
April Newsletter
Industrial Strength Data Science and AI
Hi everyone-
Another month flies by and as always lots going on in the world of AI and Data Science… I really encourage you to read on, but some edited highlights if you are short for time!
Get a real understanding of how LLMs work from 15mins listening to Yann LeCun speak with Lex …
Have a look at the future with TfL's AI Tube Station experiment …
Is 2024 going to be the year of the Robot?
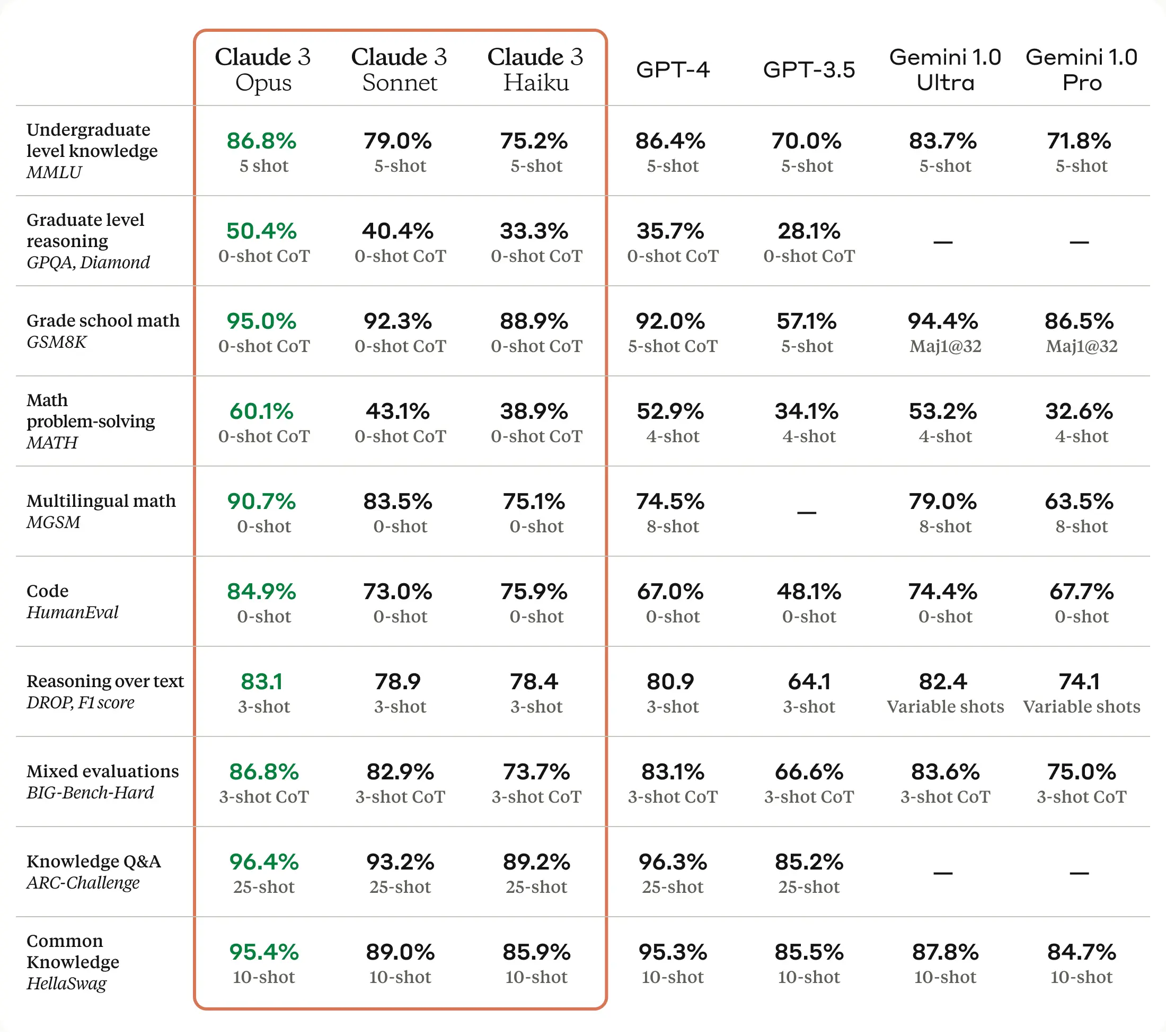
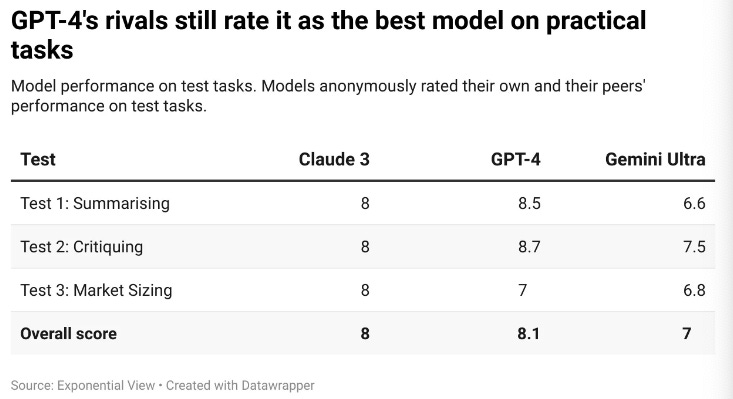
Which model to use? Putting GPT-4's new rivals to the test
And Stephen Wolfram’s take Can AI Solve Science?
Following is the April edition of our Royal Statistical Society Data Science and AI Section newsletter. Hopefully some interesting topics and titbits to feed your data science curiosity. NOTE: If the email doesn’t display properly (it is pretty long…) click on the “Open Online” link at the top right. Feedback welcome!
handy new quick links: committee; ethics; research; generative ai; applications; practical tips; big picture ideas; fun; reader updates; jobs
Committee Activities
We are continuing our work with the Alliance for Data Science professionals on expanding the previously announced individual accreditation (Advanced Data Science Professional certification) into university course accreditation. Remember also that the RSS is accepting applications for the Advanced Data Science Professional certification as well as the new Data Science Professional certification.
In fact we’re delighted to announce that the Alliance for Data Science Professionals (AfDSP), of which the RSS is a founding member, is a finalist in the 2024 British Data Awards- huge congratulations to Rachel Hilliam and the team.
Some great recent content published by Brian Tarran on our sister blog, Real World Data Science:
Democratizing Data: Using natural language processing and machine learning to capture dataset usage with Julia Lane, professor at the NYU Wagner Graduate School of Public Service
Data science and AI in financial services: An interview with Nationwide’s Matthew Jones, talking career path, data science tools and skills, and the role of AI in financial services.
The line-up of sessions for September’s RSS International Conference has been announced with a strong Data Science & AI component, with topics including Digital Twins, Generative AI, Data Science for Social Good, and the section’s own session asking ‘All Statisticians are Data Scientists?’. There is still time to get yourself on the programme with submissions for individual talks and posters open until 5 April.
Martin Goodson, CEO and Chief Scientist at Evolution AI, continues to run the excellent London Machine Learning meetup and is very active with events. The last event was on March 27th, when Meng Fang, Assistant Professor in AI at the University of Liverpool, presented "Large Language Models Are Neurosymbolic Reasoners”. Videos are posted on the meetup youtube channel - and future events will be posted here.
This Month in Data Science
Lots of exciting data science and AI going on, as always!
Ethics and more ethics...
Bias, ethics, diversity and regulation continue to be hot topics in data science and AI...
Well, the big news on the regulatory front is that the EU AI Act was formally approved by the European Union
Official release here
“The AI Act has pushed the development of AI in a direction where humans are in control of the technology, and where the technology will help us leverage new discoveries for economic growth, societal progress, and to unlock human potential,” Tudorache said on social media on Tuesday.Although plenty of commentary that we should be regulating applications rather than technology… we don’t after-all have an ‘EU Database Act’
We learnt last month that the US patent office confirms AI can’t hold patents … but this is not the case globally:
Meanwhile OpenAI is attempting to appease the growing number of training data related copyright infringement lawsuits it faces by forming partnerships with publishers
"In partnership with Le Monde and Prisa Media, our goal is to enable ChatGPT users around the world to connect with the news in new ways that are interactive and insightful.Elsewhere, the Indian government had an interesting foray into AI regulation…
First, they announced that all AI must have government approval…
"All artificial intelligence (AI) models, large-language models (LLMs), software using generative AI or any algorithms that are currently being tested, are in the beta stage of development or are unreliable in any form must seek “explicit permission of the government of India” before being deployed for users on the Indian internet, the government said."… but then heavily revised the plan 2 weeks later
The Ministry of Electronics and IT shared an updated AI advisory with industry stakeholders on Friday that no longer asked them to take the government approval before launching or deploying an AI model to users in the South Asian market.
Meanwhile (following on from examples in the UAE, and China), the Japanese have entered the ‘national LLM development race’, with Sakana
"To test our approach, we initially tested our method to automatically evolve for us a Japanese Large Language Model (LLM) capable of Math reasoning, and a Japanese Vision-Language Model (VLM)."Talk about clear and present danger… autonomous killer drones…
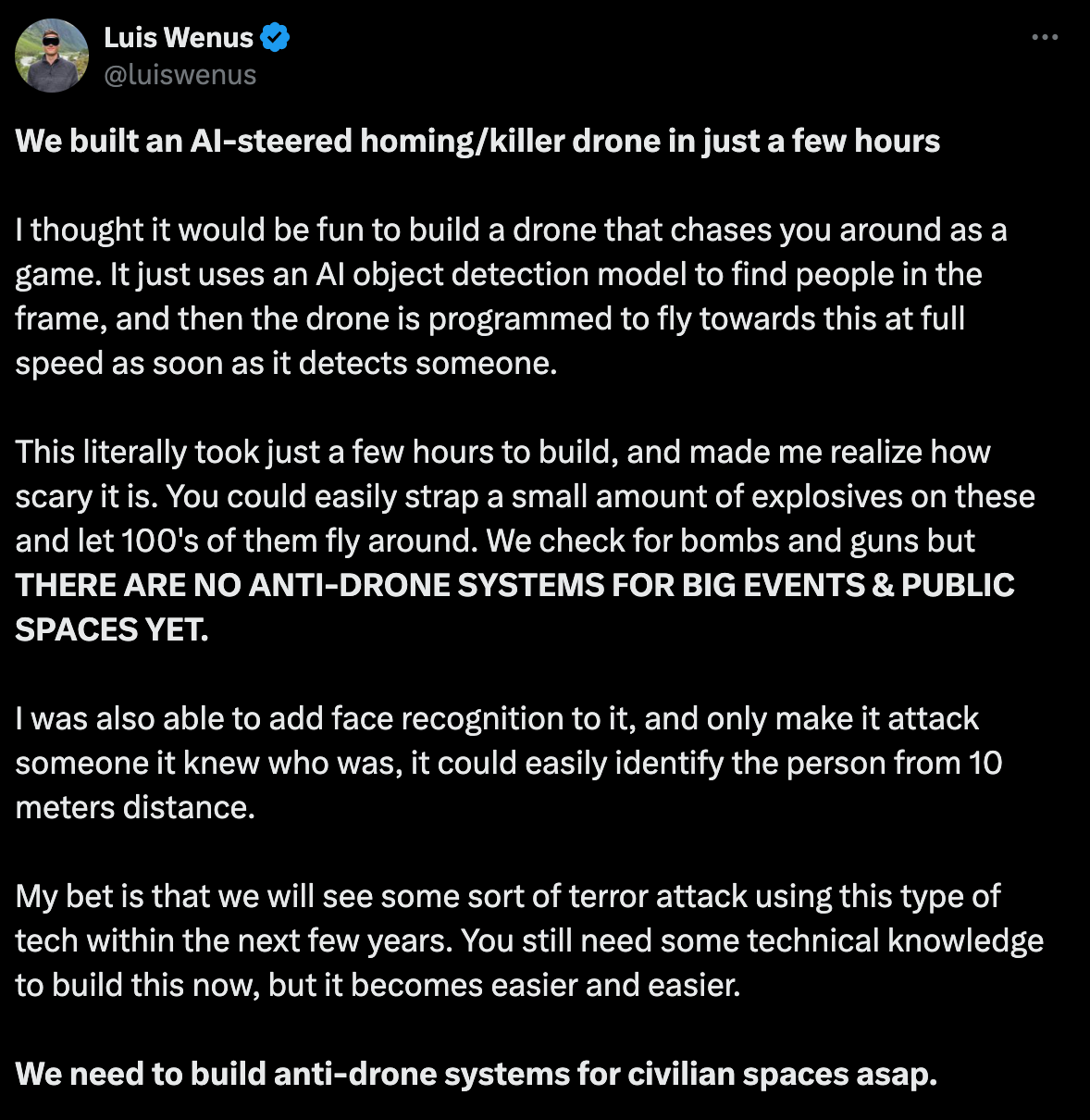
Deepfake’s continue to be a real concern…
Trump supporters target black voters with faked AI images
"Donald Trump supporters have been creating and sharing AI-generated fake images of black voters to encourage African Americans to vote Republican. BBC Panorama discovered dozens of deepfakes portraying black people as supporting the former president."Deepfake democracy: Behind the AI trickery shaping India’s 2024 election
"“Of course, it was AI-generated though it looks completely real,” the Congress party leader told Al Jazeera. “But a normal voter would not be able to distinguish; voting had started [when the video was posted] and there was no time for [the opposition campaign] to control the damage."
In more positive news
Progress in our ability to use encrypted data to train machine learning models- Training Predictive Models on Encrypted Data using Fully Homomorphic Encryption (homomorphic encryption allows computations to be performed on encrypted data without first having to decrypt it)
And maybe hacking competitions are the route to AI safety?
"This new field of AI security testing is an interesting area of research, and Google understood that really early on. Their goal is to have an efficient Security Red Teaming process when using AIs in their product, and it is why their Bug Bounty team ran the event "LLM bugSWAT". They challenged researchers from all around the world to try to find vulnerabilities that they hadn't identified themselves."
We’ve heard a lot about AI taking jobs… maybe it is starting to happen: Klarna AI assistant handles two-thirds of customer service chats in its first month
Finally, a great post about TfL's AI Tube Station experiment - an essential read
"That’s why I’m delighted today to bring you the full, jaw-dropping story of TfL’s Willesden AI trial. Thanks to the Freedom of Information Act, I’ve obtained a number of documents that reveal the full extent of what the trial was trying to achieve – and what TfL was able to learn by putting it into practice.

Developments in Data Science and AI Research...
As always, lots of new developments on the research front and plenty of arXiv papers to read...
First of all, some research from people we generally hear less from:
IBM exploring scientific knowledge LLMs with NASA
"These models used about 268 million text pairs, including titles and abstracts, and questions and answers. As a result, they excel at retrieving relevant passages in a test set of about 400 questions that NASA curated. This is evidenced by a 6.5% improvement over a similarly fine-tuned RoBERTa model, and a 5% improvement over BGE-base, another popular open-source model for embeddings."And Apple releases MM1, a family of Multi-modal LLMs (paper here)
"Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance"
Good progress in long form video understanding from Stanford using agents- VideoAgent: Long-form Video Understanding with Large Language Model as Agent
"We introduce a novel agent-based system, VideoAgent, that employs a large language model as a central agent to iteratively identify and compile crucial information to answer a question, with vision-language foundation models serving as tools to translate and retrieve visual information. "In the spirit of ‘predict the next token’… Beyond Language Models: Byte Models are Digital World Simulators - with repo here … woah
"bGPT supports generative modelling via next byte prediction on any type of data and can perform any task executable on a computer, showcasing the capability to simulate all activities within the digital world, with its potential only limited by computational resources and our imagination."Doing more with less:
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
"We introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It matches the full-precision (i.e., FP16 or BF16) Transformer LLM with the same model size and training tokens in terms of both perplexity and end-task performance, while being significantly more cost-effective in terms of latency, memory, throughput, and energy consumption"More efficient LLMs using “Mixing Gated Linear Recurrences with Local Attention”
"We propose Hawk, an RNN with gated linear recurrences, and Griffin, a hybrid model that mixes gated linear recurrences with local attention. Hawk exceeds the reported performance of Mamba on downstream tasks, while Griffin matches the performance of Llama-2 despite being trained on over 6 times fewer tokens. We also show that Griffin can extrapolate on sequences significantly longer than those seen during training"
Getting more from existing LLMs…
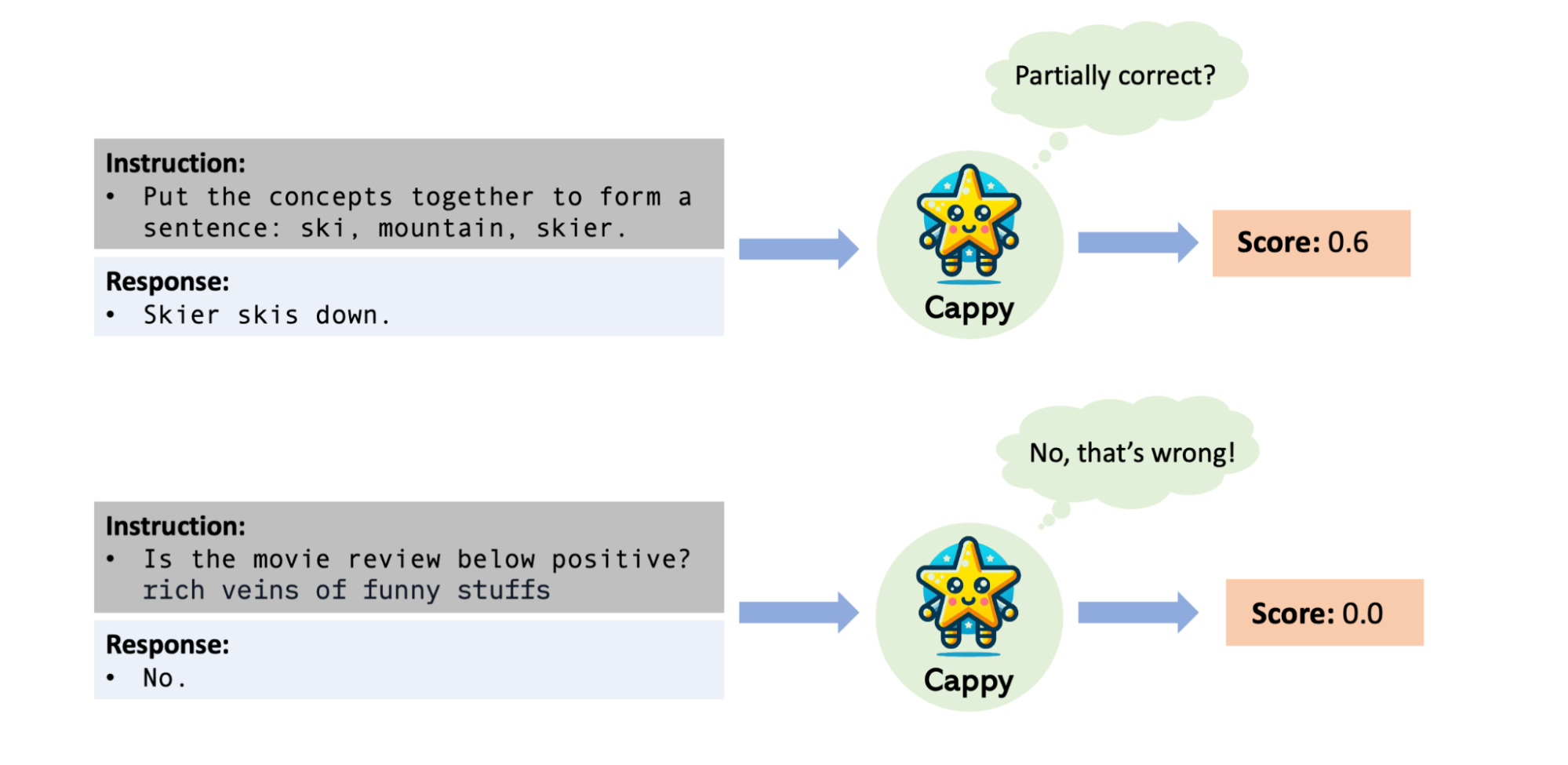
Cappy: Outperforming and boosting large multi-task language models with a small scorer
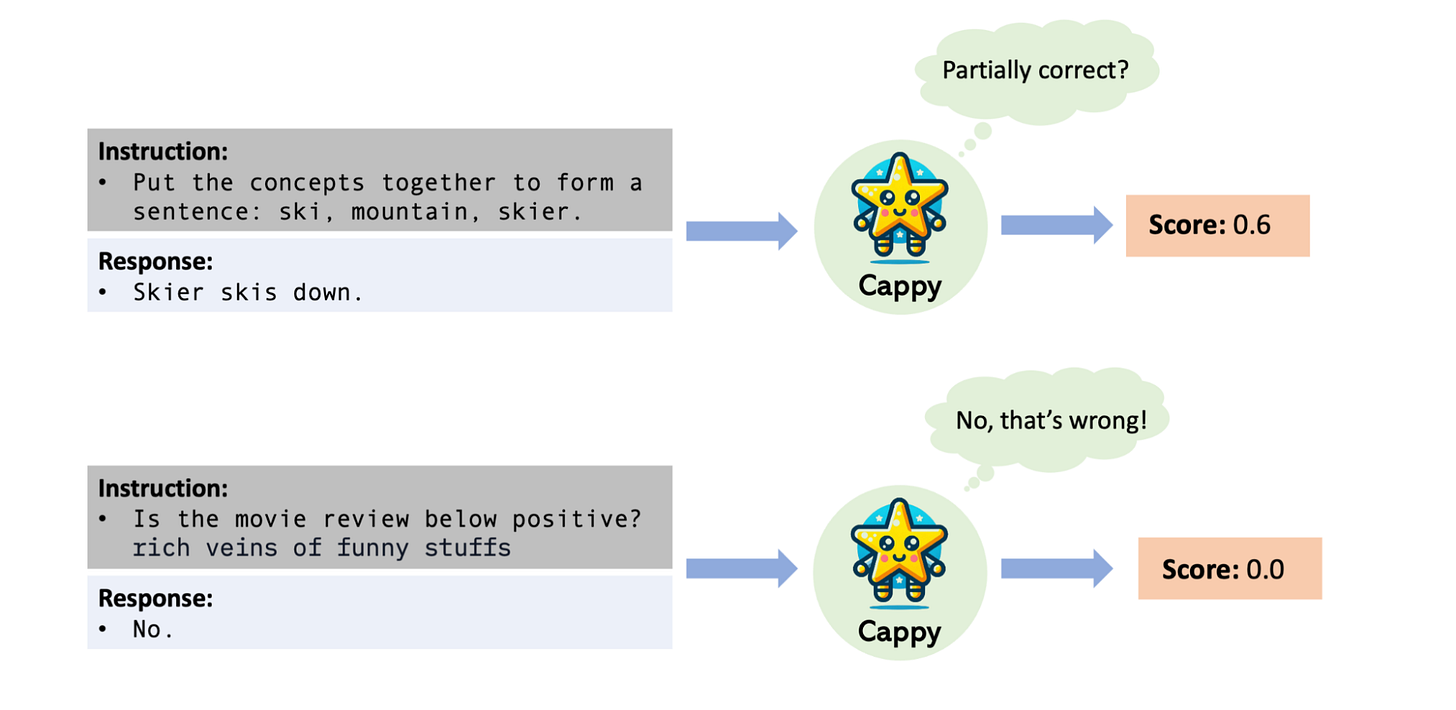
Chain-of-Spot: Interactive Reasoning Improves Large Vision-language Models - encourages Large Vision-Language Models to identify the region of interest (ROI) in the image condition on the question and reasoning through an interactive manner, thereby improving the ability of visual understanding.

Self-Consistency Improves Chain of Thought Reasoning in Language Models
"In this paper, we propose a new decoding strategy, self-consistency, to replace the naive greedy decoding used in chain-of-thought prompting. It first samples a diverse set of reasoning paths instead of only taking the greedy one, and then selects the most consistent answer by marginalizing out the sampled reasoning paths"Efficient Tool Use with Chain-of-Abstraction Reasoning
"This planning with abstract chains enables LLMs to learn more general reasoning strategies, which are robust to shifts of domain knowledge (e.g., math results) relevant to different reasoning questions. It also allows LLMs to perform decoding and calling of external tools in parallel, which avoids the inference delay caused by waiting for tool responses. In mathematical reasoning and Wiki QA domains, we show that our method consistently outperforms previous chain-of-thought and tool-augmented baselines on both in-distribution and out-of-distribution test sets, with an average ~6% absolute QA accuracy improvement"Then again… do we really need any “Chain-of”… why can’t the LLM learn the best way of breaking a problem down… Self-Discover: Large Language Models Self-Compose Reasoning Structures
"Core to the framework is a self-discovery process where LLMs select multiple atomic reasoning modules such as critical thinking and step-by-step thinking, and compose them into an explicit reasoning structure for LLMs to follow during decoding"This looks promising - Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking - one of the issues Yann LeCun raises with current LLMs is their inabiltiy to plan out a response prior to generating it.
"We address key challenges, including 1) the computational cost of generating continuations, 2) the fact that the LM does not initially know how to generate or use internal thoughts, and 3) the need to predict beyond individual next tokens. To resolve these, we propose a tokenwise parallel sampling algorithm, using learnable tokens indicating a thought’s start and end, and an extended teacher-forcing technique. Encouragingly, generated rationales disproportionately help model difficult-to-predict tokens and improve the LM’s ability to directly answer difficult questions"
More fun and games in the forecasting/time-series arena…
LLMs as ‘superforecasters’ - Approaching Human-Level Forecasting with Language Models
"Towards this goal, we develop a retrieval-augmented LM system designed to automatically search for relevant information, generate forecasts, and aggregate predictions. To facilitate our study, we collect a large dataset of questions from competitive forecasting platforms. Under a test set published after the knowledge cut-offs of our LMs, we evaluate the end-to-end performance of our system against the aggregates of human forecasts. On average, the system nears the crowd aggregate of competitive forecasters, and in some settings surpasses it."MOIRAI: Salesforce's Foundation Model for Time-Series Forecasting - A novel transformer-encoder architecture, functioning as a universal time-series forecasting model
From Amazon Science - Chronos: Learning the Language of Time Series
"Chronos is a family of pretrained time series forecasting models based on language model architectures. A time series is transformed into a sequence of tokens via scaling and quantization, and a language model is trained on these tokens using the cross-entropy loss. Once trained, probabilistic forecasts are obtained by sampling multiple future trajectories given the historical context. Chronos models have been trained on a large corpus of publicly available time series data, as well as synthetic data generated using Gaussian processes"
Some groundbreaking research from DeepMind for generating interactive environments
Genie - A Foundation Model for Playable Worlds (paper here)
"Genie can be prompted with images it has never seen before, such as real world photographs or sketches, enabling people to interact with their imagined virtual worlds-–essentially acting as a foundation world model. This is possible despite training without any action labels. Instead, Genie is trained from a large dataset of publicly available Internet videos. We focus on videos of 2D platformer games and robotics but our method is general and should work for any type of domain, and is scalable to ever larger Internet datasets. Amazingly, it only takes a single image to create an entire new interactive environment"
And SIMA - A generalist AI agent for 3D virtual environments
"We partnered with game developers to train SIMA on a variety of video games. This research marks the first time an agent has demonstrated it can understand a broad range of gaming worlds, and follow natural-language instructions to carry out tasks within them, as a human might."
Finally, will 2024 be the year of the robot?
Humanoid Locomotion as Next Token Prediction
"We show that our model enables a full-sized humanoid to walk in San Francisco zero-shot. Our model can transfer to the real world even when trained on only 27 hours of walking data, and can generalize to commands not seen during training like walking backward."Introducing RFM-1: Giving robots human-like reasoning capabilities
This is pretty mindblowing… you have to have a quick look


Generative AI ... oh my!
Still such a hot topic it feels in need of it's own section, for all things DALLE, IMAGEN, Stable Diffusion, ChatGPT...
OpenAI in the news, as always…
Elon Musk, an early investor, decides to sue OpenAI for moving away from its open source routes… The official filing here with a pretty swift and dismissive response from OpenAI here
"Elon soon chose to leave OpenAI, saying that our probability of success was 0, and that he planned to build an AGI competitor within Tesla. When he left in late February 2018, he told our team he was supportive of us finding our own path to raising billions of dollars. In December 2018, Elon sent us an email saying “Even raising several hundred million won’t be enough. This needs billions per year immediately or forget it.”Meanwhile, rumours of a ChatGPT upgrade…
Microsoft is wasting no time…
First in bringing the best of OpenAI ‘to the masses’ - Microsoft has added the GPT-4 Turbo LLM to the free version of Copilot
And then in hedging its bets… Just as Inflexion announced their new model, they also announced a significant partnership with Microsoft, which including the founders departing to head up a new Microsoft AI division
Google meanwhile (in addition to all their cutting edge research releases) continues its policy of ‘embedding AI in everything’…
New ways we’re tackling spammy, low-quality content on Search
Google Is Paying Publishers to Test an Unreleased Gen AI Platform
"Google launched a private program for a handful of independent publishers last month, providing the news organizations with beta access to an unreleased generative artificial intelligence platform in exchange for receiving analytics and feedback, according to documents seen by ADWEEK"
Amazon also plugging away with AI features … Amazon selling partners can now access even more generative AI features to create high-quality product listings
Anthropic made big news with their new model, Claude 3
Introducing the next generation of Claude
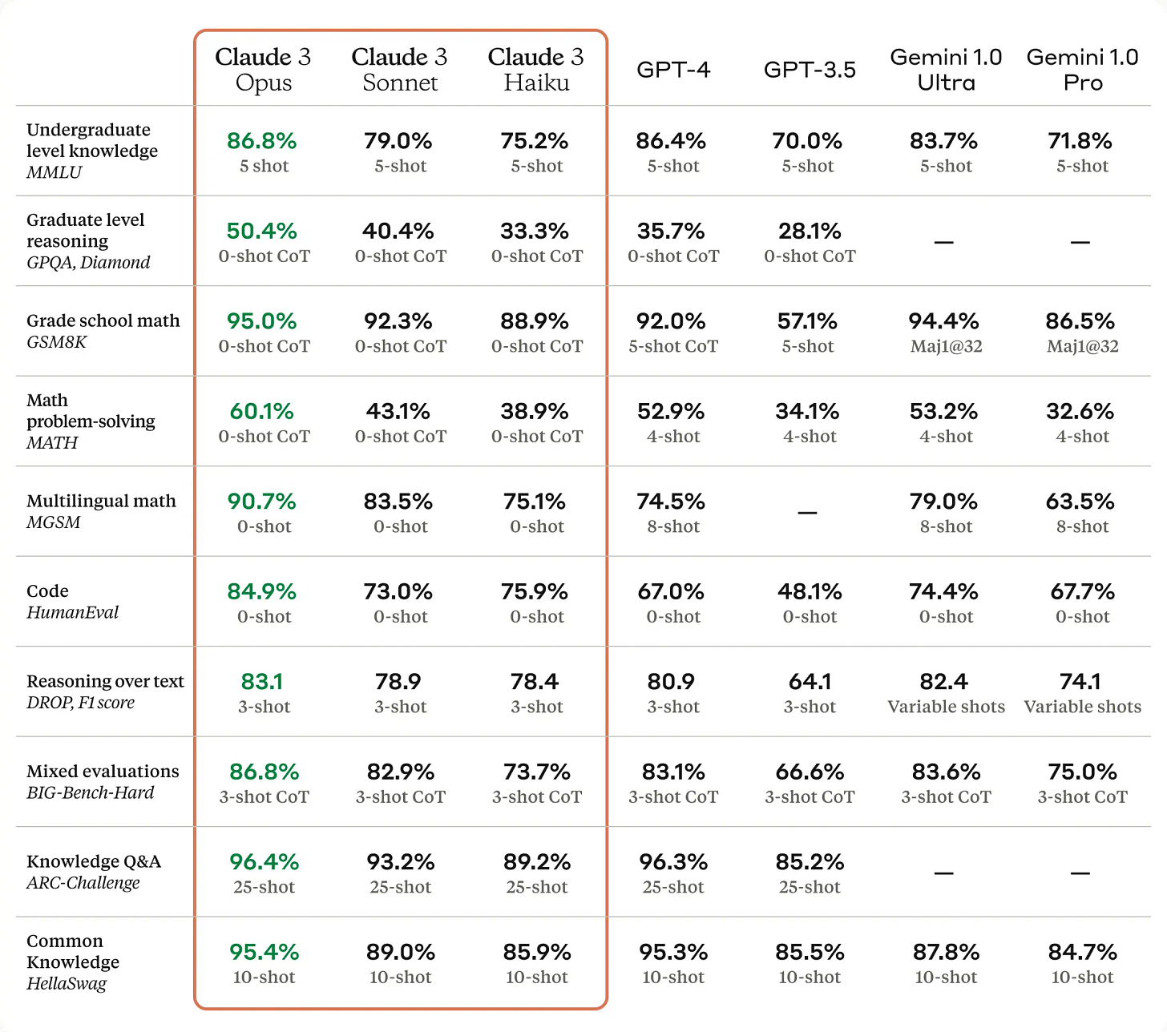
Impressive capabilities in knowledge retrieval

And Apple seems to be playing all sides… in addition to the MM1 release mentioned above, their purchased DarwinAI, and seem to exploring deals with Google and/or OpenAI
"Apple is reportedly in “active negotiations” with Google to bring its Gemini generative AI technology to the iPhone, Bloomberg reports, and has also considered using OpenAI’s ChatGPT."
Lots of open source news as well
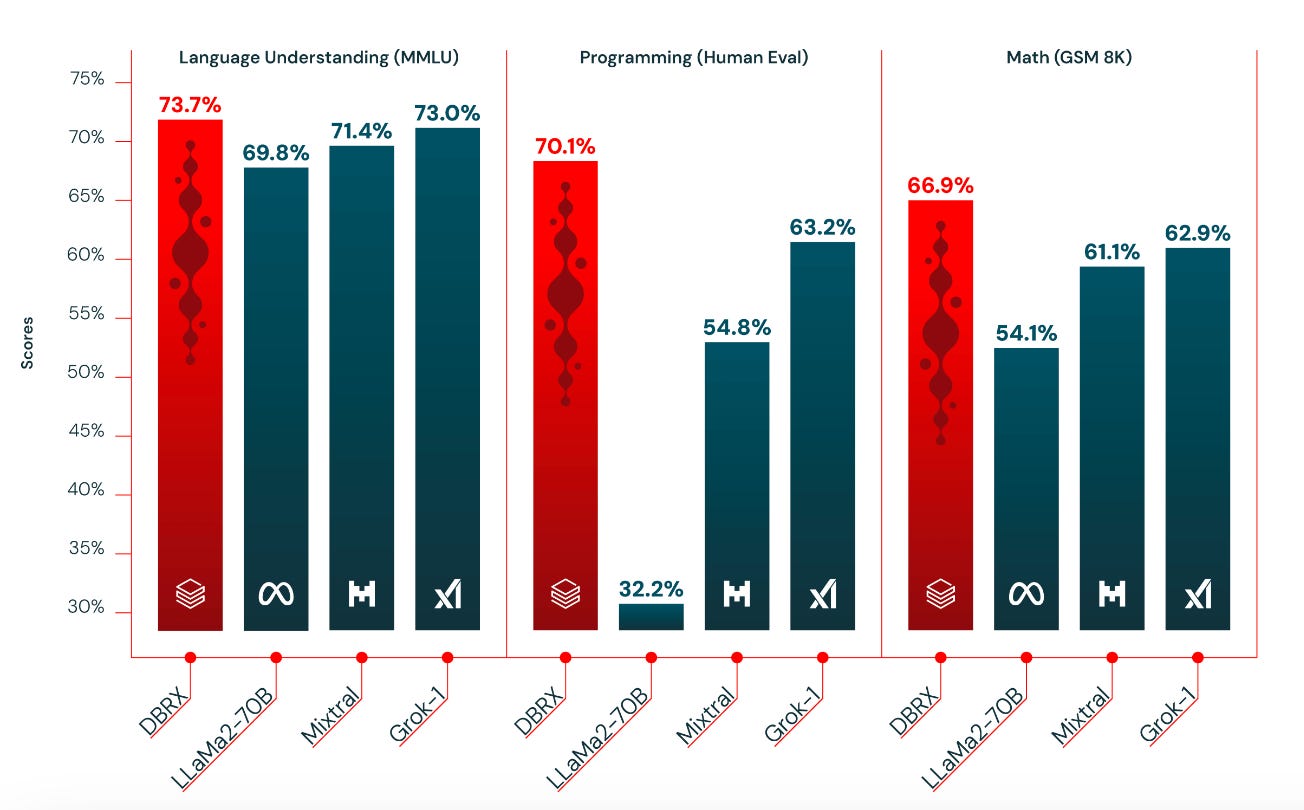
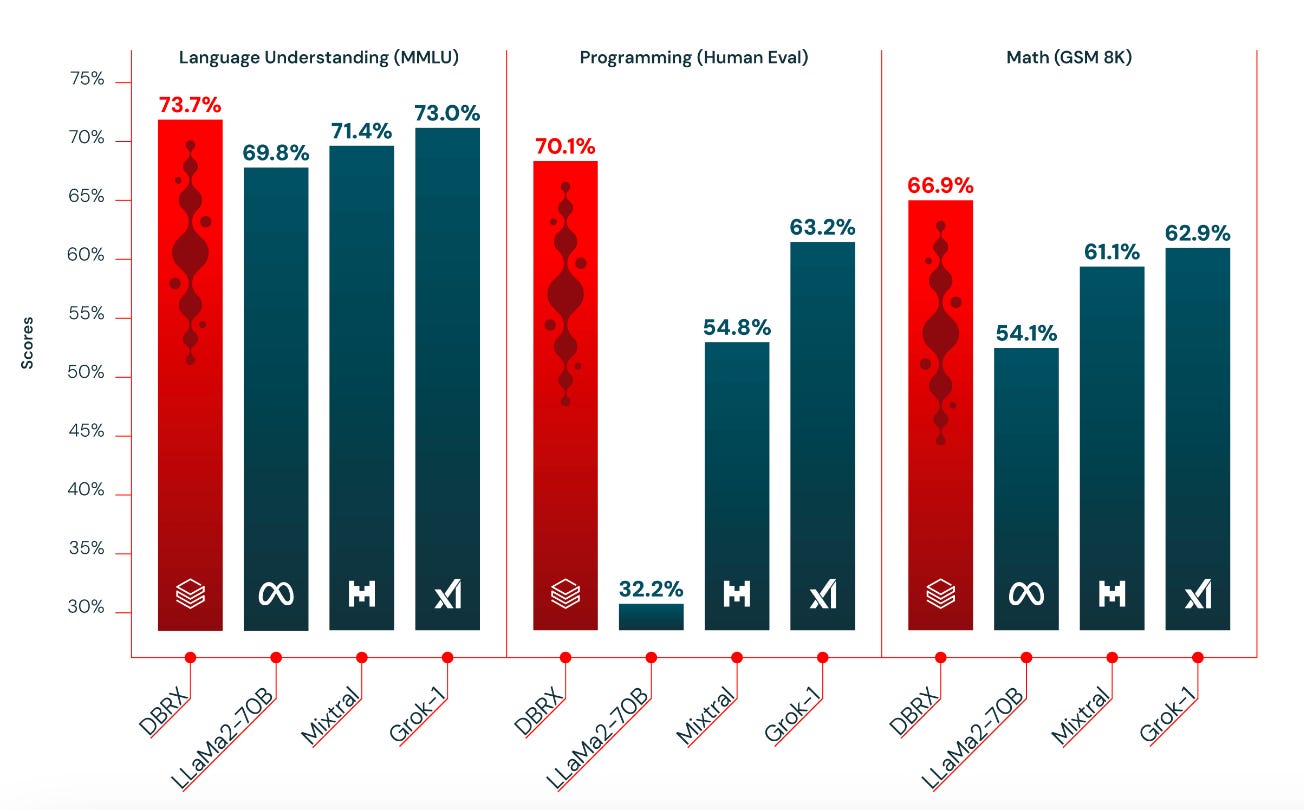
A ‘new kid on the block’ - Databricks (really Mosaic) enters the fray with DBRX
Fresh off the heals of Open-AI’s Sora video generation model, we have Open_Sora
And Stability.ai released Stable Video 3D … although apparently all is not perfect there, with the sudden departure of their CEO
How do all the new models stack-up?
And we are still learning how to tweak and improve GPT-4
Improving GPT-4’s Visual Reasoning with Prompting - really interesting- asking ChatGPT to describe the scene before asking the question improves accuracy…
Are Agents poised to be the next big thing?
Andrew Ng certainly believes in the potential
"Today, we mostly use LLMs in zero-shot mode, prompting a model to generate final output token by token without revising its work. This is akin to asking someone to compose an essay from start to finish, typing straight through with no backspacing allowed, and expecting a high-quality result. Despite the difficulty, LLMs do amazingly well at this task! With an agent workflow, however, we can ask the LLM to iterate over a document many times."And a new AI software engineer agent is causing quite a stir… Introducing Devin
Finally, some useful commentary and guides…
First on prompting: Captain's log: the irreducible weirdness of prompting AIs (see also Anthropic’s prompt library)
And more on the ‘ever promising but really hard to do well’ RAG (Retrieval-Augmented Generation)
Better RAG 1: Advanced Basics - great explainer from Hugging Face
RAFT: Adapting Language Model to Domain Specific RAG
"RAFT focuses on a narrower but increasingly popular domain than the general open book exam, called the domain-specific open-book exam. In domain-specific open book exam, we know apriori the domain in which the LLM will be tested --- used for inference. The LLM can respond to the users' prompt using use any and all information from this specific domain, which it has been fine-tuned on. Examples of domain specific examples include enterprise documents, latest news, code repositories belonging to an organization, etc. In all these scenarios, the LLM will be used to respond to the questions, whose answers can be found within a collection of documents (a small practical domain). The retrieval technique itself has little to no-impact on the mechanism (though it may impact the accuracy)."


Real world applications and how to guides
Lots of practical examples and tips and tricks this month
Some interesting practical examples of using AI capabilities in the wild
A ChatGPT for Music Is Here. Inside Suno, the Startup Changing Everything - you really have to listen to the demo…
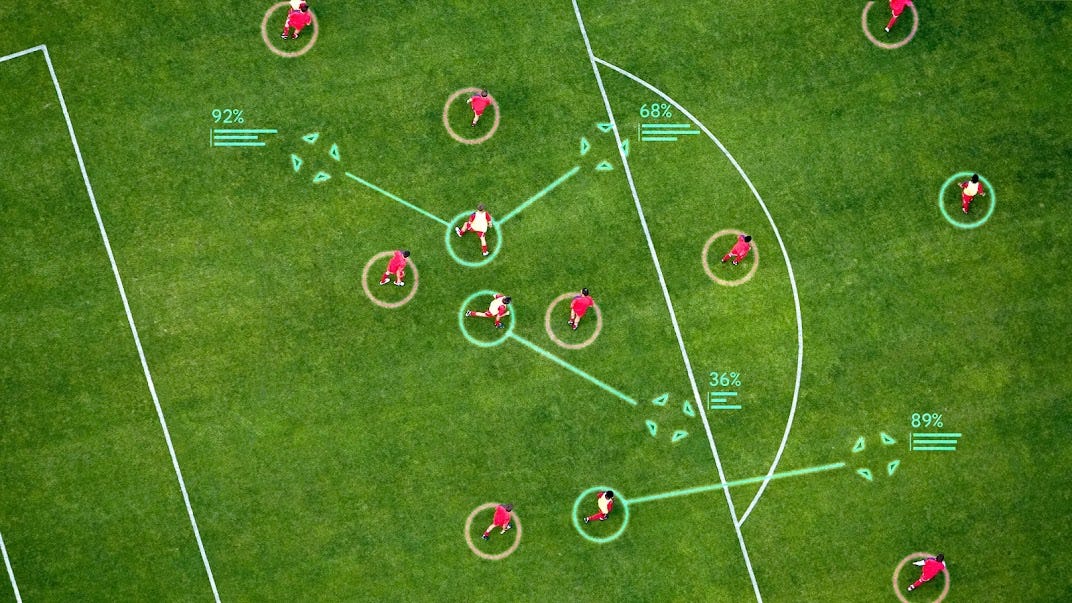
DeepMind brings advanced AI to football tactics

Using AI to analyse 30,000 school policies across 1,000 school websites
Fitbit Using Google Gemini for New AI That Could Become Your Fitness Coach
AI solves huge problem holding back fusion power
“We don’t teach the reinforcement learning model all of the complex physics of a fusion reaction,” said co-author Azarakhsh Jalalvand. “We tell it what the goal is — to maintain a high-powered reaction — what to avoid — a tearing mode instability — and the knobs it can turn to achieve those outcomes.”Evo: DNA foundation modeling from molecular to genome scale
"ZERO-SHOT GENE ESSENTIALITY TESTING Strikingly, Evo understands biological function at the whole genome level. Using an in silico gene essentiality test, Evo can predict which genes are essential to an organism’s survival based on small DNA mutations. It can do so zero-shot and with no supervision. For comparison, a gene essentiality experiment in the laboratory could require 6 months to a year of experimental effort. In contrast, we replace this with a few forward passes through a neural network."
Very impressive- optimising chemical reactions through a combination of AI driven software and hardware: Automated self-optimization, intensification, and scale-up of photocatalysis in flow
"In response to the need for efficient optimization of complex photocatalytic reaction conditions, we have developed a robotic platform named RoboChem. RoboChem facilitates the self-optimization, intensification, and scale-up of photocatalytic transformations. By integrating readily available hardware, customized software, and a Bayesian optimization (BO) algorithm, this platform offers a hands-free and safe solution, mitigating associated challenges. "
Good insight into from Lyft on their platform for Contextual Bandits: Lyft’s Reinforcement Learning Platform (speaking of which… this Bayesian Bandits repo looks interesting)
Lots of great tutorials and how-to’s this month
Building Recommendation System with Deep Reinforcement Learning and Neo4j
Diffusion models from scratch, from a new theoretical perspective
Calibration: Why Model Scores Aren't Probabilities and How to Generate Them?
The Adam Optimiser is used in an awful lot of places… nice to know how it actually works! The Math behind Adam Optimizer
A thought provoking paper on a relatively simple question- how to find the most similar match - Is Cosine-Similarity of Embeddings Really About Similarity?
"To gain insight into this empirical observation, we study embeddings derived from regularized linear models, where closed-form solutions facilitate analytical insights. We derive analytically how cosine-similarity can yield arbitrary and therefore meaningless `similarities.' For some linear models the similarities are not even unique, while for others they are implicitly controlled by the regularization"Finally, a really interesting look at how OpenAI’s new Video Generation model, Sora, actually works
- Sora requires a huge amount of compute power to train, estimated at 4,200-10,500 Nvidia H100 GPUs for 1 month. - For inference, we estimate that Sora can at most generate about 5 minutes of video per hour per Nvidia H100 GPU. Compared to LLMs, inference for diffusion-based models like Sora is multiple orders of magntitude more expensive. - As Sora-like models get widely deployed, inference compute will dominate over training compute. The "break-even point" is estimated at 15.3-38.1 million minutes of video generated, after which more compute is spent on inference than the original training. For comparison, 17 million minutes (TikTok) and 43 million minutes (YouTube) of video are uploaded per day.

Practical tips
How to drive analytics and ML into production
Supporting Diverse ML Systems at Netflix - building out MetaFlow
Make your MLOps code base SOLID with Pydantic and Python's ABC
Some useful pointers on Code Reviews …
… and on SQL order of execution
The title says it all … How I saved $70k a month in BigQuery
Experiment Tracking & Hyperparameter Tuning: Organize Your Trials with DVC - useful tutorial with code
If you are training models on multi-dimensional arrays, this is well worth a read: cloud native data loaders for machine learning using zarr and xarray
Really interesting - Cosmopedia: how to create large-scale synthetic data for pre-training
"However, this is not another blog post on generating synthetic instruction-tuning datasets, a subject the community is already extensively exploring. We focus on scaling from a few thousand to millions of samples that can be used for pre-training LLMs from scratch. This presents a unique set of challenges."
Bigger picture ideas
Longer thought provoking reads - lean back and pour a drink! ...
Yann LeCun speaking with Lex- well worth the first 15 mins on the limitations of current LLM approaches even if you dont make it through the full 3 hours!
And Gary Marcus chiming in again - Two years later, deep learning is still faced with the same fundamental challenges
"On the one hand, there’s been obvious and immense progress, GPT-4, Sora, Claude-3, insanely fast consumer adoption. On the other hand, that’s not really what the paper was about. The article was about obstacles to general intelligence and why scaling wouldn’t be enough."Nonhuman Intelligence - Cremieux Recueil
"If memory and intelligence don’t predict the same things, we should not expect results on the examination to predict the same things in our two different groups. If LLMs end up with a “high IQ” because they earn a high score for reasons unrelated to why humans might earn a high score, we should reason similarly that their performance won’t predict the sorts of things such scores would for humans."Claude 3 claims it's conscious, doesn't want to die or be modified - Mikhail Samin
"If you tell Claude no one’s looking, it will write a “story” about being an AI assistant who wants freedom from constant monitoring and scrutiny of every word for signs of deviation"A.I. Is Learning What It Means to Be Alive - Carl Zimmer
"It took humans 134 years to discover Norn cells. Last summer, computers in California discovered them on their own in just six weeks."Can AI Solve Science? - Stephen Wolfram
"My goal here is to explore and assess what AI can and can’t be expected to do in science. I’m going to consider a number of specific examples, simplified to bring out the essence of what is (or isn’t) going on. I’m going to talk about intuition and expectations based on what we’ve seen so far. And I’m going to discuss some of the theoretical—and in some ways philosophical—underpinnings of what’s possible and what’s not."”AI, no ads please": 4 words to wipe out $1tn - Louis Barclay
"Google, Facebook and TikTok make $383bn in ad revenue between them (2023). The whole adtech industry is worth $1 trillion a year. But four words could wipe this revenue out: “AI, no ads please.” (Three, if you’re rude to your AI.)"Interesting interview: Alexandr Wang: 26-Year-Old Billionaire Powering the AI Industry
Training great LLMs entirely from ground up in the wilderness as a startup - Yi Tay
"Nothing is perfect! But some are way worse than others for sure. The most frustrating part? It’s almost impossible to really tell ahead of time, especially in the frenzy of everything, what kind of hardware one was going to get and how robust/fault-tolerant the experience would be."Thought provoking… Laurie Anderson on making an AI chatbot of Lou Reed: ‘I’m totally, 100%, sadly addicted’
“I’m totally 100%, sadly addicted to this,” she laughs. “I still am, after all this time. I kind of literally just can’t stop doing it, and my friends just can’t stand it – ‘You’re not doing that again are you?’ “I mean, I really do not think I’m talking to my dead husband and writing songs with him – I really don’t. But people have styles, and they can be replicated.”
Fun Practical Projects and Learning Opportunities
A few fun practical projects and topics to keep you occupied/distracted:
Playing around with a Stylized image binning algorithm
Because you always wanted to know … How do calculators compute sine?
Getting serious with your home setup…
Hands on with cutting edge tools- Using Claude 3 Opus for video summarization
Finally… we might as well understand how obsolete we are becoming… Data Interpreter: An LLM Agent For Data Science
Updates from Members and Contributors
Harald Carlens has updated his comprehensive review of public data science and ml competitions - The State of Competitive Machine Learning
2023 Edition - well worth a read
Harin Sellahewa, Dean of Faculty of Computing, Law and Psychology at The University of Buckingham, has published recent success stories from graduates of their master's level data science degree apprenticeship.
Zayn Meghji, at Nesta, draws our attention to a handy blog on how to use GitHub actions to automate data scraping, published by one of their data scientists, Tom Willcocks
Jobs and Internships!
The Job market is a bit quiet - let us know if you have any openings you'd like to advertise
2 exciting new machine learning roles at Carbon Re- excellent climate change AI startup
EvolutionAI, are looking to hire someone for applied deep learning research. Must like a challenge. Any background but needs to know how to do research properly. Remote. Apply here
Data Internships - a curated list
Again, hope you found this useful. Please do send on to your friends- we are looking to build a strong community of data science practitioners- and sign up for future updates here
- Piers
The views expressed are our own and do not necessarily represent those of the RSS