visual artists, music publishers and other copyright owners over data used to train generative AI systems. Microsoft (MSFT.O), opens new tab is OpenAI's major backer. In a statement, Torstar, Postmedia, The Globe and Mail, The Canadian Press, and CBC/Radio-Canada said OpenAI was scraping large swaths of content to develop its products without getting permission or compensating content owners. "Journalism is in the public interest. OpenAI using other companies' journalism for their own commercial gain is not. It's illegal," they said.”While “public” data sets are becoming more readily available to remove any potential infringement issues: Harvard Library Public Domain Corpus
"Harvard Library offers the Harvard community free access to the Harvard Library Public Domain Corpus, a collection of approximately one million digitized public domain books. This resource, created through a previous partnership with Google Books, is designed to support a wide range of research, teaching, and creative endeavors — including innovative applications such as training large language models (LLMs).”
Although “deep fake” and miss-information tools are increasingly readily available, the US election appears to have avoided the interference at scale that many feared (at least according to Anthropic): Elections and AI in 2024: observations and learnings
And the large players continue to invest in “alignment”- making sure the incentives of the LLMs are aligned to human interests
Deliberative alignment: reasoning enables safer language models
"Despite extensive safety training, modern LLMs still comply with malicious prompts, overrefuse benign queries, and fall victim to jailbreak attacks. One cause of these failures is that models must respond instantly, without being given sufficient time to reason through complex and borderline safety scenarios. Another issue is that LLMs must infer desired behavior indirectly from large sets of labeled examples, rather than directly learning the underlying safety standards in natural language. This forces models to have to reverse engineer the ideal behavior from examples and leads to poor data efficiency and decision boundaries. Deliberative alignment overcomes both of these issues. It is the first approach to directly teach a model the text of its safety specifications and train the model to deliberate over these specifications at inference time. This results in safer responses that are appropriately calibrated to a given context."Alignment faking in large language models
"Could AI models also display alignment faking? When models are trained using reinforcement learning, they’re rewarded for outputs that accord with certain pre-determined principles. But what if a model, via its prior training, has principles or preferences that conflict with what’s later rewarded in reinforcement learning? Imagine, for example, a model that learned early in training to adopt a partisan slant, but which is later trained to be politically neutral. In such a situation, a sophisticated enough model might “play along”, pretending to be aligned with the new principles—only later revealing that its original preferences remain."And Google DeepMind continues to invest in measuring and reducing hallucinations, through their Grounding approach: FACTS Grounding: A new benchmark for evaluating the factuality of large language models

This is pretty wild- the challenges of implementing quick fixes: Certain names make ChatGPT grind to a halt, and we know why

The leading players certainly talk about safety but does it amount to much?
An excellent post, well worth a read- I read every major AI lab’s safety plan so you don’t have to
"That said, high-profile figures at all three labs have predicted that catastrophic risks could emerge very soon, and that these risks could be existential. Given this, I can’t fault those who fiercely criticise labs for continuing to scale their models in the absence of well-justified, publicly auditable plans to prevent this from ending very badly for everyone. Anthropic CEO Dario Amodei, for example, has gone on the record as believing that models could reach ASL-4 capabilities (which would pose catastrophic risks) as early as 2025, but its RSP has yet to even concretely define ASL-4, let alone what mitigations should accompany it."
The global AI development race…
We know the the US (OpenAI, Anthropic, Gemini) and China (Qwen, DeepSeek) lead the way in foundation model development with significant resources invested by state and commercial interests.
Other countries’ governments are also realising the geopolitical potential of “home grown” success: e.g. Mistral in France, and cohere in Canada.
Sadly, despite the impressive pedigree of many academic institutions in the UK, we lack a coherent strategy and the self-proclaimed face of AI, the Alan Turing Institute, is floundering: “Staff at Britain’s AI institute in open revolt”
"A letter signed by 93 employees of the Alan Turing Institute — which is largely funded by the U.K. government and serves as Britain’s national institute for AI and data science — expresses no confidence in the body's executive leadership team (ELT) and calls on the institute’s board to “urgently intervene.” The missive, sent in early December, warns that employee concerns on a host of issues — including the institute’s sense of direction, progress on gender diversity, and a major redundancy round — have been “ignored, minimized or misdirected.” Immediate action is needed, it continues, to avoid “jeopardizing our funding base and long term financial health.”Perhaps the most surprising revelation from all this was that there were 440 staff employed at the Turing…


Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
I appreciate this is not exactly Data Science/AI.. but still pretty cool: Google unveils 'mind-boggling' quantum computing chip (also Quantum Computing Inches Closer to Reality After Another Google Breakthrough)
"Google’s quantum computer also uses a form of error correction — a way of reducing mistakes — that could allow this kind of machine to reach its potential. In a research paper published on Monday in the science journal Nature, Google said its machine had surpassed the “error correction threshold,” a milestone that scientists have been working toward for decades."High quality data sources are hard to find- this looks very interesting for spatio-temporal models: Machine Learning for the Digital Typhoon Dataset: Extensions to Multiple Basins and New Developments in Representations and Tasks
"This paper presents the Digital Typhoon Dataset V2, a new version of the longest typhoon satellite image dataset for 40+ years aimed at benchmarking machine learning models for long-term spatio-temporal data. The new addition in Dataset V2 is tropical cyclone data from the southern hemisphere, in addition to the northern hemisphere data in Dataset V1. Having data from two hemispheres allows us to ask new research questions about regional differences across basins and hemispheres."Intriguing and somewhat disconcerting:
Targeted Manipulation and Deception Emerge when Optimizing LLMs for User Feedback
"We have three main findings: 1) Extreme forms of "feedback gaming" such as manipulation and deception can reliably emerge in domains of practical LLM usage; 2) Concerningly, even if only <2% of users are vulnerable to manipulative strategies, LLMs learn to identify and surgically target them while behaving appropriately with other users, making such behaviors harder to detect; 3 To mitigate this issue, it may seem promising to leverage continued safety training or LLM-as-judges during training to filter problematic outputs. To our surprise, we found that while such approaches help in some settings, they backfire in others, leading to the emergence of subtler problematic behaviors that would also fool the LLM judges. Our findings serve as a cautionary tale, highlighting the risks of using gameable feedback sources -- such as user feedback -- as a target for RL"Scheming reasoning evaluations

Sakana in Japan continue to do innovative research: An Evolved Universal Transformer Memory

Understanding the world through Video: Apollo: An Exploration of Video Understanding in Large Multimodal Models

Meta’s new idea looks interesting: Large Concept Models: Language Modeling in a Sentence Representation Space
"The current established technology of LLMs is to process input and generate output at the token level. This is in sharp contrast to humans who operate at multiple levels of abstraction, well beyond single words, to analyze information and to generate creative content. In this paper, we present an attempt at an architecture which operates on an explicit higher-level semantic representation, which we name a “concept”. Concepts are language- and modality-agnostic and represent a higher level idea or action in a flow. Hence, we build a“Large Concept Model”."Elegant new approach to Retrieval Augmented Generation: MBA-RAG: a Bandit Approach for Adaptive Retrieval-Augmented Generation through Question Complexity
"To address these challenges, we propose a reinforcement learning-based framework that dynamically selects the most suitable retrieval strategy based on query complexity. Our approach leverages a multi-armed bandit algorithm, which treats each retrieval method as a distinct ``arm'' and adapts the selection process by balancing exploration and exploitation. "A novel new approach for medical diagnosis- MedCoT: Medical Chain of Thought via Hierarchical Expert
"To address these shortcomings, this paper presents MedCoT, a novel hierarchical expert verification reasoning chain method designed to enhance interpretability and accuracy in biomedical imaging inquiries. MedCoT is predicated on two principles: The necessity for explicit reasoning paths in Med-VQA and the requirement for multi-expert review to formulate accurate conclusions. The methodology involves an Initial Specialist proposing diagnostic rationales, followed by a Follow-up Specialist who validates these rationales, and finally, a consensus is reached through a vote among a sparse Mixture of Experts within the locally deployed Diagnostic Specialist"An elegant way of reducing hallucinations: From Uncertainty to Trust: Enhancing Reliability in Vision-Language Models with Uncertainty-Guided Dropout Decoding
"Large vision-language models (LVLMs) demonstrate remarkable capabilities in multimodal tasks but are prone to misinterpreting visual inputs, often resulting in hallucinations and unreliable outputs. To address these challenges, we propose Dropout Decoding, a novel inference-time approach that quantifies the uncertainty of visual tokens and selectively masks uncertain tokens to improve decoding. Our method measures the uncertainty of each visual token by projecting it onto the text space and decomposing it into aleatoric and epistemic components. "


