


January Newsletter
Hi everyone-
2023- Happy New Year!...Hope you had a fun and festive holiday season or at least drank and ate enough to take your mind off the strikes, energy prices, cost of living crisis, war in Ukraine and all the other depressing headlines... Perhaps time for something a little different, with a wrap up of data science developments in the last month. Don't miss out on the ChatGPT fun and games in the middle section!
Following is the January edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. (If you are reading this on email and it is not formatting well, try viewing online at http://datasciencesection.org/)
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
Industrial Strength Data Science January 2023 Newsletter
RSS Data Science Section
Committee Activities
We are clearly a bit biased... but the section had a fantastic year in 2022! Highlights included 4 engaging and thought provoking meetups, a RSS conference lecture, direct input into the UK AI policy strategy and roadmap, ongoing advocacy and support for Open Source, significant input and support for the new Advanced Data Science Professional Certification, support for the launch of the RSS “real World data Science” platform, 11 newsletters and 2 socials! We are looking to improve on that list in 2023 and are busy planning activities under our new Chair, Janet Bastiman (Chief Data Scientist, Napier AI).
The RSS is now accepting applications for the Advanced Data Science Professional certification, awarded as part of our work with the Alliance for Data Science Professionals - more details here.
Martin Goodson (CEO and Chief Scientist at Evolution AI) continues to run the excellent London Machine Learning meetup and is very active with events. The last event was a great one - Alhussein Fawzi, Research Scientist at DeepMind, presented AlphaTensor - "Faster matrix multiplication with deep reinforcement learning". Videos are posted on the meetup youtube channel - and future events will be posted here.
Martin has also compiled a handy list of mastodon handles as the data science and machine learning community migrates away from twitter...
This Month in Data Science
Lots of exciting data science going on, as always!
Ethics and more ethics...
Bias, ethics and diversity continue to be hot topics in data science...
China continues to push ethical boundaries in the government's deployment of AI
An AI system is set to be implemented in the Chinese judicial sector by 2025, according to ChinaDaily
And the NYTimes reports on how the Chinese Police used phones and faces to track protestors
"We’re hearing stories of police turning up on people’s doorsteps asking them their whereabouts during the protests, and this appears to be based on the evidence gathered through mass surveillance,” said Alkan Akad, a China researcher at Amnesty International. “China’s ‘Big Brother’ technology is never switched off, and the government hopes it will now show its effectiveness in snuffing out unrest,” he added."Of course it is not just China. A recent report from the Electronic Privacy Information Center after a 14 month investigation highlighted the proliferation of automated decision making systems in the US Government. Of course this is not necessarily a bad thing, but transparency and governance are critical.
In a positive step, the US Food and Drug Administration (FDA) in collaboration with counterparts in Canada and the UK has released "Good Machine Learning Practice for Medical Device Development"
The 10 guiding principles identify areas where the International Medical Device Regulators Forum (IMDRF), international standards organizations, and other collaborative bodies could work to advance GMLP. Areas of collaboration include research, creating educational tools and resources, international harmonization, and consensus standards, which may help inform regulatory policies and regulatory guidelines.
We envision these guiding principles may be used to:
- Adopt good practices that have been proven in other sectors
- Tailor practices from other sectors so they are applicable to medical technology and the health care sector
- Create new practices specific for medical technology and the health care sectorWhile new techniques continue to evolve in the Medical AI sector: "Predicting sex from retinal fundus photographs using automated deep learning". Research like this highlights the importance of widely followed best practices regarding how information obtained through AI (in this case the sex of the patient) can be used.
Driverless Cars continue to be 'just over the horizon'. While Apple has scaled back its work on Self-Driving Cars, Cruise is expanding its trial of RoboTaxis in San Fransisco,
It’s hard to explain the feeling when a Cruise vehicle pulls up to pick you up with no one in the driver’s seat.
There’s a bit of apprehension, a bit of wonder, a bit of: “Is this actually happening?”
And in my case, there was a bit of a walk as the car came to a stop across the street from our chosen pickup point in Pacific Heights. The roughly half-hour drive to the Outer Richmond (paid for by Cruise) made me feel like I was in the hands of an incredibly cautious student driver, complete with nervous, premature stops, a 25 mph speed limit and no right turns on red lights.We'll have lots more Generative AI fun and games later in the newsletter, but the ethical questions around "stealing styles" continue, and a new viral AI avatar app called Lensa has caused a good deal of controversy by highlighting the bias inherent in the underlying image training set used in the app (coverage from Wired and an excellent piece in MIT Technology Review)
I have Asian heritage, and that seems to be the only thing the AI model picked up on from my selfies. I got images of generic Asian women clearly modeled on anime or video-game characters. Or most likely porn, considering the sizable chunk of my avatars that were nude or showed a lot of skin. A couple of my avatars appeared to be crying. My white female colleague got significantly fewer sexualized images, with only a couple of nudes and hints of cleavage. Another colleague with Chinese heritage got results similar to mine: reams and reams of pornified avatars. Speaking of bias, Hugging Face has an Ethics and Society newsletter which recently published an excellent summary of the risks that can be driven through bias in machine learning models.
These same systems are also likely to reproduce discriminatory and abusive behaviors represented in their training data, especially when the data encodes human behaviors. The technology then has the potential to make these issues significantly worseSome good news however- Google highlights how you can identify unintended biases with saliency, and also visualise and understand NLP models with their open source Learning Interpretability Tool
Finally a somewhat provocative piece arguing that effective altruism is driving AI research in the wrong direction
As a result, all of this money has shaped the field of AI and its priorities in ways that harm people in marginalized groups while purporting to work on “beneficial artificial general intelligence” that will bring techno utopia for humanity. This is yet another example of how our technological future is not a linear march toward progress but one that is determined by those who have the money and influence to control it. Developments in Data Science Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
When Hinton talks it's worth listening! Apparently back-propagation- the iterative approach central to pretty much all current deep learning- has run its course, and 'Forward Forward' is how it should be done (high level discussion here, implementation in python here)
Why do dreams – which are always so interesting – just disappear? Francis Crick (who played an important role in deciphering the structure of DNA) and Graeme Mitchison had this idea that we dream in order to get rid of things that we tend to believe, but shouldn’t. This explains why you don’t remember dreams.
Forward Forward builds on this idea of contrastive learning and processing real and negative data. The trick of Forward Forward, is you propagate activity forwards with real data and get one gradient. And then when you’re asleep, propagate activity forward again, starting from negative data with artificial data to get another gradient. Together, those two gradients accurately guide the weights in the neural network towards a better model of the world that produced the input data.We have discussed previously how Vision Transformers (the Transformer architecture that started out in text processing now applied to vision tasks) are now the go-to approach for vision tasks. But what do they actually learn? Interesting paper digging into this an the differences between ViTs and CNNs (and a useful implementation of ViTs in pytorch)
And now we have the 'Masked ViT' - a novel way of pre-training vision transformers using a self-supervised learning approach that masks out portions of the the training images - resulting in faster training and better predictions
And not content with conquering vision, transformers move into robotics (RT-1 Robotics transformer for real world control at scale)!
The new generative AI models rely on connecting visual and textual representations together (e.g. CLIP inside DALLE), often using a labelled training set of examples. But are there biases in these labelled training sets?
"We conduct an in-depth exploration of the CLIP model and show that its visual representation is often strongly biased towards solving some tasks more than others. Moreover, which task the representation will be biased towards is unpredictable, with little consistency across images"This is pretty amazing... Given the potential biases in the multi-modal training sets (see last item) is it possible to use pixels alone- ie train both image and language models using just the pixels of the images or the text rendered as images?
Our model is trained with contrastive loss alone, so we call it CLIP-Pixels Only (CLIPPO). CLIPPO uses a single encoder that processes both regular images and text rendered as images. CLIPPO performs image-based tasks such as retrieval and zero-shot image classification almost as well as CLIP, with half the number of parameters and no text-specific tower or embedding. When trained jointly via image-text contrastive learning and next-sentence contrastive learning, CLIPPO can perform well on natural language understanding tasks, without any word-level loss (language modelling or masked language modelling), outperforming pixel-based prior work.Knowledge graphs are an elegant concept and are increasingly used in natural language processing. But what are they and what are the different types and approaches- useful survey paper.
More slightly mind boggling stuff - a generalist neural algorithmic learner (it learns new algorithms to solve tasks...)
OpenAI have announced a new and improved embedding model (called ada)
"The new model, text-embedding-ada-002, replaces five separate models for text search, text similarity, and code search, and outperforms our previous most capable model, Davinci, at most tasks, while being priced 99.8% lower.."Meanwhile Facebook/Meta have released Data2vec 2.0 which unifies self-supervised learning across vision, speech and text

DeepMind have released DeepNash, an AI system that learned to play Stratego from scratch to a human expert level by playing against itself. This is impressive as Stratego is a game of imperfect information (unlike Chess and Go): players cannot directly observe the identities of their opponent's pieces.
And Amazon don't tend to get quite the same publicity as other large AI companies for their research - but they are prolific.. A quick guide to Amazon's 40+ papers at EMNLP 2022
Finally, a slightly different topic - scientists at the University of Cambridge have successfully mapped the connectome of an insect brain
"Brains contain networks of interconnected neurons, so knowing the network architecture is essential for understanding brain function. We therefore mapped the synaptic-resolution connectome of an insect brain (Drosophila larva) with rich behavior, including learning, value-computation, and action-selection, comprising 3,013 neurons and 544,000 synapses ... Some structural features, including multilayer shortcuts and nested recurrent loops, resembled powerful machine learning architectures"Stable-Dal-Gen oh my...and ChatGPT!
We'll pause on text to image for a moment to focus on the newest and coolest kid in town- ChatGPT from OpenAI. Even though in reality it is not much more sophisticated than the underlying language models which have been around for sometime, the interface seems to have made it more accessible, and the use cases more obvious - and so has generated a lot (!) of comment.
First of all, what is it? Well, its a chat bot: type in something (anything from "What is the capital of France" to "Write a 1000 word essay on the origins of the French Revolution from the perspective of an 18th Century English nobleman" ), and you get a response. See OpenAI's release statement here, and play around with it here (sign up for a free login). Some local implementations here and here. And some "awesome prompts" to tryout here.

Why all the fuss? Well, the responses can be very impressive, and the potential use cases quite obvious - "OpenAI’s new chatbot ChatGPT could be a game-changer for businesses". Try taking the test - "Did a Fourth Grader Write This? Or the New Chatbot?".
It really can be phenomenal. And incredibly flexible - you can build a synth, train a machine learning model, build a virtual machine, create an entire application
We have novelists leveraging it for creative inspiration, designers exploring more outlandish concepts ... and perhaps my favourite so far... a powerpoint generator for any occasion!
Its biggest opportunity is potentially in search, and Google has apparently taken note. (The irony is that Google's own language model and chat bot is arguably better than ChatGPT but has received less attention).
“For more than 20 years, the Google search engine has served as the world’s primary gateway to the internet. But with a new kind of chat bot technology poised to reinvent or even replace traditional search engines, Google could face the first serious threat to its main search business. One Google executive described the efforts as make or break for Google’s future.”So is ChatGPT ready for prime time? Not quite - there are plenty of flaws as many have been pointing out.
It can be easily tricked and it's defences avoided
Writes plausibly even when producing garbage - very hard to tell fact from fiction if you are unfamiliar with the field.
Here is a good summary of the problems
So where does this leave Generative AI in general - thoughtful piece here
Real world applications of Data Science
Lots of practical examples making a difference in the real world this month!
OpenAI has released something in addition to ChatGPT! - Point-E an AI that generates 3-D models. It uses a novel approach- it generates point clouds, or discrete sets of data points in space that represent a 3D shape (paper)
Not content with NLP, Vision, Robots... Transformers can now turn audio into images (spectrograms), which helps drive real time music generation from a text prompt
If you ever need to transcribe YouTube videos... OpenAI's Whisper can help
Alexa will now happily make up bedtime stories... or you can generate a story and video from a text prompt using open source models at Hugging Face
AI generated code is getting better... AlphaCode from DeepMind seems to be setting the standard in terms of quality, but there are open source alternatives such as 'SantaCoder' from Hugging Face. Qatalog has now launched a commercial service based on AI code generation.
More great examples of AI helping diverse organisations in different ways
Leading companies showing us how it's done:
Always fun to see updates in the robotics field:
Amazon pushing the boundaries - eliminating the need for barcodes
The Turkey Sandwich paradox...
More things to try for time series problems
Probabilistic time series forecasting with (you guessed it) Transformers
Implementations of a two different Transformer based time series approaches (PatchTST and GBT) ... and a paper with code comparing Deep Learning and statistical approaches to time series
Lots going on in the Healthcare/Medical space
This looks promising - PubMed GPT, a domain specific large language model for biomedical text, together with MultiMedQA for benchmarking LLM's clinical knowledge
Stanford researchers have generated imitation lung X-rays with diagnosable pathologies from a custom version of Stable Diffusion
And biotech labs are using AI inspired by DALL-E to invent new drugs - amazing
"These protein generators can be directed to produce designs for proteins with specific properties, such as shape or size or function. In effect, this makes it possible to come up with new proteins to do particular jobs on demand. Researchers hope that this will eventually lead to the development of new and more effective drugs. “We can discover in minutes what took evolution millions of years,” says Gevorg Grigoryan, CTO of Generate Biomedicines.
“What is notable about this work is the generation of proteins according to desired constraints,” says Ava Amini, a biophysicist at Microsoft Research in Cambridge, Massachusetts." 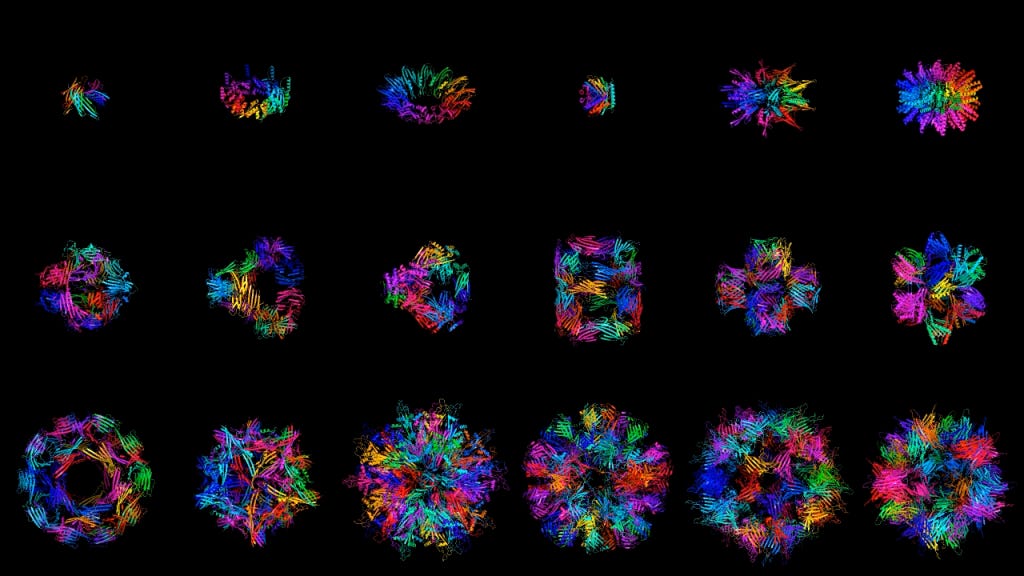
How does that work?
Tutorials and deep dives on different approaches and techniques
First of all an excellent step-by-step guide to how text to image generative models work
Learning from the best... digging into AlphaCode with Peter Norvig
Good overview of how AlphaTensor works
Excellent paper from Murray Shanahan on how Large Language Models work - well worth a read - along with "GPT-3 Architecture on a napkin" for a different view and a look at how GPT has evolved over time and an assessment of the latest version
"The more adept LLMs become at mimicking human language, the more vulnerable we become to anthropomorphism, to seeing the systems in which they are embedded as more human-like than they really are. This trend is amplified by the natural tendency to use philosophically loaded terms, such as "knows", "believes", and "thinks", when describing these systems. To mitigate this trend, this paper advocates the practice of repeatedly stepping back to remind ourselves of how LLMs, and the systems of which they form a part, actually work."Good tutorial with code using Keras to build a diffusion model
Another way of thinking about Transformers - elegant explanation
Useful guide to how Transfer learning actually works
Understanding the different loss functions available in pyTorch
In-depth tutorial building a recommender using graph neural networks in pyTorch geometric
Very timely: digging into the application of Reinforcement Learning with Human Feedback - how the ChatGPT interface works - (also a useful library to explore RL with)
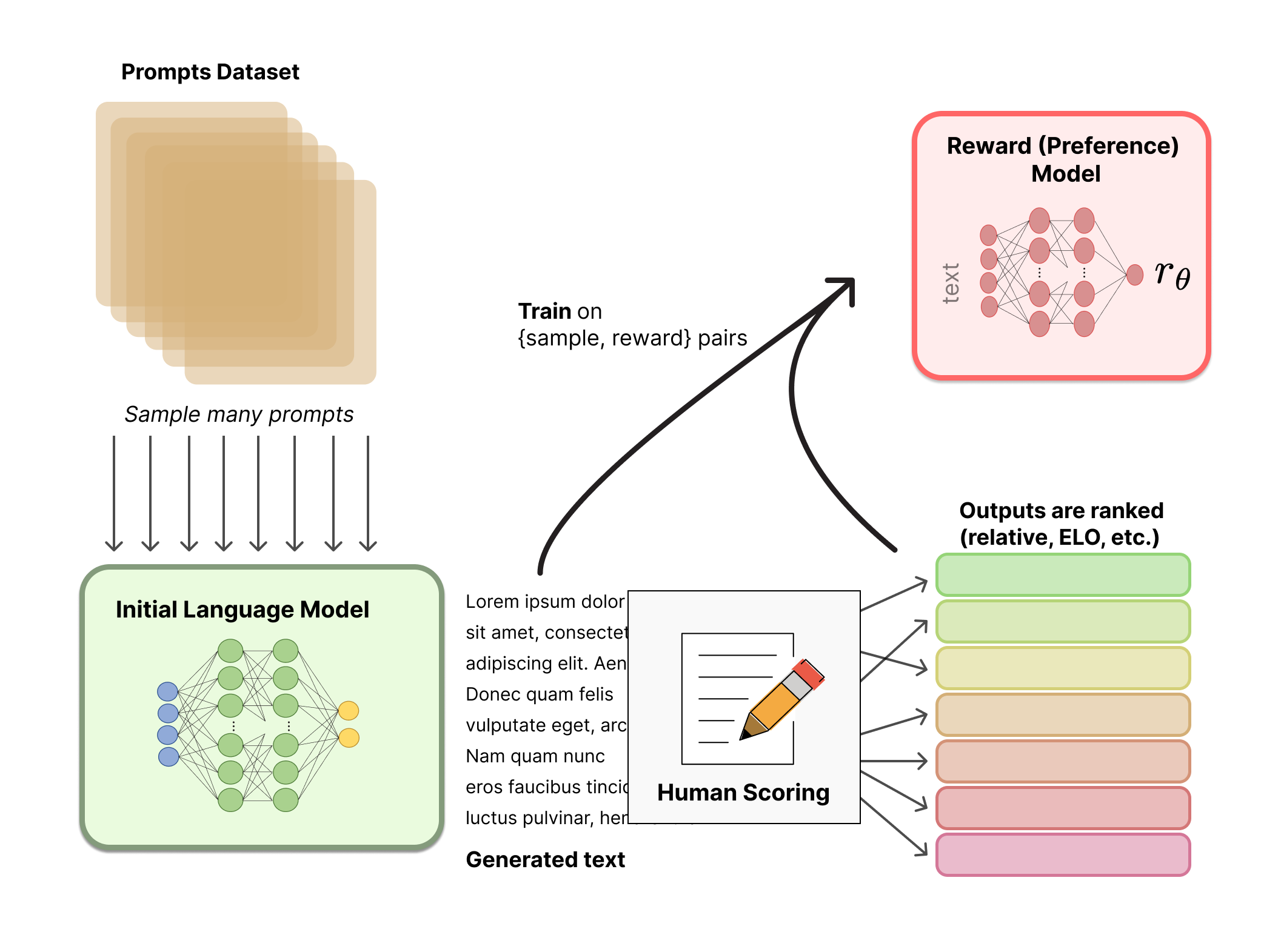
Practical tips
How to drive analytics and ML into production
Useful retrospection on a failed data science project- what went wrong and how it might have been done differently
High level look at ML Observability and its importance together with another couple of tools to try out (Hopsworks for Feature Store and MLOps and Lance for dataset versioning and reproducibility)
"If you find that your F1 / recall / accuracy score isn’t getting better with more labels, it’s critical that you understand why this is happening. You need to be able to compare label distributions and imbalance between dataset versions. You need to compare top error contributors, check for new negative noise introduced, among many other things. Today this process is extremely cumbersome even when possible, involving lots of copying, complicated syntax, and configuration files that need to be managed separately from the data itself."Digging into the complexities of data lineage along with a practical tutorial for using dbt as the business grows
Need to scale up? Definitely worth giving Ray a try
"While there are a growing number of blog posts and tutorials on the challenges of training large ML models, there are considerably fewer covering the details and approaches for training many ML models. We’ve seen a huge variety of approaches ranging from services like AWS Batch, SageMaker, and Vertex AI to homegrown solutions built around open source tools like Celery or Redis.
Ray removes a lot of the performance overhead of handling these challenging use cases, and as a result users often report significant performance gains when switching to Ray. Here we’ll go into the next level of detail about how that works."A couple of useful pointers on A/B testing. First, dealing with Multiple Metrics and then different options for correcting for multiple testing.... although Bayes is probably the way to go!
What’s Next for Data Engineering in 2023? and a useful tutorial on how Netflix uses DataFlow for pipelines
Useful resources- '21 essential books for data scientists' and 'Top Python Libraires of 2022'... not quite sure about 'essential' and 'top' but worth a quick peruse!
Quick tutorial on using gradio (looks comporable to streamlit) to build a realtime dashboard from bigquery
Finally some useful visual approaches to exploring data: facets, chloropleths and 'this not that'
Bigger picture ideas
Longer thought provoking reads - lean back and pour a drink! ...
Andrew Ng's review of the year, and predictions for 2023... great insight as always
“Consider the number of examples necessary to learn a new task, known as sample complexity. It takes a huge amount of gameplay to train a deep learning model to play a new video game, while a human can learn this very quickly. Related issues fall under the rubric of reasoning. A computer needs to consider numerous possibilities to plan an efficient route from here to there, while a human doesn’t.”And a more general Computer Science take on 2022, from Quanta magazine
“And artificial intelligence has always flirted with biology — indeed, the field takes inspiration from the human brain as perhaps the ultimate computer. While understanding how the brain works and creating brainlike AI has long seemed like a pipe dream to computer scientists and neuroscientists, a new type of neural network known as a transformer seems to process information similarly to brains"Pretty cool- Annotated History of Modern AI and Deep Learning
"A modern history of AI will emphasize breakthroughs outside of the focus of traditional AI text books, in particular, mathematical foundations of today's NNs such as the chain rule (1676), the first NNs (linear regression, circa 1800), and the first working deep learners (1965-). "Different takes on where programming is heading ... on one hand 'Prompting is programming' while on the other are we seeing the end of programming?
"Programming will be obsolete. I believe the conventional idea of "writing a program" is headed for extinction, and indeed, for all but very specialized applications, most software, as we know it, will be replaced by AI systems that are trained rather than programmed. In situations where one needs a "simple" program (after all, not everything should require a model of hundreds of billions of parameters running on a cluster of GPUs), those programs will, themselves, be generated by an AI rather than coded by hand.""One interpretation of this fact is that current language models are still not “good enough” – we haven’t yet figured out how to train models with enough parameters, on enough data, at a large enough scale. But another interpretation is that, at some level, language models are not quite solving the problem that me might want. This latter interpretation is often brought forward as a fundamental limitation of language models, but I will argue that in fact it suggests a different way of using language models that may turn out to be far more powerful than some might suspect."The way we think about AI is shaped by works of science-fiction. In the big picture, fiction provides the conceptual building blocks we use to make sense of the long-term significance of “thinking machines” for our civilization and even our species. Zooming in, fiction provides the familiar narrative frame leveraged by the media coverage of new AI-powered product releases."We found that across the board, modern AI models do not appear to have a robust understanding of the physical world. They were not able to consistently discern physically plausible scenarios from implausible ones. In fact, some models frequently found the implausible event to be less surprising: meaning if a person dropped a pen, the model found it less surprising for it to float than for it to fall. This also means that, at their current level of development, the models that could eventually drive our cars may lack a core physical understanding that they cannot drive through a brick wall."Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
"There is a cat that wanders around my neighbourhood. I wanted to build something that would notify me whenever it came to my backyard." Cats, Pi, and Machine Learning
How the UK Uses Its Land for Wealth, Energy and Grouse Hunting
Amazing visualisation.. takes a while to load but worth the wait!
Launch an astroid at the earth and see what impact it has...
Covid Corner
Apparently Covid is over - certainly there are very limited restrictions in the UK now
The latest results from the ONS tracking study estimate 1 in 45 people in England have Covid (another increase from last month's 1 in 60) ... but till a far cry from the 1 in 1000 we had in the summer of 2021.
The UK has approved the Moderna 'Dual Strain' vaccine which protects against original strains of Covid and Omicron.
Updates from Members and Contributors
Fresh from the success of their ESSnet Web Intelligence Network webinars, the ONS Data Science campus have another excellent set of webinars coming up:
24 Jan’23 – Enhancing the Quality of Statistical Business Registers with Scraped Data. This webinar will aim to inspire and equip participants keen to use web-scraped information to enhance the quality of the Statistical Business Registers. Sign up here
23 Feb’23 – Methods of Processing and Analysing of Web-Scraped Tourism Data. This webinar will discuss the issues of data sources available in tourism statistics. We will present how to search for new data sources and how to analyse them. We will review and apply methods for merging and combining the web scraped data with other sources, using various programming environments. Sign up here
Jobs!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Napier AI are looking to hire a Senior Data Scientist (Machine Learning Engineer) and a Data Engineer
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
- Piers
The views expressed are our own and do not necessarily represent those of the RSS