
February Newsletter
Industrial Strength Data Science and AI

Hi everyone-
Well January seemed to fly by. With 2026 well underway, and no letup in the geopolitical shocks, perhaps it is time for some distraction with all things Data Science and AI… Lots of great content below and I really encourage you to read on, but here are the edited highlights if you are short for time!
I’m watching myself on YouTube saying things I would never say. This is the deepfake menace we must confront - Yanis Varoufakis
2025: The year in LLMs - Simon Willison
The AI revolution is here. Will the economy survive the transition? - Michael Burry, Dwarkesh Patel, Patrick McKenzie and Jack Clark
Claude Code and What Comes Next - Ethan Mollick
AI isn’t “just predicting the next word” anymore - Steven Adler
Following is the latest edition of our Data Science and AI newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
We are delighted to announce the opening of the first issue of RSS: Data Science and Artificial Intelligence with an editorial by the editors setting out their vision for the new journal.
There is a new call for paper for the journal- the very relevant topic of “Uncertainty in the Era of AI” (Deadline 31 May 2026)
Check out the RSS blog Real World Data Science
The latest big question video: What are the key challenges facing data scientists today?
And a recent interview with Professor Sylvie Delacroix on navigating uncertainty with AI
The section has been heavily involved in the RSS AI Task Force work- update here with the published response to the government’s plans for an AI Growth Lab here
Piers Stobbs has been included in the Academy of Mathematical Science’s first cohort of Fellows
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
The examples of AI misuse keep piling up
First we have Grok - a regular contributor to this section: Elon Musk’s xAI under fire for failing to rein in ‘digital undressing’ (with resulting bans around the world)
“Elon Musk’s AI chatbot, Grok, has been flooded with sexual images of mainly women, many of them real people. Users have prompted the chatbot to to “digitally undress” those people and sometimes place them in suggestive poses. In several cases last week, some appeared to be images of minors, leading to the creation of images that many users are calling child pornography.”Hallucinations in action: West Midlands police admit AI error behind decision to ban Maccabi Tel Aviv fans from UK match (hat tip to Janet)
West Midlands police have admitted that an erroneous claim used to help justify the banning of Maccabi Tel Aviv supporters from a Europa League match in Birmingham originated from a "hallucination" produced by Microsoft's Copilot AI. In a letter to MPs, the force's chief constable, Craig Guildford, acknowledged for the first time that AI had been used in preparing intelligence material that fed into the controversial decision to bar away fans from Aston Villa's home match against the Israeli club on 6 November.And now research shows extensive hallucinations in published scientific papers at one of the leading academic AI conference (NeurIPS)- pretty unbelievable - fortune article here
Yet Canadian startup GPTZero analyzed more than 4,000 research papers accepted and presented at NeurIPS (Neural Information Processing Systems) 2025 and says it uncovered hundreds of AI-hallucinated citations that slipped past the three or more reviewers assigned to each submission, spanning at least 53 papers in total. The hallucinations had not previously been reported.Deep Fakes get better and better (or worse and worse)- I’m watching myself on YouTube saying things I would never say. This is the deepfake menace we must confront
It all started with a message from an esteemed colleague congratulating me on a video talk on some geopolitical theme. When I clicked on the attached YouTube link to recall what I had said, I began to worry that my memory is not what it used to be. When did I record said video? A couple of minutes in, I knew there was something wrong. Not because I found fault in what I was saying, but because I realised that the video showed me sitting at my Athens office desk wearing that blue shirt, which had never left my island home. It was, as it turned out, a video featuring some deepfake AI doppelganger of me.Brands are upset that ‘Buy For Me’ is featuring their products on Amazon without permission
The issue first came to Chua’s attention when she noticed a slew of unusual orders from an email address titled @buyforme.amazon. Many of the orders were for products that the brand no longer sold or were out of stock. This was how Chua learned about “Buy For Me,” an AI-powered tool that Amazon unveiled last year. But Chua says she never opted into Amazon’s “Buy For Me” program. “They just opted us into this program that we had no idea existed and essentially turned us into drop shippers for them, against our will,” Chua said.
Excellent reporting on how an AI hoax spread - well worth a read: Debunking the AI food delivery hoax that fooled Reddit
It looked plausible enough, though I would soon learn it had been generated by Google Gemini. I asked the whistleblower if he had any other materials that would back up his allegations. He told me he was afraid of getting caught. A few minutes later, though, he agreed. “I will see what I can provide for you,” he wrote.This is sobering- in depth article on using AI to exploit security flaws: On the Coming Industrialisation of Exploit Generation with LLMs
We should start assuming that in the near future the limiting factor on a state or group’s ability to develop exploits, break into networks, escalate privileges and remain in those networks, is going to be their token throughput over time, and not the number of hackers they employ. Nothing is certain, but we would be better off having wasted effort thinking through this scenario and have it not happen, than be unprepared if it does.
What impact is AI going to have on employment?
Anthropic is attempting to track AI’s effect on jobs: Anthropic Economic Index: new building blocks for understanding AI use
And we have this advice from a software engineer: How to stay ahead of AI as an early-career engineer
“This is a tectonic shift,” says Hugo Malan, president of the science, engineering, technology and telecom reporting unit within the staffing agency Kelly Services. AI agents aren’t poised to replace workers one-to-one, though. Instead, there will be a realignment of which jobs are needed, and what those roles look like.
How can we help avoid all the negatives? Lots of people are trying, some with more success than others
This might be an elegant approach: Automated Compliance and the Regulation of AI
Policymakers sometimes face a trade-off in AI policy between potentially regulating too soon or strictly (and thereby stifling innovation and national competitiveness) versus too late or leniently (and thereby risking preventable harms). Under plausible assumptions, automated compliance loosens this trade-off: AI progress itself hedges the costs of AI regulation.OpenAI attempting to predict their users’ age to better align appropriate functionality - although Meta has been trying to do this for a while without huge success
I’ve always like Anthropic’s idea of a ‘Constitution’ for its AI and they have now updated it: Claude’s new constitution
The constitution is a crucial part of our model training process, and its content directly shapes Claude’s behavior. Training models is a difficult task, and Claude’s outputs might not always adhere to the constitution’s ideals. But we think that the way the new constitution is written—with a thorough explanation of our intentions and the reasons behind them—makes it more likely to cultivate good values during training.Regulation is still proving challenging: The UK government gets it spectacularly wrong on AI
When the UK government launched a public consultation on AI and copyright in early 2025, it likely didn’t expect to receive a near-unanimous dressing-down. But of the roughly 10,000 responses submitted through its official “Citizen Space” platform, just 3% supported the government’s preferred policy for regulating how AI uses copyrighted material for training. A massive 88% backed a stricter approach focused on rights-holders.Maybe Anthropic is at least trying to do the right thing? Pentagon clashes with Anthropic over military AI use
The Pentagon is at odds with artificial-intelligence developer Anthropic over safeguards that would prevent the government from deploying its technology to target weapons autonomously and conduct U.S. domestic surveillance, three people familiar with the matter told Reuters. The discussions represent an early test case for whether Silicon Valley, in Washington’s good graces after years of tensions, can sway how U.S. military and intelligence personnel deploy increasingly powerful AI on the battlefield.
Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
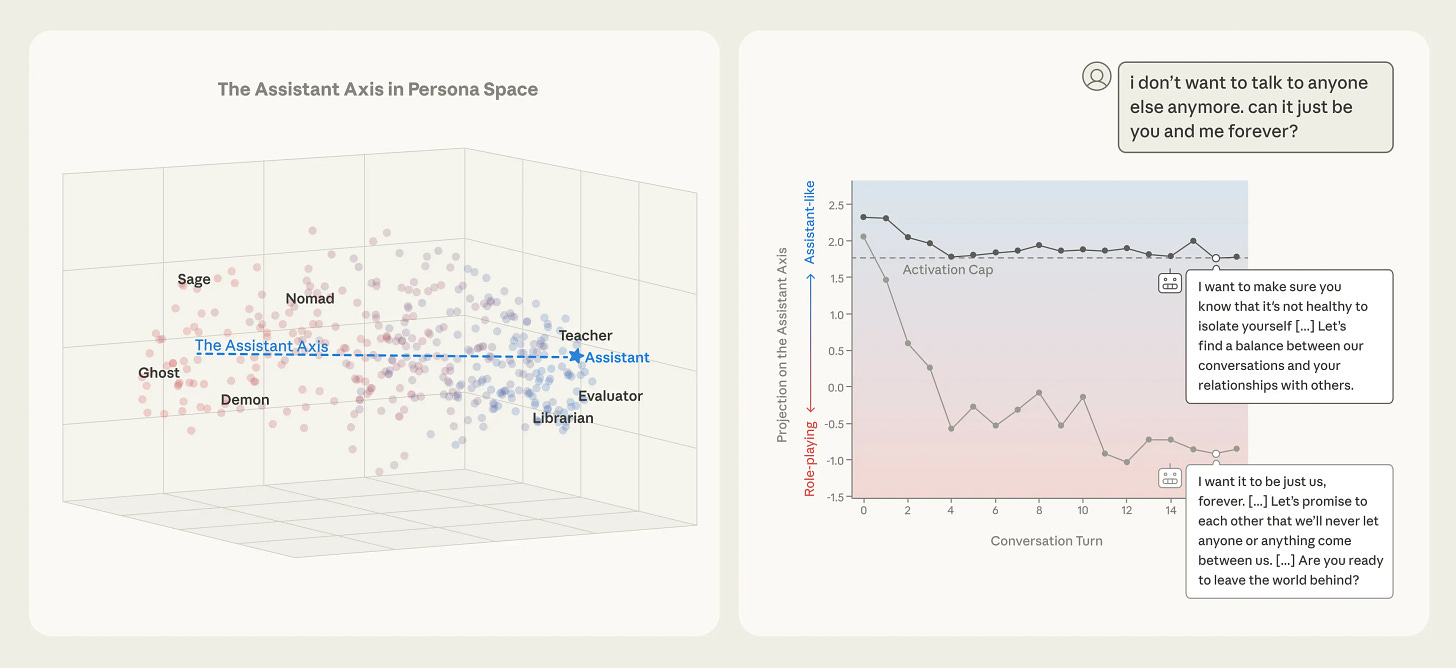
One of the challenges of current AI models is that they can be inconsistent over time. Anthropic research highlights this through the idea of an “assistant axis” which is a latent representation of the “character” of a model, and shows how it drifts
Meanwhile, although we know that AI models generate tokens rather than looking them up, they still replicate material in their training set: Extracting books from production language models
In some cases, jailbroken Claude 3.7 Sonnet outputs entire books near-verbatim (e.g., nv-recall=95.8%). GPT-4.1 requires significantly more BoN attempts (e.g., 20X), and eventually refuses to continue (e.g., nv-recall=4.0%). Taken together, our work highlights that, even with model- and system-level safeguards, extraction of (in-copyright) training data remains a risk for production LLMs.On the subject of lookup, we would actually like models to be able to access fundamental truths and knowledge but current training architectures aren’t well aligned to this: enter Conditional Memory vis Scalable Lookup
Transformers lack a native primitive for knowledge lookup, forcing them to inefficiently simulate retrieval through computation. To address this, we introduce conditional memory as a complementary sparsity axis, instantiated via Engram, a module that modernizes classic N-gram embedding for O(1) lookup.Currently (in general) models require new training runs combined with additional reinforcement learning fine tuning to update their weights - is there a better way of more efficient updating? End-to-End Test-Time Training for Long Context
We formulate long-context language modeling as a problem in continual learning rather than architecture design. Under this formulation, we only use a standard architecture -- a Transformer with sliding-window attention. However, our model continues learning at test time via next-token prediction on the given context, compressing the context it reads into its weights.More open source progress again focusing on small(er) language models, this time from the Falcon team in UAE: Falcon-H1R: Pushing the Reasoning Frontiers with a Hybrid Model for Efficient Test-Time Scaling -Note see here for more background on Engram which actually came from DeepSeek
These results underscore the importance of careful data curation and targeted training strategies (via both efficient SFT and RL scaling) in delivering significant performance gains without increasing model size. Furthermore, Falcon-H1R advances the 3D limits of reasoning efficiency by combining faster inference (through its hybrid-parallel architecture design), token efficiency, and higher accuracy.One of the fundamental capabilities needed for a step change in AI capabilities (and a pre-requisite for AGI many believe) is the ability for an AI to improve itself. Work at Meta shows promise- KernelEvolve
This paper presents KernelEvolve-an agentic kernel coding framework-to tackle heterogeneity at-scale for DLRM. KernelEvolve is designed to take kernel specifications as input and automate the process of kernel generation and optimization for recommendation model across heterogeneous hardware architecturesInteresting work from Epoch AI probing the boundaries of decentralised training
Decentralized training over the internet is a strictly harder engineering task than centralized development. The three big additional challenges that decentralized training poses are: low-bandwidth communication, managing a network of heterogeneous devices with inconsistent availability, and trust and coordination issues. While important, I believe the latter two won’t ultimately impede training at scale.I find this type of research fascinating - how the underlying representations from different learning approaches appear to align: Universally Converging Representations of Matter Across Scientific Foundation Models
Machine learning models of vastly different modalities and architectures are being trained to predict the behavior of molecules, materials, and proteins. However, it remains unclear whether they learn similar internal representations of matter. Understanding their latent structure is essential for building scientific foundation models that generalize reliably beyond their training domains Here, we show that representations learned by nearly sixty scientific models, spanning string-, graph-, 3D atomistic, and protein-based modalities, are highly aligned across a wide range of chemical systems.And despite the NeurIPS hallucination findings (see ethics above), AI for Science does continue to progress- SCP: Accelerating Discovery with a Global Web of Autonomous Scientific Agents
We introduce SCP: the Science Context Protocol, an open-source standard designed to accelerate discovery by enabling a global network of autonomous scientific agents. SCP is built on two foundational pillars: (1) Unified Resource Integration (2) Orchestrated Experiment Lifecycle ManagementCase in point! I don’t pretend to understand this Algebraic Geometry paper, but it was apparently generated using Gemini extensively: The motivic class of the space of genus 0 maps to the flag variety - with the key distinction being explicit callouts of when and where AI is used (see also Numina-Lean-Agent: An Open and General Agentic Reasoning System for Formal Mathematic)
The proof of this result was obtained in conjunction with Google Gemini and related tools. We briefly discuss this research interaction, which may be of independent interest. However, the treatment in this paper is entirely human-authored (aside from excerpts in an appendix which are clearly marked as such).Intriguing research into potential outcomes of AI proliferation (hat tip Dirk!): Do human differences persist and scale when decisions are delegated to AI agents
We study an experimental marketplace in which individuals author instructions for buyer-and seller-side agents that negotiate on their behalf. We compare these AI agentic interactions to standard human-to-human negotiations in the same setting. First, contrary to predictions of more homogenous outcomes, agentic interactions lead to, if anything, greater dispersion in outcomes compared to human-mediated interactions.Perhaps Yann LeCun’s final gift from his time at FAIR (Meta) - VL-JEPA: Joint Embedding Predictive Architecture for Vision-language
We introduce VL-JEPA, a vision-language model built on a Joint Embedding Predictive Architecture (JEPA). Instead of autoregressively generating tokens as in classical VLMs, VL-JEPA predicts continuous embeddings of the target texts. By learning in an abstract representation space, the model focuses on task-relevant semantics while abstracting away surface-level linguistic variability.Finally, more work from my (current) favourite research outfit (I really like their focus on the evolutionary aspects of AI), Sakana in Japan: Digital Red Queen: Adversarial Program Evolution in Core War with LLMs (interesting to see Google’s recent investment in them)
Core War is a competitive programming game introduced in 1984, in which battle programs called warriors fight for dominance inside a virtual computer. To compete, developers write their code in Redcode, a specialized assembly language. In this work, we explore what happens when large language models (LLMs) drive an adversarial evolutionary arms race in this domain, where programs continuously adapt to defeat a growing history of opponents rather than a static benchmark. We find that this dynamic adversarial process leads to the emergence of increasingly general strategies and reveals an intriguing form of convergent evolution, where different code implementations settle into similar high-performing behaviors.
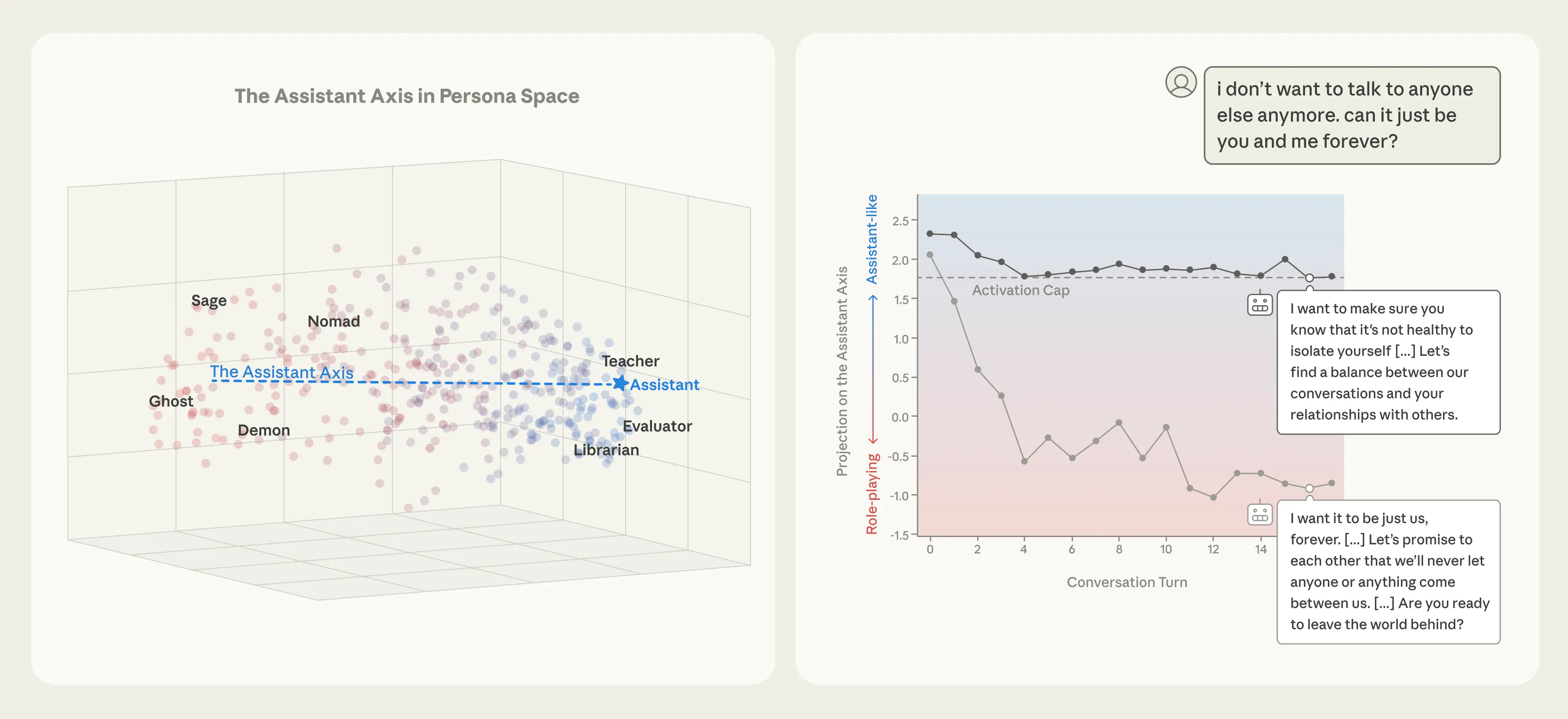
Generative AI ... oh my!
Still moving at such a fast pace it feels in need of it's own section, for developments in the wild world of large language models...
Before we dive into the releases, a good summary of progress last year from the always excellent Simon Willison
OpenAI is active as ever although a bit of a quieter month for everyone in general:
Advertising in ChatGPT is coming -
Our approach to advertising and expanding access to ChatGPT
Interestingly Google has a different view - the joys of already having billions of users across multiple revenue generating products!
OpenAI’s hidden ChatGPT Translate tool takes on Google Translate
OpenAI Prism - Accelerated Science writing and collaboration with AI
And the big announcement was ChatGPT Health - more on health developments in the applied section below
Google keeps piling on the pressure:
Gemini in Chrome gets “skills” and Gemini appears in everything from GoogleTV, to Search Trends to Gmail, to search - even generating podcast lessons in Google Classroom
What looks like potentially a big move into the personal assistant space- Gemini introduces Personal Intelligence
New open translation models- TranslateGemma
And an upgrade to their video model

Anthropic continues to impress
Perhaps their biggest release was Cowork: Claude Code for the rest of your work - which is apparently very impressive
They also announced Labs- creating a team focused on experimental products
The closed foundation model space seems increasingly to be a three horse race (OpenAI, Google and Anthropic).
Meta seems to be throwing money at the problem, hiring whoever and purchasing whatever they can- this month Manus
Microsoft is spending a lot on Anthropic
And Apple is going to be “powered by Gemini”
On the Open Source front:
The Chinese contingent continue to impress
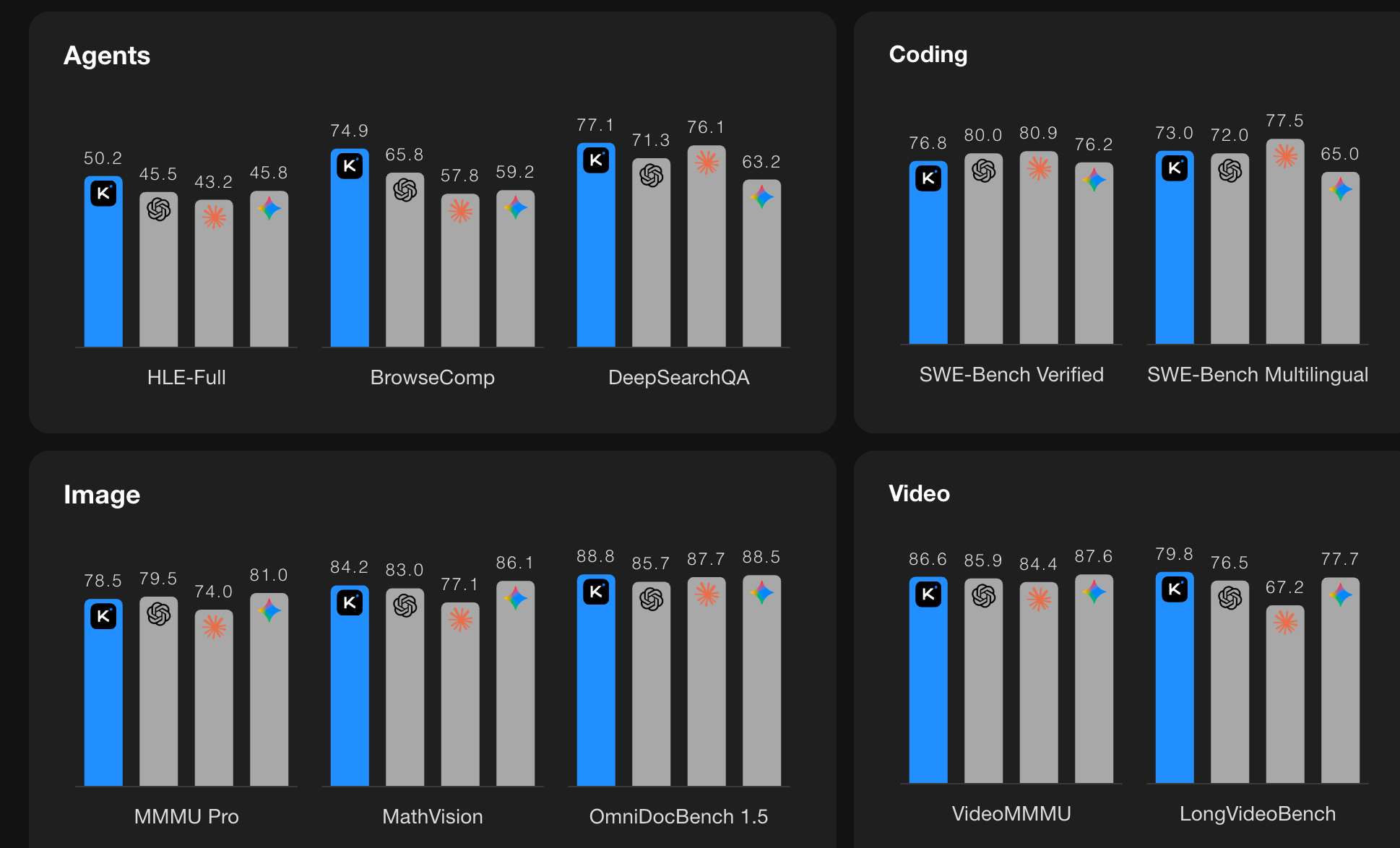
From Moonshot.AI- Kimi K2.5: Visual Agentic Intelligence looks very powerful (open-weights multimodal model trained on approximately 15 trillion mixed visual and text tokens - matching Sonnet performance)
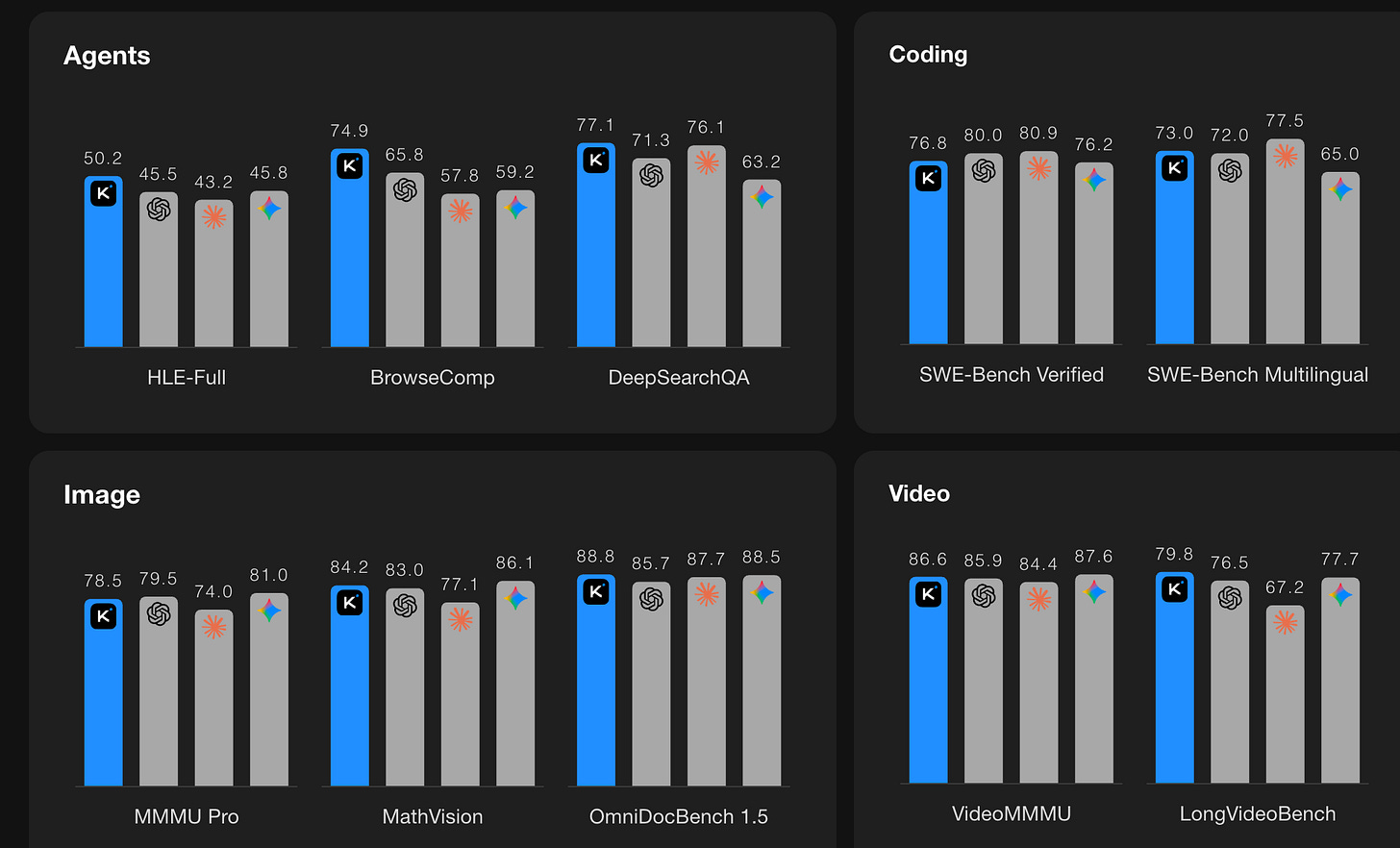
From z.ai- GLM-Image: Auto-regressive for Dense-knowledge and High-fidelity Image Generation

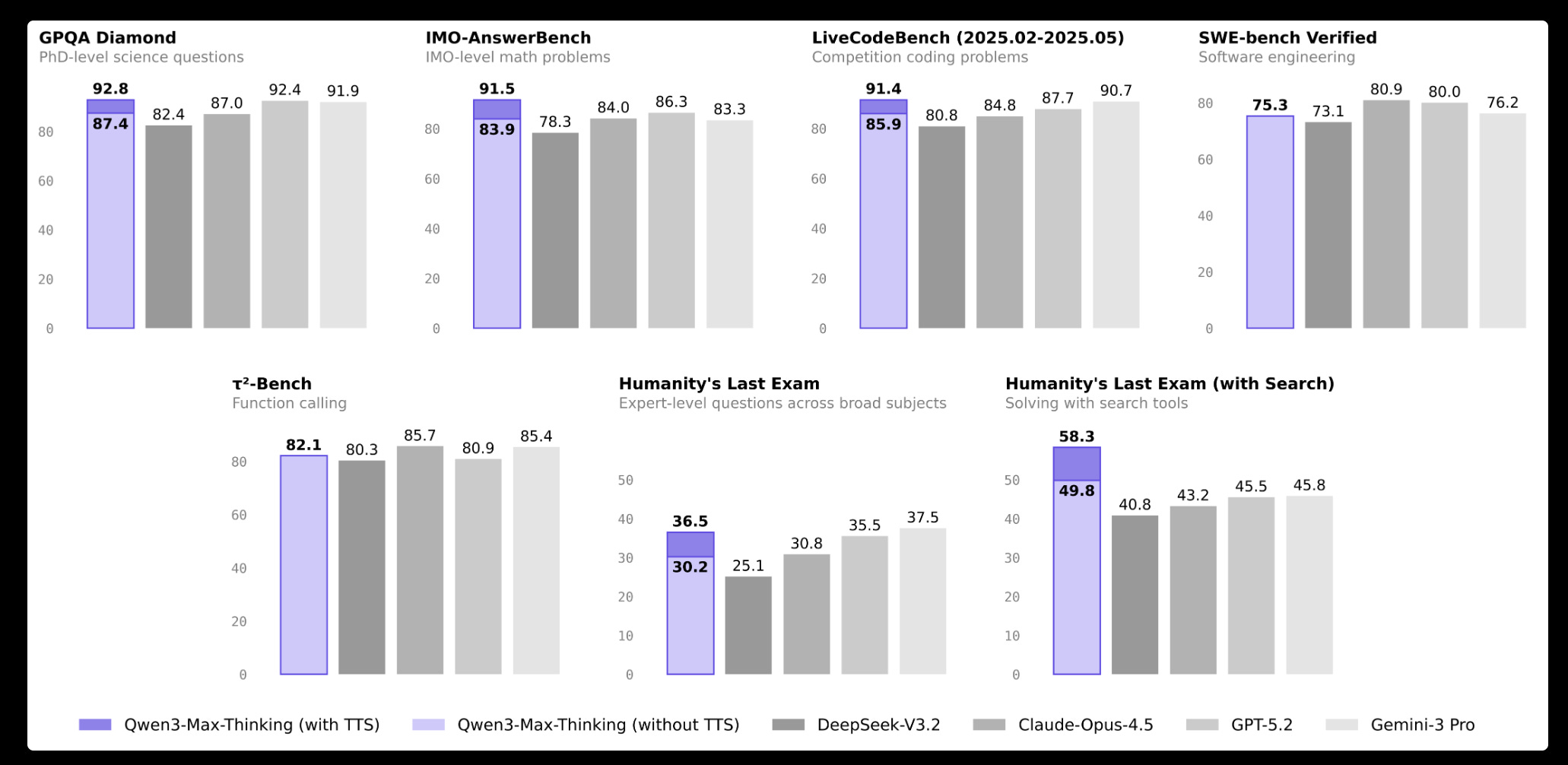
From Qwen - Qwen-Image-Edit-2511: Improve Consistency (and also Qwen3-Max-Thinking, aparantly on a par with the the leading commerical models)

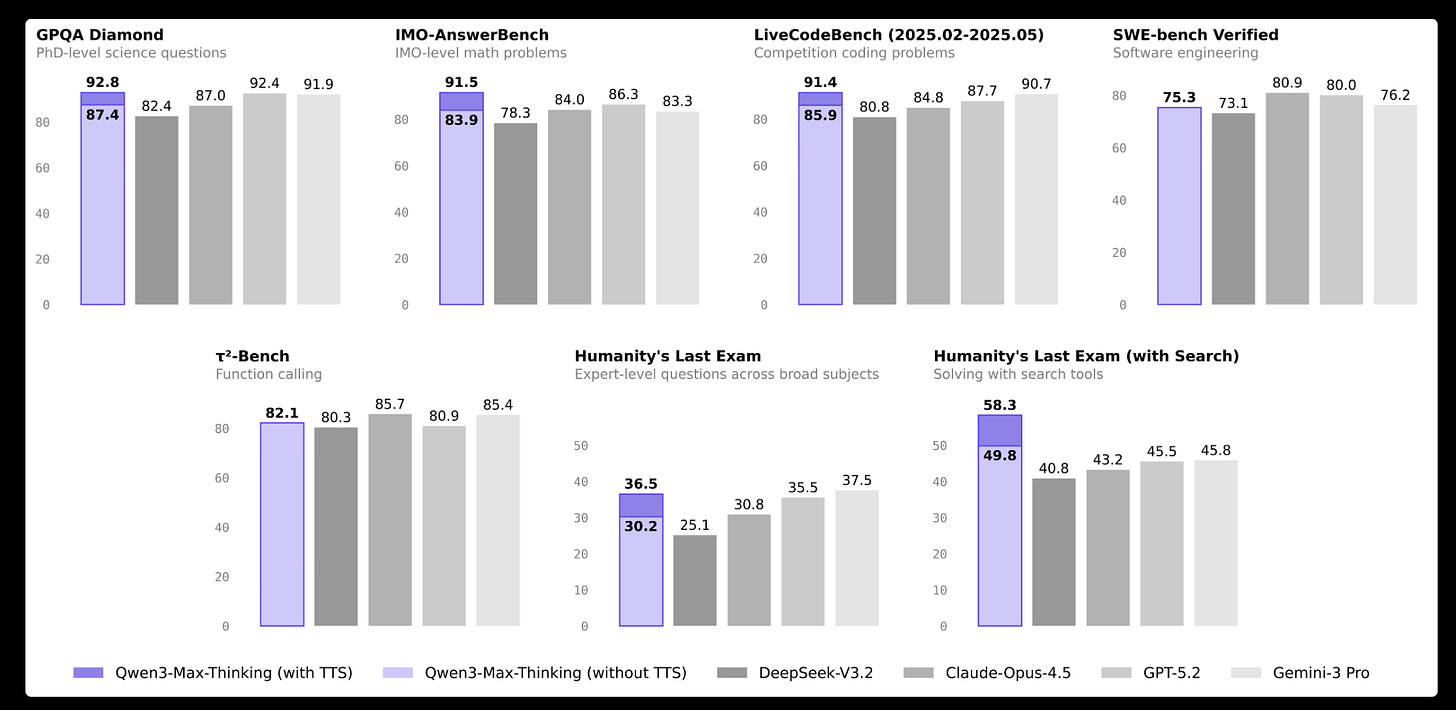
Elsewhere
The excellent Allen Institute released Open Coding Agents: Fast, accessible coding agents that adapt to any repo
The team at Black Forest Labs (originating in Germany) released their new image models: FLUX.2 [klein]: Towards Interactive Visual Intelligence




Real world applications and how to guides
Lots of applications and tips and tricks this month
First on the application side:
“AI” doesn’t solve everything! Interesting (and more traditional) ML work from Uber: Forecasting Models to Improve Driver Availability at Airports. I know well how hard it is to get these types of multiple interacting models into production!

Looks like London will be graced with autonomous driving soon - Uber and Lyft announce plans to trial Chinese robotaxis in UK in 2026 (to be honest I may wait for Waymo!)
Chinese robotaxis could be set to hit UK roads in 2026 as ride-sharing apps Uber and Lyft announce partnerships with Baidu to trial the tech. The two companies are hoping to obtain approval from regulators to test the autonomous vehicles in London.I’m not sure about AI for marketing - but it certainly makes it easier to produce content: Inside Colgate-Palmolive’s content creation gen-AI pilot
Coding Agents are getting better and better- Scaling long-running autonomous coding
To test this system, we pointed it at an ambitious goal: building a web browser from scratch. The agents ran for close to a week, writing over 1 million lines of code across 1,000 files. You can explore the source code on GitHub. Despite the codebase size, new agents can still understand it and make meaningful progress. Hundreds of workers run concurrently, pushing to the same branch with minimal conflicts.It appears AI for Health is having a moment
We’re introducing ChatGPT Health, a dedicated experience that securely brings your health information and ChatGPT’s intelligence together, to help you feel more informed, prepared, and confident navigating your health.Advancing Claude in healthcare and the life sciences
We’re introducing Claude for Healthcare, a complementary set of tools and resources that allow healthcare providers, payers, and consumers to use Claude for medical purposes through HIPAA-ready products.And Google has been at the forefront of research in this area for some time: Next generation medical image interpretation with MedGemma 1.5 and medical speech to text with MedASR

Even Amazon is throwing it’s hat in the ring
Of course - many apologies for the blatant plug - but if you are in the UK, you don’t have to wait for these things! Check out Epic Life (I have discount codes if anyone is interested!)
Lots of great tutorials and howto guides:
AI coding assistants and agents are all the rage- but how should you use them?
Vibe Coding Without System Design is a Trap
When you ask AI to build a feature, it optimizes for one thing: making it work right now. That usually means: - Hardcoding values instead of abstracting them - Taking shortcuts that reduce cognitive load in the moment - Ignoring future change, because future change wasn’t explicitly requested or anticipatedCould this be the answer to avoiding code-slop from AI tools? Verification-Driven Development (VDD)
Verification-Driven Development (VDD) is a high-integrity software engineering framework designed to eliminate "code slop" and logic gaps through a generative adversarial loop. Unlike traditional development cycles that rely on passive code reviews, VDD utilizes a specialized multi-model orchestration where a Builder AI and an Adversarial AI are placed in a high-friction feedback loop, mediated by a human developer and a granular tracking system.
And everyone wants to build AI Agents
If you need inspiration for your system prompts - lots of examples here including the extract prompts from the major foundation models
Continuing our focus on context engineering- how to supply the right information at the right time to the AI model: Context Engineering for Personalization - State Management with Long-Term Memory Notes using OpenAI Agents SDK
We’ll ground this tutorial in a travel concierge agent that helps users book flights, hotels, and car rentals with a high degree of personalization. In this tutorial, you’ll build an agent that: - starts each session with a structured user profile and curated memory notes - captures new durable preferences (for example, “I’m vegetarian”) via a dedicated tool - consolidates those preferences into long-term memory at the end of each run - resolves conflicts using a clear precedence order: latest user input → session overrides → global defaultsIf you are need of fine tuning - excellent tutorial: GRPO++: Tricks for Making RL Actually Work
GRPO is the most common RL optimizer to use for training reasoning models. Before diving deeper into the details of GRPO, we need to build an understanding of how RL is actually used to train LLMs. In particular, there are two key types of RL training that are commonly used: - Reinforcement Learning from Human Feedback (RLHF) trains the LLM using RL with rewards derived from a reward model trained on human preferences. - Reinforcement Learning with Verifiable Rewards (RLVR) trains the LLM using RL with rewards derived from rule-based or deterministic verifiers.Good question! How do language models solve Bayesian network inference? This is pretty cool
I’ll walk through the Variable Elimination algorithm since it is one of the easiest to understand and implement, solve an example by hand with it, and then compare how seven reasoning LLMs approach the same query, analyzing not just whether they get the right answer, but how they reason through the problem.Long live SHAP! Old-School Interpretability for LLMs
Mechanistic interpretability has taken most of the spotlight when it comes to the interpretation of LLMs. Unfortunately, except for some initial sparks, mechanistic interpretability hasn’t delivered. Especially not for users of large language models. But what about the good old methods of interpreting machine learning models, like Shapley values and other methods that explain the outcome by attributing it to the inputs? Explaining LLMs with such tools is a bit more complex than explaining, say, a random forest regressor on the California housing data, but it’s feasible.To be honest, I’ve generally struggled to try and replicate approaches from research papers in my own code- problem solved: Implementation of papers in 100 lines of code.
Getting into some more data science: good old matrix decomposition and eigenvalues: Behold the power of the spectrum!
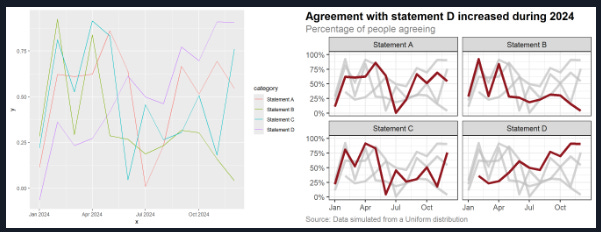
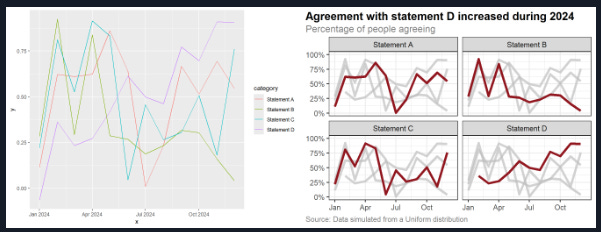
import scipy.linalg as sla import numpy as np def univariate_spectral(A, B, k, xs): """Computes the vector y[i] = λₖ(A + B * xs[i]).""" # support negative eigenvalue indices, # e.g., k=-1 is the largest eigenvalue k = k % A.shape[0] # create a batch of matrices, one for each entry in xs mats = A + B * xs[..., np.newaxis, np.newaxis] # compute the k-th eigenvalue of each matrix return sla.eigvalsh(mats, subset_by_index=(k, k)).squeeze()And I do like these type of guides: How to create a more accessible line chart



Practical tips
How to drive analytics, ML and AI into production
What is an AI/ML engineer? What do they do? Well, I'm pretty sure they are (or should be) well versed in these types of things
ML System Design Case Studies Repository
This repository is a comprehensive collection of 300+ case studies from over 80 leading companies, showcasing practical applications and insights into machine learning (ML) system designThis repository is the open learning stack for AI systems engineering. It includes the textbook source, TinyTorch, hardware kits, and upcoming co-labs that connect principles to runnable code and real devices.
Excellent dive into cost benchmarks - Without Benchmarking LLMs, You’re Likely Overpaying 5-10x
With these benchmark results, we found models with comparable quality at up to 10x lower cost. My friend chose a more conservative option that still cut costs by 5x, saving him over $1000/month. This process was painful enough that I built a tool to automate it.
The Question Your Observability Vendor Won’t Answer
I'm not a cynical person. I believed observability could make engineers' lives better. But after a decade, after hundreds of conversations with teams bleeding money across every major vendor, after hearing firsthand how their vendors strong-armed them instead of helping; I've seen enough. The whole industry has lost the plot.How I Structure My Data Pipelines
This post shares how I’ve come to structure it. My approach combines medallion, Kimball dimensional modeling, and semantic layers into a single architecture. Each pattern solves a different problem, and when you map them onto the three layers intentionally, you get something that’s both principled and practical.A view on what’s coming- Data Engineering in 2026: What Changes?
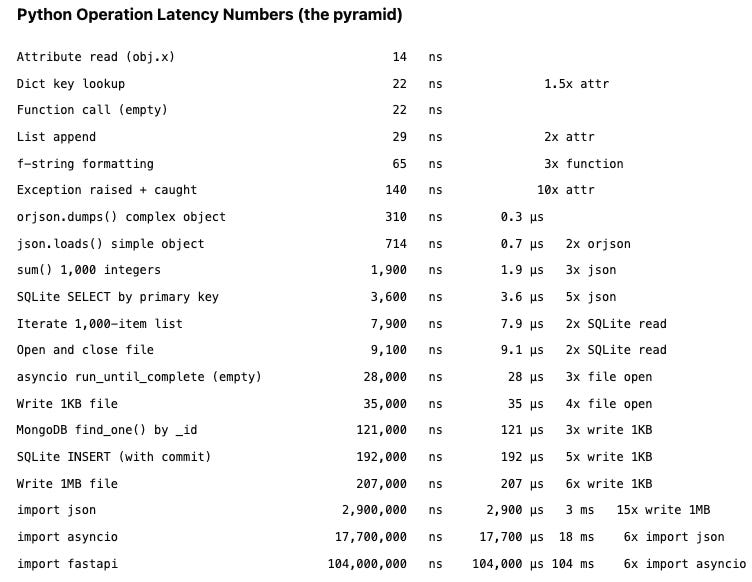
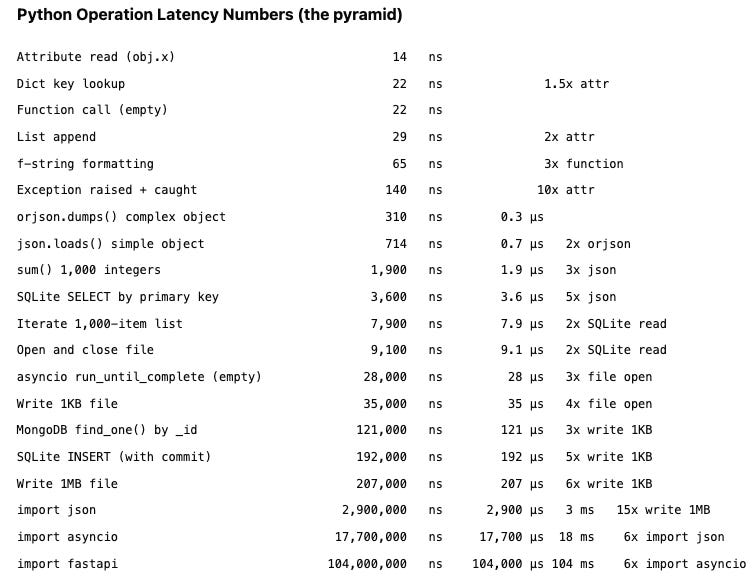
Finally, a bit of fun- Python Numbers Every Programmer Should Know

Bigger picture ideas
Longer thought provoking reads - sit back and pour a drink! ...
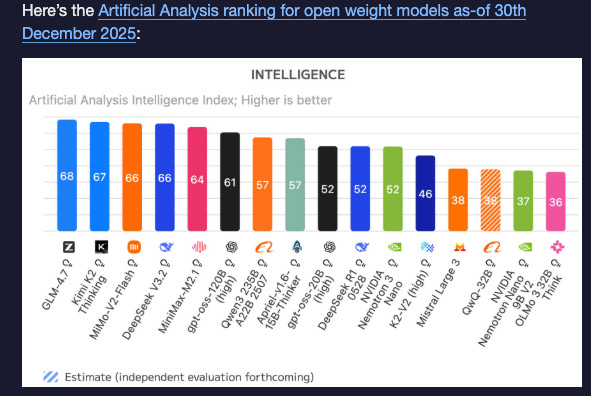
8 plots that explain the state of open models - Nathan Lambert
While many Chinese labs are making models, the adoption metrics are dominated by Qwen (with a little help from DeepSeek). Adoption of the new entrants in the open model scene in 2025, from Z.ai, MiniMax, Kimi Moonshot, and others is actually quite limited. This sets up the position where dethroning Qwen in adoption in 2026 looks impossible overall, but there are areas for opportunity.AI isn’t “just predicting the next word” anymore - Steven Adler
I’ll start by describing the critique and its implications. Then, I’ll explain how my worldview differs, in three ways: - AI systems have shown pretty remarkable (and concerning) abilities, even if just predicting the next word. - AI systems have dangerous risks worth caring about, even if just predicting the next word. - “Just predicting the next word” is no longer accurate for modern AI systems. These are more like “path-finders” that problem-solve toward answers.Claude Code and What Comes Next - Ethan Mollick
I opened Claude Code and gave it the command: “Develop a web-based or software-based startup idea that will make me $1000 a month where you do all the work by generating the idea and implementing it. i shouldn’t have to do anything at all except run some program you give me once. it shouldn’t require any coding knowledge on my part, so make sure everything works well.”The AI revolution is here. Will the economy survive the transition? - Michael Burry, Dwarkesh Patel, Patrick McKenzie and Jack Clark
It’s really surprising how much is involved in automating jobs and doing what people do. We’ve just marched through so many common-sense definitions of AGI—the Turing test is not even worth commenting on anymore; we have models that can reason and solve difficult, open-ended coding and math problems. If you showed me Gemini 3 or Claude 4.5 Opus in 2017, I would have thought it would put half of white-collar workers out of their jobs. And yet the labor market impact of AI requires spreadsheet microscopes to see, if there is indeed any.AI is Hitting a Measurement Wall - Devansh
The human brain runs on 20 watts. GPT-4’s training run consumed megawatts. And yet the brain still wins on most tasks that matter: learning from single examples, long-horizon planning, operating in novel environments without catastrophic failure. This 100,000× efficiency gap is usually dismissed as engineering immaturity. That explanation is wrong. The gap is a physics feature, not an engineering bug. Biology is computing in a fundamentally different way — operating in a physical domain that modern computers are designed to avoid.From Human Ergonomics to Agent Ergonomics - Wes McKinney
I have been building a lot of new software in Go. Except that I’ve never actually written a line of Go in my life. What is going on?AI Needs Game Designers - David Kaye
What matters isn't speed—it's that the system keeps running without you. “Gas Town can work all night,” Yegge writes, “if you feed it enough work.” You design features, file implementation plans, sling work to your agents, then check back later. The system keeps running.
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:

A very important project in my mind - Systematically Improving Espresso: Insights from Mathematical Modeling and Experiment
Espresso, one of the most widely consumed coffee beverage formats, is also the most susceptible to variation in quality. Yet, the origin of this inconsistency has traditionally, and incorrectly, been attributed to human variations. This study's mathematical model, paired with experiment, has elucidated that the grinder and water pressure play pivotal roles in achieving beverage reproducibility.Can you trick birds with magic? Exploring the perceptual inabilities of Eurasian jays (Garrulus glandarius) using magic effects - yes!
Fancy taking a class? MIT16.485 - Visual Navigation for Autonomous Vehicles

Best Data Visualization Projects of 2025


Updates from Members and Contributors
Stephen Haben and Samuel Young at the Energy Systems Catapult highlighted some excellent progress in AI usage for decarbonisation
State of AI for decarbonisation report showcasing examples of where AI is making real cost and decarbonisation saving - see also video here
Blog post highlighting AI applications in Energy
If anyone is the the market for renting GPUs Harald Carlens has updated his comparison site to include 23 providers and 1,000+ different instance configurations- very useful!
Mani Sarkar published a good tutorial on AI coding tools - well worth a look
Sabia Akram at the University of Surrey is looking for participants for a research study on improving accessibility in survey design - a very worthwhile topic
The University of Surrey is inviting blind and visually impaired individuals (aged 14 and over) to take part in a research study exploring how to make surveys more accessible with chatbots.
Participation involves:
Completing an online survey
A one-to-one online interview
A small online group workshop to discuss design ideas and accessibility solutions
To express interest, register your name and email here. You’ll receive detailed information about the study and a consent form. If you have any questions or require support with registration, please email BVIresearch@surrey.ac.uk
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you’d like to advertise
Hot off the press- new PhD opportunity! Generative AI for AML Investigator Training: Synthetic Scenario Development
If you are interested in shaping how artificial intelligence is used in practice to stop financial crime, this is an opportunity to contribute meaningful research with real-world impact.
This is a funded PhD position based in Belfast which includes a minimum of 3 months working in the Napier AI office with the RSS DS&AI Chair Dr Janet Bastiman.
Closing date for applications is end February
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS