


February Newsletter
Hi everyone-
January reminded us (in the UK at least) of the joys of a 'big coat' with 2023 definitely off to a cold start... No great change to the depressing headlines though so hopefully time for a bit of distraction with a wrap up of data science developments in the last month. Don't miss out on more ChatGPT fun and games in the middle section!
Following is the February edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. (If you are reading this on email and it is not formatting well, try viewing online at http://datasciencesection.org/)
As always- any and all feedback most welcome! If you like these, do please send on to your friends- we are looking to build a strong community of data science practitioners. And if you are not signed up to receive these automatically you can do so here.
Industrial Strength Data Science February 2023 Newsletter
RSS Data Science Section
handy new quick links:
committee; ethics; research; generative ai; applications; tutorials; practical tips; big picture ideas; fun; reader updates; jobsCommittee Activities
We are still actively planning our activities for the year, and are currently working with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is now accepting applications for the Advanced Data Science Professional certification- more details here.
In addition, the RSS is hosting a corporate workshop to discuss how the RSS can help engage employers of data scientists: "We are looking for leaders in the data/stats profession working in the private sector to contribute thoughts and ideas to help shape the RSS corporate and membership offering that will meet the needs of data strategies across private sector organisations."- Wednesday 08 February 2023, 9.00AM - 12.00PM in the Shard (book here for free)
This year’s RSS International Conference will take place in the lovely North Yorkshire spa town of Harrogate from 4-7 September. As usual Data Science is one of the topic streams on the conference programme, and there is currently an opportunity to submit your work for presentation. There are options available for 20-minute talks, 5-minute rapid-fire talks and for poster presentations – for full details visit the conference website. The deadline for talk submissions is 5 April. Registration has also opened with an extra discount for RSS Fellows available until 17 February.
The AI Standards Hub, led by Florian Ostmann, is organising a webinar on 17th February (sign up here) on harmonising standards to support the implementation of the EU AI Act. The event will feature Sebastian Hallensleben, the chair of the CEN-CENELC committee tasked with developing these standards.
Giles Pavey, Global Director of Data Science at Unilever, was featured in Tom Davenport’s new book “All in on AI” talking about how companies can implement AI Assurance in a proportionate manner.
Martin Goodson (CEO and Chief Scientist at Evolution AI) continues to run the excellent London Machine Learning meetup and is very active with events. The last event was on Jan 18th when Hattie Zhou, PhD student at MILA and the University of Montreal, presented "Teaching Algorithmic Reasoning via In-context Learning". Videos are posted on the meetup youtube channel - and future events will be posted here.
Martin has also compiled a handy list of mastodon handles as the data science and machine learning community migrates away from twitter...
This Month in Data Science
Lots of exciting data science going on, as always!
Ethics and more ethics...
Bias, ethics and diversity continue to be hot topics in data science...
We'll have lots more later on ChatGPT fun and games, but it felt like the artist backlash against generative AI was worth including here...
Artists are increasingly and loudly making their case against the generative AI tools, and are now taking their cases to the courts - see more details here (where it is described as a "A 21st-century collage tool"... ouch) as well as a response here
One of the key arguments is that the generative models have been trained on copyrighted materials without permission - in fact Getty Images has now sued Stable Diffusion as discussed here by the PinsentMasons team (if you are worried your materials might have been included in the training data, you can check here)
Of course there are similarities to the somewhat grey area of web-scraping which was ruled legal by the US courts last year
And it's not just images, as author Séamas O’Reilly points out
"I had hoped the entire book would be written in a flurry of nonsensical synonyms, with every word changed to an increasingly absurd alternative, like when song lyrics get spun back and forth between multiple languages on Google Translate.
In fact, the AI has presumably worked out exactly how little it needs to do to get out of trouble, and I get to the end of the book mostly bemused and, weirdest of all, disappointed by its lack of effort."Of course it's not just copyright infringement... the potential for harm from generative AI, deep fakes and facial recognition is significant. We have cybercriminals using ChatGPT to help launch cyber attacks, fraudsters spoofing customer voices to demand refunds, facial images used unlawfully, and authoritarian governments infringing privacy (like in Iran tracking who is breaking hijab laws).
And it's not like the tools are foolproof.. as CNET as found out... "CNET pauses publishing AI-written stories after disclosure controversy"
China is an intriguing case, as while the government can often be one of the worst culprits (China Is the World’s Biggest Face Recognition Dealer), they are also at the forefront of attempted regulation, now turning to deepfakes (more detail here)
Meanwhile the US government has released the final report from the National Artificial Intelligence Research Resource Task Force, and is becoming more increasingly involved in regulation and crackdown: Algorithms Allegedly Penalized Black Renters. The US Government Is Watching
Stepping back, it's sometimes useful to remember that we don't need AI to highlight bias in action...
"Changing my feminine first name to a masculine nickname on my resume gave me way more responses per application.
Just a heads up to any other women that this could also work for. My name isn’t typically associated with a more masculine sounding nickname so I had to get a bit creative. Happy to help anyone who needs it brainstorm a nickname.
I’m so tired."It's also useful to remember that there is lots of research going on to attempt to identify deep fakes and missinformation, and counter the effects of bias through more robust processes (e.g. AWS AI Service Cards)
At AWS, we think responsible AI encompasses a number of core dimensions including:
Fairness and bias– How a system impacts different subpopulations of users (e.g., by gender, ethnicity)
Explainability– Mechanisms to understand and evaluate the outputs of an AI system
Privacy and Security– Data protected from theft and exposure
Robustness– Mechanisms to ensure an AI system operates reliably
Governance– Processes to define, implement and enforce responsible AI practices within an organization
Transparency– Communicating information about an AI system so stakeholders can make informed choices about their use of the systemDevelopments in Data Science Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
Some promising research in combating Generative AI's fluent falsehoods and identifying AI based content:
First of all, we can attempt to build better models- DeepMind's 'Sparrow' (actually published - but not released - prior to ChatGPT) is supposedly better than CharGPT at "communicating in a way that’s more helpful, correct, and harmless" as more learning from human feedback is incorporated.
Then we have watermarking: "embedding signals into generated text that are invisible to humans but algorithmically detectable from a short span of tokens" making it easy to identify human from machine...
But who needs watermarks when you have DetectGPT which can apparently identify AI generated text without any training data, based purely on the "log probabilities computed by the model of interest"

Clearly Generative AI is very much a hot topic, so lots of research probing how to make the models better or trying different approaches:
Who needs diffusion models (the piece of DALLE etc that generates the image) when you have StyleGAN-T which apparently matches existing models but with increased speed. Of course why choose either or when you could have both- using Diffusion models to train GANs...(GANs - Generative adversarial networks - are fun and worth checking out)
But now Google has released MUSE (text to image model) which uses masked transformers and is apparantly faster still...
And not to be outdone, Meta/Facebook has released MAV3D which generates 3d videos from text!
"The dynamic video output generated from the provided text can be viewed from any camera location and angle, and can be composited into any 3D environment. MAV3D does not require any 3D or 4D data and the T2V model is trained only on Text-Image pairs and unlabeled videos"Also Generative AI keeps expanding from text and images...
Google released MusicLM which, you guessed it, generated music from text... I know, you've always wanted "a calming violin melody backed by a distorted guitar riff". And apparently, large language models are natural drummers - "fine-tuning large language models pre-trained on a massive text corpus on only hundreds of MIDI files of drum performances"
And Microsoft published VALL-E, "a language modeling approach for text to speech synthesis" (here is a pytorch version you can play around with)
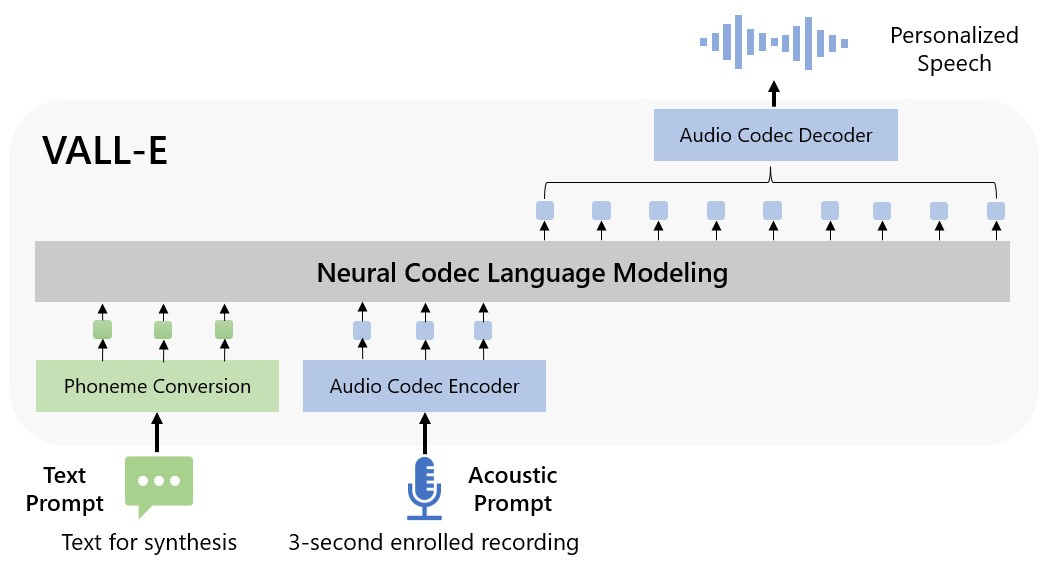
One of the key current research areas for generative models, is how best to include information external to the model (other facts or corpuses, more human feedback etc)
OpenAI have a new model which is focused on following more complex instructions (InstructGPT)
While "Demonstrate-Search-Predict" seems to be promising in terms of incorporating additional external information (Retrieval-augmented in-context learning); see also REACT for images ("a framework to acquire the relevant web knowledge to build customized visual models for target domains")
We can now adapt the output images using additional text prompts with InstructPix2Pix "given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image"
GLIGEN allows different "grounding" information to be included in the prompt to better hone the output (e.g. caption and bounding boxes along with the text prompt)
It's well documented how bad ChatGPT can be at symbolic maths problems (not really surprising when it's sort of "averaging" over all the maths out there!) - a small research team in Austria have made some impressive improvements with SymbolicAI. Wolfram Alpha think there is lots of opportunity in this space as well ... although they may be late to the game judging by this colab notebook!

A regular theme in research is making the models smaller and more efficient:
DeepMind has made progress with RETRO and Gopher
And apparently you could save an awful lot of storage space with very limited change in performance if you switched to 4-bit precision!
This is a great concept- a prize for identifying important tasks on which language models (LMs) perform worse the larger they are (“inverse scaling”).
Good news on the open source front with a new open source bi-lingual large language model released out of China, and an initial version of Open-Assistant released by the LAION-AI group - "Open Assistant is a project meant to give everyone access to a great chat based large language model." If you are struggling to keep track of all the different models, you're definitely not the only one.... this is a useful resource
Always good to see more time series research...
We have generative AI for text, for art (and I know it's used in weather forecasting) so how about time series!
And then the mouthful that is Self-supervised Contrastive Representation Learning for Semi-supervised Time-Series Classification (CA-TCC)
And everyone loves some good robot research. First of all Imperial takes Web-Scale Diffusion Models to Robotics with DALL-E-BOT... And then Google attempts to "Grasp the Ungraspable with Emergent Extrinsic Dexterity"

Finally... this blows my mind - language modelling without language!
"PIXEL is a pretrained language model that renders text as images, making it possible to transfer representations across languages based on orthographic similarity or the co-activation of pixels. PIXEL is trained to reconstruct the pixels of masked patches instead of predicting a distribution over tokens. "Generative AI ... oh my!
Still such a hot topic it feels in need of it's own section, for all things DALLE, IMAGEN, Stable Diffusion, ChatGPT...
Somewhat unsurprisingly (given zero to a million users in 5 days as discussed last month), Microsoft has made further investment in OpenAI - reportedly $10b -(official release). Various OpenAI services are already available through Microsoft's Azure Cloud
Development in ChatGPT continues ("OpenAI has hired an army of contractors to make basic coding obsolete"). Amazon is worried about private information ("Amazon begs employees not to leak corporate secrets to ChatGPT") while Google is still "freaking out about ChatGPT".
Meanwhile, applications and examples continue to impress:
Create your own app - "AI code generation for the first 80%,
styling tools for the last 20%."ChatGPT scored 70% on the USMLE medical licensing exam in the US
And apparently passed a US Bar exam practice test - more validation here
An interesting case study in providing mental health support
Finally lots of examples of using it to help with programming (more below) - for example "Iteratively Generating Data Visualization Code with ChatGPT"

Of course ChatGPT is far from perfect, and the difficulty lies in not knowing when it is wrong.
Perhaps not surprisingly, Gary Marcus ('deep learning is not enough...') is keeping track of the various types of mistakes it makes
"In terms of underlying techniques, ChatGPT is not particularly innovative ... Why hasn't the public seen programs like ChatGPT from Meta or from Google? The answer is, Google and Meta both have a lot to lose by putting out systems that make stuff up," says Meta's chief AI scientist, Yann LeCun."There has been a fair amount of discussion on the use of tools like ChatGPT in education and elsewhere:
NYC public schools have banned it - more here - although there are some proponents of it in education
Stack Overflow has banned it, as has the prestigious ICML (International Conference on Machine Learning)- "Papers that include text generated from a large-scale language model (LLM) such as ChatGPT are prohibited unless the produced text is presented as a part of the paper’s experimental analysis."
And clearly detecting when text has been generated from ChatGPT-like models will likely be very important going forward (as discussed in the Research section above) with some tools already available (e.g. GPTZero)
As mentioned above, one area when ChatGPT like tools are causing considerable interest is in coding:
Finally, stepping back - thoughtful piece from Andreessen Horowitz (Venture Capital firm): Who Owns the Generative AI Platform?; and another musing on the educational impact of these tools ("A Chat With Dead Legends & 3 Forecasts")
"The Socratic Method, named after the Greek philosopher Socrates, is anchored on dialogue between teacher and students, fueled by a continuous probing stream of questions. The method is designed to explore the underlying perspectives that inform a student’s perspective and natural interests. ... Imagine history “taught” through a chat interface that allows students to interview historical figures. Imagine a philosophy major dueling with past philosophers - or even a group of philosophers with opposing viewpoints."Real world applications of Data Science
Lots of practical examples making a difference in the real world this month!
Always good to see real world examples using cutting edge techniques -
Here Airbnb use text generation models to reshape their customer support
Ebay used a large language model (BERT) to generate embeddings for their six billion items, resulting in better search and recommendations
Perplexity.ai is attempting to combined generative results with search and source material to solve the trustfulness issue... with what looks to be good results
And Carper.ai have released new code assistants based on what they call "diff models" - models trained to predict a code diff, trained on millions of commits scraped from GitHub (for ai assisted coding also check out this comparison between ChatGPT and CoPilot - they are all pretty impressive!)
Finally Apple is launching a whole product range based (AI narrated audio books) on voice synthesis
"However, as with so many AI applications lately, this development raises questions about what might happen to human narrators working in the business—as well as concerns over who benefits most. If AI narrators become something readers commonly accept and enjoy, it could increase the leverage Apple and other tech companies have over publishers and authors who want as many people as possible to see or hear their work."It feels like large language models specifically augmented with reputable medical domain information could be incredibly useful - and it looks like DeepMind are moving in that direction with MedPALM
On a slightly smaller scale... AI for smells
Always great to see new data driving better forecasting in the public domain- congrats to the ONS Data Science Campus for their work on understanding trade flows with new shipping data
I'm probably not the only one who finds Boston Dynamics robots amazing and terrifying at the same time... now they can do construction... although for some reason I find this comforting...
Sophisticated work at Expedia on optimising rankings with cascade bandits
Also at Spotify - Survival Analysis Meets Reinforcement Learning
Finally, what looks like excellent work at LinkedIn on observational causal inference "a collection of methods to estimate treatment effects when the treatment is observed rather than randomly assigned" - well worth a read both in terms of how they do and how they have scaled it with their ocelot platform.
How does that work?
Tutorials and deep dives on different approaches and techniques
First of all more pointers on our favourite multi-purpose mechanism... transformers
"Large transformer models are mainstream nowadays, creating SoTA results for a variety of tasks. They are powerful but very expensive to train and use. The extremely high inference cost, in both time and memory, is a big bottleneck for adopting a powerful transformer for solving real-world tasks at scale."This is pretty cool- text summarisation using RLHF (reinforcement learning with human feedback) ; and another approach using Hugging Face's Flan-T5
This is an excellent Hugging Face tutorial (What Makes a Dialog Agent Useful?) that goes through the various techniques used to make ChatGPT - definitely worth a read (more great Hugging Face tutorials, on Graph Machine Learning and Object Detection)
"A few weeks ago, ChatGPT emerged and launched the public discourse into a set of obscure acronyms: RLHF, SFT, IFT, CoT, and more, all attributed to the success of ChatGPT. What are these obscure acronyms and why are they so important? We surveyed all the important papers on these topics to categorize these works, summarize takeaways from what has been done, and share what remains to be shown."Given the recent improvements in chat-bots, there is a fair bit of interest in applying the state of the art techniques to a custom domain ("how do I apply ChatGPT to my customer service?")...
How to implement Q&A against your documentation with GPT3, embeddings and Datasette
Useful background on 'Prompt Engineering' with relevant tools such as OpenPrompt and PromptSource
You may have noticed a bit of a theme here - LangChain and langchain-hub
"Large language models (LLMs) are emerging as a transformative technology, enabling developers to build applications that they previously could not. But using these LLMs in isolation is often not enough to create a truly powerful app - the real power comes when you are able to combine them with other sources of computation or knowledge.
This library is aimed at assisting in the development of those types of applications"Getting a bit more maths and statsy...
Superposition, Memorization, and Double Descent - "This suggests a naive mechanistic theory of overfitting and memorization: memorization and overfitting occur when models operate on "data point features" instead of "generalizing features"
Good tutorial on loading and manipulating data - "Welcome to the jungle, we've got fun and frames"
"Shapley values - and their popular extension, SHAP - are machine learning explainability techniques that are easy to use and interpret. However, trying to make sense of their theory can be intimidating. In this article, we will explore how Shapley values work - not using cryptic formulae, but by way of code and simplified explanations."Finally, if you really want to learn about large language models learn from the best...
And of course nanoGPT - "The simplest, fastest repository for training/finetuning medium-sized GPTs"
Practical tips
How to drive analytics and ML into production
Kicking off old-school - in praise of the plain old python function ... and in the opposite direction sketch, an ai code writing assistant for pandas!
Annotating and editing training data, weeding out and correcting bad examples is always tricky to manage - cleanlab looks like a promising open source solution (also prodi.gy)
If your using Deep Learning models you'll know how tricky they are to tune... so Google's Deep Learning Tuning Playbook could be very useful
Most MLOps platforms will include some sort of auto-retraining capability - but how important is this? Some useful tips here

Speaking of MLOps... Seldon's new open source offering might be worth taking a look at
Getting more data-centric - a look at the four core tools of the modern data stack
Going hardcore - data pipeline design patterns and how to properly test data models
If you're in the market for a data catalog... maybe checkout Recap: A Data Catalog for People Who Hate Data Catalogs
Finally.. How ELT Schedules Can Improve Root Cause Analysis For Data Engineers
“Correlation doesn’t imply causation, but it does waggle its eyebrows suggestively and gesture furtively while mouthing ‘look over there’” – Randall MunroeBigger picture ideas
Longer thought provoking reads - lean back and pour a drink! ...
“Two paradigms have always existed in computer science: one for building and one for exploring. For a long time, there was no need to put a name to them. Then came Beau Shiel.
Shiel was a manager working on Xerox’s AI Systems, and he was running into a problem. He was using tools and methodologies that relied on a linear roadmap, one where each step led toward an expected outcome. But Shiel didn’t know what the outcome was. He didn’t even know what the steps were. Like many data teams today, Shiel wasn’t building. He was exploring.
In 1983, he wrote a paper called “Power Tools for Programmers” and described his work in a new way: exploratory programming.”Jeff Dean at Google Research maps out their plans: Language, vision and generative models
“We want to build more capable machines that partner with people to accomplish a huge variety of tasks. All kinds of tasks. Complex, information-seeking tasks. Creative tasks, like creating music, drawing new pictures, or creating videos. Analysis and synthesis tasks, like crafting new documents or emails from a few sentences of guidance, or partnering with people to jointly write software together. We want to solve complex mathematical or scientific problems. Transform modalities, or translate the world’s information into any language. Diagnose complex diseases, or understand the physical world. Accomplish complex, multi-step actions in both the virtual software world and the physical world of robotics.""AI is transforming the digital world. Machines can now interpret complex images and human language. They can also generate beautiful images and language—effectively propelling us into a world of Endless Media. While this will forever change our digital lives, the physical world hasn’t yet been impacted in the same way. One major exception has been biology. Here, I’ll make the following claim:
Biology is the most powerful way to transform the physical world using AI.""One of the main ways computers are changing the textual humanities is by mediating new connections to social science. The statistical models that help sociologists understand social stratification and social change haven’t in the past contributed much to the humanities, because it’s been difficult to connect quantitative models to the richer, looser sort of evidence provided by written documents. But that barrier is dissolving""It's like a dark forest that seems eerily devoid of human life – all the living creatures are hidden beneath the ground or up in trees. If they reveal themselves, they risk being attacked by automated predators.
Humans who want to engage in informal, unoptimised, personal interactions have to hide in closed spaces like invite-only Slack channels, Discord groups, email newsletters, small-scale blogs, and digital gardens. Or make themselves illegible and algorithmically incoherent in public venues."Now, if obtaining the ability of perfect language modeling entails intelligence ("AI-complete"), why did I maintain that building the largest possible language model won't "solve everything"? and was I wrong? ...
Was I wrong? sort of. I was definitely surprised by the abilities demonstrated by large language models. There turned out to be a phase shift somewhere between 60B parameters and 175B parameters, that made language models super impressive. They do a lot more than what I thought a language model trained on text and based on RNNs/LSTMs/Transformers could ever do. They certainly do all the things I had in mind when I cockily said they will "not solve everything"."Large language models (LLMs) explicitly learn massive statistical correlations among tokens. But do they implicitly learn to form abstract concepts and rules that allow them to make analogies?"Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
Small data projects - Arts and culture in London
Covid Corner
Apparently Covid is over - certainly there are very limited restrictions in the UK now
The latest results from the ONS tracking study estimates 1 in 70 people in England have Covid (a positive move from last month's 1 in 45) ... but till a far cry from the 1 in 1000 we had in the summer of 2021.
Updates from Members and Contributors
Alison Bailey at the ONS Data Science Campus draws our attention to the UNECE starter guide to using synthetic data for those working in official statistics. The guide provides the reader with info on synthetic data concepts and methods, as well as tools, tips, and practical advice on their implementation within a statistical office, as well as entry points into the academic literature.
George Richardson highlights what looks to be an excellent Medium blog that Nesta's Data Analytics team publishes = Nesta is an not-for-profit 'innovation agency' in the UK that tackles issues related to early years, sustainability and health using design, data and other methods
In addition to the piece quoted in the ethics section on copyright issues with generative art, Mark Marfé and colleagues at Pinsent Masons have published "UK text and data mining copyright exception proposals set to be watered down"
Fresh from the success of their ESSnet Web Intelligence Network webinars, the ONS Data Science campus have another excellent webinar coming up:
23 Feb’23 – Methods of Processing and Analysing of Web-Scraped Tourism Data. This webinar will discuss the issues of data sources available in tourism statistics. We will present how to search for new data sources and how to analyse them. We will review and apply methods for merging and combining the web scraped data with other sources, using various programming environments. Sign up here
Jobs!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
This looks like a really interesting opportunity - Data Scientist at OurWorldInData - see here for details. OurWorldInData is a nonprofit with close ties to the University of Oxford, with a mission to make the world's data and research easier to access and understand, so that we can collectively make progress against some of the big problems facing humanity, such as climate change, poverty, and much more
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Napier AI are looking to hire a Senior Data Scientist (Machine Learning Engineer) and a Data Engineer
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here.
- Piers
The views expressed are our own and do not necessarily represent those of the RSS