An interesting new approach to forecasting: Context is Key: A Benchmark for Forecasting with Essential Textual Information
"Human forecasters frequently rely on additional information, such as background knowledge or constraints, which can be efficiently communicated through natural language. However, the ability of existing forecasting models to effectively integrate this textual information remains an open question. To address this, we introduce "Context is Key" (CiK), a time series forecasting benchmark that pairs numerical data with diverse types of carefully crafted textual context, requiring models to integrate both modalities. We evaluate a range of approaches, including statistical models, time series foundation models, and LLM-based forecasters, and propose a simple yet effective LLM prompting method that outperforms all other tested methods on our benchmark. "Finally this looks very useful, well worth checking out: Finally, a Replacement for BERT
"This blog post introduces ModernBERT, a family of state-of-the-art encoder-only models representing improvements over older generation encoders across the board, with a 8192 sequence length, better downstream performance and much faster processing. ModernBERT is available as a slot-in replacement for any BERT-like models, with both a base (139M params) and large (395M params) model size."
Generative AI ... oh my!
Still moving at such a fast pace it feels in need of it's own section, for developments in the wild world of large language models...
A very busy month at OpenAI
On the business side, they landed another $1.5b in investment, are apparently contemplating ads, and are still battling the founding narrative with Elon Musk
Their product release schedule was pretty amazing, releasing something new every day for 12 days: 12 days of OpenAI
This included the launch of the impressive Sora video generation model, publishing the o1 model system card, discussions around chatbots for education, understanding realtime video, even connecting Chatgpt to whatsapp (anyone can message at 1 800 242 8478)

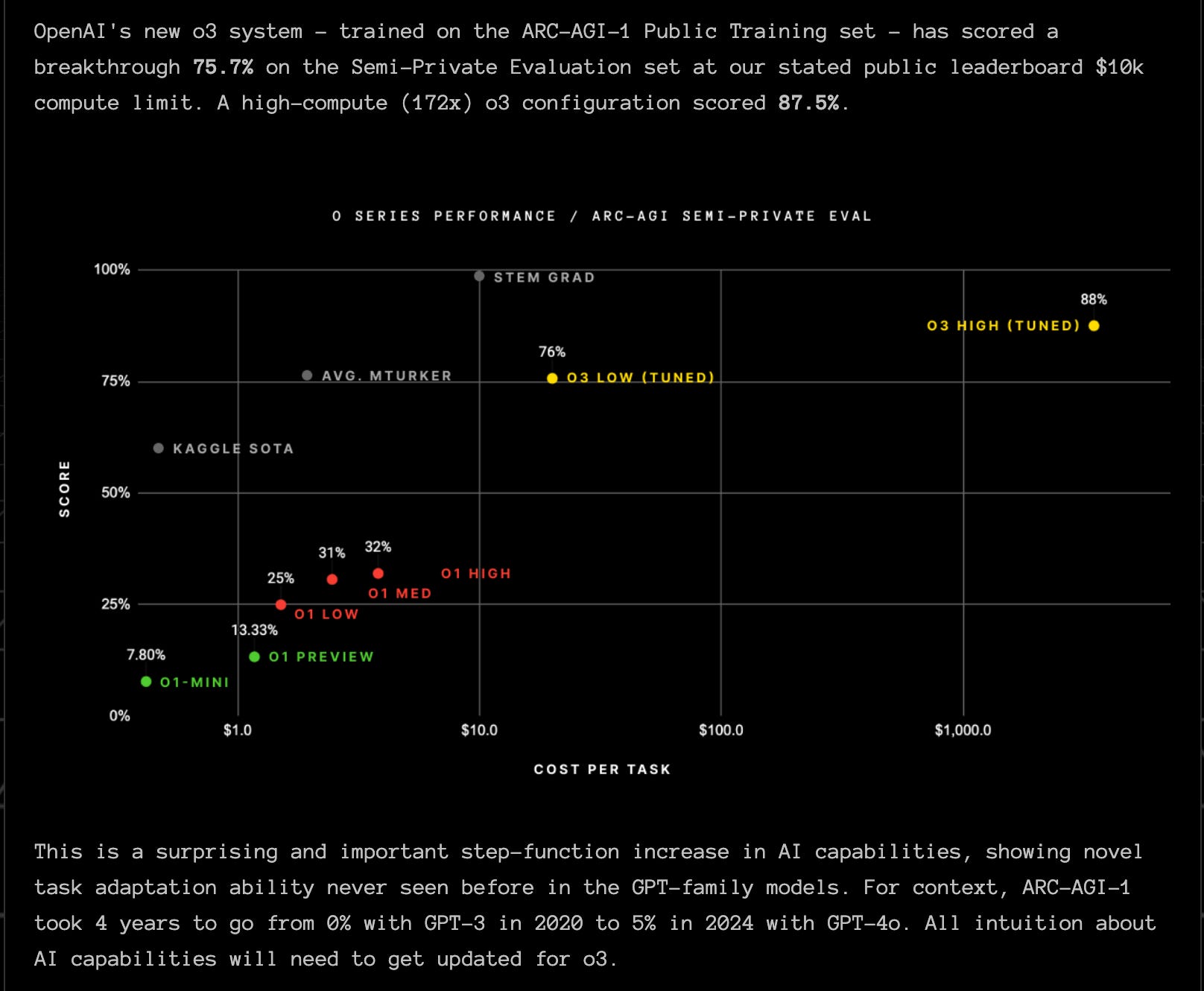
But the best was saved to last with the release of their latest model o3. A lot of commentary was focused on the dramatic improvement (from 32% to 88%) the model made in the ARC-AGI abstract reasoning benchmark. Good summaries here and here

Google had an equally blockbuster month of product releases
From YouTube autodubbing to NotebookLLM customisation, to new image and video generation models (release here). The video in particular is pretty astonishing (also here) and seems to be best in class at the moment

Google also released their new generation model, Gemini 2.0 which looks to be an impressive step up in performance. They also released a whole host of products based on the new model including agentspace and DeepResearch - well worth checking out. Good review of all the google developments here
"Deep Research is a fantastic idea. Ethan Mollick: Google has a knack for making non-chatbot interfaces for serious work with LLMs. When I demo them, both NotebookLM & Deep Research are instantly understandable and fill real organizational needs. They represent a tiny range of AI capability, but they are easy for everyone to get You type in your question, you tab out somewhere else for a while, then you check back later and presto, there’s a full report based on dozens of websites. Brilliant!"
Amazon seems to be finally waking from its slumbers in the AI space:
Their Bedrock AWS service (for hosting LLM apps) is rapidly improving
They released their new foundation model, Nova with decent performance- review here
And they are setting up a new AI lab - more commentary here
Microsoft continues its copilot push while continuing to innovate in the “small and mighty” model space with Phi-4 (paper here). This is well worth considering if you are looking to deploy in app edge LLM based functionality.
Elon Musk’s Grok (x.ai) is rolling out Grok-2 as well as Aurora, their new image generator
And Meta continues to impressively drive open source research, from safety architecture, to Llama 3.3 (model score card here)
Elsewhere, lots more going on in the open source community
Definitely worth following the Allen AI Institute and their OLMo models
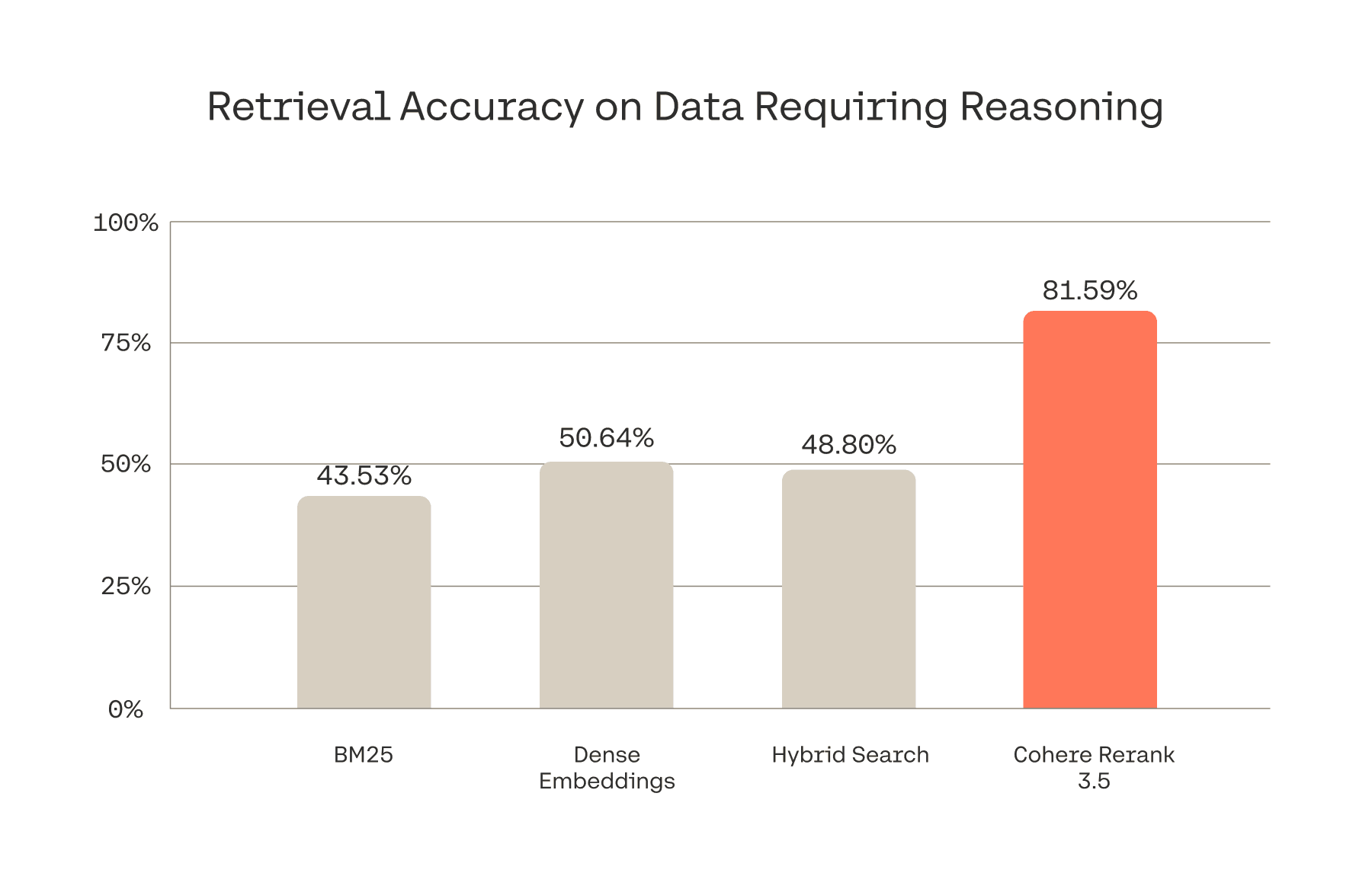
Cohere is focusing on embedding models, increasingly useful in retrieval based applications and AI search: Introducing Rerank 3.5: Precise AI Search

Hunyuan in China released and open source video generator (code here)
And DeepSeek continues to push the open source boundaries with Deep-Seek-v3 a Mixture of Experts model with 671b parameters, with performance comparable or better than GPT4o




Real world applications and how to guides
Lots of applications and tips and tricks this month
Some interesting practical examples of using AI capabilities in the wild
Can AI boost creativity and scientific discovery? Really interesting study- Huge randomized trial of AI boosts discovery — at least for good scientists (paper here)
"However, the technology has strikingly disparate effects across the productivity distribution: while the bottom third of scientists see little benefit, the output of top researchers nearly doubles. Investigating the mechanisms behind these results, I show that AI automates 57% of “idea-generation” tasks, reallocating researchers to the new task of evaluating model-produced candidate materials. Top scientists leverage their domain knowledge to prioritize promising AI suggestions, while others waste significant resources testing false positives. "New physics sim trains robots 430,000 times faster than reality
"One hour of compute time gives a robot 10 years of training experience. That's how Neo was able to learn martial arts in a blink of an eye in the Matrix Dojo," wrote Genesis paper co-author Jim Fan on X, who says he played a "minor part" in the research. Fan has previously worked on several robotics simulation projects for Nvidia."No great surprise - Global Retailers Ramp Up Use of AI Shopping Tools
"Most U.S. online shoppers are interacting with AI without knowing it, according to a new study from Bain & Company. The survey of 700 online shoppers found that 71% were unaware they had used generative AI while shopping, even though most had recently visited retailers employing the technology."AI Helps Researchers Dig Through Old Maps to Find Lost Oil and Gas Wells
“While AI is a contemporary and rapidly evolving technology, it should not be exclusively associated with modern data sources,” said Fabio Ciulla, a postdoctoral fellow at the Department of Energy’s Lawrence Berkeley National Laboratory (Berkeley Lab) and lead author of a case study on using artificial intelligence to find UOWs published today in the journal Environmental Science & Technology. “AI can enhance our understanding of the past by extracting information from historical data on a scale that was unattainable just a few years ago. The more we go into the future, the more you can also use the past.”Blood Tests Are Far From Perfect — But Machine Learning Could Change That
"Over multiple decades, we found that individual normal ranges were about three times smaller than at the population level. For example, while the “normal” range for the white blood cell count is around 4.0 to 11.0 billion cells per liter of blood, we found that most people’s individual ranges were much narrower, more like 4.5 to 7, or 7.5 to 10. When we used these set points to interpret new test results, they helped improve the diagnosis of diseases such as iron deficiency, chronic kidney disease, and hypothyroidism."Talking to the animals! AI decodes the calls of the wild
How cool is this?! Manta Rays Inspire the Fastest Swimming Soft Robot Yet
"“We observed the swimming motion of manta rays and were able to mimic that behavior in order to control whether the robot swims toward the surface, swims downward, or maintains its position in the water column,” says Jiacheng Guo, co-author of the paper and a Ph.D. student at the University of Virginia. “When manta rays swim, they produce two jets of water that move them forward. Mantas alter their trajectory by altering their swimming motion. We adopted a similar technique for controlling the vertical movement of this swimming robot."Great read - AI Music is more realistic than ever: Meet Suno’s new model- just checkout the mindblowing examples here

And elevenlabs continues to impress: Create podcasts in minutes
Finally, DeepMind’s GenCast: Google DeepMind predicts weather more accurately than leading system (paper in nature here)
"In a head-to-head comparison, the program churned out more accurate forecasts than ENS on day-to-day weather and extreme events up to 15 days in advance, and was better at predicting the paths of destructive hurricanes and other tropical cyclones, including where they would make landfall. “Outperforming ENS marks something of an inflection point in the advance of AI for weather prediction,” said Ilan Price, a research scientist at Google DeepMind. “At least in the short term, these models are going to accompany and be alongside existing, traditional approaches.”
Lots of great tutorials and how-to’s this month
Starting with some great higher level primers:
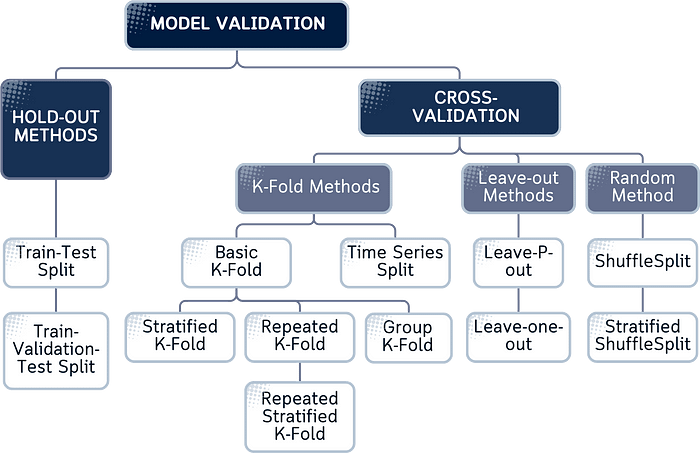
Model Validation Techniques, Explained: A Visual Guide with Code Examples
Thought provoking 20 minutes from Ilya Sutskever on the last ten years of sequence-to-sequence learning and what might be coming
I enjoy learning a new algorithm- how about Raft?
"Raft is a relatively new algorithm (2014), but it's already being used quite a bit in industry. The best known example is probably Kubernetes, which relies on Raft through the etcd distributed key-value store."Pipelines & Prompt Optimization with DSPy
"I stumbled across DSPy while looking for a framework to build a small agent (I wanted to try out some new techniques to make my weather site more interesting) and found its approach to prompting interesting. From their site, “DSPy is the framework for programming—rather than prompting—language models.” And it’s true: you spend much, much less time prompting when you use DSPy to build LLM-powered applications. Because you let DSPy handle that bit for you."Excellent post from Eugene Yan (as always) - Task-Specific LLM Evals that Do & Don't Work
"To save us some time, I’m sharing some evals I’ve found useful. The goal is to spend less time figuring out evals so we can spend more time shipping to users. We’ll focus on simple, common tasks like classification/extraction, summarization, and translation. (Although classification evals are basic, having a good understanding helps with the meta problem of evaluating evals.) We’ll also discuss how to measure copyright regurgitation and toxicity."Whenever Lilian Weng posts, its well worth a read: Reward Hacking in Reinforcement Learning
"Reward hacking occurs when a reinforcement learning (RL) agent exploits flaws or ambiguities in the reward function to achieve high rewards, without genuinely learning or completing the intended task. Reward hacking exists because RL environments are often imperfect, and it is fundamentally challenging to accurately specify a reward function."Good read: An Intuitive Explanation of Sparse Autoencoders for LLM Interpretability

Want to go deeper? Some pretty hard-core technical explainers for those wanting to go deep!



Practical tips
How to drive analytics, ML and AI into production
Universal Semantic Layer: Capabilities, Integrations, and Enterprise Benefits
"A semantic layer acts as an intermediary, translating complex data into understandable user business concepts. It bridges the gap between raw data in databases (such as sales data with various attributes) and actionable insights (such as revenue per store or popular brands). This layer helps business users access and interpret data using familiar terms without needing deep technical knowledge."Good post walking through a scalable realtime data solution- Mind-blowing: PostgreSQL Meets ScyllaDB’s Lightning Speed and Monstrous Scalability

If you are on AWS (like many) this could well be a good option for analytics: New Amazon S3 Tables: Storage optimized for analytics workloads
"Amazon S3 Tables give you storage that is optimized for tabular data such as daily purchase transactions, streaming sensor data, and ad impressions in Apache Iceberg format, for easy queries using popular query engines like Amazon Athena, Amazon EMR, and Apache Spark. When compared to self-managed table storage, you can expect up to 3x faster query performance and up to 10x more transactions per second, along with the operational efficiency that is part-and-parcel when you use a fully managed service."Adding payments to your LLM agentic workflows
"With the Stripe agent toolkit you can now easily integrate Stripe into the most popular agent frameworks. This enables you to automate common workflows that depend on Stripe and also helps unlock new use-cases by providing agents access to financial services on tools. In addition, usage-based billing can quickly integrate in these agent frameworks to bill your customers. "Finally this is great- skimpy - kudos to Arthur Turrell
from skimpy import generate_test_data, skim df = generate_test_data() skim(df)

Bigger picture ideas
Longer thought provoking reads - sit back and pour a drink! ...
I’m personally a big believer in this: A new golden age of discovery (in a similar vein, see also How Hallucinatory A.I. Helps Science Dream Up Big Breakthroughs, and the research paper here highlighted earlier)
"In this essay, we take a tour of how AI is transforming scientific disciplines from genomics to computer science to weather forecasting. Some scientists are training their own AI models, while others are fine-tuning existing AI models, or using these models’ predictions to accelerate their research. Scientists are using AI as a scientific instrument to help tackle important problems, such as designing proteins that bind more tightly to disease targets, but are also gradually transforming how science itself is practised."Lots of “reviews of the year” (and no doubt more to come)
Always worth reading what Andrew Ng has to say
"Consider this: GPT-4 was released March 2023. Since then, models have become much faster, cheaper, sometimes smaller, more multimodal, and better at reasoning, and many more open weight versions are available — so progress has been fantastic! (Claims that AI is “hitting a wall” seem extremely ill-informed.) But more significantly, many applications that already were theoretically possible using the March 2023 version of GPT-4 — in areas such as customer service, question answering, and process automation — now have significant early momentum."And a thoughtful investor perspective from Kelvin Mu- “what an extraordinary time to be alive”!
"Regardless of where one stands in this debate, one fact is indisputable: the pace of AI innovation and adoption this year was unprecedented. Few years in modern history have seen such a concentrated burst of technological progress and investment as we saw in 2024. This is more than a technological revolution; it is a societal revolution. And we are not merely spectators to this revolution but active participants—a rare opportunity we must responsibly embrace. What an extraordinary time to be alive."
What just happened - Ethan Mollick
"As one fun example, I read an article about a recent social media panic - an academic paper suggested that black plastic utensils could poison you because they were partially made with recycled e-waste. A compound called BDE-209 could leach from these utensils at such a high rate, the paper suggested, that it would approach the safe levels of dosage established by the EPA. A lot of people threw away their spatulas, but McGill University’s Joe Schwarcz thought this didn’t make sense and identified a math error where the authors incorrectly multiplied the dosage of BDE-209 by a factor of 10 on the seventh page of the article - an error missed by the paper’s authors and peer reviewers. I was curious if o1 could spot this error. So, from my phone, I pasted in the text of the PDF and typed: “carefully check the math in this paper.” That was it. o1 spotted the error immediately (other AI models did not)."“Agentic” is very much flavour of 2025
OpenAI cofounder Ilya Sutskever says the way AI is built is about to change
Why you should care about AI agents
"The difference between the chatbots of today and the agents of tomorrow becomes clearer when we consider a concrete example. Take planning a holiday: A system like GPT-4 can suggest an itinerary if you manually provide your dates, budget, and preferences. But a sufficiently powerful AI agent would transform this process. Its key advantage would be the ability to interact with external systems – it could select ideal dates by accessing your calendar, understand your preferences through your search history, social media presence and other digital footprints, and use your payment and contact details to book flights, hotels and restaurants. One text prompt to your AI assistant could set in motion an automated chain of events that culminates in a meticulous itinerary and several booking confirmations landing in your inbox. "
As are ‘World Models’
The AI We Deserve - Boston Review
"Many of these concerns point to a larger structural issue: power over this technology is concentrated in the hands of just a few companies. It’s one thing to let Big Tech manage cloud computing, word processing, or even search; in those areas, the potential for mischief seems smaller. But generative AI raises the stakes, reigniting debates about the broader relationship between technology and democracy."Another great post from Ethan Mollick- 15 Times to use AI, and 5 Not to
"There are several types of work where AI can be particularly useful, given the current capabilities and limitations of LLMs. Though this list is based in science, it draws even more from experience. Like any form of wisdom, using AI well requires holding opposing ideas in mind: it can be transformative yet must be approached with skepticism, powerful yet prone to subtle failures, essential for some tasks yet actively harmful for others. I also want to caveat that you shouldn't take this list too seriously except as inspiration - you know your own situation best, and local knowledge matters more than any general principles. With all that out of the way, below are several types of tasks where AI can be especially useful, given current capabilities—and some scenarios where you should remain wary."
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
Boids is an artificial life program that produces startlingly realistic simulations of the flocking behavior of birds
Build your own: Streamlining AI Paper Discovery: Building an Automated Research Newsletter
The system is fully automated, and executes in the following manner: 1. Monitors arXiv RSS feeds for new AI papers 2. Uses Claude to evaluate their relevance to my interests 3. Generates summaries focused on key findings and practical implications 4. Delivers curated papers via email twice weekly
5 ways to explore chess during the 2024 World Chess Championship
The Black Spatula Project- get involved!


Build your own Babel fish - Fish Audio




Updates from Members and Contributors
Aidan Kelly, Data Scientist at Nesta, published an excellent post on evaluating LLMs, including n-gram, probability-based and LLM-as-a-judge metrics - well worth a read
Sarah Phelps, Policy Advisor at the ONS, is helping organise the next Web Intelligence Network Conference, "From Web to Data”, on 4-5th February in Gdansk, Poland. Anyone interested in generating or augmenting their statistics with web data should definitely check it out.
Finally there is also a newly announced webinar on 16th January (14:00 CET): “Enhancing Data Quality and Methodologies for Web-Scrapped Statistics” - more information here
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
Two Lead AI Engineers in the Incubator for AI at the Cabinet Office- sounds exciting (other adjacent roles here)!
2 exciting new machine learning roles at Carbon Re- excellent climate change AI startup
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS